基于症状提取和特征表示的电子病历多标签分类方法与流程
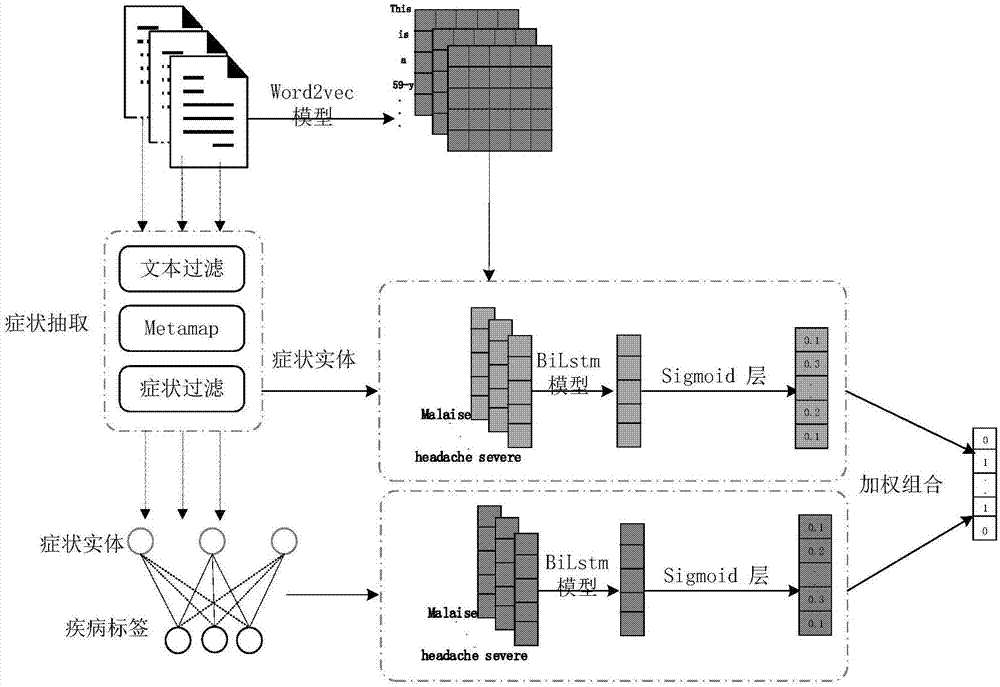
本发明属于医疗大数据分析领域,具体涉及一种基于症状提取和特征表示的电子病历多标签分类方法。
背景技术:
电子病历(electronicmedicalrecord,emr)的多标签分类是医学应用领域中的一项重要任务,其目的是基于电子病历中的症状、检验检测指标、药物、文本等信息自动为电子病历生成疾病标签,不仅可以节省大规模电子病历管理维护的成本,还可以为医学知识挖掘及应用提供便利。基于电子病历的多标签分类也可用于辅助诊断系统、医院导诊系统,极大的提高医生工作效率和缩短病人就诊时间。电子病历的多标签分类依赖于从病历文本中提取的特征,目前存在的方法有基于整个文本信息的,但全文本数据存在大量冗余信息影响分类效果;也有基于文本中记录的检验检测指标、临床数据、医疗编码以及药物等指标信息,但是由于部分电子病历缺乏相关信息,使得这些方法无法使用。
因此,有必要提供一种分类效果和适用性好的电子病历分类方法。
技术实现要素:
本发明所解决的技术问题是,针对现有技术的不足,提供一种基于症状提取和特征表示的电子病历多标签分类方法,分类效果和适用性好。
本发明的技术方案为:
基于症状提取和特征表示的电子病历多标签分类方法,包括以下步骤:
步骤1、获取已知疾病标签的电子病历集合作为样本集;
步骤2、从样本集中提取症状序列(所有的症状构成的序列);将样本集中各个样本与疾病标签的映射关系转换为症状与疾病标签的映射关系;
对于症状i,统计其与多少疾病标签存在映射关系,以及与每个疾病标签存在映射关系的次数(若从一个样本中提取出了症状i,且该样本带有疾病标签j,则认为症状i与疾病标签j存在一次映射关系),并根据统计数据使用tf-idf模型构建其第一症状向量x1i,其中i=1,2,…,m,m为所有症状的个数;
由所有症状的第一症状向量构成症状向量序列x1,x1={x11,x12,…,x1i,…,x1m};
步骤3、基于样本集中的电子病历文本训练word2vec模型,训练完成之后,使用word2vec模型将每个症状映射为一个症状向量,称为第二症状向量,其中症状i映射得到的第二症状向量记为x2i;由所有症状的第二症状向量构成症状向量序列x2,x2={x21,x22,…,x2i,…,x2m};
步骤4、对于样本集中的每一个电子病历,分别构建其对应的第一症状向量序列、第二症状向量序列和疾病标签向量;
构建一个电子病历对应的第一症状向量序列和第二症状向量序列的方法为:
首先从其中提取症状序列;然后对于症状序列中的每一个症状k,分别从x1和x2中找出其第一症状向量x1k和第二症状向量x2k;由症状序列中所有症状的第一症状向量构成该电子病历对应的第一症状向量序列x′1={x1k},所有症状的第二症状向量构成该电子病历对应的第二症状向量序列x′2={x2k},其中k∈{1,2,…,m};
构建电子病历的疾病标签向量,其维数等于所有疾病标签的个数n,每一维度对应一个疾病标签,若该电子病历带有某一疾病标签,则疾病标签向量中相应维度的取值为1,若该电子病历不带某一疾病标签,则疾病标签向量中相应维度的取值为0;
步骤5、训练两个双向lstm(longshort-termmemory,长短期记忆)模型;训练过程为:
将样本对应的第一症状向量序列和疾病标签向量作为第一双向lstm模型的输入序列和输出,训练第一双向lstm模型;
将样本对应的第二症状向量序列和疾病标签向量作为第二双向lstm模型的输入序列和输出,训练第二双向lstm模型;
每一个训练好的双向lstm模型的输出都是一个概率向量,表示与输入的症状向量序列相应的电子病历与各种疾病标签相关的概率;
步骤6、对于未知疾病标签的电子病历,首先构建其对应的第一症状向量序列和第二症状向量序列(按步骤4中的方法);再将其对应的第一症状向量序列和第二症状向量序列分别输入两个训练好的双向lstm模型,得到两个概率向量;最后,对两个概率向量进行加权组合,得到最终的分类向量,表征该电子病历与各种疾病标签相关的概率。
进一步地,所述步骤1中,从mimic-iii数据集中获取出院总结作为样本。
进一步地,所述步骤2和步骤5中,基于metamap工具从电子病历中提取症状序列。
进一步地,基于metamap工具从电子病历中提取症状序列前,先根据电子病历各部分的标题过滤掉不包含症状信息的部分,然后使用metamap处理,方法为:首先根据语义类型过滤掉与症状无关的实体,筛选出症状实体,再根据上下文环境从筛选出的症状实体中过滤掉在否定语境中的症状实体,从而提取出症状序列。
进一步地,所述步骤2中,第一症状向量x1i=(wi,1,wi,2,...,wi,n),其中wi,j表示症状i和疾病标签j之间的关联强度,
进一步地,所述步骤3中,先对电子病历文本进行预处理,去除文本中的停用词,再基于预处理后的文本训练word2vec模型。
进一步地,所述步骤6中,对两个概率向量进行加权组合计算最终的分类向量时,两个概率向量的权重均设置为0.5。
本发明基于从电子病历中抽取的症状序列并结合两种症状表示方法进行病历的多标签分类。该方法考虑到疾病与症状以及症状间的关联关系对电子病历的疾病标签多分类问题的影响采用两种不同的症状表征方法:使用tf-idf构建症状向量以及使用word2vec学习症状向量。为了更好的从症状序列中提取特征,本发明结合两种症状向量构建方法使用双向lstm对症状序列建模,lstm模型能够处理不同长度的症状序列。本方法不仅避免了文本数据的冗余信息对多标签分类的影响,还解决了在检验检测信息等指标缺失的情况下将多标签分类方法应用于疾病辅助诊断的问题。
以下对各主要步骤进行详细说明。
一、症状的提取
临床记录中文本记录了患者病情,然而,由于文本中语句的多样性和句法的多样性,很难从语料库中准确提取症状。比如,“breathwithdifficulty”、“difficultbreathing”和“dyspnea”均为呼吸困难的意思。书写表达的不规范也给症状的识别带来了困难。在抽取症状时,应注意症状的不规则性和陈诉的多样性。为了提高抽取症状实体的效率和准确率,使用现有的技术,如nltk和metamap。nltk是一个用于符号统计和自然语言处理的工具包。metamap则用于在文本中识别统一医学语言系统(umls)中所包含的实体。umls包含超过100万个生物医学实体和500万个实体名称,每个实体都有语义类型,如临床属性、符号或症状、临床药物等。metamap的重要特性是它可以识别umls中实体的变体和首字母缩写。为了提高metamap的正确性和有效性,本发明对医学文本中没有症状实体的部分以及在否定语境中的症状实体进行了过滤。
在mimic-iii中电子病历分为护士笔记、出院总结等不同类型,本发明使用了出院总结。mimic-iii中每个出院总结都有其对应的疾病标签即icd-9标签。从mimic-iii数据集中的出院总结中提取所有症状实体。虽然电子病历是无结构的文本,但是mimic-iii的出院总结被划分为不同的部分,每个部分都有相关的标题,如当前病史,既往病史、社会史、治疗流程、入院用药、出院诊断等,为了提高处理效率,本发明首先根据标题过滤掉不包含症状信息的部分,如社会病史、入院用药和出院诊断;然后使用metamap处理;metamap不仅可以识别文本中的umls实体词和umls实体词对应的语义类型,还可以判断该实体词上下文环境是否定还是肯定,本发明首先根据语义类型过滤掉与症状无关的实体,提取症状实体,再根据上下文环境过滤掉在否定语境中的症状实体,最终得到本发明所需的所有症状实体。比如,对于“病人报告在入院前有出汗、咳嗽和上背部疼痛症状。并否认出现胸痛、恶心/呕吐、腹泻和排尿困难的症状”这一临床文本,则需要过滤掉“胸痛”、“恶心/呕吐”、“腹泻”和“排尿困难”等患者否定的症状。
二、症状的向量表征
症状的向量表征是本发明中最为关键的一步,因为它决定着多标签分类模型是否能准确提取特征。在本发明中使用了两种症状表示方案。考虑到当患者出现某些症状时,可以根据症状和疾病之间的关系推断出潜在的疾病标签,本发明使用了基于tf-idf的症状表示,其通过统计方法获得症状和疾病之间的关联强度。同时,鉴于症状之间的关联对疾病标签推断也具有潜在影响,本发明还使用了word2vec来获得可以量化症状之间相似性的症状表示。
(1)tf-idf(termfrequency-inversedocumentfrequency,词频-逆向文件频率)
在之前的步骤一中使用metamap提取电子病历中存在的症状实体后,将电子病历与疾病标签的映射关系转换为症状实体与疾病标签的映射关系。所有电子病历与疾病标签的映射都转换为症状实体与疾病标签的映射关系后,就可以统计出症状i与哪些疾病相关联。
tf-idf用于将文本文档转化为标识符的特征向量。本发明使用tf-idf作为症状的向量表示方案,并以此构建症状和疾病之间的关系模型。从出院总结中提取出所有症状之后,每个症状i由一个向量表示,具体表示形式如下:
si=(wi,1,wi,2,...,wi,n)(1)
wi,j为症状i和疾病标签j之间的关联强度,为了获得连续的关联强度,本发明使用tf-idf来量化关联的强度。
n为所有疾病标签的个数,di为与症状i相关联的疾病标签数量(与症状i存在映射关系的疾病标签数量),tfi,j为带有疾病标签j的电子病历中症状i出现的次数。
选择tf-idf作为症状的表示方案是因为wi,j能准确的量化症状与疾病标签之间的关联强度。当某一症状与多个疾病标签相关联时,di将偏大,wi,j将偏小,则该症状的疾病标签推断分类能力将偏弱。
(2)词向量
由于疾病通常伴有多种症状,因此症状之间的关系可以作为疾病标签推断有利依据。例如,咳嗽、呼吸短促和视力下降是常见的症状。通常咳嗽和呼吸短促与各种疾病有关,如支气管炎、肺炎和哮喘。在诊断过程中,这两种症状可能同时出现。即使患者没有同时出现这两种症状,医生通常也会在电子病历中记录相似症状的表现情况。因此,症状之间的关联为疾病推断提供了有利的依据。word2vec模型是无监督人工神经网络(ann)框架,用于获得能够量化语义相似性的词向量表示。为了表示症状之间的相似性和差异性,本发明使用出院总结训练word2vec模型,获取出院总结中所有词的词向量,从而得到症状的词向量(一个症状对应一个词向量,所有症状对应的词向量的维度相等;相似性高的两个症状,它们对应的词向量欧氏距离小),即另一种症状向量表示方案,在此之前,需要去除出院总结中的停用词。
三、双向lstm(bilstm)模型
在本发明中,电子病历的多标签分类问题针对给定电子病历,根据从出院总结中提取的症状序列推断该病历的疾病标签,最后选出概率大于指定阈值的疾病标签作为多标签分类结果。
深度学习技术已经广泛应用于临床领域,尤其是循环神经网络,它能高效的处理序列任务、视觉任务、语音任务和自然语言处理任务。然而,在医学应用领域,很多任务处理的序列数据存在长期依赖。循环神经网络处理较长的序列的能力受到梯度下降问题的限制。为了解决这一问题,本发明使用了具有双向结构的长短期记忆网络(lstm)。双向结构能够提取全局特征,在长序列处理中得到了广泛的应用。lstm同时也解决了长期依赖的问题。以下公式给出了每个步骤的计算流程:
ft=σ(wf1·xt+wf2·ht-1+bf)(3)
it=σ(wi1·xt+wi2·ht-1+bi)(4)
ot=σ(wo1·xt+wo2·ht-1+bo)(5)
gt=tanh(wg1·xt+wg2·ht-1+bg)(6)
ct=ft·ct-1+it·gt(7)
ht=ot·tanh(ct)(8)
其中,xt表示第t步输入的症状向量;ft、it、ot、gt、ct、ht分别表示第t步的遗忘门、输入门、输出门、中间变量、细胞状态(cellstate)和隐藏状态(hiddenstate);f、i和o用于控制数据流在lstm中的传递,c和h表示输入数据在lstm中的状态;t取值为1到症状序列的长度;wf1和wf2、wi1和wi2、wo1和wo2、wg1和wg2分别为遗忘门、输入门、输出门、中间变量的两个权重矩阵,bf、bi、bo和bg分别为遗忘门、输入门、输出门、中间变量的偏置向量,权重矩阵和偏置是需要训练的参数,通过正太分布进行初始化,使用adam算法迭代更新;σ(·)和tanh(·)为激活函数,σ(·)表示sigmoid函数,tanh(·)为双切正切函数,取值范围为[-1,1];h0、c0设置为满足正太分布的随机值;
本发明将正向lstm和反向lstm的最终输出的隐藏状态拼接为输入的症状向量序列的全局特征(将两种类型的症状向量序列分别输入两个双向lstm模型,可以获得两种类型的全局特征),然后把全局特征放到带有sigmoid激活单元的输出层,得到概率向量,概率向量的每一维度的值表示输入的症状向量序列与该维度对应的疾病标签相关的概率;具体描述如下:
1)将症状向量序列中的第一至最后一个症状向量按顺序依次作为第一至最后一步的输入双向lstm模型的症状向量,最后一步得到的ht即为正向lstm的最终输出的隐藏状态,记为hforward;
将症状向量序列中的第一至最后一个症状向量按倒序依次作为第一至最后一步的输入双向lstm模型的症状向量,最后一步得到的ht即为反向lstm的最终输出的隐藏状态,记为hbackward;
2)将hforward和hbackward拼接为症状序列的全局特征,记为hconcatenate;设hforward和hbackward的维度为l,则hconcatenate的维度长度为2l;
3)把全局特征hconcatenate放到输出层,在输出层,hconcatenate首先被映射为维度为n(所有疾病标签的数量)的输出向量output(该过程可以表示为用大小为n×2l的参数矩阵w与hconcatenate相乘,得到output),此时输出向量中元素的取值范围为实数域;然后通过sigmoid函数将output的每一维度的值从实数域映射到0-1之间,得到概率向量。
对于未知疾病标签的电子病历,将从中提取的症状序列对应的两种症状向量序列,分别输入两个训练好的双向lstm模型,得到两个概率向量;最后对两个概率向量进行加权组合,得到最终的分类向量,表征该电子病历与各种疾病相关的概率。
有益效果:
本发明基于症状实体和特征表示进行电子病历的多标签分类。
因为症状信息反应了疾病的存在和特点以及病人的状况,所以作为初步诊断所依赖的可靠信息,症状会被记录在病历中。本发明通过症状进行电子病历的多标签的分类更加可靠,适用性更好。
不同的症状表示方法会影响电子病历的分类效果。本发明考虑症状与疾病的关联强度对分类的影响,使用tf-idf构建症状向量作为输入训练双向lstm模型;考虑到症状间的关联关系对分类的影响,使用了word2vec学习症状向量作为输入训练双向lstm模型。最后结合已训练好的两个双向lstm模型做最终的多标签分类。
因此,本发明不仅提取了电子病历文本中的症状作为特征,还考虑了症状与疾病的关联关系、症状间的关联关系对分类的影响,充分发挥了症状在电子病历分类中的作用,方法有效且准确性高。此外本方法不仅避免了全文本数据中冗余信息对分类的影响,还可以应用在病历文本中检验检测信息缺失的情况下电子病历的多标签分类。
附图说明
图1:本发明的流程图;
图2:双向lstm网络结构图;
图3:不同权重分布的组合结果;图3(a)~图3(d)分别为第一双向lstm模型(bilstm+tf-idf)取不同权重时mif1、microauc、maf1、macroauc这4个评价指标的结果。
具体实施方式
以下结合附图和具体实施方式对本发明进行进一步具体说明。
本发明公开了一种基于症状提取以其表征模型并使用双向循环的电子病历多标签分类方案。不仅症状与疾病之间的关联关系对电子病历的多标签分类很重要,同样,症状之间的关联关系也影响着电子病历的多标签分类,基于此,本发明结合了考虑了症状与疾病之间的关联关系的tf-idf症状表示方案和考虑了症状之间的关联关系的word2vec症状表示方案。使用了metamap提取电子病历中的症状实体。采用了双向长短期记忆网络(bilstm)对提取得到的症状序列进行建模,模型输出所有标签的概率并根据阈值选择相关标签。本发明根据电子病历中症状实体进行多标签分类可以避免文本冗余信息的干扰提高多标签分类效果。
本发明有效性验证:
为了验证使用本发明【以下称为bilstm+symvec(tf-idf+word2vec)】进行多标签分类的有效性和相比于其他方法的性能优越性,将本方法应用于minic-iii数据集的出院总结中常见的50种疾病和100种疾病标签进行分类。将方法bilstm+symvec(tf-idf+word2vec)与bilstm+symvec、bilstm+symvec(tf-idf)、bilstm+symvec(word2vec)和deeplabeler等4个其他方法在预测的微平均准确率(mip)、微平均召回率(mir)、微平均f1(mif1)、微平均曲线下面积(microauc)、宏平均准确率(map)、宏平均召回率(mar)、宏平均f1(maf1)和宏平均曲线下面积(macroauc)等8个评价指标进行了比较。其中mip、mir、mif1、map、mar和maf1的计算公式如下:
其中,
deeplabeler和bilstm+word2vec都以全文本作为输入,其中bilstm+word2vec使用word2vec来表示全文的单词序列,使用全文的单词序列作为输入。为了与这两个模型进行比较,本发明使用了不同症状表示方案的bilstm:使用tf-idf的bilstm和使用word2vec的bilstm。然后将这两个模型组合为bilstm+symvec(tf-idf+word2vec)即本发明中使用的模型,其为bilstm+symvec(tf-idf)和bilstm+symvec(word2vec)的输出得分的加权和,权重为0.5。
表1不同模型在50种常见疾病标签的分类性能(微平均)
表2不同模型在100种常见疾病标签的分类性能(微平均)
表3不同模型在50种常见疾病标签的分类性能(宏平均)
表4不同模型在100种常见疾病标签的分类性能(宏平均)
如表1所示,本发明提出的模型优于deeplabeler和bilstm+word2vec,这说明症状在多标签分类中起着重要的作用。与仅使用tf-idf和word2vec的bilstm相比,bilstm+symvec(tf-idf+word2vec)的结果得到进一步改善。这是因为bilstm可以很好地从tf-idf和word2vec的症状表示方案中提取不同类型的全局特征。本发明还对100种常见的疾病标签进行了相同的实验,如表2所示,本发明的模型在所有指标上的表现也都优于其他模型,进一步表明模型bilstm+symvec(tf-idf+word2vec)是最好的。表1和表2的结果显示,不管是在50种常见疾病还是在100种常见疾病的多标签分类的表现,bilstm+symvec都要优于deeplabeler和bilstm+word2vec,尤其是组合了tf-idf和word2vec的bilstm+symvec(tf-idf+word2vec)的结果是最好的。多标签分类的宏平均评估结果如表3和表4所示,可得到与前面微平均一致的结论。但宏平均各项指标的值都比微平均小,尤其是在常见100种疾病标签的分类结果。原因是宏平均指标更容易受到样本数较小标签的影响,微平均指标更容易受到样本数较多的标签的影响。
为了进一步分析tf-idf和word2vec的权重变化对多标签分类结果的影响,比较了bilstm+symvec(tf-idf+word2vec)与不同权重分布的结果。
如图3所示,当第一双向lstm模型(bilstm+tf-idf)的权重从0.3变化为0.8时,所有四个指标的结果都相当相近。当权重在0.5和0.7之间时,结果最佳。因此,在本发明中,将0.5设置为默认权重。
综上所述,本发明所提出的基于双向循环和症状提取的电子病历多标签分类方法在预测的性能、准确性、实际应用等方面都具有重要作用。
- 还没有人留言评论。精彩留言会获得点赞!