一种鲁棒宽度学习系统的制作方法
本发明属于工业过程建模技术领域,具体涉及一种鲁棒宽度学习系统。
背景技术:
复杂工业过程的控制与优化问题一直以来是个热门的研究方向,而建立精确的复杂工业过程的模型是控制与优化的前提与基础。机理建模是建立在对过程的物理、化学机理分析基础之上,推导得出描述操作变量与状态变量及输出变量之间的函数关系式。机理建模能准确地表达变量之间的关系、有效的解释客观现象并且不会出现违背常理的情况,但其建模难度大,建模周期漫长且研究人员需要了解所有相关的理论知识。过去的许多年,基于数据驱动建模技术受到越来越多研究人员的关注,其简单方便的特性显著地提高建模效率。随着人工神经网络的快速发展,一些研究人员将人工神经网络应用于数据驱动建模,得益于人工神经网络的强大的学习能力,基于人工神经网络的数据建模方法得到了快速推广和应用。
随着人工智能越来越受到人们关注,其背后的深度学习神经网络被广泛应用于各种尖端领域,例如模式识别,人脸识别和语音识别等。依靠网络中大量的特征层,深度学习神经网络十分适合处理高维大数据。尽管深度学习神经网络有着强大的学习能力,但其复杂的结构导致其面对众多的调节参数,导致其需要经历漫长的学习过程。而且为了获得更好的学习效果,深度学习神经网络需要大量的高性能计算机的支持。但是实际工业现场空间狭小且环境恶劣,很难安装大量的高性能计算机,况且高性能计算机价格昂贵,大量的使用会导致生产成本的上升,不利于提高企业综合效益。最近,一些学者提出了些新颖的神经网络用于简化训练过程,能有效降低对计算机资源的依赖。
宽度学习系统是一个有效且高效的新型人工神经网络。宽度学习系统充分利用随机向量函数连接网络的优势,在输入层和输出层有直接的连接,使得网络结构扁平化。相较于深度学习神经网络,宽度学习系统结构简单,可调参数更少。相较于深度学习神经网络利用复杂的迭代过程求解网络的连接权值,宽度学习系统通过岭回归算法计算出连接权值。简单的网络结构使得宽度学习系统易于扩展,结合相应的增量的学习算法可以实现模型的快速更新。宽度学习系统在图像识别,时序预测和复杂工业过程建模方面都有一定的应用,均有不错的效果。
但在实际工业生产过程中,由于传感器故障、环境噪声等因素影响,采集到的样本数据中可能存在一定数量的离群点,如果将含有离群的样本作为训练集用于训练宽度学习系统,宽度学习系统的广义逼近能力将受到影响,所建的宽度学习系统模型预测精度无法满足工业要求。因此,现有的宽度学习系统鲁棒性差,无法抑制离群点带来的对建模精度的不利影响的问题,
技术实现要素:
针对上述现有技术存在的问题,本发明提供一种鲁棒宽度学习系统,该系统能提高宽度学习系统的鲁棒性,能有效抑制离群点带来的对建模精度的不利影响的问题,便于建立鲁棒宽度系统模型,以适用于复杂工业过程中相关指标的预测。
为了实现上述目的,本发明提供一种鲁棒宽度学习系统,包括以下步骤:
步骤1:数据预处理,其步骤如下:
步骤1.1:采集训练数据,设训练数据的输入数据矩阵为
其中,n为训练数据的样本个数;
m和c分别对应输入数据和输出数据的变量个数;
步骤1.2:根据公式(1)中的转换函数对训练数据进行线性转换处理,将结果值映射到[-1,1],其中转换函数为:
其中,
x,y代表待转换的数据;
xmin,ymin代表待转换的数据中最小值;
xmax,ymax代表待转换的数据中最大值;
步骤2:求解残差矩阵r,其步骤如下:
步骤2.1:假设鲁棒宽度学习系统的增强节点组数为m,每组q个增强节点,根据公式(2)求解系统的扩展输入矩阵am,am由输入数据矩阵和增强节点矩阵组合而成,am表达式如下
am=[x0|hm](2);
其中,x0表示
hm=[h1,...,hm]表示增强节点矩阵,
ξ(·)表示激活函数,是增强节点上的非线性函数,负责将增强节点的输入映射到输出端,采用常用的sigmod函数作为激活函数,激活函数如公式(3)所示:
步骤2.2:根据公式(4)利用岭回归算法求解迭代初始的连接权重矩阵
其中,i代表单位矩阵;
y0表示
λ代表正则化参数;
上标‘t’表示矩阵的转置;
步骤2.3:根据公式(5)利用残差公式求解残差矩阵r:
其中,r=[r1,r2,...,rn]t;
ri表示第i个训练数据的残差;
步骤3:计算训练数据的权值矩阵,步骤如下:
步骤3.1:根据公式(6)利用核密度估计算法求得残差概率密度函数:
其中,
k(·)是核密度函数,表达式为公式(7):
步骤3.2:计算所有训练数据组成的权值矩阵θ,第l个训练数据的权值θl=f(ri),根据公式(6)计算θl,所有的θl组成权值矩阵θ,θ=[θ1,...,θn]t;
步骤4:建立鲁棒宽度学习系统模型,具体步骤如下:
步骤4.1:根据公式(8)求解第k次迭代的连接权重矩阵
其中,k=1,2,3…;
步骤4.2:若相邻两步的输出权值的差的绝对值的最大值大于设定的阀值ε时,即
其中,xnew表示新的输入数据;
y预测表示预测的输出数据。
hm=[h1,...,hm],
进一步,在有新的训练数据输入时,通过以下步骤进行系统更新:
s1:设新的训练数据的输入数据矩阵为
s2:利用步骤1.2中的公式(1)对新训练数据进行线性转换处理,并得到转换后数据的输入数据矩阵xa0和输出数据矩阵ya0;
s3:计算新增加训练数据对应的残差矩阵ra:
s3.1:根据公式(10)求解新增加训练数据对应的扩展输入矩阵aa:
s3.2:由公式
s3.3:根据公式(11)求解迭代初始的新的连接权重矩阵
其中,b根据公式(12)得出:
其中,c=aa-dtam,
s3.4:根据公式(14)利用残差公式求解新增加训练数据对应残差矩阵ra;
其中,ra=[r1,r2,...,ra]t;
s4:计算新增加训练数据权值:
s4.1:利用核密度估计算法求得新增加训练数据的残差概率密度函数,函数公式如下:
s4.2:计算所有的新增加训练数据的权值组成权值矩阵θa,第l个训练数据的权值θla=fa(ri),根据公式(15)计算θla,所有的θla组成权值矩阵θa,θa=[θ1a,...,θaa]t;
s5:更新鲁棒宽度学习系统,根据公式(16)计算aam对应的伪逆矩阵(aam)+:
其中,
b'根据公式(17)得出:
其中,c'=θaaa-d'θaam;
根据公式(18)求解ka次迭代的新的连接权重矩阵
其中,ka=1,2,3…;
s6:若相邻两步的新的连接权重矩阵的差的绝对值的最大值大于设定的阀值ε时,即
进一步,在增加新的增强节点时,通过以下步骤进行系统更新:
步骤a:设新增的一组的增强节点个数为q,则新增增强节点通过公式(20)表示为:
其中,
步骤b:增加增强节点之后,新的扩展输入矩阵am+1=[am|hm+1],根据公式(21)推导得出am+1的伪逆矩阵(am+1)+:
其中,
b'根据公式(22)得出:
其中,c'=θhm+1-θamd';
步骤c:根据公式(23)求解增加增强节点之后的新的连接权重矩阵wm+1:
步骤d:更新后的模型输出预测表达公式(24)如下:
y预测=[xnew|hm+1]wm+1(24)
其中,hm+1=[h1,...,hm+1];
本发明首先利用宽度学习系统得到预测值;再利用核密度估计方法根据预测值与实际值之间的残差计算每个数据的权值,正常的数据分配较大的权值,而疑似离群点则分配较小的权值,因此鲁棒宽度学习系统能自动的学习到训练集中正确的信息;最后利用本发明中的加权岭回归算法计算系统的连接权值,从而建立鲁棒宽度学习系统模型。本发明同时提供两种鲁棒增量学习算法,分别用于增加训练数据和增强节点,从而实现已建鲁棒宽度学习系统模型的快速更新。与原有的宽度学习系统相比,当训练数据集中存在离群点时,本发明在预测精度、鲁棒性和泛化性方面具有明显的优势。本发明提高了宽度学习系统的鲁棒性,抑制了离群点的不利影响。
附图说明
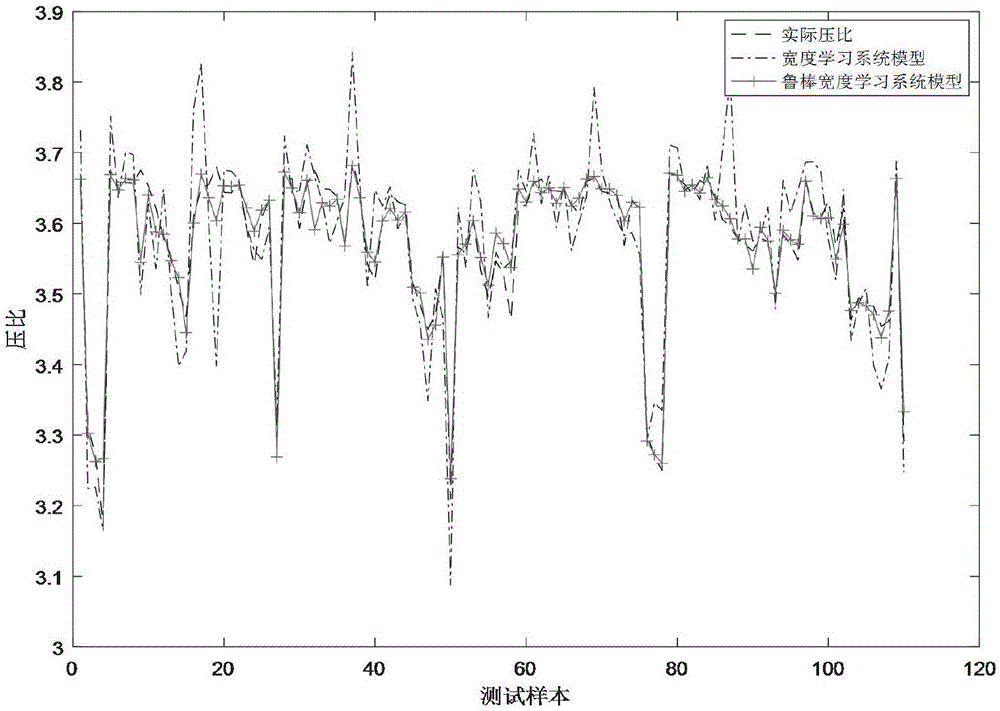
图1为鲁棒宽度学习系统模型与宽度学习系统模型对测试数据集的拟合效果对比图;
图2为随着离群点含量的增加,鲁棒宽度学习系统模型与宽度学习系统模型测试均方根误差变化趋势图;
图3为随着训练数据的增加,鲁棒宽度学习系统模型与宽度学习系统模型的测试均方根误差变化趋势图;
图4为随着训练数据和增强节点的增加,鲁棒宽度学习系统模型与宽度学习系统模型的测试均方根误差变化趋势图;
图5为增加训练数据的鲁棒增量学习方式与增加训练数据和增强节点的鲁棒增量学习方式的学习效果对比图。
具体实施方式
下面结合实施例和附图对本发明作进一步说明。
一种鲁棒宽度学习系统,包括以下步骤:
步骤1:数据预处理,其步骤如下:
步骤1.1:采集训练数据,设训练数据的输入数据矩阵为
其中,n为训练数据的样本个数;
m和c分别对应输入数据和输出数据的变量个数;
步骤1.2:根据公式(1)中的转换函数对训练数据进行线性转换处理,将结果值映射到[-1,1],其中转换函数为:
其中,
x,y代表待转换的数据;
xmin,ymin代表待转换的数据中最小值;
xmax,ymax代表待转换的数据中最大值;
步骤2:求解残差矩阵r,其步骤如下:
步骤2.1:假设鲁棒宽度学习系统的增强节点组数为m,每组q个增强节点,根据公式(2)求解系统的扩展输入矩阵am,am由输入数据矩阵和增强节点矩阵组合而成,am表达式如下
am=[x0|hm](2);
其中,x0表示
hm=[h1,...,hm]表示增强节点矩阵,
ξ(·)表示激活函数,是增强节点上的非线性函数,负责将增强节点的输入映射到输出端,采用常用的sigmod函数作为激活函数,激活函数如公式(3)所示:
步骤2.2:根据公式(4)利用岭回归算法求解迭代初始的连接权重矩阵
其中,i代表单位矩阵;
y0表示
λ代表正则化参数;
上标‘t’表示矩阵的转置;
步骤2.3:根据公式(5)利用残差公式求解残差矩阵r:
其中,r=[r1,r2,...,rn]t;
ri表示第i个训练数据的残差;
步骤3:计算训练数据的权值矩阵,步骤如下:
步骤3.1:根据公式(6)利用核密度估计算法求得残差概率密度函数:
其中,
k(·)是核密度函数,表达式为公式(7):
步骤3.2:计算所有训练数据组成的权值矩阵θ,第l个训练数据的权值θl=f(ri),根据公式(6)计算θl,所有的θl组成权值矩阵θ,θ=[θ1,...,θn]t;
步骤4:建立鲁棒宽度学习系统模型,具体步骤如下:
步骤4.1:根据公式(8)求解第k次迭代的连接权重矩阵
其中,k=1,2,3…;
步骤4.2:若相邻两步的输出权值的差的绝对值的最大值大于设定的阀值ε时,即
其中,hm=[h1,...,hm],
xnew表示新的输入数据;
y预测表示预测的输出数据。
在有新的训练数据输入时,通过以下步骤进行系统更新:
s1:设新的训练数据的输入数据矩阵为
s2:利用步骤1.2中的公式(1)对新训练数据进行线性转换处理,并得到转换后数据的输入数据矩阵xa0和输出数据矩阵ya0;
s3:计算新增加训练数据对应的残差矩阵ra:
s3.1:根据公式(10)求解新增加训练数据对应的扩展输入矩阵aa:
s3.2:由公式
s3.3:根据公式(11)求解迭代初始的新的连接权重矩阵
其中,b根据公式(12)得出:
其中,c=aa-dtam,
s3.4:根据公式(14)利用残差公式求解新增加训练数据对应残差矩阵ra;
其中,ra=[r1,r2,...,ra]t;
s4:计算新增加训练数据权值:
s4.1:利用核密度估计算法求得新增加训练数据的残差概率密度函数,函数公式如下:
s4.2:计算所有的新增加训练数据的权值组成权值矩阵θa,第l个训练数据的权值θla=fa(ri),根据公式(15)计算θla,所有的θla组成权值矩阵θa,θa=[θ1a,...,θaa]t;
s5:更新鲁棒宽度学习系统,根据公式(16)计算aam对应的伪逆矩阵(aam)+:
其中,
b'根据公式(17)得出:
其中,c'=θaaa-d'θaam;
根据公式(18)求解ka次迭代的新的连接权重矩阵
其中,ka=1,2,3…;
s6:若相邻两步的新的连接权重矩阵的差的绝对值的最大值大于设定的阀值ε时,即
在增加新的增强节点时,通过以下步骤进行系统更新:
步骤a:设新增的一组的增强节点个数为q,则新增增强节点通过公式(20)表示为:
其中,
步骤b:增加增强节点之后,新的扩展输入矩阵am+1=[am|hm+1],根据公式(21)推导得出am+1的伪逆矩阵(am+1)+:
其中,
b'根据公式(22)得出:
其中,c'=θhm+1-θamd';
步骤c:根据公式(23)求解增加增强节点之后的新的连接权重矩阵wm+1:
步骤d:更新后的模型输出预测表达公式(24)如下:
y预测=[xnew|hm+1]wm+1(24);
其中,hm+1=[h1,...,hm+1];
实施例:
本实施例是大型工业多级离心压缩机建模,建立鲁棒宽度学习系统模型用于预测大型工业多级离心压缩机的输出压比,具体步骤如下:
收集510组大型工业多级离心压缩机运行数据(此数据来采自于某钢厂实际运行机组),输入数据变量包括:入口压力,入口温度和入口流量,输出数据变量为输出压比。选择其中的400组数据作为训练集,110组数据作为测试集。为了保证测试结果的真实有效,在训练集中加入一定数量的离群点。离群点添加方式如下:设在训练集中,离群点数量占总训练数据数量的百分比为γ。离群点中,50%的离群点为高杠杆离群点(即输入数据中不在正常范围内,而对应的输出值却在合理范围内的点),其可以通过在正常训练数据的输入数据上随机加上或减去不超过训练集中输入数据最大值的噪声产生;剩余50%的离群点为高残差离群点(即输出数据中残差与其他点相比较大的点),其可以通过在正常训练数据的输出数据上随机加上或减去不超过训练集中输出数据最大值的噪声产生。
1.建立鲁棒宽度学习系统模型
步骤1.1:数据预处理。设含有γ离群点的训练集的输入数据矩阵为
其中,
步骤1.2:计算残差矩阵r。假设鲁棒宽度学习系统的增强节点组数为m(m=11),每组q(q=20)个增强节点。首先求解系统的扩展输入矩阵am,其由输入数据矩阵和增强节点矩阵组合而成,表达式如下
am=[x0|hm](2)
其中,hm=[h1,...,hm]表示增强节点矩阵,
然后利用岭回归算法求解迭代初始的连接权重矩阵
其中i代表单位矩阵,λ代表正则化参数(λ=2-8),上标‘t’表示矩阵的转置。最后利用残差公式求解残差矩阵r,r=[r1,r2,...,rn]t而ri表示第i个训练数据的残差。
步骤1.3:计算训练数据的权值矩阵。首先利用核密度算法求得残差概率密度函数,函数公式如下:
其中
最后第l个训练数据的权值θl可由公式(6)(θl=f(ri),其中l,i=1…n)计算。所有的训练数据的权值组成权值矩阵θ,θ=[θ1,...,θn]t。
步骤1.4:建立鲁棒宽度学习系统模型。首先利用步骤1.2中计算得到的扩展输入矩阵am和步骤1.3中计算得到的训练数据的权值矩阵θ,通过本发明所提出的加权岭回归算法求解第k次迭代的连接权重矩阵
若相邻两步的输出权值的差的绝对值的最大值大于设定的阀值ε=0.1时,即
其中hm=[h1,...,hm],
利用测试集对所建模型进行验证,验证结果如下:首先进行λ=20的条件下,利用鲁棒宽度学习系统模型对测试数据进行预测,作为对比,同样用宽度学习系统模型对测试数据进行预测,两个模型的预测值和真实值在图1展现。由图1可见鲁棒宽度学习系统模型的预测值与真实值更为接近。其次进行在不同数量的离群点条件下,即λ=[0,5,10,15,20,25,30],两个模型的预测能力比较,以预测值均方根误差值作为判断标准(rootmeansquareerror,简写为rmse),均方根误差如下:
其中,yi表示第i个测试数据输出的预测值,
表1为在不同离群点含量下,鲁棒宽度学习系统模型与宽度学习系统模型的测试均方根误差
2.增加训练数据的鲁棒增量学习算法
步骤2.1:数据预处理。设含有λ=20离群点的训练集的输入数据矩阵为
步骤2.2:求解残差矩阵r。假设鲁棒宽度学习系统的增强节点组组数为m(m=3),每组q(q=20)个增强节点。首先求解系统的扩展输入矩阵am,其由输入数据矩阵和增强节点矩阵组合而成,表达式如公式(2)。然后利用公式(4)求解迭代初始的连接权重矩阵
步骤2.3:计算训练数据的权值。首先利用核密度估计算法求得残差概率密度函数,如公式(6)。最后第l个训练数据的权值θl可由公式(6)(θl=f(ri),其中l,i=1…n)推出。所有的训练数据的权值组成权值矩阵θ,θ=[θ1,...,θn]t。
步骤2.4:建立鲁棒宽度学习系统模型。首先利用步骤2.2中计算得到的扩展输入矩阵am和步骤2.3中计算得到的训练数据的权值矩阵θ,通过公式(8)求解第k次迭代的连接权重矩阵
若相邻两步的连接权重矩阵的差的绝对值的最大值大于设定的阀值ε(ε=0.1)时,即
其中hm=[h1,...,hm],
步骤2.5:新训练数据预处理。设新增加训练数据的输入数据矩阵为
步骤2.6:计算新增加训练数据对应的残差矩阵ra。首先求解新增加训练数据对应的扩展输入矩阵aa
其中
而c=aa-dtam,
步骤2.7:求解新增加训练数据权值。利用核密度估计算法求得新增加训练数据残差概率密度函数,函数公式如下:
其中
步骤2.8:鲁棒宽度学习系统模型更新。利用步骤2.4求得的
其中
其中c'=θaaa-d'θaam,则第ka(ka≤30)次迭代的新的连接权重矩阵
若相邻两步的新的连接权重矩阵的差的绝对值的最大值大于设定的阀值ε(ε=0.1)时,即
步骤2.9:利用测试集对每次更新后的模型进行验证,计算模型的预测值的均方根误差。返回步骤2.5,继续添加30组训练数据,依步骤顺序更新模型,直到所有的400组训练数据添加完毕,则停止模型更新。
结果如下:图3为鲁棒宽度学习系统模型和宽度学习系统利用各自的增量的学习算法对模型进行更新,每次更新后两个模型预测值的均方根误差对比图。由图中可以明显看到本法发明的鲁棒宽度学习系统的模型每次更新后的模型的预测远精度高于宽度学习系统模型,说明所提出的增加数据的鲁棒增量学习算法有效。
3.增加增强节点的鲁棒增量学习算法
当新增加训练数据进入模型后,增加适当数量的增强节点可以提升模型对新增加数据的学习能力。在本验证实验中,我们将增加训练数据和增加增强节点的鲁棒增量学习算法相结合,在增加训练数据的同时增加增强节点以提高模型的预测精度。具体实施步骤如下:
步骤3.1:数据预处理。设含有λ=20离群点的训练集的输入数据矩阵为
步骤3.2:计算残差矩阵r。假设鲁棒宽度学习系统的增强节点组组数为m(m=1),每组q(q=20)个增强节点。首先求解系统的扩展输入矩阵am,其由输入数据矩阵和增强节点矩阵组合而成,表达式如公式(2)。然后利用公式(4)求解迭代初始的连接权重矩阵
步骤3.3:计算训练数据的权值矩阵。首先利用核密度估计算法求得残差概率密度函数,函数公式如(6),第l个训练数据的权值θl可由公式(6)(θl=f(ri),其中l,i=1…n)推出。所有的训练数据的权值组成权值矩阵θ,θ=[θ1,...,θn]t。
步骤3.4:建立鲁棒宽度学习系统模型。首先利用步骤3.2中计算得到的扩展输入矩阵am和步骤3.3中计算得到的训练数据的权值矩阵θ,通过公式(8)求解第k次迭代的连接权重矩阵
若相邻两步的连接权重矩阵的差的绝对值的最大值大于设定的阀值ε(ε=0.1)时,即
其中hm=[h1,...,hm],
步骤3.5:新训练数据预处理。设新的训练数据的输入数据矩阵为
步骤3.6:计算新增加训练数据对应的残差矩阵ra。首先求解新增加训练数据对应的扩展输入矩阵aa
其中
而c=aa-dtam,
步骤3.7:求解新增加训练数据权值。利用核密度估计算法求得新增加训练数据残差概率密度函数,函数公式如下:
其中
步骤3.8:鲁棒宽度学习系统模型更新。利用步骤2.4求得的
其中
其中c'=θaaa-d'θam,则第ka(ka≤30)次迭代的新的连接权重矩阵
若相邻两步的新的连接权重矩阵的差的绝对值的最大值大于设定的阀值ε(ε=0.1)时,即
步骤3.9:增加增强节点后的鲁棒宽度学习系统模型更新。假设新增的一组的增强节点个数为q(q=20),则新增加增强节点可以表示为
其中
其中
而c'=θchm+1-θxamd'。则增加增强节点之后的新的连接权重矩阵为
其中
增加增强节点之后的鲁棒宽度学习系统模型预测输出表达式更新为
其中
步骤3.10:利用测试集验证模型,计算预测值的均方根误差。返回步骤3.5,继续增加新的30组训练数据和20个增强节点,依序更新模型,直到400组训练数据全部添加完毕。
结果如下:图4为鲁棒宽度学习系统模型和宽度学习系统利用各自的增量的学习算法增加训练数据和增强节点对模型进行更新,每次更新后两个模型预测值的均方根误差对比图。由图中可以明显看到本法发明的鲁棒宽度学习系统的模型每次更新后的模型的预测远高于宽度学习系统模型,说明所提出的增加节点的鲁棒增量学习算法有效。图5为利用增加训练数据和增强节点的鲁棒增量学习算法与只增加训练数据的鲁棒增量学习算法分别对鲁棒宽度学习系统模型进行更新,模型预测值的均方根误差对比图。由图中看出利用增加训练数据和增强节点的鲁棒增量学习算法更新的模型的预测精度高于用只增加训练数据的鲁棒增量学习算法更新的模型。说明增加增强节点可以提高模型的学习能力。
- 还没有人留言评论。精彩留言会获得点赞!