一种基于双记忆注意力的方面级别情感分类模型及方法与流程
本发明属于文本情感分类技术领域,具体属于自然语言处理技术领域,具体涉及一种基于双记忆注意力机制和编码器-解码器结构的方面级别情感分类模型及方法。
背景技术:
情感分析,又称为意见挖掘,是分析人们对于产品、服务、组织、个人、事件、主题及其属性等实体对象所怀有的意见、情感、评价、看法和态度等主观感受的研究领域。方面级别情感分析是针对给定语句所描述对象的特定方面(如顾客对餐馆的评价中可能涉及服务,环境,菜品等多个方面),分析该语句所表达出的情感倾向(积极、消极或中性),它是情感分析的一个细分任务,也是该领域关注的基本问题之一。
传统的特征表示方法包括one-hot、n-gram以及领域专家通过文本或者额外的情感词典设计的一些有效特征。然而,特征工程是一个劳动密集型的任务,且需要较多的领域知识。因此,特征的自动学习渐渐成为人们研究的重点。基于神经网络的深度学习方法就是自动学习特征的一种方法。并且随着深度学习在计算机视觉,语音识别和自然语言处理等领域的成功应用,越来越多的基于深度学习的文本情感分类模型产生,这些模型普遍地利用词嵌入(wordembedding,we)的方法进行特征表示,这种低维度词向量表示方法不仅能很好地解决传统语言模型中词表示中存在的维度过大的问题,而且能很好的保留词的语义信息,使得语义相似的词距离更近。另外,在词嵌入的基础上,通过卷积神经网络(convolutionalneuralnetwork,cnn)、递归神经网络(recursiveneuralnetwork,rnn)和循环神经网络(recurrentneuralnetwork,rnn)等神经网络模型,能很好地表示句子或者文本级别的语义信息。
现有的解决方案中,基于注意力机制的循环神经网络模型和基于注意力机制的多层模型性能表现较好,前者性能较好的原因是借助深度学习模型的特征抽象机制,可以获得更加准确的注意力分布,而后者是利用上一层捕获的注意力来帮助下一层计算得到更精确的注意力分布,然而,这两种学习模型忽视了蕴含在句子中不明显但同样对情感分类很重要的词级别或短语级别情感特征。
技术实现要素:
本发明的目的是克服上述现有技术的缺陷,提供一种基于双记忆注意力的方面级别情感分类模型及方法。
本发明所提出的技术问题是这样解决的:
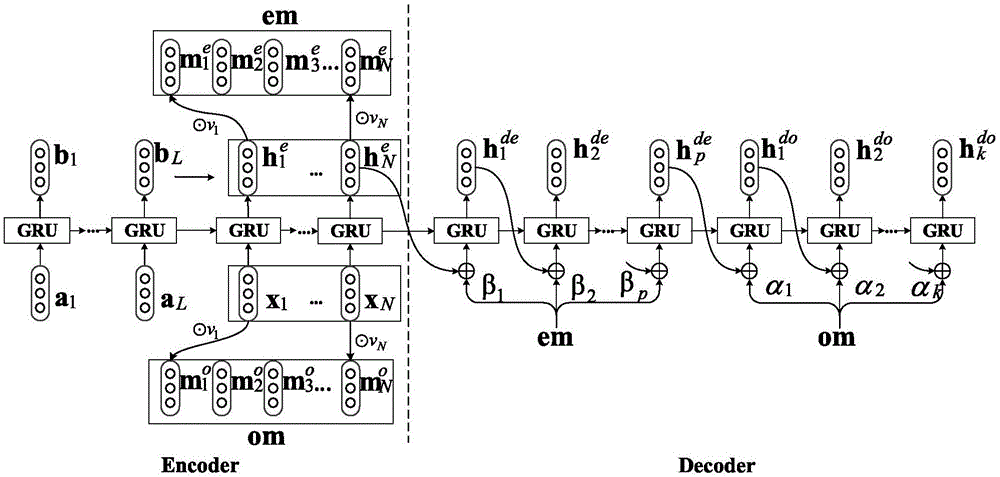
一种基于双记忆注意力的方面级别情感分类模型,包括编码器、解码器和softmax分类器;
编码器:利用标准gru循环神经网络依次对输入语句中的方面级别信息和输入语句进行编码,并从原始输入语句及其在编码器中的隐藏层状态中分别构成两个记忆,根据方面级别词语的位置对其进行加权,分别称为原始记忆(originalmemory,om)和编码记忆(encodedmemory,em);
解码器:由前馈神经网络注意力层和多层gru循环神经网络组成,前者从方面级别记忆的语义关联中捕捉重要的情感信息,后者则将这些信息在不同计算层中选择性组合,构成对编码记忆em和原始记忆om的两个解码阶段;
softmax分类器:将解码器学习到的特征用于情感分类。
一种基于双记忆注意力的方面级别情感分类方法,包括以下步骤:
步骤1.设定输入语句为s={w1,w2,...,wn},对输入语句中的每个单词做词嵌入得到向量表示x={x1,x2,...,xn},其中n代表句子长度,1≤i≤n,
步骤2.从输入语句中构建第一个记忆——原始记忆om,并根据方面级别词语的位置对其进行加权;将方面级别词语和上下文词语的绝对距离定义为词语的位置,将方面词语的位置看作0,则输入语句中的词语wi的位置权重向量
其中,1≤j≤d,qi是词wi的位置,向量vi是由
计算原始记忆
步骤3.用编码器对输入语句的方面级别词语进行编码,方面级别表示bl为:
bl=gru(bl-1,al)
其中,
对输入语句进行编码,i=1时,第一次计算的隐藏层状态为:
i≥2时,第i次计算的隐藏层状态为:
步骤4.从编码后的输入语句
步骤5.在解码器上先对编码记忆em解码,利用解码器的前馈神经网络注意力层,以方面表示bl、gru之前的隐藏层状态
当2≤t≤p时,注意力权重的评分函数为:
其中,
当t=1时,
采用一个soffmax函数来计算注意力权重βt=(βt,1,βt,2,...,βt,n):
最后得到输出向量:
当2≤t≤p时,由
当t=1时,
步骤6.在解码器上对原始记忆om解码,利用解码器的前馈神经网络注意力层,以方面表示bl、gru之前的隐藏层状态
当2≤u≤k时,注意力权重的评分函数为:
其中,
当u=1时,
采用一个softmax函数来计算注意力权重αu=(αu,1,αu,2,...,αu,n):
最后得到输出向量
当2≤u≤k时,由
当u=1时,
步骤7.将解码器的最后输出
其中,
步骤8.采用有监督学习方式使交叉熵损失函数的最小化,其中损失函数如下所示:
其中,αm是模型对训练集中第m个样本类别标签的正确预测概率,1≤m≤训练样本数;
编码器和解码器中,标准gru循环神经网络为:
rt=σ(wrxt+urht-1)
zt=σ(wzxt+uzht-1)
其中,rt为重置门,zt为更新门,ht为隐藏层状态,xt、ht-1代表t时刻的输入和t-1时刻隐藏层输出,
步骤3中,也可以先对输入语句进行编码,再对方面级别词语进行编码。
本发明的有益效果是:
本发明基于编码器-解码器模型和注意力机制,提出了一种带有双记忆注意力的文本方面级别情感分类模型及方法,引入位置注意力层构建原始记忆om和编码记忆em,应用一个特殊的前馈神经网络注意力层对随机初始化的注意力分布微调,以此来持续捕获语句中的重要情感特征,通过有监督学习的方式训练出文本方面级别情感分类模型。
本发明不同于已有专利或文献中提到的双重注意力模型中将注意力分别作用于blstm(bidirectionallongshort-termmemory,双向长短记忆)编码后的输入文本和情感符号的集合,本发明从原始文本序列和gru循环神经网络编码后的隐藏层状态中分别构建两个记忆模块,将两个注意力机制分别作用于这两个记忆中。
与现有技术相比,能够显著增强文本方面级别情感分类的鲁棒性,提高方面级别情感分类的正确率。
附图说明
图1为本发明所述模型总体结构示意图;
图2为本发明所使用的前馈神经网络注意力层计算模型。
具体实施方式
下面结合附图和实施例对本发明进行进一步的说明。
本实施例提供一种具有双记忆注意力的rnn编码器-解码器情感分类模型,该模型由编码器、两个记忆模块、解码器和分类器组成。首先,编码器对输入语句对应的词向量进行编码,获得gru循环神经网络中的隐藏层状态
一种基于双记忆注意力的方面级别情感分类模型,包括编码器、解码器和softmax分类器;
编码器:利用标准gru循环神经网络依次对输入语句中的方面级别信息和输入语句进行编码,并从原始输入语句及其在编码器中的隐藏层状态中分别构成两个记忆,根据方面级别词语的位置对其进行加权,分别称为原始记忆(originalmemory,om)和编码记忆(encodedmemory,em);
解码器:由前馈神经网络注意力层和多层gru循环神经网络组成,前者从方面级别记忆的语义关联中捕捉重要的情感信息,后者则将这些信息在不同计算层中选择性组合,构成对编码记忆em和原始记忆om的两个解码阶段;
softmax分类器:将解码器学习到的特征用于情感分类。
一种基于双记忆注意力的方面级别情感分类方法,包括以下步骤:
步骤1.设定输入语句为s={w1,w2,...,wn},对输入语句中的每个单词做词嵌入得到向量表示x={x1,x2,...,xn},其中n代表句子长度,1≤i≤n,
步骤2.从输入语句中构建第一个记忆——原始记忆om,并根据方面级别词语的位置对其进行加权;将方面级别词语和上下文词语的绝对距离定义为词语的位置,将方面词语的位置看作0,则输入语句中的词语wi的位置权重向量
其中,1≤j≤d,qi是词wi的位置,向量vi是由
计算原始记忆
步骤3.用编码器对输入语句的方面级别词语进行编码,方面级别表示bl为:
bl=gru(bl-1,al)
其中,
对输入语句进行编码,i=1时,第一次计算的隐藏层状态为:
i≥2时,第i次计算的隐藏层状态为:
步骤4.从编码后的输入语句
步骤5.在解码器上先对编码记忆em解码,利用解码器的前馈神经网络注意力层,以方面表示bl、gru之前的隐藏层状态
当2≤t≤p时,注意力权重的评分函数为:
其中,
当t=1时,
采用一个softmax函数来计算注意力权重βt=(βt,1,βt,2,...,βt,n):
最后得到输出向量:
当2≤t≤p时,由
当t=1时,
步骤6.在解码器上对原始记忆om解码,利用解码器的前馈神经网络注意力层,以方面表示bl、gru之前的隐藏层状态
当2≤u≤k时,注意力权重的评分函数为:
其中,
当u=1时,
采用一个softmax函数来计算注意力权重αu=(αu,1,αu,2,...,αu,n):
最后得到输出向量
当2≤u≤k时,由
当u=1时,
步骤7.将解码器的最后输出
其中,
步骤8.采用有监督学习方式使交叉熵损失函数的最小化,其中损失函数如下所示:
其中,αm是模型对训练集中第m个样本类别标签的正确预测概率,1≤m≤训练样本数;
编码器和解码器中,标准gru循环神经网络为:
rt=σ(wrxt+urht-1)
zt=σ(wzxt+uzht-1)
其中,rt为重置门,zt为更新门,ht为隐藏层状态,xt、ht-1代表t时刻的输入和t-1时刻隐藏层输出,
步骤3中,也可以先对输入语句进行编码,再对方面级别词语进行编码。
本发明采用随机梯度下降(stochasticgradientdescent,sgd)方法优化目标函数且使用dropout技巧来缓和过拟合问题。
- 还没有人留言评论。精彩留言会获得点赞!