一种支持非结构化数据的采集分析系统和方法与流程
本发明涉及数据处理技术,尤其是一种支持非结构化数据的采集分析系统和方法。
背景技术:
目前,依赖于大数据技术的高速发展,越来越多的web应用被用户所使用,使得web应用数据量的快速增长。随着web应用吞吐量的增大,传统的数据存储方式已经不能满足当前的需求,因而促使了大数据量存储技术的产生。但是,目前大多数的web分析系统采用结构化的数据库,这些系统都不能够方便地对非结构化的数据进行存储和分析,其要求web应用对采集的数据进行预处理,输出与数据库结构相同的数据格式,增大了web应用的负载压力。因此有必要对现有技术进行改进。
技术实现要素:
为解决上述技术问题,本发明的目的在于:提供一种支持非结构化数据的采集分析系统和方法。
本发明所采取的第一种技术方案是:
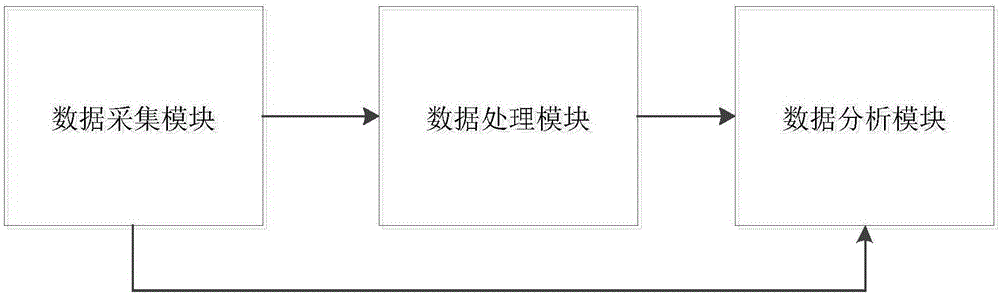
一种支持非结构化数据的采集分析系统,包括:
数据采集模块,用于获取web页面上传的数据作为第一数据,对所述第一数据进行校验,得到第二数据,将第二数据存入非结构化数据库中;
数据处理模块,用于从非结构化数据库中抽取第二数据,对第二数据进行数据清洗,得到第三数据,然后将第三数据存入结构化数据库中;
数据分析模块,用于对非结构化数据库中的数据或者结构化数据库中的数据进行分析处理。
进一步,所述非结构化数据库为mongodb数据库,所述结构化数据库为mysql数据库。
进一步,所述数据采集模块包括数据录入单元,所述数据录入单元用于采集用户输入的数据作为第一数据。
进一步,所述非结构化数据库中以文档作为存储单位。
进一步,所述对第二数据进行数据清洗,得到第三数据,其具体包括:
获取结构化数据库的第一表结构;
获取第二数据的第二表结构;
根据第一表结构,删除第二表结构中的无效字段的数据,得到第三数据;所述无效字段是指第一表结构中不存在的字段。
进一步,所述数据处理模块按照设定周期从非结构数据库中抽取第二数据。
本发明所采取的第二种技术方案是:
一种支持非结构化数据的采集分析方法,包括以下步骤:
获取web页面上传的数据作为第一数据;
对所述第一数据进行校验,得到第二数据;
将第二数据存入非结构化数据库中;
从非结构化数据库中抽取第二数据;
对第二数据进行数据清洗,得到第三数据;
将第三数据存入结构化数据库中。
进一步,所述非结构化数据库为mongodb数据库,所述结构化数据库为mysql数据库。
进一步,所述对第二数据进行数据清洗,得到第三数据,其具体包括:
获取结构化数据库的第一表结构;
获取第二数据的第二表结构;
根据第一表结构,删除第二表结构中的无效字段的数据,得到第三数据;所述无效字段是指第一表结构中不存在的字段。
进一步,所述从非结构化数据库中抽取第二数据,其具体为:
按照设定的周期从非结构化数据库中抽取第二数据。
本发明的有益效果是:本发明采用非结构数据库对原始数据进行存储,然后逐步将原始数据处理为结构化的数据并存储在结构化数据库中,使得本系统可以有助于减轻web应用的负载压力,提升非结构化数据处理的效率。
附图说明
图1为本发明一种具体实施例的支持非结构化数据的采集分析系统的模块框图;
图2为本发明一种具体实施例的支持非结构化数据的采集分析方法的流程图。
具体实施方式
下面结合说明书附图和具体的实施例对本发明进行进一步的说明。
参照图1,本实施例公开了一种支持非结构化数据的采集分析系统,该系统包括:
数据采集模块,用于获取web页面上传的数据作为第一数据,对所述第一数据进行校验,得到第二数据,将第二数据存入非结构化数据库中。在本模块中,由于web页面上传的数据可能存在类型错误或者数据丢失等问题,因此在将数据库存储非结构化数据库中前需要对第一数据进行校验。所有的数据上传时系统都可以获得数据上传的时间和数据类型等相关信息,系统需要对这些数据进行规范化后存储起来。当然,如果系统发现web页面上传的数据存在问题,也可以由人工修正。其中,非结构化数据库以文档作为单位对数据进行储存。在大部分的场合中非结构化数据库中存有的数据并不能直接使用,因此需要逐步对这些数据进行结构化处理。
数据处理模块,用于从非结构化数据库中抽取第二数据,对第二数据进行数据清洗,得到第三数据,然后将第三数据存入结构化数据库中。本模块主要用于逐步从非结构化数据库中抽取数据,然后将这些抽取出来的数据结构化,再将完成结构化的数据存入结构化数据库中。本实施例中的抽取,可以是指有规律的抽取,例如,按照文档存入的先后顺序,每次处理10个文档。
数据分析模块,用于对非结构化数据库中的数据或者结构化数据库中的数据进行分析处理。所述分析处理包括读取、统计、挖掘或者分类等。在本模块中,如果系统需要用格式化的数据进行统计,可以直接从结构化数据库中抽取数据。如果系统需要对原始数据进行数据挖掘,也可以直接从非结构化数据库中调取数据来进行数据挖掘。
作为优选的实施例,所述非结构化数据库为mongodb数据库,所述结构化数据库为mysql数据库。由于第一数据往往并不是规范的excel文件,因此对于结构化数据库,其并不能有效地处理这一类文件。本实施例采用mongodb数据库作为非结构化数据库,能够对这一类非结构化的数据文件进行更加高效地存储。鉴于mongodb数据库的弱数据模式,添加一个新的字段对于旧表格并没有任何影响。对于非结构化的数据,mongodb数据库的处理速度非常快;所以采用mongodb数据库可以实现数据存储层的灵活水平扩展。
作为优选的实施例,所述数据采集模块包括数据录入单元,所述数据录入单元用于采集用户输入的数据作为第一数据。当然,在本实施例中,系统也可以支持人工导入的数据,作为更多的数据来源。
作为优选的实施例,所述对第二数据进行数据清洗,得到第三数据,其具体包括:
获取结构化数据库的第一表结构;
获取第二数据的第二表结构;
根据第一表结构,删除第二表结构中的无效字段的数据,得到第三数据;所述无效字段是指第一表结构中不存在的字段。
本实施例将非结构化数据中的无效字段进行去除,使得非结构化数据符合结构化数据库的数据格式。
作为优选的实施例,所述数据处理模块按照设定周期从非结构数据库中抽取第二数据。其中,本实施例通过etl定期同步非结构化数据库中的数据到结构化数据库中,当然,所述同步包括清洗过程。通过定期的处理,可以保证非结构数据库中的非结构化数据能够被及时处理成结构化的数据。
参照图2,一种支持非结构化数据的采集分析方法,包括以下步骤:
s1、获取web页面上传的数据作为第一数据。
s2、对所述第一数据进行校验,得到第二数据。
s3、将第二数据存入非结构化数据库中。
步骤s1至步骤s3的主要功能是将原始数据进行校验,然后将经过校验的数据存入非结构数据库中。由于web页面上传的数据可能存在类型错误或者数据丢失等问题,因此在将数据库存储非结构化数据库中前需要对第一数据进行校验。所有的数据上传时系统都可以获得数据上传的时间和数据类型等相关信息,系统需要对这些数据进行规范化后存储起来。当然,如果系统发现web页面上传的数据存在问题,也可以由人工修正。其中,非结构化数据库一般以文档作为单位对数据进行储存。在大部分的场合中非结构化数据库中存有的数据并不能直接使用,因此需要逐步对这些数据进行结构化处理。
s4、从非结构化数据库中抽取第二数据。
s5、对第二数据进行数据清洗,得到第三数据。
s6、将第三数据存入结构化数据库中。
步骤s4至步骤s6主要功能在于逐步从非结构化数据库中抽取数据,然后将这些抽取的数据结构化,再将完成结构化的数据存入结构化数据库中。本实施例中的抽取,可以是有规律的抽取,例如,按照文档存入的先后顺序,每次处理10个文档。
作为优选的实施例,所述非结构化数据库为mongodb数据库,所述结构化数据库为mysql数据库。
作为优选的实施例,所述步骤s5具体包括:
s51、获取结构化数据库的第一表结构;
s52、获取第二数据的第二表结构;
s53、根据第一表结构,删除第二表结构中的无效字段的数据,得到第三数据;所述无效字段是指第一表结构中不存在的字段。
本实施例将非结构化数据中的无效字段进行去除,使得非结构化数据符合结构化数据库的数据格式。
作为优选的实施例,所述从非结构化数据库中抽取第二数据,其具体为:
按照设定的周期从非结构化数据库中抽取第二数据。
对于上述方法实施例中的步骤编号,其仅为了便于阐述说明而设置,对步骤之间的顺序不做任何限定,实施例中的各步骤的执行顺序均可根据本领域技术人员的理解来进行适应性调整。
以上是对本发明的较佳实施进行了具体说明,但本发明并不限于所述实施例,熟悉本领域的技术人员在不违背本发明精神的前提下还可做作出种种的等同变形或替换,这些等同的变形或替换均包含在本申请权利要求所限定的范围内。
- 还没有人留言评论。精彩留言会获得点赞!