低分辨率监控场景中具有遮挡的行人属性识别方法与流程
本发明属于行人的特征识别技术,具体为低分辨率监控场景中具有遮挡的行人属性识别方法。
背景技术:
行人是监控场景中的最主要研究对象。识别行人的基本属性是有非常意义的。为了方便传统监控系统中的查询和检索任务,有必要人工地标记行人的基本属性,然后为感兴趣的行人输入属性标签。但是,在庞大的监控数据下,这种工作不能满足对行人属性标记的需要。通过计算机视觉技术在监控中自动标记行人属性是一种有效的方法。
行人属性识别方法是通过对输入图像的处理获取图像中行人属性的算法,本发明主要涉及图像采集,图像预处理,图像增强,属性提取,属性分类等算法步骤。其中图像增强和属性分类是两个关键问题。
目前在行人属性识别场景上已经有所研究,如layne等人在“personre-identificationbyattributes”中运用svm算法对行人属性的识别,deng在等人在“pedestrianattributerecognitionatfardistance”中引入行人数据库(peta)对识别算法的优化。但他们都缺少对低分辨率图场景下的识别研究,所以在实际监控场景下运用存在一定局限。
另外,对行人的性别属性识别上也有所研究,如sun等人利用遗传算法对人脸的部分特征点作为分类特征,通过构建人工神经网络作为识别的分类器;还有luo提出的局部二元模式(lbp)特征解决多角度人脸识别;amitjain利用独立分量分析(ica)提取人脸特征,并结合svm分类器识别。同样,他们未考虑在监控场景下的应用。
外观属性主要体现在对行人服装的理解上,也是行人属性识别的重要内容。通过对衣服外观的理解,可以提供语义属性,包括衣服的颜色,款式,是否戴眼镜,以及是否携带包装。近年来,许多研究人员通过对行人服装的理解,结合环境的背景信息,有效地认识到行人图像的基本外观。gallagher和chen等人提出了一种从一组图像中学习服装模型的算法来解决如何从图像中分割服装区域的问题。但是同样的,如果行人图像被遮挡,那么服装区域将更难分割。
技术实现要素:
本发明的目的在于提出了一种低分辨率监控场景中具有遮挡的行人属性识别方法。
实现本发明的技术解决方案为:低分辨率监控场景中具有遮挡的行人属性识别方法,具体步骤为:
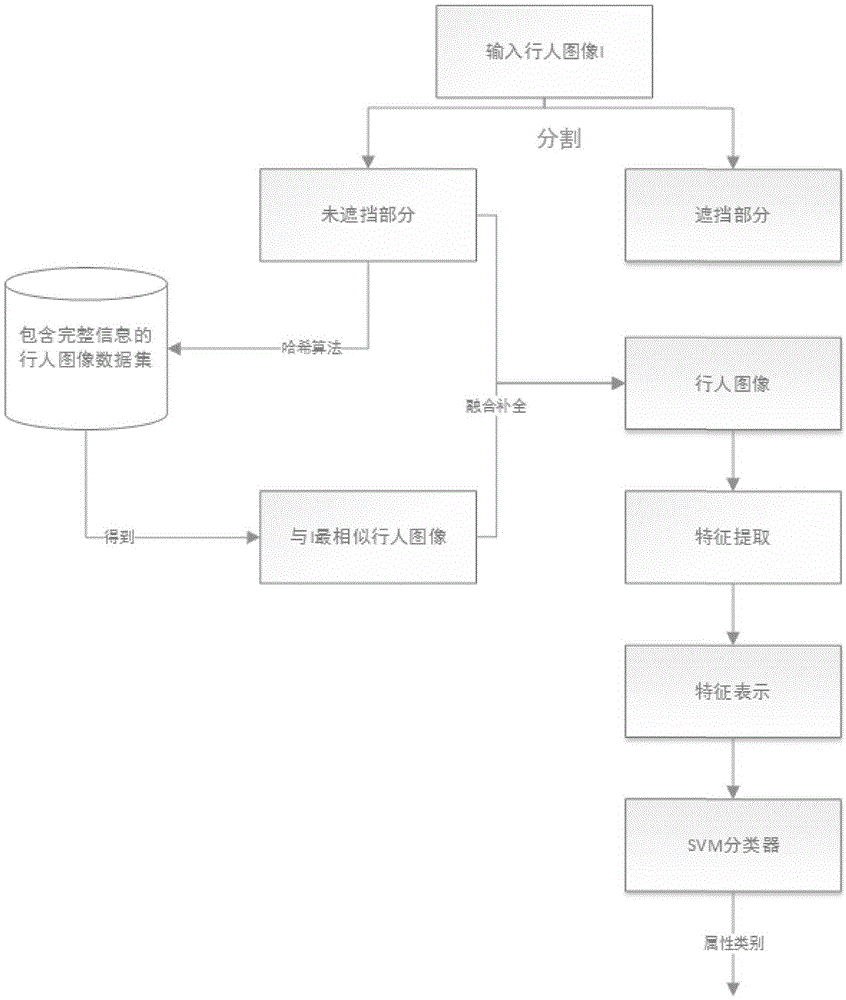
步骤1、利用度量学习对被遮挡的行人图像进行修复操作,去除行人图像中的遮挡物;
步骤2、对修复后的图像进行横向切割,将相应图像块分别标记为行人“头肩部分”、“上身部分”以及“下身部分”;
步骤3、确定要识别的属性,提取该属性对应部分的每块图像的特征,具体特征包括:颜色特征、lbp特征、gabor滤波器特征、schmid滤波器特征,并将每个特征表示为16-bin直方图;
步骤4、将步骤3中的16-bin直方图作为图像的特征向量,并将图像的特征向量输入训练好的svm分类器得到识别结果。
优选地,步骤1中利用度量学习对被遮挡的行人图像进行修复操作的具体步骤为:
步骤1-1、给定一个没被遮挡的信息完整的行人图像数据集p;
步骤1-2、给定被遮挡的行人图像i并标记图像i被遮挡部分,在行人图像数据集p中使用哈希算法找到与图像i未遮挡部位最相似的行人图像t,用行人图像t补全行人图像i被遮挡部分。
优选地,步骤1-2中在行人图像数据集p中使用哈希算法找到与图像i未遮挡部位最相似的行人图像t的具体步骤为:
步骤1-2-1、根据遮挡标记裁剪出行人图像i未遮挡部分i1;
步骤1-2-2、将图像未遮挡部分i1灰度化并归一化到n*n尺寸,记为图像g;
步骤1-2-3、计算图像g中所有像素的灰度平均值a,将图像g中每个像素点的灰度值与平均值a做比较,如果该像素点的灰度值大于平均值a,则将该像素点记为‘1’,如果该像素点的灰度值小于平均值a则记为‘0’,以此将未遮挡部分i1转化为01形式的字符串,记为未遮挡部分i1的hash指纹;
步骤1-2-4、裁剪出数据集p中每幅图像中与图像未遮挡部分i1对应位置的图像p1,并利用步骤1-2-2~步骤1-2-3的方法得到图像p1的hash指纹;
步骤1-2-5、分别比较图像未遮挡部分i1的hash指纹与图像集p1中每幅图像的hash指纹的相似度大小,找出数据集p中与图像i最相似的行人图像t。
优选地,步骤1-2-3中图像i的hash指纹与数据集p中每幅图像的hash指纹的相似度为“汉明距离”,所述“汉明距离”定义为比较的两个等长字符串中对应位置的不同字符的个数,个数越少则两幅图像越相似。
优选地,n的取值范围为8~12。
优选地,步骤3中要识别的属性与身体部分的对应关系未:属性“眼镜”和“头发”属于“头肩部分”;属性“v领”、“商标”和“背包”属于“上身部分”,属性“短裤”和“牛仔裤”属于“下身部分”,对于全局属性“男性”、“女性”属于整个行人图像。
优选地,步骤4中所述svm分类器的核函数为直方图交叉核,该训练好的svm分类器为使用未被遮挡的图像集相应属性的特征向量作为训练集进行训练得到的最优分类器。
本发明与现有技术相比,其显著优点为:(1)本发明分类效果更好,分类准确率更高;(2)本发明在面对低分辨率的行人图像时,具有更强的鲁棒性;(3)本发明通过使用度量学习能够恢复被遮挡的图像进行属性分类,识别效果更好。
下面结合附图对本发明做进一步详细的描述。
附图说明
图1是本发明的低分辨率下监控场景中具有遮挡的行人属性识别方法的总体流程图。
图2是rgb空间图像以及各个通道图像。
图3是ycbcr空间图像以及各个通道图像。
图4是hsv空间图像以及各个通道图像。
图5是图像lbp特征,左为rgb图像,中为灰度图像,右为lbp图谱。
图6是不同参数下gabor滤波器提取的图像特征图谱
图7是不同参数下schmid滤波器提取的图像特征图谱
具体实施方式
低分辨率监控场景中具有遮挡的行人属性识别方法,具体步骤为:
步骤1、利用度量学习对被遮挡的行人图像进行修复操作,去除行人图像中的遮挡物,具体步骤为:
步骤1-1、给定一个没被遮挡的信息完整的行人图像数据集p;
步骤1-2、给定被遮挡的行人图像i并标记图像i被遮挡部分,在行人图像数据集p中使用哈希算法找到与图像i未遮挡部位最相似的行人图像t,用行人图像t补全行人图像i被遮挡部分。
进一步的实施例中,步骤1-2中在行人图像数据集p中使用哈希算法找到与图像i未遮挡部位最相似的行人图像t的具体步骤为:
步骤1-2-1、根据遮挡标记裁剪出行人图像i未遮挡部分i1;
步骤1-2-2、将图像未遮挡部分i1灰度化并归一化到n*n尺寸,记为图像g;
步骤1-2-3、计算图像g中所有像素的灰度平均值a,将图像g中每个像素点的灰度值与平均值a做比较,如果该像素点的灰度值大于平均值a,则将该像素点记为‘1’,如果该像素点的灰度值小于平均值a则记为‘0’,以此将未遮挡部分i1转化为01形式的字符串,记为未遮挡部分i1的hash指纹;
步骤1-2-4、裁剪出数据集p中每幅图像中与图像未遮挡部分i1对应位置的图像p1,并利用步骤1-2-2~步骤1-2-3的方法得到图像p1的hash指纹;
步骤1-2-5、分别比较图像未遮挡部分i1的hash指纹与图像集p1中每幅图像的hash指纹的相似度大小,找出图像p1中与图像i最相似的行人图像t。
在某些实施例中,图像i的hash指纹与数据集p中每幅图像的hash指纹的相似度为“汉明距离”,所述“汉明距离”定义为比较的两个等长字符串中对应位置的不同字符的个数,个数越少则两幅图像越相似。
步骤2、对修复后的图像进行横向切割,将相应图像块分别标记为行人“头肩部分”、“上身部分”以及“下身部分”;在某些实施例中,将行人图像横向平均切割为10块,标记为1~10块,将第1块到第3块标记为行人“头肩部分”,第3块到第7块标记为行人“上身部分”,第6块到第10块标记为行人“下身部分”;
步骤3、确定要识别的属性,提取该属性对应部分的每块图像的特征,具体特征包括:颜色特征、lbp特征、gabor滤波器特征、schmid滤波器特征,并将每个特征表示为16-bin直方图;在某些实施例中,要识别的属性与身体部分的对应关系为:属性“眼镜”和“头发”属于“头肩部分”;属性“v领”、“商标”和“背包”属于“上身部分”,属性“短裤”和“牛仔裤”属于“下身部分”,对于全局属性“男性”、“女性”属于整个行人图像。
步骤4、将步骤3中的16-bin直方图作为图像的特征向量,并将图像的特征向量输入训练好的svm分类器得到识别结果。
在某些实施例中,训练好的svm分类器的训练过程为:
对未被遮挡的图像集的每幅图像进行横向切割,将相应图像块分别标记为行人“头肩部分”、“上身部分”以及“下身部分”;提取相应属性所对应部分的每块图像的特征,将每个特征表示为16-bin直方图作为训练集以及测试集图像的特征向量训练svm分类器。使用5折交叉验证来评估svm分类器的分类结果,将分类效果最优的模型作为最优的svm分类器。
实施例
如图1所示,低分辨率监控场景中具有遮挡的行人属性识别方法,具体步骤为:
步骤1、利用度量学习对被遮挡的行人图像进行修复操作,去除行人图像中的遮挡物,具体步骤为:
步骤1-1、给定一个没被遮挡的信息完整的行人图像数据集p;
步骤1-2、给定被遮挡的行人图像i并标记图像i被遮挡部分,根据遮挡标记裁剪出行人图像i未遮挡部分i1;
将图像未遮挡部分i1灰度化并归一化到n*n尺寸,记为图像g;
计算图像g中所有像素的灰度平均值a,将图像g中每个像素点的灰度值与平均值a做比较,如果该像素点的灰度值大于平均值a,则将该像素点记为‘1’,如果该像素点的灰度值小于平均值a则记为‘0’,以此将未遮挡部分i1转化为01形式的字符串,记为未遮挡部分i1的hash指纹;
裁剪出数据集p中每幅图像中与图像未遮挡部分i1对应位置的图像p1,并利用步骤1-2-2~步骤1-2-3的方法得到图像p1的hash指纹;
步骤1-2-5、分别比较图像未遮挡部分i1的hash指纹与图像集p1中每幅图像的hash指纹的相似度大小,找出图像p1中与图像i最相似的行人图像t。
用行人图像t中与图像i被遮挡部分对应位置图像补全行人图像i被遮挡部分。
步骤2、对修复后的图像进行切割,将行人图像横向平均切割为10块,标记为1~10块,我们将第1块到第3块标记为行人“头肩部分”,第3块到第7块标记为行人“上身部分”,第6块到第10块标记为行人“下身部分”;不同的属性分布于不同的身体部分,属性“眼镜”和“头发”属于“头肩部分”,属性“v领”,“商标”和“背包”属于“上身部分”,属性“短裤”和“牛仔裤”属于“下身部分”,对于全局属性“男性”、“女性”属于整个行人图像。
步骤3、确定要识别的属性,提取该属性对应部分的每块图像的特征,具体特征包括:颜色特征、lbp特征、gabor滤波器特征、schmid滤波器特征,并将每个特征表示为16-bin直方图;
如图2、图3、图4所示,可知不同颜色空间不同通道具有不同的颜色特征。lbp特征提取图像局部纹理特征如图5所示。gabor滤波器的参数选择如表1所示,表1参数所选gabor滤波器提取的图像如图6所示。schmid滤波器的参数选择如表2所示,表1参数所选gabor滤波器提取的图像如图7所示。
表1
表2
步骤4、将步骤3中的16-bin直方图作为图像的特征向量,并将图像的特征向量输入训练好的svm分类器得到识别结果,所述svm分类器的核函数为直方图交叉核。
表3
本实施例在peta数据集的子数据集viper相应属性的特征向量作为该属性分类器的训练集和测试集。viper数据集细节如表3所示。本实施例将训练集和测试集的特征向量通过直方图交叉核函数映射到高维空间,用svm分类器进行分类。
直方图交叉核函数定义为:
本实施例为每个属性分别训练分类器,即对数据集样本进行切割,将行人图像横向平均切割为10块,标记为1~10块,将第1块到第3块标记为行人“头肩部分”,第3块到第7块标记为行人“上身部分”,第6块到第10块标记为行人“下身部分”,提取属性对应部分的每块图像的特征,具体特征包括:颜色特征、lbp特征、gabor滤波器特征、schmid滤波器特征,将每个特征表示为16-bin直方图作为图像的特征向量,对于不平衡的属性训练,使用随机下采样来处理不平衡数据,使用5折交叉验证来评估模型好坏,最终保存分类效果最优的模型作为最优的svm分类器。在本实施例中选择八个属性来测试属性分类的性能。对于每个属性,本实施例对训练数据进行10次采样,并将十个结果的平均值作为最终分类结果。本实施例与“personre-identificationbyattributes”中提出的方法进行比较,比较结果即识别正确率如表5所示。
表5
- 还没有人留言评论。精彩留言会获得点赞!