一种可重构系统的缓存分区划分方法与流程
本发明属于高速缓存分区领域,具体涉及一种可重构系统的缓存分区划分方法。
背景技术:
通用计算机和asic代表了两种极端的计算手段,通用计算机具有最大的灵活性和低性能,asic具有最高的性能和最差的灵活性。而现在有许多应用需求既要求较高的性能,又需要一定的灵活性。例如,一个多媒体应用中可能包括数据并行处理、位处理、不规则计算、高精度字操作、具有实时要求的操作等子任务,要求处理系统能够灵活地处理上述各个子任务并达到一定的性能。许多其它应用也具有类似的需求,如数据加密、人工智能等,这些应用需求导致了可重构处理器的产生。可重构处理器是在运行时通过配置流来动态改变运算单元阵列的功能,其功能的改变一般只消耗很短的时钟周期,然后通过数据流来驱动运算单元阵列进行计算,是一种兼具高灵活性和高能量效率的并行计算架构,目前已成为学术界和工业界的研究热点,并且已经有许多令人瞩目的研究成果和工业产品面世。
缓存技术的出现是为了缩小存储器与处理器之间速度的差异。缓存中的数据是主存数据的子集。因此若需要从主存调入一个块到高速缓存中,会出现该块映射在缓存的位置已经被其他内容所占用。lru替换策略是根据最近一次访问的数据块来决定驱逐的。这在高局部工作集中有着良好的表现。但是在多核系统中,却有着一定的局限性。共享缓存在芯片多处理器(cmp)中普遍存在,以缓解主存储器的高延迟,高能量和有限带宽。这些优势成本很高。当多个应用程序共享cmp时,它们会受到共享缓存中的干扰。这会导致较大的性能变化,妨碍服务质量(qos)保证,并且可能会降低缓存利用率,从而影响整体吞吐量。因此有效地管理共享片上缓存,减少片外存储器带宽需求成为关键。缓存分区被认为是提高共享缓存效率的有前途的技术。
技术实现要素:
本发明目的是以已有的经典的缓存分区方法为基础,加入两个新的数据,对其进行修正和改进,有效的管理共享片上缓存,提高可重构处理器系统的性能。
本发明采用如下技术方案来实现的:
一种可重构系统的缓存分区划分方法,包括以下步骤:
1)在多个粗粒度可重构阵列cgra处理数据时,采用无效缩放fs管理共享片上缓存,以减少片外存储器带宽需求;
2)在缓存分区时以无效缩放fs为基础,引入新数据——数据重叠量和迭代次数进行修正,以达到性能优化。
本发明进一步的改进在于,步骤1)的具体实现方法如下:
101)通过缩放每个分区中的候选者的无用性来控制每个分区的大小,每个分区的缩放因子为αi;
102)属于分区i的替代候选者fcand的无用性将有αi缩放,具有最大fsaclecand的行将被驱逐。
本发明进一步的改进在于,步骤101)具体实现方法如下:
假设具有r替换候选者,且具有两个分区,插入比率分别为i1和i2,目标比例分别为s1和s2;不失一般性,假设i1<s1,ii=ei,因此i2>s2,自然地,即没有缩放,分区的大小比列倾向于与其插入速率成比例;为了将分区2的大小从i2减小到s2,将属于分区2的高速缓存行的无用性按比例因子α2放大,α2>1,并保持分区1未放缩,即α1=1;
式中α2为分区2缩放因子,i1和i2分别为分区1和分区2插入比率,s1和s2分别为分区1和分区2目标比例,r为替换候选者数。
本发明进一步的改进在于,步骤102)具体实现方法如下:
在每次驱逐中,属于分区i的替代候选者fcand的无用性将由αi缩放,其中具有最大fscaledcand的行将会被驱逐
fscalecand=fcand×αi(1)
式中fcand表示替代候选者,αi表示i区缩放因子,fscaledcand表示替代候选者无用性。
本发明进一步的改进在于,步骤2)的具体实现方法如下:
201)通过cgra之间数据重叠量对缩放因子进行修正;
202)通过cgra中的迭代次数对缩放因子进行修正;
203)同时考虑数据重叠和迭代次数的影响对缩放因子进行修正。
本发明进一步的改进在于,步骤201)具体实现方法如下:
假设有两个分区实际上的命中数是由以下公式所得:
式中
通过重叠数据量对其放缩因子进行修正,修正公式如下:
式中
本发明进一步的改进在于,步骤202)具体实现方法如下:
实际的命中数由下式给出:
u*=u×n(7)
式中n为迭代次数;
因此对缩放因子的修正公式如下:
式中n1和n2分别为分区1和分区2迭代次数。
本发明进一步的改进在于,步骤203)具体实现方法如下:
同时考虑到数据重叠和迭代次数的影响,可得到下式:
本发明具有如下有益的技术效果:
本发明面向可重构处理器,在原先的分区方法中新加入了数据的重叠量和迭代次数的统计,对其进行修正和改进,一定程度上避免了多cgra平台中cgra之间数据的重叠和计算不平衡的不利影响,提高了在可重构处理器中缓存的性能。
无效缩放(fc)可以精确分区整个缓存,同时有大量分区仍然保持高关联性。高速缓存行的无用表示行对其应用程序性能的无用,并且可以通过各种策略进行排序。通过缩放属于不同分区的缓存行的无用性,fs可以调整不同分区的驱逐,从而控制这些分区的大小。通过总是从完整的候选列表中逐出具有最大规模无用功能的缓存行,fs可以保留大量有用行,从而保持高关联性。
传统分区方法中,重叠数据量在求和中抵消了,无法对其分区比例进行改变,通过引入重叠数据量这一参数对fs缩放因子进行修正能够得到更有效的缩放因子,使分区更合理。
引入迭代次数后,能够更精确的得到cgra上的未命中数,如果实际的命中数大于命中计数器所得到的命中数,分区对应的缩放因子会减小,分区的大小趋于增加,性能高的分区可以分配到更多的缓存资源,能精确而精细地对分区大小进行控制,使得性能得以优化。
附图说明
图1一个通用cgra的组成。
图2双cgra平台的硬件框图。
图3性能测试结果。
具体实施方式
主要特点:
1.基于利用率的分区方法(utility-basedcachepartitioning)和无效缩放(futilityscaling),合理划分缓存区域。
2.引入两个新的数据——数据重叠量和迭代次数,并且可通过硬件追踪计算数据。
主要优点
1.结合利用率的分区方法(utility-basedcachepartitioning)和无效缩放(futilityscaling)优点,合理划分缓存区域,将主存中合适的内容放在合适的缓存分区中,提高系统性能。
2.利用数据重叠量和迭代次数对原有缓存划分进行修正,得到更合理的缩放因子α和无效性f,精确而细致地对分区大小进行控制,使性能高的分区会分配更多的缓存资源,优化性能。
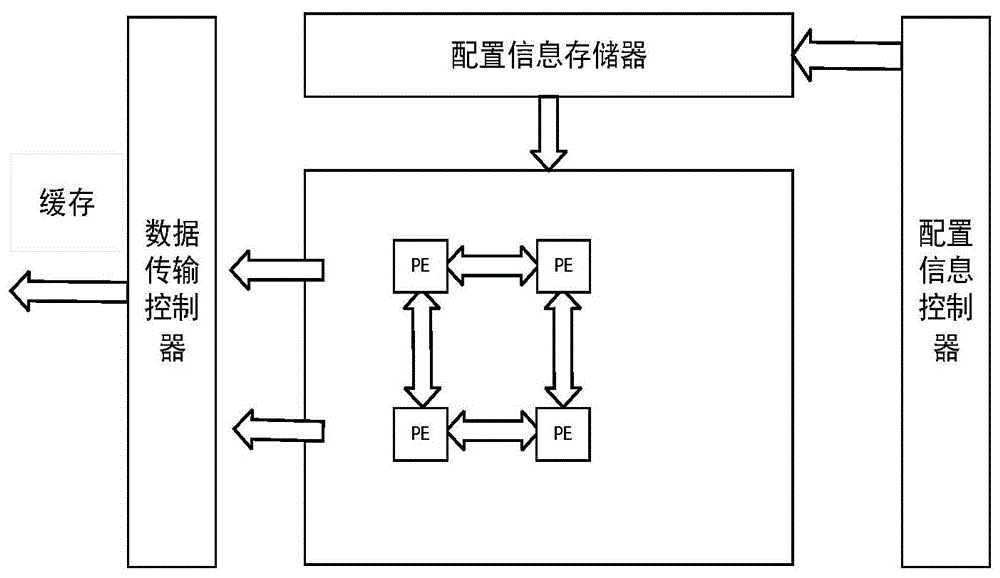
本发明提出的缓存划分方法主要面向可重构处理器,一个通用cgra组成如图1,一个通用的cgra由一个可扩展的pe数组,一个数据传输控制器,一个配置信息存储器和一个配置控制器组成,如图3-2所示。pe数组是cgra的主要部分,每个pe可以动态地被配置为执行字级操作,诸如算术和逻辑操作。pe的操作和pe之间的互连可以在不同的cgra设计中有所不同。数据传输控制器将操作数数据提供给pe阵列。配置信息存储器存储用于配置pe阵列的配置信息。通过更改配置信息,cgra的功能可以在运行时完全动态编程。配置控制器负责调度pe阵列配置信息的执行顺序。缓存划分硬件框图如图2,整个硬件结构由cgra,umon,cmon,imon,mmon,fmon,分区算法,共享缓存组成。
umon为命中率监视器,监视每个cgra的命中数。当cgra发出访问请求,且请求命中,命中计数器加一。
cmon为数据重叠量计数器,监视每个cgra的数据重叠量。当cgra发出访问请求,且请求命中,但是core_id不等于cache_id时,计数器加一。
imon为迭代监视器,在cgra平台中,迭代次数可直接由配置信息得到。
mmon为未命中监视器,两个监视器得到的未命中数比例可作为两个分区的插入比例,以计算缩放因子α。
fmon为无效性监视器,每个块都有一个计数器,每当被访问时计数器归零,其它块的计数器加一,当访问未命中时,被替换的块计数器归零,而其它块加一。计数器的值就是每个块的无效性f。
cgra上得各个监视器将监视到的信息传递给分区算法之后得到分区结果,之后分区算法将分区结果传给共享缓存,对其进行划分。其中基于数据重叠量和迭代次数的缓存划分设计如下:
fs主要是通过缩放每个分区中的候选者的无用性来控制每个分区的大小。每个分区的缩放因子为αi。在每次驱逐中,属于分区i的替代候选者(fcand)的无用性将由αi缩放,其中具有最大gcaledcand(公式1)的行将会被驱逐。
fscalecand=fcand×αi(1)
式中fcand表示替代候选者,αi表示i区缩放因子,fscaledcand表示替代候选者无用性;
假设具有r替换候选者(一般等于缓存的way数),且具有两个分区,插入比率分别为i1和i2,目标比例分别为s1和s2。不失一般性,假设i1<s1,ii=ei(稳定),因此i2>s2。自然地(即,没有缩放),分区的大小比列倾向于与其插入速率成比例。为了将分区2的大小从i2减小到s2,将属于分区2的高速缓存行的无用性按比例因子α2(α2>1)放大,并保持分区1未放缩,即α1=1。
式中α2为分区2缩放因子,i1和i2分别为分区1和分区2插入比率,s1和s2分别为分区1和分区2目标比例,r为替换候选者数;
数据重叠量为cnt,cnt21表示由cgra2发出的请求在cgra1所属的分区上命中的数据量,反之亦然。
有两个分区实际上的命中数是由公式3和4所得:
式中
通过重叠数据量对其放缩因子进行修正。修正公式如下:
式中
迭代次数记为n,可由可重构系统中的配置信息直接给出。在流水线型cgra中,每个cgra都有其对应的迭代次数。
实际的命中数由下式给出:
u*=u×n(7)
因此对缩放因子的修正如公式8和9。
式中n1和n2分别为分区1和分区2迭代次数;
同时考虑到数据重叠和迭代次数的影响,可得到下式:
如果实际的命中数大于命中计数器所得到的命中数,那么分区对应的缩放因子会有所减小,因此分区的行更不容易被驱逐,分区的大小趋于增加。实际命中数大于计数器所得的命中数的分区,即实际的性能高的分区会分配更多的缓存资源,在这种不断驱逐中,精确而精细地对分区的大小进行控制,使得性能得到优化。
【本发明的性能测试】
缓存划分算法的提出就是为了利用通过划分将主存中合适的内容放在合适的缓存分区中,所谓合适就是在通过划分。所以评价一个缓存划分算法的核心指标就是访问命中率(hitrate)或者未命中率(missrate)。对替换和分区算法的执行,cpu主要用来不断发出访问地址,主存存储每个访问地址对应的数据,缓存作为主存的子集也用来存储访问地址对应的数据,而缓存管理电路一方面判断访问地址是否命中,再根据结果发出信号传送相关的数据。本发明在已经拥有使用rtl级verilog代码实现的cache仿真平台用来仿真lru替换策略的基础上,用verilog语言的testbench实现。
本发明使用matlab程序中的rand函数生成比如600个0到599的随机数,并将少部分给核1,大部分给核2。因为是随机数,所以会有部分的数据重叠,即本发明涉及的数据重叠量。通过对不缓存划分和缓存划分的5组随机序列对比,如图所示,平均性能提升达到了25%。
- 还没有人留言评论。精彩留言会获得点赞!