一种结合表观特征和时空分布的双流网络行人重识别方法与流程
本发明属于计算机视觉中的行人重识别技术领域,具体为一种结合表观特征和时空分布的双流网络行人重识别方法。
背景技术:
近年来,视频监控在公共安全领域中发挥着重大的作用,而行人重识别技术是视频监控中非常关键的一步,其在协助警方追踪罪犯,维护社会稳定中起到关键的作用。近几年,由于深度神经网络在提取图像特征时的优异表现,行人重识别技术有了很大的突破。
当前对于行人重识别的研究主要集中在神经网络结构的优化和损失函数的优化上。然而,单纯地从神经网络结构上对模型进行改进的效果相当有限。因此,研究人员尝试挖掘其他的辅助信息从而提高模型性能。其中,挖掘行人的结构信息是当前行人重识别领域很重要的研究方向。挖掘行人的结构信息包括基于区域分块的特征提取,基于姿态估计的特征提取,和基于背景语义信息的特征提取等。
通过挖掘行人图像的结构信息对行人重识别算法模型进行改进对于行人重识别的性能有很大的提升(market1501数据集上rank1准确率为80%-90%)。然而当前算法模型的准确率还远远无法应用到现实场景当中。究其原因,由于当前的研究主要还是集中在图像表观特征的提取和优化上,往往忽视了对时空信息的科学提取和合理利用。由于跨摄像头下行人图像存在光照、角度、姿态等问题,使得同一行人在不同摄像头下的图像存在较大差异,只基于表观特征的算法模型往往还不能准确匹配复杂环境下的行人。
当前基于时空约束的行人重识别技术有少量的研究,然而已有的基于时空约束的算法模型往往基于主观的先决条件,包括主观估计行人平均行进速度从而约束行人图像对的空间距离;以及基于单峰值的韦布尔分布模型构造时空分布模型从而进行时空约束。然而现实世界中行人的行进速度往往具有不确定性。因此已有的时空约束模型并不能很好的应用于现实世界中。构建一个鲁棒的时空模型具有如下两个挑战:(1)现实世界中两个摄像头之间往往存在多个时间差峰值,因为可能存在多条不同的道路,所以构建一个鲁棒的时空模型是非常困难的。(2)即使我们构建出了一个比较鲁棒的时空模型,但是由于行人的行进速度和行进状态不可预测,比如我们要跟踪一个小偷,那他的速度往往会非常快,路径也会非常诡异。也就是说行人的行进状态往往具有非常大的不确定性。
技术实现要素:
针对现有行人重识别技术中存在的不足和问题难点,本发明提出一种结合表观特征和时空分布的双流网络行人重识别方法,该方法能够显著提高识别的准确率。
本发明通过以下的技术方案实现:一种结合表观特征和时空分布的双流网络行人重识别方法,包括步骤:
表观特征上,使用深度神经网络算法提取每个行人图像的表观特征向量,计算出所有行人图像对之间的表观相似度,所述图像对是指检索图像和数据库图像;
时空分布上,对于训练数据集,以一时间差单位区间统计每组摄像头对的原始时间差概率分布模型,得到n*n个时间差概率统计直方图,n为摄像头个数,然后对每个时间差概率统计直方图进行高斯平滑,得到时空分布模型;由时空分布模型求出检索图像和数据库图像之间的时空概率;
对表观相似度和时空概率进行逻辑平滑,得到平滑后的表观相似度和时空概率;
将平滑后的表观相似度和时空概率进行联合计算得到最终的行人图像对相似度,对行人图像对相似度排序得到行人重识别结果。
优选的,使用余弦距离计算出所有行人图像对之间的表观相似度。
优选的,时空分布模型的构建步骤是:
步骤2.1,假设训练数据集中一共有n个摄像头,对于摄像头对ci和cj,i=1,2,…,n,j=1,2,…,n,以δt为一个单位区间,统计训练数据集中同一行人先后出现在摄像头ci和cj的时间差概率分布,从而得到n*n个原始时间差概率分布直方图
步骤2.2,对于摄像头对ci和cj的原始时间差概率分布直方图
更进一步的,原始时间差概率分布直方图
其中:
k代表统计直方图中第k个单位区间,例如记δt为统计直方图的时间差单位区间,则tj-ti∈((k-1)δt,kδt);
y=1代表
进一步地,由步骤2.1得到的原始时间差概率分布模型只统计了训练数据集中的时空信息,然而现实场景中往往具有更加复杂的分布情况,因此对原始时间差概率分布模型进行高斯平滑使得时空模型更加客观可靠,具有更好的泛化性。具体为:
z=σkp(y=1|k,ci,cj)
其中:
k为高斯核函数,用于平滑原始时间差概率分布模型;
z为归一化参数;
p(y=1|k,ci,cj)代表关于摄像头对ci和cj的原始时间差概率分布模型经过高斯平滑后,在第k个单位区间的时空概率。
优选地,对表观相似度和时空概率进行逻辑平滑,将平滑后的表观相似度和时空概率相乘,得到最终的行人图像对相似度;具体为:
pjoint=f(s;a0,k0)f(pst;a1,k1)
pst=p(y=1|k,ci,cj)
其中,
s代表行人图像对xi和xj的表观相似度;ii、ij分别表示两张行人图像的表观特征向量;
pst代表行人图像对的时空概率;
f(x;a,k)代表逻辑回归函数,用于表观相似度和时空概率的逻辑平滑;
f(s;a0,k0)代表逻辑平滑后的表观相似度;
f(pst;a1,k1)代表逻辑平滑后的时空概率;
pjoint代表行人对间最终的行人图像对相似度。
与现有的基于时空约束的行人重识别技术相比,本发明具有如下优点:
1)提出了一种通用的结合表观特征和时空分布的双流网络模型进行行人重识别。
2)本发明并未基于主观的先验概率分布或者平均速度估计的形式构建时空分布模型,而是在训练数据集上采用无参数的统计学习方法学习时空分布模型,使得模型更加具有鲁棒性。
3)对于从训练数据集中学到的时空分布概率模型,由于训练数据集并不能完全反映现实世界中的时空信息,本发明对原始时空分布模型进行高斯平滑,使得时空分布模型具有更好的泛化性能。
4)使用基于逻辑平滑的相似性联合度量方法,使本发明具有更好的准确率。
附图说明
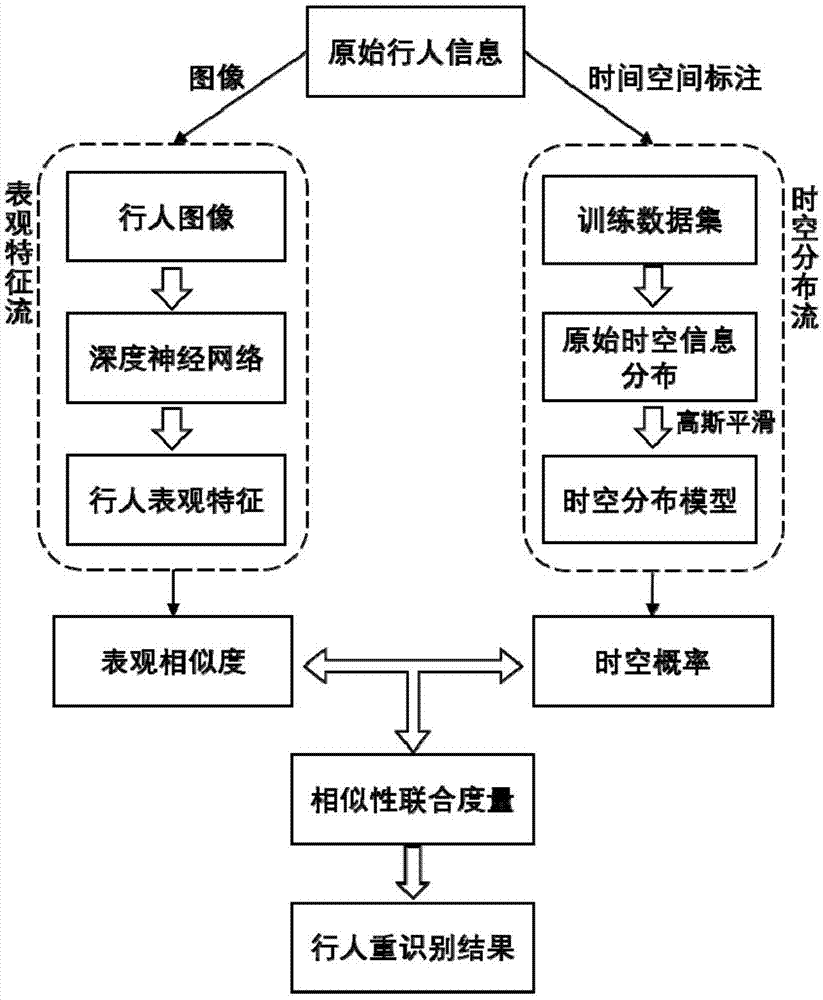
图1为本发明方法流程图。
图2为本实施例从训练数据集学到的原始时空分布模型。
图3为本实施例高斯平滑后的时空分布模型。
具体实施方式
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
实施例
本实施例一种结合表观特征和时空分布的双流网络行人重识别方法在dukemtmc-reid数据集上进行,这是当前权威的大型行人重识别数据集之一。该数据集中行人的时空信息以摄像头标号和帧号表示。下面结合图1对方法步骤进行详述。
第一步:可使用当前通用的行人重识别深度神经网络算法提取每个行人图像的表观特征向量,本实施例选择使用dukemtmc-reid训练集训练pcb网络模型。训练过程中使用水平翻转的数据增强方法,采用随机梯度下降的优化算法进行训练。训练完成后,对原始行人图像使用上述pcb网络模型提取图像表观特征向量,提取的方法是将原始行人图像纵向分割成6个局部块分别提取特征,之后将6个局部特征串联得到最后的表观特征。然后,使用余弦距离计算所有行人图像对(检索图像和数据库图像之间)的表观相似度。记xi和xj表示两张行人图像,ii和ij表示这两张图像的表观特征向量,则图像xi和xj的表观相似度为:
第二步:利用dukemtmc-reid训练集中的摄像机序号和帧号信息学习该数据集每组摄像头对ci和cj之间的时间差概率分布模型。具体步骤如下:
步骤2.1,令δt=100为时间差单位,统计dukemtmc-reid训练集中同一行人先后出现在摄像头ci和cj的时间差概率分布,从而得到所有摄像头对的原始时间差概率分布直方图
其中,dukemtmc-reid数据集中一共有8个摄像头,k代表统计直方图中第k个单位区间,例如记δt为统计直方图的时间差单位区间,则tj-ti∈((k-1)δt,kδt);
步骤2.2,由步骤2.1学习到的dukemtmc-reid训练集的时间差概率分布直方图只能表示训练集中数据的分布,然而训练数据集中的数据往往不能包含现实世界中所有的分布情况,因此引入高斯函数对步骤2.1中得到的时间差概率分布直方图进行高斯平滑,即
z=σkp(y=1|k,ci,cj);
其中
第三步:对于行人图像对xi和xj,根据其摄像头标注通过步骤二学习到的时空模型得到其时空概率。将表观相似度和时空概率进行逻辑平滑得到最后的表观概率和时空概率,具体为:
pjoint=f(s;a0,k0)f(pst;a1,k1)
pst=p(y=1|k,ci,cj)
其中s表示行人图像对的表观相似度;pst表示行人图像对的时空概率;f(x;a,k)表示逻辑回归函数,用于表观相似度和时空概率的逻辑平滑;f(s;a0,k0)表示逻辑平滑后的表观相似度;f(pst;a1,k1)表示逻辑平滑后的时空概率;pjoint表示行人对的最终联合概率。经过实验验证,a0取值为1,a1取值为2,k0和k1取值为5。
第四步:将检索行人图像与所有数据库行人图像之间的相似度由小到大进行排序,从而得到行人重识别结果。
通过实验结果证明,本实施例最终在dukemtmc-reid测试集上的性能:rank1准确率为94.4%,rank5准确率为97.4%,rank10的准确率为98.2%,map值为83.9%,远远优于其他的行人重识别算法。本方法与其他现有行人重识别方法的结果对比如表1所示。
表1本方法与其他现有行人重识别方法的结果对比
本实施例提供的结合表观特征和时空分布的双流网络行人重识别方法,尤其适用于大区域的跨摄像头行人跟踪。由于摄像头中视频本身存在相关的时间和空间信息,因此时空信息的获取不需要任何额外的手工标注。在dukemtmc-reid数据集上通过以下四个步骤:(1)使用深度神经网络提取行人图像的表观特征并计算图像对的表观相似度;(2)通过基于高斯平滑的统计方法学习训练数据集的时空分布模型;(3)通过基于逻辑平滑的联合度量方法对表观相似度和时空概率进行联合计算得出最终相似度;(4)将最终相似度进行排序得到行人重识别结果。实验结果表明本方法的rank1准确率远远高于其他算法模型。
此外,实验证明除了使用pcb算法模型提取表观特征外,将本方法的表观特征提取算法置换成其他深度模型均能得到将近10%的性能提升,基于不同表观特征提取算法结合时空分布的双流网络行人重识别方法的结果对比如表2所示。
表2本发明基于不同表观特征提取算法的结果对比示例
可通过各种手段实施本发明描述的技术。举例来说,这些技术可实施在硬件、固件、软件或其组合中。对于硬件实施方案,处理模块可实施在一个或一个以上专用集成电路(asic)、数字信号处理器(dsp)、可编程逻辑装置(pld)、现场可编辑逻辑门阵列(fpga)、处理器、控制器、微控制器、电子装置、其他经设计以执行本发明所描述的功能的电子单元或其组合内。
对于固件和/或软件实施方案,可用执行本文描述的功能的模块(例如,过程、步骤、流程等)来实施所述技术。固件和/或软件代码可存储在存储器中并由处理器执行。存储器可实施在处理器内或处理器外部。
本领域普通技术人员可以理解:实现上述方法实施例的全部或部分步骤可以通过程序指令相关的硬件来完成,前述的程序可以存储在一计算机可读取存储介质中,该程序在执行时,执行包括上述方法实施例的步骤;而前述的存储介质包括:rom、ram、磁碟或者光盘等各种可以存储程序代码的介质。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!