一种基于博文相似性的社交机器人检测系统及方法与流程
本发明涉及一种基于博文相似性的社交机器人检测系统及方法,属于机器学习和社交网络
技术领域:
。
背景技术:
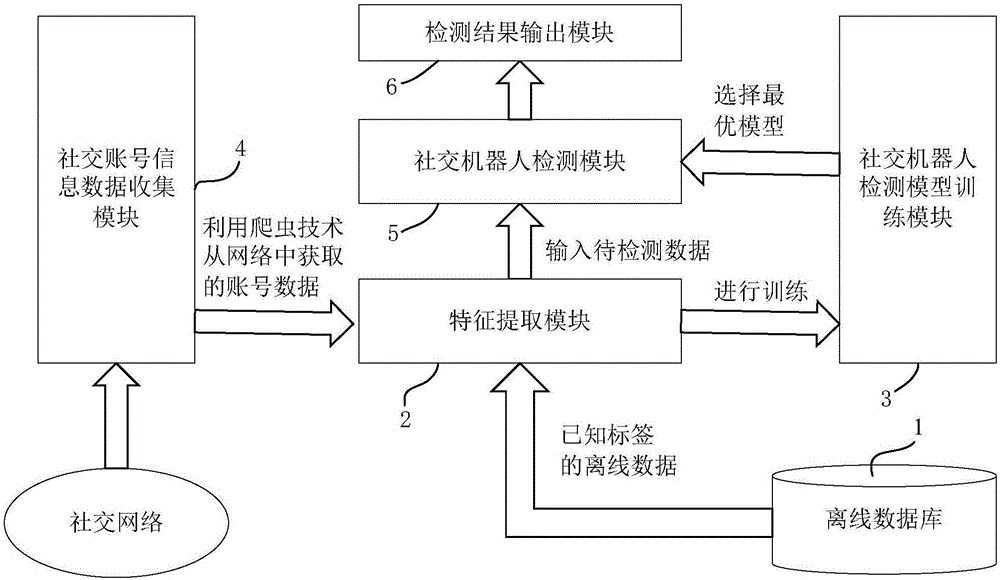
:随着互联网的飞速发展,社交网络已经成为绝大多数人们生活中不可或缺的一部分,为人们的生活和交际提供了许多便利。但随着人工智能的逐渐发展,在社交网络中也出现了许多并非真人控制的账号,这些模仿人类行为活跃在社交网络上的账号,被称之为社交机器人。据报道,facebook认为其用户大约有8300万为虚假使用者;而在推特中,奥巴马的1782万关注者中,有29.9%的人为虚假账户;同样的米特·罗姆尼(mittromney)的814000名关注者中,也有21.9%的用户可能是社交机器人(参考文献[1])。这些社交机器人在政治活动中可以用于摇摆选民,发动政治攻击,操纵公众舆论等,还有一些社交机器人被用于在社交网络中进行市场营销,例如发布广告,制造流行趋势等。这些行为,对社交网络内容的真实性造成了一定的影响。但更需要重视的是,除此之外,社交机器人还带来各种各样的安全风险,其中之一就是通过与社交网络用户建立联系,从而获得网络用户个人详细信息如生日、电子邮件、电话号码、地址等,在获取了这些信息后,社交机器人背后的操作者可以利用网络用户个人信息及建立的信任关系,对目标进行社会工程学攻击(参考文献[2])。目前国内外对社交机器人检测技术进行了大量的研究工作。从检测方法上可以分为:1.基于蜜罐系统的社交机器人检测(参考文献[3]):这种方法通过设置账号并发布正常用户不会关注的无意义内容来吸引社交机器人的关注。2.基于特征阈值的社交机器人检测(参考文献[4]):通过观察社交机器人的行为,提取特征,通过大量实验得到特征阈值,需要判断的账号与阈值比较后得到结果。3.基于机器学习的社交机器人检测(参考文献[5]):通过提取特征,进行机器学习,得到训练好的模型,将需要判断的账号输入模型即可得到预测结果。其中,基于机器学习的社交机器人检测方法得到了普遍的应用。但是随着技术的不断发展,机器人账号更加智能,原有的特征已不能很好的反应目前的趋势。并且,已有的方法多着重账号的配置文件以及账号的行为习惯,并未对发布的内容风格进行研究,因此对于可以模仿正常用户的配置文件及行为习惯的社交机器人检测效果不佳,需要提出新的特征。社交机器人是人工智能飞速发展的产物之一,相比于传统的垃圾账号,社交机器人更加智能。它们可以捕捉热门话题,发布相关信息从而获取更多正常用户的关注。社交机器人还可以在某一领域成为具有影响力的用户,影响公众意见。其次,有不法分子利用社交机器人对用户进行社会工程学攻击。由于社交网络中用户个人信息较为容易获取,所以社交机器人可以通过与用户建立起信任关系,进而对用户进行社会工程学攻击,在社交网络中具有威胁性。现有的社交机器人检测,对新型智能机器人的检测表现一般,需要针对当前社交机器人特点,发现新的特征及方法建立模型来进行检测。参考文献如下:1、shafahi,m.,kempers,l.,afsarmanesh,h.:phishingthroughsocialbotsontwitter.in:ieeeinternationalconferenceonbigdata.pp.3703{3712(2017).2、hill,k.:theinvasionofthetwitterbots.http://www.forbes.com/sites/kashmirhill/2012/08/09/the-invasion-of-the-twitter-bots/(2012).3、lee,k.,eoff,b.d.,caverlee,j.:sevenmonthswiththedevils:along-termstudyofcontentpollutersontwitter.in:internationalconferenceonweblogsandsocialmedia,barcelona,catalonia,spain,july(2011).4、varol,o.,ferrara,e.,davis,c.a.,menczer,f.,flammini,a.:onlinehuman-botinteractions:detection,estimation,andcharacterization.the11thinternationalaaaiconferenceonwebandsocialmedia(2017).5、subrahmanian,v.s.,menczer,f.,azaria,a.,durst,s.,kagan,v.,galstyan,a.,lerman,k.,zhu,l.,ferrara,e.,flammini,a.:thedarpatwitterbotchallenge.computer49(6),38{46(2016).技术实现要素:本发明针对于现有社交机器人检测对新型智能机器人的检测表现一般,不能很好针对当前社交机器人的特点进行检测的问题,提出一种基于博文相似性的社交机器人检测系统及方法,将博文相似性特征定义为内容相似性,标点符号使用相似性,博文长度相似性及停用词相似性四个方面,并采用潜在语义相似性模型(潜在语义分析,lsa,latentsemanticanalysis)来计算博文内容相似性。本发明通过提取包括博文相似性在内的多维特征,采用机器学习算法建立模型,从而达到检测社交网络中的账号是否为社交机器人的目的。本发明提出一种基于博文相似性的社交机器人检测系统,包括离线数据库、特征提取模块、社交机器人检测模型训练模块、社交账号信息数据收集模块、社交机器人检测模块和检测结果输出模块。离线数据库存储带标签的离线数据集,离线数据集包含社交机器人账号以及正常用户账号的数据,标签用于标记账号是否为社交机器人。特征提取模块用于对输入的账号数据进行特征提取,对符合要求1和2的账号数据进行特征提取;要求1是账号使用语言是英语,要求2是账号的原创博文数量大于k条,k为大于等于2的正整数;特征提取模块所提取的特征包括元数据特征和博文内容特征;其中元数据特征包括用户关注数和用户粉丝数的比例、用户点赞数、发布博文的客户端、博文发布的时间间隔和转发博文占总博文的比重;博文内容特征包括账号行为特征和博文相似性特征,其中,账号行为特征包括:平均每条博文的提及人数、平均每条博文的带话题数、以及平均每条博文含url链接数;博文相似性特征包括:内容相似性、标点符号相似性、博文长度相似性和停用词使用相似性。社交机器人检测模型训练模块利用特征提取模块进行特征提取后的带标签的离线数据,采用多种机器学习算法进行模型训练,并通过测试数据获得最优检测模型,将该最优检测模型输入社交机器人检测模块。社交账号信息数据收集模块用于利用网络爬虫技术从社交网络中爬去待检测的账号数据;在社交机器人检测过程中,社交账号信息数据收集模块将爬取的待检测的账号数据输入特征提取模块。本发明的基于博文相似性的社交机器人检测方法,通过爬虫技术获取社交网络上的账号数据,生成一个带标签的离线数据集,标签用于标记账号是否为社交机器人,所述方法包括如下步骤:步骤10,对所述的离线数据集中账号使用语言是英语的每条账号数据进行元数据特征提取;所提取的元数据特征包括:用户关注数和用户粉丝数的比例、用户点赞数、发布博文的客户端、博文发布的时间间隔和转发博文占总博文的比重;步骤20,对经过步骤10处理后的每条账号数据,若账号的博文数量大于k条,则对博文内容进行特征提取,否则对该账号数据终止操作。博文内容提取的特征分为账号行为特征和博文相似性特征两部分,其中,账号行为特征包括:平均每条博文的提及人数、平均每条博文的带话题数、以及平均每条博文含url链接数;博文相似性特征包括:内容相似性、标点符号相似性、博文长度相似性和停用词使用相似性。步骤30,将步骤10获得的元数据特征和步骤20获得的博文内容提取的特征用于机器学习算法输入,标签作为输出,利用训练数据中提取好特征的带标签的账号数据,采用不同机器学习算法进行模型训练,然后再输入测试数据进行性能测试,选出最优检测模型作为最终的社交机器人检测模型。所述的步骤20中,内容相似性通过潜在语义分析lsa模型来计算获得。本发明与现有技术相比,具有以下明显优势:(1)目前已有的基于机器学习的检测方法中的特征,与新型的智能机器人的特征吻合度一般。本发明提出了符合新型社交机器人的特征,将博文相似性扩展为内容相似性、博文长度相似性、标点符号使用相似性以及停用词相似性,并率先将lsa模型应用于内容相似性特征的计算中,与其他方法相比,对社交机器人的检测具有更高的准确率,具有创新性。(2)本方法将lsa模型应用到社交机器人检测特征中的博文相似性计算中,对博文内容中单词向量进行了降维,相比传统相似性计算方法,在提高了检测准确率的同时,还极大节约了博文相似性特征提取的工作量,具有高效性。附图说明图1是本发明的基于博文相似性的社交机器人检测系统的结构示意图;图2是本发明的基于博文相似性的社交机器人检测模型训练方法流程图;图3是本发明的基于博文相似性特征提取处理流程示意图;图4是本发明利用lsa模型进行文本相似性计算流程图。图中:1-离线数据库;2-特征提取模块;3-社交机器人检测模型训练模块;4-社交账号信息数据收集模块;5-社交机器人检测模块;6-检测结果输出模块。具体实施方式为了便于本领域普通技术人员理解和实施本发明,下面结合附图对本发明作进一步的详细描述。本发明提供了一种基于博文相似性的社交机器人检测系统和方法。通过爬虫技术获取社交网络上的账号数据,包括用户配置文件、博文数量、内容及发布时间等,利用社交机器人检测系统对账号进行检测,若检测结果显示为社交机器人账号,则进行提示。为了达到检测社交网络中的账号是否为社交机器人的目的,如图1所示,为本发明提供的基于博文相似性的社交机器人检测系统的一种实现结构,包括:离线数据库1,特征提取模块2,社交机器人检测模型训练模块3,社交账号信息数据收集模块4,社交机器人检测模块5和检测结果输出模块6。离线数据库1存储带标签的离线数据集,离线数据集中每个账号都已经标记出是否为社交机器人,离线数据包含社交机器人账号以及正常用户账号。带标签的数据集用来对社交机器人检测模型进行训练和测试。特征提取模块2用于对输入的账号数据进行特征提取。特征提取模块2所要处理的数据分两类:一是离线数据库1中的带标签的数据,这部分数据用于社交机器人检测模型的训练和测试,以获得最优检测模型;二是社交账号信息数据收集模块4利用爬虫技术从网络中获取的用户账号数据,这部分数据是需要检测的数据。无论哪类数据,特征提取模块2都对符合要求的账号数据进行特征提取,要求1:账号使用语言是英语,要求2:账号的原创博文数量大于k条;k为正整数,本发明实施例取值为10。特征提取模块2所提取的特征包括元数据特征和博文内容特征;其中元数据特征包括用户关注数和用户粉丝数的比例、用户点赞数、发布博文的客户端、博文发布的时间间隔和转发博文占总博文的比重;博文内容特征包括账号行为特征和博文相似性特征,其中,账号行为特征包括:平均每条博文的提及人数、平均每条博文的带话题数、以及平均每条博文含url链接数;博文相似性特征包括:内容相似性、标点符号相似性、博文长度相似性和停用词使用相似性。具体各特征在下面再进行具体说明。社交机器人检测模型训练模块3对经过特征提取处理后的带标签的离线数据,利用多种机器学习算法进行模型训练;输入测试数据对不同模型进行评价,得到最优检测效果模型。将离线数据库1的一部分数据作为训练数据,一部分作为测试数据,将利用特征提取模块2提取的特征作为机器学习算法的输入,输出为对应的标签,即是否为社交机器人。通过对训练好的多个模型进行测试,选取其中最优的模型作为最终的社交机器人检测模型,即将获得的最优模型输入社交机器人检测模块5。社交账号信息数据收集模块4利用网络爬虫技术,对待检测的社交账号进行网络数据收集。所爬取的用户数据包括用户信息和发布的博文内容等,用户信息如:用户昵称、用户关注人数和用户粉丝人数等;发布的博文数据包括:博文数量、内容、时间和发布博文的客户端等。社交机器人检测模块5中存储社交机器人检测模型训练模块3训练得到的最优检测模型,社交账号信息数据收集模块4采集的待检测账号数据经过特征提取模块2提取特征后,输入到社交机器人检测模块5中进行账号检测,检测结果输入检测结果输出模块6中。检测结果输出模块6将机器学习模型预测的账号结果反馈到用户,若模型判定为社交机器人则发出警告提醒。社交机器人检测模型训练过程中,离线数据库1将已知标签的数据传输给特征提取模块2;特征提取模块2将提取的数据特征传输给社交机器人检测模型训练模块3进行训练获得最优的社交机器人检测模型;社交机器人检测模型训练模块3将经训练得到的最优检测模型输入给社交机器人检测模块5用作检测模型。社交机器人检测过程中,社交账号信息数据收集模块4将获取的账号信息数据传输给特征提取模块2;特征提取模块2将提取的数据特征输入给社交机器人检测模块5进行检测;社交机器人检测模块5将检测结果输入给检测结果输出模块6,检测结果输出模块6将预测结果反馈到用户,若模型判定为社交机器人则发出警告提醒。本发明的基于博文相似性的社交机器人检测方法,一个实现流程如图2所示,利用离线数据库1结合多种机器学习算法进行训练,从而建立检测模型,对待检测账号进行检测。该方法主要包括:账号元数据特征提取,博文内容特征提取及社交机器人检测模型训练三个步骤,下面说明各步骤的实现。步骤10,通过爬虫技术获取社交网络上的账号数据,生成带标签的离线数据集,标签是指是否为社交机器人。首先对带标签的离线数据的账号使用的语言进行判断,若不是英语,对该离线数据结束操作,若是英语,进一步进行账号元数据特征提取。一条账号的离线数据提取的元数据特征包括:用户关注数和用户粉丝数的比例、用户点赞数、发布博文的客户端、博文发布的时间间隔和转发博文占所有博文的比重。用户粉丝数和用户关注数的比例,即账号被关注人数与关注人数的比例。相对于正常用户而言,社交机器人通常会关注大量的人,来获取他人的注意,以此提高自己的影响力。并且由于其自身没有真实的社会关系网,所以其获得的关注人数相较于正常用户通常较少。用户点赞数,即用户对其他博文的点赞数。用户的点赞行为,一般发生在浏览自己主页的时间轴timelines时发生,timeline中会有用户自己关注的人的博文,用户可以通过点赞及转发等操作,来表达自己对此条博文的态度。但是对于由智能程序控制的社交机器人而言,它们很少会产生浏览timeline这种人类特有的行为,进而表现为很少对其他博文点赞。发布博文的客户端:用户可以通过多种平台来发布博文,常见的有来自官方网站、手机客户端等等。同时推特twitter也像用户提供开放的应用程序编程接口api接口,方便用户的一些个性化定制。社交机器人往往利用api接口来发布博文。博文发布的时间间隔:正常用户发布博文的时间具有随机性,而一些社交机器人由于程序的设定,具有较为规律的发布时间。因此,本发明先求出发布博文之间的时间间隔,再求发布博文相差时间的方差,以方差来衡量博文发布时间是否具有规律性。转发博文占所有博文的比重:社交机器人发布的博文内容一般取决于程序的设置,如果转发的话,不好表达机器人自己的目的,所以一般的社交机器人的原创内容较多;还有些社交机器人通过转发博文与正常用户产生交流,建立信任关系。但是此类机器人一般很少存在原创内容。步骤20,对每个账户的博文内容进行特征提取。首先,判断博文数量是否大于10条,如果是,进行账号博文内容特征提取;如果不是,结束对该账户的操作。博文内容特征包括:平均每条博文的提及人数、平均每条博文的带话题数、平均每条博文含url(统一资源定位符)链接数、内容相似性、标点符号相似性、博文长度相似性和停用词使用相似性。本发明实施例中k设置为10。原创博文的数量k的取值,因为要比较相似性,所以k至少大于等于2。并且k应大于等于lsa模型中topic数的数值,也就是说lsa模型中topic数的设置要小于等于k。博文内容特征可分为账号行为特征和博文相似性特征两大部分。博文的内容可以反映出账号的行为特征,账号行为特征包括,平均每条博文的提及人数、平均每条博文的带话题数、平均每条博文含url链接数。平均每条博文的提及人数,即用户博文中的平均提及人数。对于正常用户而言,社交网络更多作为和朋友交流分享生活的平台。所以正常用户会有更多的互动行为。具体行为体现在发布的博文内容中会出现较多的“@”符号。平均每条博文的带话题数,即用户博文中平均话题数。一般而言,为了获取更多的关注度,社交机器人博文中会有更多的“#”符号,以期出现在更多的话题中,被更多的人发现关注。平均每条博文含url链接数:社交机器人为了达到它的某种目的,常常会在博文中添加url链接,链接可能是图片,文章,网站,也有可能是伪装成正常内容的钓鱼网站。本发明通过大量数据分析,发现社交机器人所发布的内容具有较为固定的主题,博文内容及词汇的使用都较为集中,因此,在社交机器人的检测中引入博文相似性特征;并首次将博文相似性特征分解为多个维度,博文相似性特征包括:内容相似性、标点符号相似性、博文长度相似性及停用词使用相似性,下面对其中的各特征说明。内容相似性:计算用户发布的原创博文之间的相似性均值。一般而言机器人发布的博文内容主题较为相似。而正常用户的博文内容较为广泛,词汇相对多变。标点符号相似性:每个人都有自己的标点符号使用习惯,因此标点使用的相似性也被选为特征。通过计算每个博文帖子中标点使用频率的方差来衡量标点符号使用的相似性。博文长度相似性:在社交机器人行为分析中,可以发现博文帖子的长度;如:单词的数量,比正常用户的账户博文长度更加固定。本发明选择用户发布的原创博文中单词数量的方差来衡量博文长度的相似度。停用词使用相似性:停用词通常是指一些最常用的短语功能词,如“is”,“at”,“which”,“on”。停用词通常没有特定含义,但仍可反映用户的写作风格,计算每条博文中常见停用词的频率,然后计算频率方差来衡量停用词的相似度。如图3所示,为本发明的博文相似性特征的一个提取流程,如下:步骤21、将爬取到的用户所发布的所有博文进行处理,过滤掉所有转发博文,只对原创博文进行相似性分析;步骤22、判断过滤后得到的原创博文数量,为了博文相似性的计算,只保留数量大于10条的账号作为数据集;步骤23、统计每个账号所有原创博文中标点符号的使用频率占比,计算方差后得到标点符号相似性;步骤24、统计每个账号所有原创博文中停用词的使用频率占比,计算方差后得到停用词使用相似性;步骤25、以原创博文的单词数量作为长度的衡量标准,计算博文单词数量的方差后得到博文长度相似性;步骤26、将原创博文进行分词并做去掉停用词处理,然后利用lsa模型计算博文内容的相似性,如图4所示。在内容相似性检测中本发明采用潜在语义索引lsa模型,lsa是一种博文挖掘技术,可以对词汇进行聚类,达到降维的目的。lsa的出现源自问题:如何从一个搜索中快速找到相关的文档。一般情况下,当本发明试图通过比较词的异同来找到相关的博文时,存在着难以解决的局限性问题。因为,在搜索中本发明实际想要去比较的不是词,而是隐藏在词之后的意义和概念。潜在语义分析试图去解决这个问题,它把词和文档都映射到一个“概念”空间并在这个空间内进行比较。如图4所示,利用lsa模型计算账号的原创博文的内容相似性特征,即进行文本相似性计算,包括:271)博文预处理,包括:a、将一个账号的所有原创博文读入,并以列表方式进行存储。b、对每一条博文进行分词并对单词进行小写化,并且去掉博文中的停用词及标点符号。c、分词后的单词需要进行词干化,主要包括将名词的复数变为单数及将动词的其他形态变为基本形态。272)lsa模型建立,包括;d、将词干化后的词建立字典,表示这个单词及单词在博文语料库里出现的次数。e、将训练文档向量组成的矩阵进行svd分解,并计算出矩阵的一个低维近似矩阵,通过lsa模型将文档映射到一个话题topic维的空间中,本发明的lsa模型中设置topic=10。topic的取值要小于等于上文所述的k值。f、通过建立索引,来比较博文之间的相关度。在博文中随机选取10篇博文作为索引,将其向量化;再用之前训练好的lsa模型将索引映射到topic空间。即可计算索引博文与其他博文之间的余弦相似度,从而得到博文的内容相似性。步骤30、社交机器人检测模型训练:将提取好特征的带标签的训练数据采用多种不同的机器学习算法进行模型训练;然后输入测试数据进行性能测试,选出最优检测模型。将提取好特征的带标签的用户账号数据集分为训练数据和测试数据两部分,分别用作模型训练及模型性能测试。本发明选择了多种机器学习算法进行模型训练,包括knn(k最近邻)、决策树、随机森林、adaboost、gradientboosting等。得到的模型用测试数据进行测试,发现最优模型为gradientboosting模型。boosting方法属于机器学习中的集成学习,是一种用来提高弱分类算法准确度的方法,这种方法通过构造一个预测函数系列,然后以一定的方式将他们组合成一个预测函数。gradientboosting是一种boosting的方法,其与传统的boosting的区别是,每一次的计算是为了减少上一次的残差(residual),而为了消除残差,可以在残差减少的梯度(gradient)方向上建立一个新的模型。本发明在模型训练后,引入皮尔森相关系数计算特征与标签的相关性,证明了本发明提出的博文内容特征的有效性。皮尔森相关系数:是用来反应两种变量之间相似程度的统计量,在机器学习中可以用来计算特征与标签间的相似度,即可判断所提取到的特征和标签是正相关或负相关。特征皮尔森相关系数如表1下:表1特征皮尔森相关系数排名特征皮尔森相关系数是否为新提出特征1转发博文占总博文比重0.68否2博文长度相似性0.53是3标点符号相似性0.51是4博文发布平台0.51否5用户博文中的平均提及人数0.47否6博文内容相似性-0.41是7用户粉丝数与用户关注数的比例0.31否8平均每条博文含url链接数0.22否9停用词使用相似性-0.19是10用户博文中平均话题数0.18否11用户对其他博文的点赞数0.08否12发布博文相差时间的方差-0.03否新特征(博文相似性特征共4个)的提取是本发明的重要创新点。这个表格是训练模型时所用的所有特征与是否为机器人结果的相关性,皮尔森相关系数的绝对值越大越能证明特征的有效性。通过上面表格可以看出,本发明提出的博文相似性特征(包含博文长度相似性、标点符号相似性、博文内容相似性、停用词使用相似性)在所有的特征中均取得了不错的效果。为使本发明的技术方案更加清楚,下面对本发明提出的方法进行实验仿真,仿真条件如下所示:操作系统windows10编程语言python2.7硬件条件处理器intel(r)xeon(r)cpue5-2620v32.40ghz检测对象推特网站上的社交用户(已知标签)系统功能给出系统检测的准确率、召回率以及f1值(1)数据爬取及特征提取:通过网络爬虫技术结合推特网站的官方api获取到原始数据。对数据进行处理,分别提取账号元数据特征及博文内容特征。(2)机器人检测结果验证:将预测结果与已知标签做对比。计算出准确率、召回率以及f1值。(3)观察社交机器人检测结果:社交机器人检测模型的准确率、召回率以及f1值分别达到:98.09%,98.01%,98.11%。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1