一种基于神经协同过滤的智能商业选址方法与流程
本发明涉及商业选址和基于深度学习的推荐系统领域,尤其涉及基于神经协同过滤的商业地址推荐的方法。
背景技术:
大数据驱动的商业选址是新零售时代创新性应用之一。目前已经有了一些商业选址的研究,它们大多基于地理信息服务、poi数据等多元异构信息来选择其最佳位置。具体地,它们首先从多元数据中提取信息来获取各个方面的特征:地理特征(密度、竞争性等)、移动性特征(区域流行度、流入流量等)等,然后利用这些特征进行线性回归分析、矩阵分解(matrixfactorization,mf)或迁移学习等来获取最优位置。尽管这些方法都能提供比较满意的准确率,但他们都需要从数据中手动挖掘特征。若特征提取不全面便可能得不到较好的效果;此外,线性回归和mf方法均是线性模型,如果特征之间存在某种关联,此模型不能很好的表达这些特征。
近两年,深度学习在图像识别、文本处理、计算机视觉已取得巨大成功,在推荐系统方面也取得了很多突破,表明深度学习可以从内容中直接提取特征,可以更加准确地学习用户和项目的潜在特征。在推荐系统中一般有几种使用深度学习的方法:无监督的学习方法;利用深度学习来预测潜在特征;利用深度学习的方法将学习到的特征作为辅助信息。通常更多的是利用深度学习来对辅助信息建模,比如项目的文字描述、跨域行为的用户以及丰富的知识库,然后将深度学习学习到的特征与mf相结合。利用深度学习来预测潜在特征的研究相对较少,比较典型的是一种使用深层神经网络方法将用户和项目映射到共同低维空间,得到用户和项目的潜在特征,接着使用余弦相似度来计算最终的结果。
技术实现要素:
本发明基于以上缺陷提出一种基于神经协同过滤的智能商业选址方法,能够满足商业领域尤其是新零售领域的需求。本发明的技术方案为:
一种基于神经协同过滤的智能商业选址方法,包括以下步骤:
s1:建立餐馆、地址交互矩阵;
s2:建立地址偏好模型;
s3:餐馆地址推荐。
进一步地,一种基于神经协同过滤的智能商业选址方法,所述s1具体包括:
s11:获取餐馆数据与城市poi数据,利用餐馆的经纬度与划分区域块时的经纬度的范围匹配,若该餐馆在这个范围内,则保存此餐馆;
s12:定义餐馆类别-地址交互矩阵y∈rm×n,如下:
其中,yui的值为1,则表示在这个地址i上,存在着类别为u的餐馆,而yui的值为0则表示在地址i上,并不能说明不存在类别为u的餐馆。
进一步地,一种基于神经协同过滤的智能商业选址方法,所述s2具体包括:
s21:根据餐馆类别-地址交互矩阵y,建立svd模型,线性模拟餐馆类别对地址的偏好,svd模型为:
这里p∈rm×k和q∈rn×k分别表示餐馆类别和地址的潜在空间矩阵,
s22:根据餐馆类别-地址交互矩阵,建立mlp模型,非线性模拟餐馆类别对地址的偏好,mlp模型为:
其中,θg表示mlp模型交互函数g的参数;
s23:由s3和s4得到的两个偏好,可以得到最终的餐馆类别对地址的偏好:
其中,h表示svd与mlp模型之间的权重;σ表示激活函数。
进一步地,一种基于神经协同过滤的智能商业选址方法,所述s3包括:
s31:使用交叉熵损失函数来学习模型的参数,得到最终的预测评分矩阵:
这里,γ表示交互矩阵中观察到的项,γ-表示消极实例,可将未观察的样本全体视为消极实例,也可以采取抽样的方式标记为消极实例。
s32:依据预测评分矩阵,对餐馆类别推荐top-n个地址。
本发明的有益效果为:神经协同过滤可以预测出交互矩阵中的缺失值,然后预测值以某种方式向餐馆类别进行推荐。其能够有效解决矩阵分解(matrixfactorization,mf)线性模拟交互的问题、避免了冷启动的问题,同时加入了多层感知机(multi-layerperception,mlp)这一深度学习方法,可以从数据中学习任意函数,增加了地址推荐的准确性。
附图说明
图1为本发明一种基于神经协同过滤的智能商业选址方法的流程图;
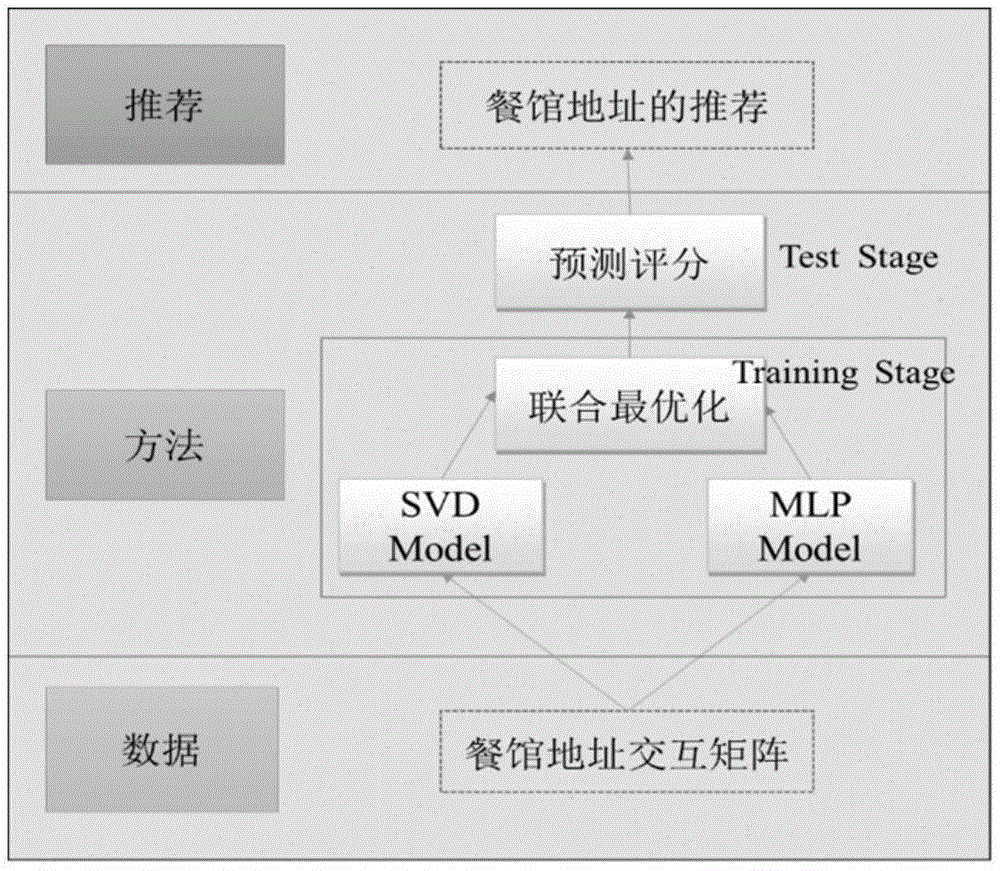
图2为本发明一种基于神经协同过滤的智能商业选址方法的方法模型;
图3为本发明一种基于神经协同过滤的智能商业选址方法推荐性能hr、ndcg随推荐列表长度的变化。
具体实施方式
下面结合附图来进一步描述本发明的技术方案:
如图1所示,一种基于神经协同过滤的智能商业选址方法,包括以下步骤:s1:建立餐馆、地址交互矩阵;s2:建立地址偏好模型;s3:餐馆地址推荐。
如图2所示,一种基于神经协同过滤的智能商业选址方法,所述方法为:
s1:建立餐馆、地址交互矩阵;
s11:获取餐馆数据与城市poi数据,利用餐馆的经纬度与划分区域块时的经纬度的范围匹配,若该餐馆在这个范围内,则保存此餐馆;
s12:定义餐馆类别-地址交互矩阵y∈rm×n,如下:
其中,yui的值为1,则表示在这个地址i上,存在着类别为u的餐馆,而yui的值为0则表示在地址i上,并不能说明不存在类别为u的餐馆。
利用这样的交互矩阵很容易判断出该餐馆类别的偏好,比如矩阵的某一行(西餐),表示北京市该餐馆类别开店的所有的位置,集合这些位置,可以判断出它对位置的一个偏好,如集合西餐这一类别的餐馆,可以得到它周围的公司住宅区、商务住宅区、交通、餐饮、购物中心等较多,说明西餐比较偏好于此类的地址。s2:建立地址偏好模型;
s21:根据餐馆类别-地址交互矩阵y,建立svd模型,线性模拟餐馆类别对地址的偏好,svd模型为:
这里p∈rm×k和q∈rn×k分别表示餐馆类别和地址的潜在空间矩阵,
一般地,根据餐馆类别-地址交互矩阵y,可以直接建立mf方法补全矩阵,但是这只是线性地描述了餐馆类别与地址特征之间的关系,一般特征之间的关系并不一定是线性或非线性的,很复杂,因此这里我们从线性和非线性的角度来刻画餐馆类别与地址特征之间的关系。
简单来说,
s22:根据餐馆类别-地址交互矩阵,建立mlp模型,非线性模拟餐馆类别对地址的偏好,mlp模型为:
其中,θg表示mlp模型交互函数g的参数;
s23:由s3和s4得到的两个偏好,可以得到最终的餐馆类别对地址的偏好:
其中,h表示svd与mlp模型之间的权重;σ表示激活函数。
s3:餐馆地址推荐;
s31:使用交叉熵损失函数来学习模型的参数,得到最终的预测评分矩阵:
这里,γ表示交互矩阵中观察到的项,γ-表示消极实例,可将未观察的样本全体视为消极实例,也可以采取抽样的方式标记为消极实例。然后最小化此目标函数,利用随机梯度下降方法进行训练优化,得到结果较优的参数,从而得到餐馆类别对地址的预测评分矩阵。
s32:依据预测评分矩阵,对餐馆类别推荐top-n个地址。
比如,如果设置n为10,则西餐的推荐的地址列表为:851,590,656,853,21,918,9,884,277,1178(这些均是地址块id),而对于火锅,推荐列表为:772,307,1034,657,1073,1213,789,345,113,149。
图3为种基于神经协同过滤的智能商业选址方法推荐性能hr、ndcg随推荐列表长度的变化。hr表示测试集中的餐馆类别u的地址i是否在u的推荐地址列表中;ndcg表示推荐的排名质量,即测试集中的餐馆类别u的地址i是否在u的推荐地址列表靠前的位置。
从这两幅图中可以看出,随着推荐列表长度的增加,推荐性能越来越好,因为长度增加意味着正确的地址有更大的概率被推荐出来。此外,也可以看出,我们的方法优于其他的基于特征的方法和深度学习方法,表明了我们的方法的可行性与有效性。
- 还没有人留言评论。精彩留言会获得点赞!