基于改进差分进化算法的非线性系统参数辨识方法与流程
本发明涉及热工自动化技术领域,特别是涉及基于改进差分进化算法的非线性系统参数辨识方法。
背景技术:
在工业领域中,研究对象通常非常复杂,内部机理模糊不清,很难有理论直接获得相应的数学模型,而且大部分为非线性模型,因此提出利用已知的观测数据来辨识研究对象的数学模型及其参数。随着智能优化算法的出现,非线性系统模型参数可以使用神经网络、遗传算法、粒子群算法等算法进行辨识。差分进化(differentialevolution,de)算法是为求解切比雪夫多项式共同提出的一种采用浮点矢量编码在连续空间中进行随机搜索的优化算法。de的原理简单,受控参数少,实施随机、并行、直接的全局搜索,易于理解和实现,受到了广泛的关注。但差分进化算法存在随着进化代数的增加,容易收敛于局部最优点或算法停滞。为此需要寻找新的方法改进缺点,本专利将动态调整缩放因子和交叉率的方法结合在一起,提出新的改进方法,对非线性系统模型进行参数辨识。
技术实现要素:
为了解决差分进化算法存在随着进化代数的增加,容易收敛于局部最优点或算法停滞的缺点,本发明提供基于改进差分进化算法的非线性系统参数辨识方法,将动态调整缩放因子和交叉率的方法结合在一起,提出新的改进方法。根据个体的寿命值大小,动态调整缩放因子和交叉率,在算法初期保持多样性来避免早熟收敛,在后期保留优质解,加快收敛速度,最终使非线性系统的辨识参数更准确、辨识速度更快,为达此目的,本发明提供基于改进差分进化算法的非线性系统参数辨识方法,具体步骤如下:
(1)初始化种群,在问题的可行解空间生成随机初始化种群:
(2)变异操作,de通过差分策略实现个体变异,将两个任意个体的差分向量加到另一个随机的个体向量上成为变异向量;
(3)交叉操作,通过交叉操作生成试验向量,通过随机选择,使试验向量至少有一个分量由变异向量提供;
(4)选择操作,de采用“贪婪”选择策略,根据目标向量与试验向量的适应值来选择最优个体。
本发明的进一步改进,所述步骤一详细步骤如下;
初始化种群为xi=(xi,1,xi,2,...,xi,d),i=1,2,…,np,其中d为维数,np为种群规模;
寿命在个体生成时被赋值,个体的寿命每进化一代寿命降低1,当某个体的寿命降为0时,则认为此个体无继续进化的能力,淘汰此个体并复制精英个体,使算法寻优能力进一步加强,加快收敛速度,根据双线性分配策略分配寿命值,如式(1)、(2)所示;
其中,minfit、maxfit和avgfit分别表示当前种群适应值的最小值、最大值和平均值,lfmin和lfmax分别代表寿命的最小值和最大值,lf∈(0,100),这种分配策略利用当前种群的进化信息以及个体自身特性信息,加大具有相近适应值个体的寿命值差异。
本发明的进一步改进,所述步骤二详细步骤如下;
变异方式为:
vi,g+1=xr1,g+f*(xr2,g-xr3,g)(3)
其中,r1≠r2≠r3≠i,g为代数,f为缩放因子;
缩放因子f较大时,扰动较大,能在更大范围内寻求有潜力的解,有利于保持种群的多样性,f较小时,则对基向量造成的扰动较小,搜索范围较小,提高算法的开发能力,易找到高质量的最优解,因此在寿命较大时,个体适应值较优,采用较小的f,对个体所对应的差分向量进行较小的缩放,使算法在此较优个体的附近继续进化,容易求得更好的解,缩放因子的取值如式(4)所示;
其中fmax和fmin分别为缩放因子的最大值和最小值,lf(i)为个体的寿命值,f(i)为个体的缩放因子。
本发明的进一步改进,所述步骤三详细步骤如下;
交叉操作的方程为:
其中,j=1,2,…,d,jrand为[1,d]内随机选择的整数,cr∈(0,1)为交叉率;
变异率cr越大就代表着新生个体被引入变异个体越多,能够增加种群的多样性,同时也会增加种群的收敛速度,cr较小时,算法的收敛速度比较慢,但是成功搜索到最优解的概率增加,会增加算法的鲁棒性,因此为了在算法后期增加种群多样性和收敛速度,随着寿命值的降低,cr减小,交叉率取值如式(6)所示。
其中crmax和crmin分别代表交叉率的最大值和最小值,cr(i)为个体的交叉率。
本发明的进一步改进,所述步骤四详细步骤如下;
根据目标向量xi,g与试验向量ui,g+1的适应值f(x)来选择最优个体;对于最小化问题,选择操作的公式为:
本发明基于改进差分进化算法的非线性系统参数辨识方法,具有如下优点:
1)本发明差分进化算法de的原理简单,受控参数少,实施随机、并行、直接的全局搜索,易于理解和实现。
2)本发明改进差分进化算法的最优解和收敛精度比基本的差分进化算法更精确。
3)本发明改进的差分进化算法对非线性系统的适应性好,对非线性模型参数的辨识误差低、精确度提高。
附图说明
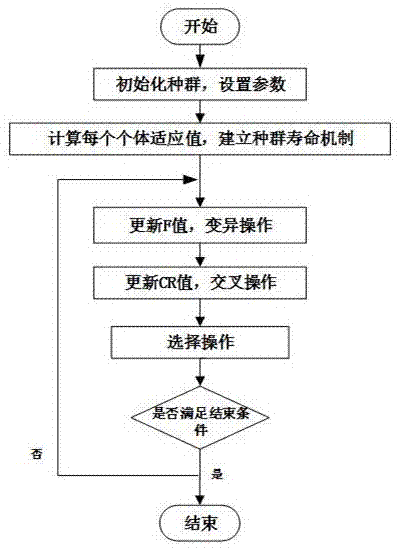
图1为本发明改进算法流程图;
图2为本发明参数辨识结果示意图;
图3为本发明相同输入下实际输出与辨识估计输出值对比图。
具体实施方式
下面结合附图与具体实施方式对本发明作进一步详细描述:
本发明提供基于改进差分进化算法的非线性系统参数辨识方法,将动态调整缩放因子和交叉率的方法结合在一起,提出新的改进方法。根据个体的寿命值大小,动态调整缩放因子和交叉率,在算法初期保持多样性来避免早熟收敛,在后期保留优质解,加快收敛速度,最终使非线性系统的辨识参数更准确、辨识速度更快。
本发明de算法是一种基于种群的智能优化方法,借助于种群个体之间的差分信息对个体形成扰动来搜索整个种群空间,并利用贪婪竞争机制选择优化,寻求最优解。改进的de算法的基本步骤如图1所示。具体步骤如下:
(1)初始化种群。在问题的可行解空间生成随机初始化种群:xi=(xi,1,xi,2,...,xi,d),i=1,2,…,np。其中d为维数,np为种群规模。
寿命在个体生成时被赋值,个体的寿命每进化一代寿命降低1,当某个体的寿命降为0时,则认为此个体无继续进化的能力,淘汰此个体并复制精英个体,使算法寻优能力进一步加强,加快收敛速度。根据双线性分配策略分配寿命值,如式(1)、(2)所示。
其中,minfit、maxfit和avgfit分别表示当前种群适应值的最小值、最大值和平均值、。lfmin和lfmax分别代表寿命的最小值和最大值。lf∈(0,100)。这种分配策略可以利用当前种群的进化信息以及个体自身特性信息,加大具有相近适应值个体的寿命值差异。
(2)变异操作。de通过差分策略实现个体变异,将两个任意个体的差分向量加到另一个随机的个体向量上成为变异向量。常用的变异方式为:
vi,g+1=xr1,g+f*(xr2,g-xr3,g)(3)
其中,r1≠r2≠r3≠i,g为代数,f为缩放因子。
缩放因子f较大时,扰动较大,能在更大范围内寻求有潜力的解,有利于保持种群的多样性。f较小时,则对基向量造成的扰动较小,搜索范围较小,提高算法的开发能力,易找到高质量的最优解。因此在寿命较大时,个体适应值较优,采用较小的f,对个体所对应的差分向量进行较小的缩放,使算法在此较优个体的附近继续进化,容易求得更好的解。缩放因子的取值如式(4)所示。
其中fmax和fmin分别为缩放因子的最大值和最小值。lf(i)为个体的寿命值。f(i)为个体的缩放因子。
(3)交叉操作。通过交叉操作生成试验向量。通过随机选择,使试验向量至少有一个分量由变异向量提供。交叉操作的方程为:
其中,j=1,2,…,d,jrand为[1,d]内随机选择的整数,cr∈(0,1)为交叉率。
变异率cr越大就代表着新生个体被引入变异个体越多,能够增加种群的多样性,同时也会增加种群的收敛速度。cr较小时,算法的收敛速度比较慢,但是成功搜索到最优解的概率增加,会增加算法的鲁棒性。因此为了在算法后期增加种群多样性和收敛速度,随着寿命值的降低,cr减小。交叉率取值如式(6)所示。
其中crmax和crmin分别代表交叉率的最大值和最小值。cr(i)为个体的交叉率。
(4)选择操作。de采用“贪婪”选择策略,根据目标向量xi,g与试验向量ui,g+1的适应值f(x)来选择最优个体;对于最小化问题,选择操作的公式为:
为进一步说明改进算法的准确性和快速性,结合实施例对改进的算法在matlab下进行仿真验证。
实施例1:
为验证算法的有效性,利用多个基准函数进行测试。测试函数为schwefel,ackley,rastrigin,alpine,griewank函数,最优解均为0。种群数目设置为维数的10倍,其余参数设置如下:基本de:f=0.6,cr=0.9,deafcr的参数为:fmax=1,fmin=0.2,crmax=1,crmin=0.8。表1给出了这两种算法对30维的测试函数的优化结果,对每一个函数运行30次,最大迭代次数为1000次.
表格1算法测试结果
由表1的测试数据看出deafcr算法在保持算法稳定性的同时,比de算法的最优解、平均值都小,因此deafcr算法搜索到的最优解和收敛精度比基本de算法好。
实施例2:
为试验改进差分进化算法在非线性定长系统的辨识效果,本专利选取传递函数模型和hammerstein模型进行辨识与仿真研究。结果与遗传(ga)算法的和自适应变异率和动态交叉变异率进化差分算法(mcde)进行对比分析,验证算法的有效性。
二阶惯性环节加纯时延的传递函数模型如式(8)所示。
待辨识的参数为增益系数k、时间常数t1、t2和延迟时间τ。参数的搜索范围0≤k≤4,0≤t1≤4,0≤t2≤4,0≤τ≤2,采样周期为0.1s,采样数据为100个,输入为随机输入u,采样时间0≤t≤9.9,用lsim函数求输出输出信号y,y=lism(g,u,t)。
仿真实验中的参数设置为:维数d=4,种群规模np=40,迭代次数为200次,其余参数与函数测试时相同。仿真30次,取平均值。仿真结果如表2所示。
表格2传递函数模型辨识结果对比
由图2-3进的de算法精确度较高。
实施例3:
hammerstein模型是由一个无记忆非线性增益环节和线性子系统串联而成,在有色噪声干扰下的模型可描述为:
a(q-1)y(k)=b(q-1)x(k)+c(q-1)w(k)(9)
考虑如式(9)的hammerstein模型,噪声w(k)为均值为0,方差为0.01的高斯白噪声。输入u(k)为均值为0,方差为0.2的高斯白噪声。取:a(q-1)=1-1.5q-1+0.7q-2,b(q-1)=q-1+0.5q-2,c(q-1)=1+1.5q-1,x(k)=u(k)+0.5u2(k)+0.3u3(k)+0.1u4(k)。
因此该模型的待辨识参数为8个,a1、a2、b1、b2、c1、r2、r3、r4,维度为8,种群规模np为80,迭代次数为1000次,参数搜索范围为[-2,2],其余参数设置同上。仿真结果如表3。
表格3hammerstein模型参数辨识结果对比
由表3可以看出三种算法对传递函数模型的辨识都有较高的精度。但对于辨识hammerstein模型来说,本专利提出的改进de算法更准确。由表3可知,改进的de算法对非线性参数r4的估计值比mcde算法精度提高7.5%,比ga算法对参数c1的估计精确度提高82.72%。因此专利提出的改进算法对非线性系统辨识的误差更低,精度更高,证明该方法的可行性和有效性。
以上所述,仅是本发明的较佳实施例而已,并非是对本发明作任何其他形式的限制,而依据本发明的技术实质所作的任何修改或等同变化,仍属于本发明所要求保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!