一种基于大数据的智能分析报告自动生成系统的制作方法
本发明属于基于各项智能化信息技术手段研发的报告智能分析且自动生成系统技术领域,尤其涉及大数据挖掘分析技术、数据交换与共享技术、碎片标引与索引技术、知识图谱技术的智能分析报告自动生成系统。
背景技术:
传统智能数据分析挖掘bi项目中最常见、基础的数据加工行为。构建数据仓库期间,各类业务系统的数据需要经过严格的etl过程,才能够进入到数据仓库中,进而为后续的数据展现、分析提供支撑。通常,由于企业的各业务系统数据口径不一致,使得bi项目必须实施etl工作,否则在含糊、不准确的数据上进行各种数据行为是徒劳的、没有意义的。
在多介质跨媒体的数字时代,传统的数据媒介无法满足内容组织和服务过程中报告编写者远程协同写作、需求个性化定制、智能识别、编辑自动化等需求。因此,打破传统流程和概念的约束,建立一个基于内容对象的、协同工作的、“一次制作、多元发布”的动态报告生成机制成为一个关键的技术。
技术实现要素:
为解决上述技术问题,本发明的目的是提供一种基于大数据的智能分析报告自动生成系统。
本发明的目的通过以下的技术方案来实现:
一种基于大数据的智能分析报告自动生成系统,包括:大数据资源池、知识图谱系统、模型引擎系统及xml专家观点库自动推送系统;所述
大数据资源池,用于汇聚不同数据来源的数据资源和知识资源,并根据主题智能推送关联数据与关联知识;
知识图谱系统,基于知识逻辑和属性关系构建,并根据主题词自动关联与主题词相关的知识,实现智能检索与问答;
模型引擎系统,用于关联对应与主题词相关的应用领域涉及到的分析模型,实现对指标数据的深入分析;
xml专家观点库自动推送系统,用于自动关联与主题词相对应,自动推送解决问题的知识点,并自动生成智能型报告。
与现有技术相比,本发明的一个或多个实施例可以具有如下优点:
基于大数据生成的报告从内容来看客观、科学,从来源来看,数据和知识标注来源,能追溯,从生成速度来看,自动生成,效率加快。
附图说明
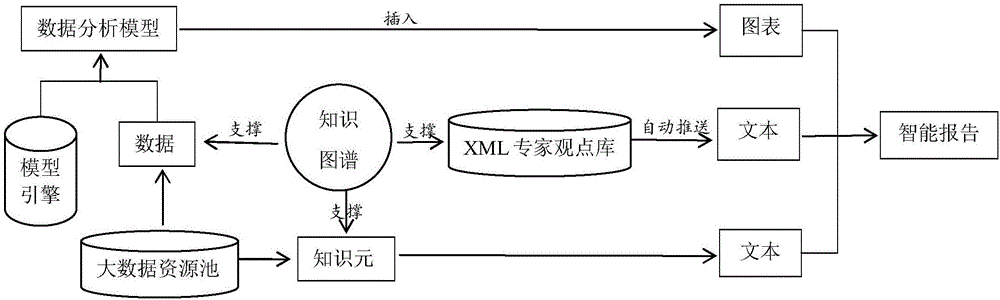
图1是基于大数据的智能分析报告自动生成系统结构图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合实施例及附图对本发明作进一步详细的描述。
如图1所示,为基于大数据的智能分析报告自动生成系统结构,包括:大数据资源池、知识图谱系统、模型引擎系统及xml专家观点库自动推送系统;所述
大数据资源池,用于汇聚不同数据来源的数据资源和知识资源,并根据主题智能推送关联数据与关联知识;
知识图谱系统,基于知识逻辑和属性关系构建,并根据主题词自动关联与主题词相关的知识,实现智能检索与问答;
模型引擎系统,用于关联对应与主题词相关的应用领域涉及到的分析模型,实现对指标数据的深入分析;
xml专家观点库自动推送系统,用于自动关联与主题词相对应,自动推送解决问题的知识点,并自动生成智能型报告。
上述大数据资源池:使用etl工具将分布的、异构数据源中的数据如关系数据、平面数据文件等通过自然语言处理技术、人工智能、数据挖掘、数据处理、知识碎片化技术抽取到临时中间层后进行清洗、转换、集成,最后加载到数据仓库或数据集市中,成为联机分析处理、数据挖掘的基础。通过分类、估计、预测、相关性分组或关联规则、聚类、描述和可视化、复杂数据类型(text,web,图形图像,视频,音频等)挖掘,将数据存储进入关系数据库、nosql、sql等。
知识图谱系统:调用知识图谱与指标本体系统,以自然语言为基础建立起来的知识网络体系构建的知识图谱,展示与知识元相关的数据之间的关联关系和揭示多维语义关系。通过将零散分布的数据形成知识网格,融合生产数据、科研数据、市场数据等资源,深入发掘数据的整体性与关联性。知识图谱包括基础资源层、知识单元层、知识组织层和知识表达层。通过将不同来源的数据进行知识抽取,形成知识单元实体,再将抽取出的实体进行知识融合,发掘实体之间的关联关系,可从语义的层面来实现知识的组织,发掘知识间隐含的关系,形成知识网络。
上述知识图谱系统从结构化、半结构化与非结构化数据出发,采用自动或半自动技术,从原始数据库和第三方数据库中提取知识事实,并将提取的知识事实存入知识库的数据层和模式层。
上述将提取的知识事实存入知识库数据层和模式层的过程包括:知识抽取、知识表示、知识融合、知识推理四个过程,且每一次更新迭代均包含这四个阶段。
模型引擎系统:调用模型引擎,利用统计分析方法,如假设检验、显著性检验、差异分析、相关分析、t检验、方差分析、卡方分析、偏相关分析、距离分析、回归分析、简单回归分析、多元回归分析、逐步回归、回归预测与残差分析、logistic回归分析、曲线估计、因子分析、聚类分析、主成分分析、因子分析、快速聚类法与聚类法、判别分析、对应分析、多元对应分析(最优尺度分析)、bootstrap技术等构建实用模型。
上述模型引擎系统基于cnki农业领域权威论文资源,根据研究目的、内容、数据类型的不同,利用人工智能技术构建各类分析模型,形成模型引擎。
xml专家观点库自动推送系统:利用碎片标引与索引技术除了对整本或整篇内容进行元数据标注外,还要更详细地对数字出版资源各个章节的知识分别单独标引和索引。经过标引和索引后的碎片知识更容易被读者获取和利用,其生命周期要比整本书的更长、更有效。数字内容碎片化组织主要流程包括:维持传统出版内容,保存作者稿件、终审稿件、终排文件,并转换终排文件按照种、册、件、篇、章以及节模式进行组织;将形成的篇、章、节内容按学科、中图分类、主题等方式分类,将形成的分类按照某一学科、某一方向、某一行业构建知识体系;将知识体系再拆分成不同方向的知识单元,知识单元拆分成知识点,最后拆分成主题词、关键词;通过关键词间语义关系将知识点进行动态关联,形成网状互联关系;将内容按需重组,采用多形态同步生成技术实现动态出版。
上述xml专家观点库自动推送系统由知识库管理系统、独立的知识库、数据库、推理机、解释器、知识获取模块和用户界面组成;所述
知识库管理系统,用于对知识库中的知识进行检查和检索;
数据库,用于存储原始数据及推理机在推理中得到的中间信息;
解释器,用于对求解过程做出说明并提供解决问题的对策;
知识获取模块,用于将获取的相关知识转入到知识库;
用户界面,负责接受用户输入的信息并转化为系统内部表示形式,并提交到相应模块进行处理,然后将系统输出的内部信息转化为用户可以接受的表现形式返还给用户。
上述xml专家观点库自动推送系统中,所解决问题的知识点包括现状分析、原因探索、对策建议与展望预测知识资源等。
碎片化解决以后,复用与重组是动态数字出版的关键技术之一。传统的内容管理可以管理碎片化的内容,但是无法管理碎片化内容的复用和重组规则,特别是动态的重组,需要实现申请请求、组合、输出等一系列标准化的动态重构。
对于碎片化的内容和整体化、格式化的文件,必须要有一个检查海量文件存储后是否损坏的方法,然后对于损坏的部分进行备份和修复,建立海量文件特征管理,以便于检查、管理、修复,这是目前数字内容检查及复用技术中的关键。
基于对内容的收集以及碎片化和重组的研究基础,本文设计了一个内容动态重组和按需出版平台。平台总体技术框架路线按业务流程、功能及特点,分为相对独立的三个层次:数据服务层、数据管理层和数据获取层。
数据服务层主要包括多渠道数字出版服务系统、移动阅读系统。数据管理层主要包括数字资源管理系统、数据验证管理、海量数据特征处理等模块。数据获取层主要包括在线出版编纂系统、作者、编辑、专家标引工具、基于互联网的科技符号以及图形的复杂编辑工具等。
其中,数据管理层主要实现对于出版社数字内容资源,包括书报刊、篇章节、知识点、音视频、动画以及图片等多媒体资源的集中加工处理、资源管理和数字内容输出服务,分为内容存储管理、通用组件管理、内容整理管理、逻辑内容库管理及内容展现管理等主要功能。
①内容存储管理:将各类数字内容存入统一内容管理平台,然后通过内容碎片化处理,把内容按章节、图片等进行分割,并在分割后进行语义化标注,将处理后的结果存入碎片内容存储平台。②通用组件管理:系统将对内容的描述信息(属性标签)进行统一管理,并管理各类内容间的关联信息,同时,系统将为管理的内容提供全文搜索引擎,对全部内容进行统一检索。③内容整理管理。提供了语义引擎,帮助加工人员对数字内容进行标注;同时提供了内容标注工具,该工具帮助把pdf文档分割为章节与图片,并为切割后的碎片化内容添加语义标签;内容检索系统提供了对不同层次内容的检索能力,并将检索到的内容按权重排序。编辑个人空间提供了编辑与作者积累和管理个人内容的工具。④内容展现管理。数字内容经过整理后,会形成各种逻辑内容库,如原始素材库、图片库、文章库、音视频库等。
虽然本发明所揭露的实施方式如上,但所述的内容只是为了便于理解本发明而采用的实施方式,并非用以限定本发明。任何本发明所属技术领域内的技术人员,在不脱离本发明所揭露的精神和范围的前提下,可以在实施的形式上及细节上作任何的修改与变化,但本发明的专利保护范围,仍须以所附的权利要求书所界定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!