一种数据核对方法及装置与流程
本发明涉及数据核对技术领域,具体为一种数据核对方法及装置。
背景技术:
企业数据泛指所有与企业经营相关的信息、资料,包括公司概况、产品信息、经营数据、研究成果等,其中不乏涉及商业机密。通常所说的企业数据是指狭义的企业数据,一般只包含公司概况介绍,包括公司经营范围、联系方式、企业规模等,通常是公开的数据。企业数据的获取渠道分为集中式和分布式。集中式一般由统一的政府部门发布,如工商局数据、统计局数据,具有权威性和全面性,但数据内容比较粗略,缺乏精细度。分布式是由商业公司透过下属部门通过各种手段分散获取并统一整理,一般能使数据的精细度和准确度达到一定要求。
目前,每一次进行企业数据核对时,主要是通过数据库与需要进行核对的数据库进行相连,然后系统自动从每一个数据库中均提取出相关数据,并进行一一核对,或者采用excel表进行数据自动核对,以上两种核对方式虽然不需要人工参与就能进行核对数据,但是核对精度低,而且无法实现对大量数据进行分类后核对,降低了工作效率,因此,有必要进行改进。
技术实现要素:
本发明的目的在于提供一种数据核对方法及装置,以解决上述背景技术中提出的问题。
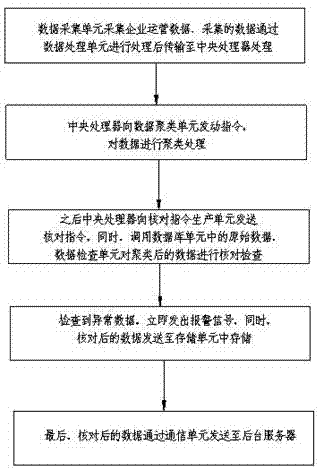
为实现上述目的,本发明提供如下技术方案:一种数据核对方法,核对方法包括以下步骤:
a、数据采集单元采集企业运营数据,企业运营数据包括企业成本数据、利润数据、员工考勤数据、采购数据、订单数据、交易数据,采集的数据通过数据处理单元进行处理后传输至中央处理器处理;
b、中央处理器向数据聚类单元发动指令,对数据进行聚类处理;
c、之后中央处理器向核对指令生产单元发送核对指令,同时,调用数据库单元中的原始数据,数据检查单元对聚类后的数据进行核对检查;
d、检查到异常数据,立即发出报警信号,同时,核对后的数据发送至存储单元中存储;
e、最后,核对后的数据通过通信单元发送至后台服务器。
优选的,所述步骤b中数据聚类单元聚类方法如下:
a、采集待聚类数据,并将数据切割呈n个子数据集;
b、对n个子数据集进行冗余过滤,得到非冗余数据;
c、对非冗余数据采用多个计算线程进行合并计算;
d、对合并计算后的计算结果进行修正并保存;
e、最后从非冗余数据中确定相关数据,即完成对数据的聚类。
优选的,所述步骤e中具体方式为:根据随机森林算法和预设训练数据,建立随机森林模型;根据随机森林模型对非冗余数据进行判别和分类,以在非冗余数据中确定相关数据。
优选的,一种数据核对装置,包括中央处理器、数据采集单元、数据处理单元、数据检查单元、核对指令生成单元、存储单元、数据库单元、报警单元、数据聚类单元以及通信单元,所述数据采集单元通过数据处理单元连接中央处理器,所述中央处理器分别连接数据检查单元、核对指令生成单元、存储单元、数据库单元、报警单元、数据聚类单元,所述中央处理器通过通信单元连接后台服务器;其中,数据采集单元用于采集企业运营数据;数据处理单元用于对采集的数据进行降噪处理;数据检查单元用于检查采集的企业数据;核对指令生成单元用于生成数据核对指令;存储单元用于存储核对后的数据;数据库单元用于保存原始数据;报警单元用于在检查出异常时发出报警信号;数据聚类单元用于对采集的数据进行聚类处理;通信单元用于传输核对后的数据。
与现有技术相比,本发明的有益效果是:本发明采用的核对方法操作简单,成本低,核对时,先自动采集企业数据至中央处理器,中央处理器发送数据聚类指令,对采集的企业数据进行聚类处理,之后中央处理器发送核对指令后对聚类后的数据进行核对,该数据核对过程自动化程度高,通过对数据聚类后再进行核对,能够提高束核对精度;其中,本发明采用的数据聚类单元聚类方法能够降低总体计算复杂度以及提高了计算的稳定性,而且数据概况分析能力强,适于海量数据的快速聚类处理,进一步提高了数据分类的精确性,从而提高了数据核对效果,此外,不仅可以使聚类的处理速度可以达到实时性的要求,还可以调整聚类结果,从而避免了聚类出局部片断式的聚类结果,与现有的数据核对系统相比,明显具有高精度、全自动化、海量数据处理的优点。
附图说明
图1为本发明流程;
图2为本发明装置原理框图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1,本发明提供一种技术方案:一种数据核对方法,核对方法包括以下步骤:
a、数据采集单元采集企业运营数据,企业运营数据包括企业成本数据、利润数据、员工考勤数据、采购数据、订单数据、交易数据,采集的数据通过数据处理单元进行处理后传输至中央处理器处理;
b、中央处理器向数据聚类单元发动指令,对数据进行聚类处理;
c、之后中央处理器向核对指令生产单元发送核对指令,同时,调用数据库单元中的原始数据,数据检查单元对聚类后的数据进行核对检查;
d、检查到异常数据,立即发出报警信号,同时,核对后的数据发送至存储单元中存储;
e、最后,核对后的数据通过通信单元发送至后台服务器。
本发明中,步骤b中数据聚类单元聚类方法如下:
a、采集待聚类数据,并将数据切割呈n个子数据集;
b、对n个子数据集进行冗余过滤,得到非冗余数据;
c、对非冗余数据采用多个计算线程进行合并计算;
d、对合并计算后的计算结果进行修正并保存;
e、最后从非冗余数据中确定相关数据,即完成对数据的聚类。
其中,步骤e中具体方式为:根据随机森林算法和预设训练数据,建立随机森林模型;根据随机森林模型对非冗余数据进行判别和分类,以在非冗余数据中确定相关数据。通过建立的随机森林模型对非冗余数据进行判别和分类,以确定相关数据,从而将不相关数据从非冗余数据中过滤掉,进而在对相关数据进行聚类时有效地提高了聚类的速度和准确率。
此外,本发明还公开了一种数据核对装置,包括中央处理器1、数据采集单元2、数据处理单元3、数据检查单元4、核对指令生成单元5、存储单元6、数据库单元7、报警单元8、数据聚类单元9以及通信单元10;所述数据采集单元2通过数据处理单元3连接中央处理器1,所述中央处理器1分别连接数据检查单元4、核对指令生成单元5、存储单元6、数据库单元7、报警单元8、数据聚类单元9,所述中央处理器1通过通信单元10连接后台服务器11;其中,数据采集单元2用于采集企业运营数据;数据处理单元3用于对采集的数据进行降噪处理;数据检查单元4用于检查采集的企业数据;核对指令生成单元5用于生成数据核对指令;存储单元6用于存储核对后的数据;数据库单元7用于保存原始数据;报警单元8用于在检查出异常时发出报警信号;数据聚类单元9用于对采集的数据进行聚类处理;通信单元10用于传输核对后的数据。
本发明采用的核对方法操作简单,成本低,核对时,先自动采集企业数据至中央处理器,中央处理器发送数据聚类指令,对采集的企业数据进行聚类处理,之后中央处理器发送核对指令后对聚类后的数据进行核对,该数据核对过程自动化程度高,通过对数据聚类后再进行核对,能够提高束核对精度;其中,本发明采用的数据聚类单元聚类方法能够降低总体计算复杂度以及提高了计算的稳定性,而且数据概况分析能力强,适于海量数据的快速聚类处理,进一步提高了数据分类的精确性,从而提高了数据核对效果,此外,不仅可以使聚类的处理速度可以达到实时性的要求,还可以调整聚类结果,从而避免了聚类出局部片断式的聚类结果,与现有的数据核对系统相比,明显具有高精度、全自动化、海量数据处理的优点。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!