基于Spark大数据平台的邻域密度不平衡数据混合采样方法与流程
本发明属于计算机数据挖掘、计算机信息处理技术领域。
背景技术:
“大数据”在物理学、生物学、环境生态学等领域以及军事、金融、通讯等行业存在已有时日,却因为近年来互联网和信息行业的发展而引起人们关注。大数据作为云计算、物联网之后it行业又一大颠覆性的技术革命。云计算主要为数据资产提供了保管、访问的场所和渠道,而数据才是真正有价值的资产。企业内部的经营交易信息、互联网世界中的商品物流信息,互联网世界中的人与人交互信息、位置信息等,其数量将远远超越现有企业it架构和基础设施的承载能力,实时性要求也将大大超越现有的计算能力。如何盘活这些数据资产,使其为国家治理、企业决策乃至个人生活服务,是大数据核心议题,也是云计算内在的灵魂和必然的升级方向。
数据挖掘是从大量的、不完全的、有噪声的、模糊的、随机的数据中提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。随着信息技术的高速发展,人们积累的数据量急剧增长,动辄以tb计,如何从海量的数据中提取有用的知识成为当务之急。数据挖掘就是为顺应这种需要应运而生发展起来的数据处理技术。是知识发现的关键步骤。数据挖掘的任务主要是关联分析、聚类分析、分类、预测、时序模式和偏差分析等。数据挖掘技术是一个年轻且充满希望的研究领域,商业利益的强大驱动力将会不停地促进它的发展.每年都有新的数据挖掘方法和模型问世,人们对它的研究正日益广泛和深入。尽管如此,数据挖掘技术仍然面临着许多问题和挑战:如数据挖掘方法的效率亟待提高,尤其是超大规模数据集中数据挖掘的效率;开发适应多数据类型、容噪的挖掘方法,以解决异质数据集的数据挖掘问题;动态数据和知识的数据挖掘;网络与分布式环境下的数据挖掘等;另外,近年来多媒体数据库发展很快,面向多媒体数据库的挖掘技术和软件今后将成为研究开发的热点。
不平衡数据问题,即数据集的类间分布不平衡的一系列数据,是“分类型数据挖掘”在现实世界很常见的一类问题,在有些常规的算法中,这种不平衡数据问题会带来算法失效的结果。例如:在使用决策树算法进行分类的时候,不平衡数据问题会使得树无法继续生长,当然,通过调整阈值或设定树的最小层数也可以强制使树继续生长,但对于大量的数据而言,这种做法将失效;在有些算法中,不平衡数据问题会导致分划面的位置过于偏向于正类点的位置,例如:在支持向量机方法中,以线性支持向量机为例,如果对于正负类数据点采用同样的惩罚系数的话,可能最终结果是分化面基本上把几乎所有的正类点和负类点都划在分划面的一侧,使得最终的结果都为负类点。因此使用采样技术对数据先进行预处理,使得数据类间的不平衡度有效减少,可有效降低分类器失效的可能性。采样可以分为欠采样和过采样两类。欠采样主要是通过适当的方法规则来降低训练集中多数类的数据,使训练集的类间比例趋于平衡;过采样则与之相反,通过适当的方法规则来增加训练集中的少数类数据,使训练集的类间比例趋于平衡。
在生物学方面,脑电信号的大数据研究具有重大意义,脑电信号是人体所携带的生物电信号,能够记录大脑神经元活动信息。脑电信号必须取自活体,天然支持活体检测功能,同时,由于任何人都无法模仿他人的思维,且人在受胁迫、精神紧张时的脑电信号与平静状态存在差异,因而釆用脑电信号做身份识别具有极高的安全性,是对传统生物特征识别系统的一个重要补充。然而,脑电信号非常微弱,极易受到各种环境因素及个体因素的干扰,对脑电身份识别系统的性能产生严重影响。现有的脑电信号预处理技术存在诸多局限,如只适于处理多电极脑电信号、分解过程耗时缺乏实际指导意义、去噪过程需要人工干预等。同时脑电信号数据也同样存在数据分布不平衡的问题,因此结合不平衡数据问题的研究,去进一步研究脑电信号数据分析,也具有重要的意义。
三支决策理论是姚一豫等人在粗糙集和决策粗糙集基础上提出的新的决策理论。2012年10月召开的中国粗糙集与软计算会议上,姚一豫教授系统地介绍了三支决策理论的背景、框架、模型及应用。“三支决策理论与应用”标志着三支决策由粗糙集的三个区间的语义解释逐步发展为在一种不确定或不完整信息条件下的决策理论。许多学者研究和拓展了三支决策理论,并将其应用于多个学科领域。2013年在漳州举办的中国粗糙集与软计算学术会议上还专门开设了三支决策讨论班,来自各地的专家学者讨论了三支决策的研究新进展及其未来的发展方向。三支决策用接受、拒绝和不承诺表示决策的三种类型。
技术实现要素:
本发明旨在解决以上现有技术的问题。提出了一种能适当减少多数类数据数目,且尽可能减少分类器对多数类数据识别率的影响,有效降低新合成的少数类数据对多数类数据泛化空间的影响,保证多数类数据原有的识别率,减缓算法在不平衡数据中对多数类偏好问题,可有效提高性能的算法,同时结合并行化计算框架spark,使数据分布式存储,并行化计算,可极大缩减数据量庞大的建模时间的基于spark大数据平台的邻域密度不平衡数据混合采样方法。本发明的技术方案如下:
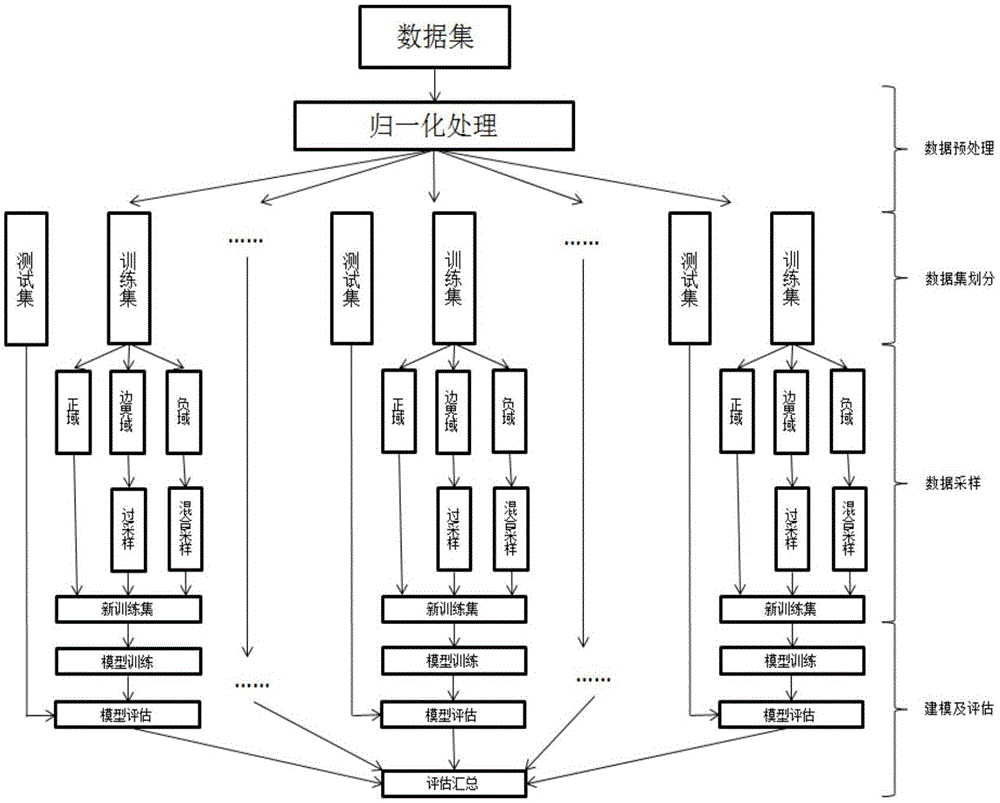
一种基于spark大数据平台的邻域密度不平衡数据混合采样方法,其包括以下步骤:
101、数据初始化步骤:获取数据并进行归一化处理,统一通过spark的textfile方法保存为rdd(弹性分布式数据),再转化为labelpoint对象的数据集,并将labelpoint划分为训练集和测试集;
102、三支决策划分步骤:使用spark算子对rdd进行计算,获取数据集的距离矩阵和邻域半径,再计算邻域密度,结合三支决策理论,将rdd中的数据集划分至正域空间,负域空间和边界域空间;
103、数据采样步骤:使用spark计算每个边界域空间中少数类数据的k近邻集合,结合插值采样方法,生成若干个少数类数据;在负域空间中,对其中的少数类数据采用过采样的方式处理,扩大邻域半径,区分有效少数类数据和噪音数据,并对有效少数类数据进行插值采样处理和删除噪音数据,对其中的多数类数据采用欠采样的方式处理,通过对多数类数据进行排序,确定轮询周期,保留一部分多数类数据;
104、模型评估步骤:调用spark的mllib中的分类器算法进行评估,对比未采样和采样后的结果。
进一步的,所述步骤101具体包括:将数据转化为sparkrdd对象,根据z-score标准化公式:
进一步的,所述通过spark算子转化为labelpoint对象具体包括:采用zipwithindex算子将rdd数据(例如:{0.7245,0.2354,0.6934,0.1842,0.3824,0})转化为labelpoint对象(例如:[0,{0.7245,0.2354,0.69340.1842,0.3824}])。
进一步的,所述训练集和测试集的划分过程包括:依据10折交叉验证,参考数据的类别分布,将labelpoint划分成10份,每次选取一份作为测试集,其余9份作为训练集。
进一步的,步骤102运用spark计算数据的邻域半径,其步骤包括:通过spark的groupby算子对rdd进行分组计算,再将rdd通过sortby算子对距离矩阵集合排序,通过mappartitions算子计算每个分区数据的邻域半径,接着使用filter算子,筛选距离小于邻域半径的数据点,最后通过persist算子将得到的数据邻域集合rdd持久化至内存中;其中邻域半径的计算公式如下:
r=min(δ(si,d))+r×scope(δ(si,d)),0≤r≤1(1)
其中,min(δ(si,d))表示在训练集中数据d和距离其最近数据点之间的距离,r表示权重,scope(δ(si,d))表示在训练集中数据d与其他数据之间距离的取值范围。
进一步的,所述步骤102根据基于邻域密度的三支决策模型将数据集中的数据划分至正域空间,负域空间和边界域空间,具体包括以下步骤:通过spark的groupby算子将对应标号数据进行聚合,再根据mappartitions算子计算每个分区中数据邻域内多数类和少数类数据的数目,从而结合邻域密度公式计算多数类和少数类的邻域密度,参考三支决策理论的决策函数,计算每个数据的决策状态值,根据决策阈值将数据划分至不同区域,区域包括:正域空间,负域空间和边界域空间,,最后调用persist算子将处理完成的rdd定义为ndms_rdd并持久化至内存中。
进一步的,为了实现三支决策,首先需要引入实体的评价函数f(x),也称为决策函数,它的值称为决策状态值,其大小反映实体的好坏程度;其次,引入一对阈值α和β来定义正域、边界域和负域中的事件对象;再次,根据决策状态值和阈值将论域中事件对象划分到正域、边界域和负域中,构造出相应的三支决策规则。
进一步的,所述步骤103具体包括:对labelpoint对象进行混合采样,针对边界域数据,根据k近邻找到对应数据集合,在邻域内插值采样若干少数类数据;针对负域数据,采用fn欠采样方法对多数类数据进行欠采样处理,其过程包括,计算负域中多数类和少数类数据的数目,用于计算欠采样方法保留多数类数据的轮询周期,再计算多数类数据的中心数据点,遍历负域中的多数类数据,求得每个数据和中心数据点的距离集和,对集合进行逆序排列,再遍历逆序集合,结合轮询周期保留部分多数类样本;采用改进的随机过采样方法对少数类数据进行过采样处理。
进一步的,所述采用改进的随机过采样方法对少数类数据进行过采样处理的过程包括:统计负域中每个少数类数据的邻域内包含的少数类数据数目,对于满足少数类数目为零的数据,扩大其邻域半径,再统计其邻域内少数类数据的数目,若满足噪声条件,则删除该少数类数据,否则生成若干合成的少数类样本。
进一步的,步骤104具体包括:调用spark的mllib库中的分类器进行模型训练,将经过混合采样处理的数据合成一个新的训练集,使用cart,adboost和svm作为分类器对采样结果进行建模,并以auc和f-value值对比评估。
本发明的优点及有益效果如下:
本发明提出的混合采样方法结合spark并行计算技术,有效的结合了混合采样算法和邻域三支决策理论,一方面对边界域空间和负域空间混合采样,提高了算法对少数类数据的识别率,剔除了影响多数类有影响的少数类数据,适当保留信息量大的多数类数据,保证了多数类的识别率,提高了算法整体的分类精度;另一方面结合分布式存储数据,并行化处理数据的技术,可大幅提升数据规模庞大的建模效率。
附图说明
图1是本发明提供优选实施例基于spark大数据平台邻域密度不平衡数据混合采样方法流程图;
图2边界域空间过采样原理图;
图3负域空间过采样原理图;
图4负域空间欠采样原理图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、详细地描述。所描述的实施例仅仅是本发明的一部分实施例。
本发明解决上述技术问题的技术方案是:
一种基于spark大数据平台的邻域密度的不平衡数据混合采样方法,包括以下步骤:
将本地的不平衡数据集上传至大数据平台,通过z-score归一化数据,采用hdfs分布式存储,结合分布式计算框架spark读入hdfs中的数据文件保存为rdd,接着并将其保存为labelpoint对象。具体步骤包括:
先通过sparkcontext对象的textfile方法分布式地创建rdd数据集(可供后续过程并行化计算)。再计算每个特征的均值和标准差,使用zipwithindex算子,将rdd对象的数据归一化处理并存为labelpoint对象。最后依据10折交叉验证,参考数据的类别分布,将labelpoint对象划分成10份,每次选取一份作为测试集,其余9份作为训练集。
运用spark计算数据的邻域半径,其步骤包括:通过spark的groupby算子对rdd进行分组计算,将其结果通过sortby算子对距离矩阵集合排序,通过mappartitions算子计算每个分区数据的邻域半径,接着使用filter算子,筛选距离小于邻域半径的数据点,最后通过persist算子将得到的数据邻域集合rdd持久化至内存中。其中邻域半径的计算公式如下:
r=min(δ(si,d))+r×scope(δ(si,d)),0≤r≤1(1)
其中,min(δ(si,d))表示在训练集中数据d和距离其最近数据点之间的距离,r表示权重,scope(δ(si,d))表示在训练集中数据d与其他数据之间距离的取值范围。
根据基于邻域密度的三支决策模型将数据集中的数据划分至正域空间,负域空间和边界域空间,具体包括以下步骤:通过spark的groupby算子将对应标号数据进行聚合,再根据mappartitions算子计算每个分区中数据邻域内多数类和少数类数据的数目,从而结合邻域密度公式计算多数类和少数类的邻域密度,参考三支决策理论的决策函数,计算每个数据的决策状态值,根据决策阈值将数据划分至不同区域(区域包括:正域空间,负域空间和边界域空间),最后调用persist算子将处理完成的rdd定义为ndms_rdd并持久化至内存中。其中邻域三支决策模型定义如下:
定义1:给定实数空间上的非空有限数据集合u,
定义2:给定实数空间上的非空有限数据集合u,
其中,x∈xmax表示x为多数类数据,x∈xmin表示x为少数类数据。
为了实现三支决策,首先需要引入实体的评价函数f(x),也称为决策函数,它的值称为决策状态值,其大小反映实体的好坏程度;其次,引入一对阈值α和β来定义正域、边界域和负域中的事件对象;再次,根据决策状态值和阈值将论域中事件对象划分到正域、边界域和负域中,构造出相应的三支决策规则
定义3:给定实数空间上的非空有限数据集合u={x1,x2,…,xn},
(p)如果f(x)≥α,则x∈pos(x)
(b)如果β<f(x)<α,则x∈bnd(x)(6)
(n)如果f(x)≤β,则x∈neg(x)
式(6)中,
决策(p)表示当f(x)大于α时,将x划分到x正域;决策(b)表示当f(x)小于α且小于β时,将x划分到边界域;决策(n)表示当f(x)小于β时,将x划分到负域。
式(5)中,f(x)的计算公式如下所示:
式(6)中,f(x)表示:在数据x的邻域内,多数类数据和少数类数据的平均密度的比值关系,为了避免分母为0,此处使n,m和
通过spark的filter算子对ndms_rdd进行筛选,选择边界域内少数类数据,然后调用join方法筛选出其与持久化存储在内存中的rdd全集数据的交集rdd,再使用map算子,合成n个新合成的少数类数据,并添加到一个用于存储新合成数据的集合ndata。
通过spark的filter算子,选择负域内少数类数据rdd,然后调用join方法筛选出其与持久化存储在内存中的rdd全集数据的交集,再调用filter算子计算rdd数据邻域内的少数类数据的数量,若其大于零,则在与其最近的数据之间插值采样n个数据;若其等于零,则扩大一倍邻域半径,再统计新邻域内少数类数据的数量,若新邻域内的数量仍为零,则判断为噪音点从rdd中删除,若大于零,则在与其最近的数据之间插值采样n个数据,并添加到用于存储新合成数据的集合ndata。再通过spark的filter算子,选择负域内多数类数据,然后调用join方法筛选出其与持久化存储在内存中的rdd全集数据的交集rdd,计算rdd内每个特征的均值,以均值作为多数类数据的中心点rdd并将中心点rdd广播至每个节点的内存中,通过mappartitions算子计算每个分区的数据与广播中心点rdd的距离,再通过sortby算子对距离排序,最后按照轮询周期保留多数类数据。
最后根据sparkmllib库中的分类器算法对采样过后的训练集进行评估,分类器算法选择cart,adaboost和svm等进行评估。
以下结合附图和具体实例对本发明的实施作进一步具体描述。
将本地的不平衡数据集上传至大数据平台,并通过hdfs分布式存储,再通过sparkcontext对象的textfile方法分布式地创建rdd数据集(可供后续过程并行化计算)。再计算每个特征的均值和标准差,使用zipwithindex算子,将rdd对象的数据归一化处理并存为labelpoint对象。最后依据10折交叉验证,参考数据的类别分布,将labelpoint对象划分成10份,每次选取一份作为测试集,其余9份作为训练集。例如:
一条数据{3.5,4.25,6.24,0.22,12.5,2.4,1},其中,最后一列表示数据的类别标签,前面n-1列表示数据的特征。
转化为rdd{1,[3.5,4.25,6.24,0.22,12.5,2.4]},第一列为数据的类别标签,后面n-1列表示数据的特征。
归一化后的labelpoint{49,1,[0.29,0.67,0.82,0.50,0.42,0.68]},其中,第一列为数据的编号,第二列为类别标签,后面n-2列表示数据的特征。
运用spark计算数据的邻域半径,其步骤包括:通过spark的groupby算子对rdd内的数据根据对应标号进行分组计算,将其结果通过sortby算子对距离矩阵集合排序,通过mappartitions算子计算每个分区数据的邻域半径,接着使用filter算子,筛选距离小于邻域半径的数据点,最后通过persist算子将得到的数据邻域集合rdd持久化至内存中。例如:
计算数据si的邻域半径,若数据si与最近的数据的距离min(δ(si,d))=13.75,数据si与最远的数据的距离max(δ(si,d))=29.39,则数据si的取值范围scope(δ(si,d))=29.39-13.75=15.64,根据邻域半径的计算公式:
r=min(δ(si,d))+r×scope(δ(si,d)),0≤r≤1
若权重r为0.39,则邻域半径r=13.75+0.39*15.64=19.85。
根据基于邻域密度的三支决策模型将数据集中的数据划分至正域空间,负域空间和边界域空间,具体包括以下步骤:通过spark的groupby算子将对应标号数据进行聚合,再根据mappartitions算子计算每个分区中数据邻域内多数类和少数类数据的数目,从而结合邻域密度公式计算多数类和少数累的邻域密度,参考三支决策理论的决策函数,计算每个数据的决策状态值,根据决策阈值将数据划分至不同区域(区域包括:正域空间,负域空间和边界域空间),最后调用persist算子将处理完成的rdd定义为ndms_rdd并持久化至内存中。例如:
计算少数类数据x的邻域密度,需要计算邻域内的多数类数据的数量n0和少数类数据的数量n1,根据定义2中的邻域密度公式:
若n0=2,n1=4,则邻域密度
为了实现三支决策,首先需要引入实体的评价函数f(x),也称为决策函数,它的值称为决策状态值,其大小反映实体的好坏程度;其次,引入一对阈值α和β来定义正域、边界域和负域中的事件对象;再次,根据决策状态值和阈值将论域中事件对象划分到正域、边界域和负域中,构造出相应的三支决策规则。例如:
计算数据x的决策状态值f(x),根据其计算公式:
阈值α和β的计算公式:
若数据x邻域范围内的多数类数据的密度和
α=4/3-(1/2)*((1/2)/4)=31/16,
β=2/5-(1/2)*((1/3)/2)=29/60
由于f(x)∈[β,α],则数据x被换分至边界域空间。
再对数据集进行混合采样。对边界域空间的rdd进行并行化过采样,通过spark的filter算子对ndms_rdd筛选,选择边界域内少数类数据,然后调用join方法筛选出其与持久化存储在内存中的rdd全集数据的交集rdd,再使用map算子,合成n个新的少数类数据,并添加到一个用于存储新合成数据的集合ndata。图2中给出了边界域空间少数类数据的过采样示意图。其中实线圆区域代表边界域空间,实线圆外部代表负域空间。以s1为例对其进行采样。第一步,先搜索距离s1最近的n(n=5)个同类别数据:s2、s3、s4、s5和s6,并合成5个新数据:n1、n2、n3、n4和n5。第二步,判断新合成数据是否属于边界域空间,经计算,n1、n2、n3和n4属于边界域空间,它们不会对负域空间内多数类数据的泛化能力产生影响,故保留;而n5属于负域空间,可能会影响负域空间内多数类数据的泛化能力,需要删除n5。经上述步骤,可适当增加边界域空间内少数类数据的比例,同时有效减少新合成数据对负域空间中多数类数据的影响。
对负域空间的rdd进行并行化的混合采样,通过spark的filter算子,选择负域内少数类数据rdd,然后调用join方法筛选出其与持久化存储在内存中的rdd全集数据的交集,再调用filter算子计算rdd数据邻域内的少数类数据的数量,若其大于零,则在与其最近的数据之间直接插值采样n个数据;若其等于零,则扩大一倍邻域半径,再计算统计新邻域内少数类数据的数量,若新邻域内的数量仍为零,则判断为噪音点从rdd中删除,若大于零,则在与其最近的数据之间直接插值采样n个数据,并添加到用于存储新合成数据的集合ndata。图3中给出负域空间少数类数据过采样示意图。以s1为例,s1的邻域半径是r,在s1邻域内都是多数类数据(m1、m2、m3、m4和m6)。根据公式(7),若s1邻域多数类数据平均密度是
以上这些实施例应理解为仅用于说明本发明而不用于限制本发明的保护范围。在阅读了本发明的记载的内容之后,技术人员可以对本发明作各种改动或修改,这些等效变化和修饰同样落入本发明权利要求所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!