一种基于分数阶离散灰色模型的年用电量预测方法与流程
本发明创造涉及一种年用电量预测方法,尤其是一种基于分数阶离散灰色模型的年用电量预测方法。
背景技术:
电力是人类生存和社会进步不可缺少的重要物质基础。电力发展难以摆脱“缺电—加大电源建设—电力富余—缺电”的大幅度、周期性震荡。随着日益加重的资源紧缺和环境压力,电力和经济的可持续发展已成为社会普遍关注的焦点问题,学者们日益注意到单纯依靠增加电力供给已无法满足经济长期可持续发展的要求,因此如何有效的预测年用电量是一个十分值得研究的问题。
技术实现要素:
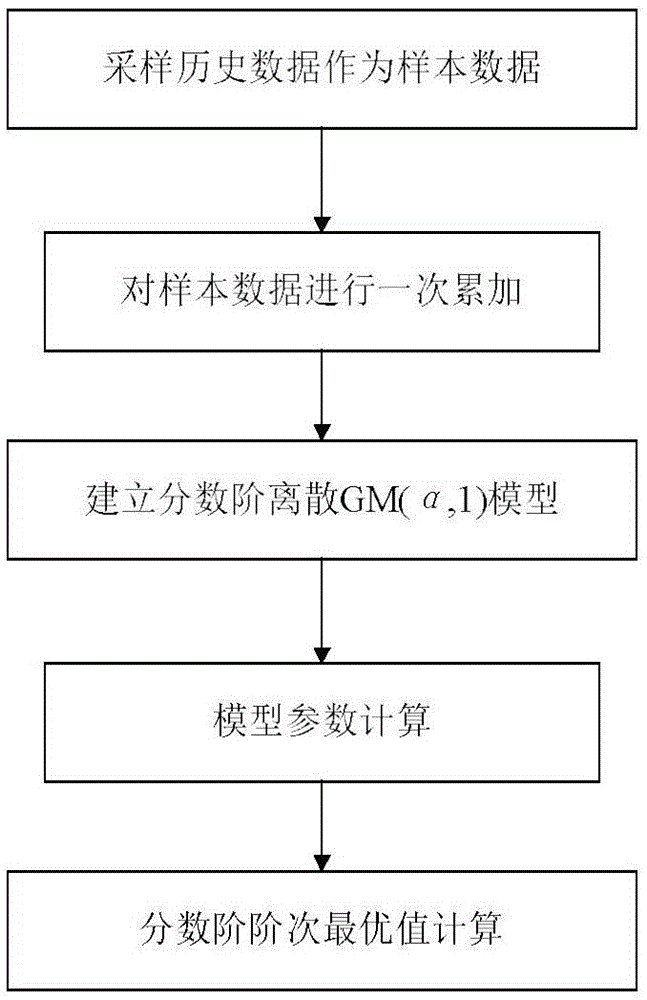
为了解决现有技术存在的问题,本发明提供一种基于分数阶离散灰色模型的年用电量预测方法,步骤为:步骤1、采集年用电量的历史数据作为样本数据;步骤2、对样本数据进行一次累加;步骤3、建立分数阶离散gm(α,1)模型;步骤4、利用最小二乘方法给出模型参数的计算方法;步骤5、利用粒子群优化算法给出模型的分数阶阶次的最优值。本发明提出的分数阶离散gm(α,1)模型,是对离散gm(1,1)模型进行的推广。在模型建立过程中,引入了分数阶差分的概念,有效的提高了gm(1,1)模型对年用电量预测的精度。用分数阶累加运算代替一阶累加运算,避免了分数阶微分方程到差分方程的跳跃,提高了离散gm(1,1)模型的拟合度,从而说明了本发明比离散gm(1,1)模型建模的误差更小,可以广泛地应用到年用电量的预测中。
为了实现上述目的,本发明创造采用的技术方案为:一种基于分数阶离散灰色模型的年用电量预测方法,其特征在于,其步骤为:
步骤1、采集年用电量的历史数据作为样本数据;
步骤2、对样本数据进行一次累加;
步骤3、建立分数阶离散gm(α,1)模型;
步骤3.1、设第k维向量
称x(1)(k)=β1x(1)(k-1)+β2为离散gm(1,1)模型;
其中β1和β2为需要计算的模型参数;
步骤3.2、将离散gm(1,1)模型表示为:
δx(1)(k)=x(1)(k)-x(1)(k-1)=(β1-1)x(1)(k-1)+β2;(4)
步骤3.3、定义分数阶离散gm(α,1)模型为:
δαx(1)(k)=(β1-1)x(1)(k-1)+β2;(5)
其中α为模型的分数阶阶次;
步骤3.4、定义分数阶算子δαx(1)(k)为:
其中j为下标;
步骤3.5、将分数阶差分(6)代入(5)模型中;
步骤3.6、x(1)(k)如(3)所述,分数阶离散gm(α,1)模型表示为:
步骤3.7、参数cj表示为:
步骤4、利用最小二乘方法给出模型参数的计算方法;
步骤5、利用粒子群优化算法给出模型的分数阶阶次的最优值。
所述步骤2中,具体方法为:
步骤2.1、设在时刻k原始数列为n维向量,则可以表示为:
x(0)=(x(0)(1),x(0)(2),…,x(0)(n));(1)
步骤2.2、对非负原始数据x(0)进行一次累加,可得到如下式子:
x(1)=(x(1)(1),x(1)(2),…,x(1)(n));(2)
步骤2.3、根据(2),第k维向量x(1)(k)可以由下式得到:
所述步骤4中,具体方法为:
步骤4.1、定义参数变量β=(β1,β2)t,根据最小二乘算法,给出参数向量的计算
公式:
β=(btb)-1btyα;(10)
其中矩阵b和向量yα的定义如下
其中η(1)(k)的定义为
步骤4.2、当α确定后,根据参数cj的定义(9),参数c1的计算公式为:
c1=β1-1+α;(12)。
所述步骤5中,具体方法为:
步骤5.1、选取如下粒子群的适应度函数:
其中
步骤5.2、设置粒子群的每个粒子群维数为1,当阶次α确定后,根据一阶累加的定义可以获得分数阶离散gm(α,1)模型的解
步骤5.3、设置粒子个数n和迭代次数m,初始化每个粒子群的位置,设置粒子位置的取值范围,即阶次的取值范围[0,αmax],在取值范围[0,αmax]内随机初始化每个粒子的位置,设置粒子速度的取值范围[vmin,vmax],同样地在这个范围内随机初始化粒子的速度信息;
步骤5.4、根据初始化种群的全局最优和每个粒子自身最优,选择(13)中的适应度函数,计算全局最优位置pg,令第i个粒子自身的最优位置pi等于每个粒子群初始化的位置值;
步骤5.5、对于第k次迭代,更新第i个粒子的位置xi(k)和速度vi(k),计算公式如下
vi(k)=wvi(k-1)+c1r1(pi-xi(k-1))+c2r2(pg-xi(k-1));(15)
xi(k)=xi(k-1)+vi(k);(16)
其中c1和c2为学习因子,w为惯性系数,r1和r2是0到1之间的随机数;
步骤5.6、对于第k次迭代,判断每个粒子群的位置和速度是否在取值范围内,如果超出范围,则取边界值,计算第k次迭代时,第i个粒子自身最优位置和全局最优位置;
步骤5.7、当m次迭代过程结束,选取粒子群全局最优位置作为分数阶离散gm(α,1)模型的阶次α。
所述步骤5.2中,分数阶离散gm(α,1)模型的解可通过如下方法确定:
固定g1=1,分数阶离散gm(α,1)模型解为:
其中:
当α=1,c1=β1和cj=0,j≥2时,分数阶离散gm(α,1)模型是离散gm(1,1)模型,因此分数阶离散gm(α,1)模型是离散gm(1,1)模型的推广形式。
本发明创造的有益效果为:
本发明与现有技术相比,而本发明引入了分数阶差分的概念,将离散gm(1,1)模型进行推广,用分数阶累加运算代替一阶累加运算,从而提高灰色预测模型的拟合以及对年用电量的预测精度。同时能够精确的预测电力的年消耗量,有利于各行业合理利用能源,降低能源消耗,提高经济效益;有利于政府制定合理的政策促进经济社会的可持续发展;有利于构造建设资源节约型的和谐社会。
附图说明
图1为本发明提出的一种基于分数阶离散灰色模型的年用电量预测方法的流程示意图。
具体实施方式
一种基于分数阶离散灰色模型的年用电量预测方法,其步骤为:
步骤1、采集年用电量的历史数据作为样本数据。
步骤2、对样本数据进行一次累加:
步骤2.1、设在时刻k原始数列为n维向量,则可以表示为:
x(0)=(x(0)(1),x(0)(2),…,x(0)(n));(1)
步骤2.2、对非负原始数据(1)进行一次累加,可得到如下式子:
x(1)=(x(1)(1),x(1)(2),…,x(1)(n));(2)
步骤2.3、根据(2),第k维向量x(1)(k)可以由下式得到:
步骤3、建立分数阶离散gm(α,1)模型:
步骤3.1、设第k维向量
称x(1)(k)=β1x(1)(k-1)+β2为离散gm(1,1)模型;
其中β1和β2为需要计算的模型参数;
步骤3.2、将离散gm(1,1)模型表示为:
δx(1)(k)=x(1)(k)-x(1)(k-1)=(β1-1)x(1)(k-1)+β2;(4)
步骤3.3、定义分数阶离散gm(α,1)模型为:
δαx(1)(k)=(β1-1)x(1)(k-1)+β2;(5)
其中α为模型的分数阶阶次;
步骤3.4、定义分数阶算子δαx(1)(k)为:
其中j为下标;
步骤3.5、将分数阶差分(6)代入模型(5)中;
步骤3.6、x(1)(k)如(3)所述,分数阶离散gm(α,1)模型表示为:
步骤3.7、参数cj表示为:
步骤4、利用最小二乘方法给出模型参数的计算方法:
步骤4.1、定义参数变量β=(β1,β2)t,根据最小二乘算法,给出参数向量的计算公式:
β=(btb)-1btyα;(10)
其中矩阵b和向量yα的定义如下
其中η(1)(k)的定义为
步骤4.2、当α确定后,根据参数cj的定义(9),参数c1的计算公式为:
c1=β1-1+α;(12)。
步骤5、利用粒子群优化算法给出模型的分数阶阶次的最优值:
步骤5.1、选取如下粒子群的适应度函数:
其中
步骤5.2、设置粒子群的每个粒子群维数为1,当阶次α确定后,根据一阶累加的定义可以获得分数阶离散gm(α,1)模型的解
固定g1=1,分数阶离散gm(α,1)模型解为:
其中:
特别的,当α=1,c1=β1和cj=0,j≥2时,分数阶离散gm(α,1)模型是离散gm(1,1)模型,因此分数阶离散gm(α,1)模型是离散gm(1,1)模型的推广形式;
步骤5.3、设置粒子个数n和迭代次数m,初始化每个粒子群的位置,设置粒子位置的取值范围,即阶次的取值范围[0,αmax],在取值范围[0,αmax]内随机初始化每个粒子的位置,设置粒子速度的取值范围[vmin,vmax],同样地在这个范围内随机初始化粒子的速度信息;
步骤5.4、根据初始化种群的全局最优和每个粒子自身最优,选择(13)中的适应度函数,计算全局最优位置pg,令第i个粒子自身的最优位置pi等于每个粒子群初始化的位置值;
步骤5.5、对于第k次迭代,更新第i个粒子的位置xi(k)和速度vi(k),计算公式如下
vi(k)=wvi(k-1)+c1r1(pi-xi(k-1))+c2r2(pg-xi(k-1));(15)
xi(k)=xi(k-1)+vi(k);(16)
其中c1和c2为学习因子,w为惯性系数,r1和r2是0到1之间的随机数;
步骤5.6、对于第k次迭代,判断每个粒子群的位置和速度是否在取值范围内,如果超出范围,则取边界值,计算第k次迭代时,第i个粒子自身最优位置和全局最优位置;
步骤5.7、当m次迭代过程结束,选取粒子群全局最优位置作为分数阶离散gm(α,1)模型的阶次α。
离散gm(1,1)模型是对原始数据进行一阶累加,然后建立以一阶微分方程为白化方程的灰色预测模型,而分数阶离散gm(α,1)模型引入了分数阶差分的概念,其基本思想是用分数阶累加运算代替一阶累加运算以提高灰色预测模型的拟合和年用电量的预测精度。当α=1,c1=β1和cj=0,j≥2时,分数阶离散gm(α,1)模型是离散gm(1,1)模型,因此分数阶离散gm(α,1)模型是离散gm(1,1)模型的推广形式。
以下结合附图对本发明的预测方法进行描述,所举实例只用于解释本发明,并非用于限定本发明的范围。
一种基于分数阶离散灰色模型的年用电量预测方法,其特征在于,包括以下步骤:
步骤1、采集年用电量的历史数据作为样本数据。
步骤2、对样本数据进行一次累加:
选取非负原始数据
x(0)=(x(0)(1),x(0)(2),…,x(0)(n));(1)
对(1)进行一次累加,可得到(1)的一次累加序列为:
x(1)=(x(1)(1),x(1)(2),…,x(1)(n));(2)
其中
步骤3、建立分数阶离散gm(α,1)模型:
设x(1)(k)如(3)所述,称x(1)(k)=β1x(1)(k-1)+β2为离散gm(1,1)模型;
离散gm(1,1)模型还可以表示为:
δx(1)(k)=x(1)(k)-x(1)(k-1)=(β1-1)x(1)(k-1)+β2;(4)
定义分数阶离散gm(α,1)模型为:
δαx(1)(k)=(β1-1)x(1)(k-1)+β2;(5)
分数阶算子δαx(1)(k)为如下形式:
其中:
将分数阶差分(6)代入模型(5)中,可得到如下分数阶离散gm(α,1)模型:
其中参数cj表示为:
步骤4、利用最小二乘方法给出模型参数的计算方法:
定义参数变量β=(β1,β2)t,根据最小二乘算法,给出参数向量的计算公式:
β=(btb)-1btyα,(10)
其中
当α确定后,根据参数cj的定义(9),参数c1的计算公式为:
c1=β1-1+α;(12)。
步骤5、利用粒子群优化算法给出模型的分数阶阶次的最优值:
步骤5.1、选取如下粒子群的适应度函数:
其中
步骤5.2、设置粒子群的每个粒子群维数为1,当阶次α确定后,根据一阶累加的定义可以获得分数阶离散gm(α,1)模型的解
步骤5.3、设置粒子个数n和迭代次数m,初始化每个粒子群的位置,设置粒子位置的取值范围,即阶次的取值范围[0,αmax],在取值范围[0,αmax]内随机初始化每个粒子的位置,设置粒子速度的取值范围[vmin,vmax],同样地在这个范围内随机初始化粒子的速度信息;
步骤5.4、根据初始化种群的全局最优和每个粒子自身最优,选择(13)中的适应度函数,计算全局最优位置pg,令第i个粒子自身的最优位置pi等于每个粒子群初始化的位置值;
步骤5.5、对于第k次迭代,更新第i个粒子的位置xi(k)和速度vi(k),计算公式如下
vi(k)=wvi(k-1)+c1r1(pi-xi(k-1))+c2r2(pg-xi(k-1));(15)
xi(k)=xi(k-1)+vi(k);(16)
其中c1和c2为学习因子,w为惯性系数,r1和r2是0到1之间的随机数;
步骤5.6、对于第k次迭代,判断每个粒子群的位置和速度是否在取值范围内,如果超出范围,则取边界值,计算第k次迭代时,第i个粒子自身最优位置和全局最优位置;
步骤5.7、当m次迭代过程结束,选取粒子群全局最优位置作为分数阶离散gm(α,1)模型的阶次α。
需要说明的是,在步骤5.2中的分数阶gm(α,1)模型的解可通过以下公式获得:
固定g1=1,分数阶离散gm(α,1)模型解为:
其中
下面结合实例对本发明的一种基于分数阶离散gm(α,1)模型的年用电量预测方法进一步详细说明。
为了分析灰色模型的精度,用rpe和mrpe作为评价指标。
本例于中国国家统计局网站选取2007年至2015年实测数据,其中模型需要的各项参数为:
粒子群的粒子个数n=30;
迭代次数m=50;
学习因子c1=1,c2=1;
惯性系数为w=0.9,αmax=6,vmin=-0.5,vmax=0.5;
基于粒子优化算法得到分数阶阶次为α=1.8148;
分数阶离散gm(α,1)模型参数为β1=0.9945和β2=8066.6;
离散gm(1,1)模型的参数β1=1.0864和β2=32460.7。
针对上述参数,给出分数阶离散gm(α,1)模型和离散gm(1,1)模型分别对2007年至2014年中国电力总消耗量进行数据拟合,并且对2015年中国年用电量进行预测,结果如表1所示,相对误差的结果如表2所示。
表1年用电量(亿千瓦小时)
表2相对误差分析(%)
从表2可以看出,对于中国2007年至2014年这8个年用电量的历史数据值,本发明提出的分数阶离散gm(α,1)模型的mrpe小于离散gm(1,1)模型的mrpe,并且基于分数阶离散gm(α,1)模型获得的2015年中国年用电量的预测值rpe明显小于基于离散gm(1,1)的rpe,说明分数阶阶次α的引入可以明显地改善灰色模型的拟合精度和减小预测误差。
- 还没有人留言评论。精彩留言会获得点赞!