一种结合心率与面部表情面向游戏用户的非接触式情感识别方法与流程
本发明属于情感识别领域,特别涉及一种结合心率与面部表情面向游戏用户的非接触式情感识别方法。
背景技术:
游戏由于呈现的消息具有互动性和有趣性而吸引了越来越多的用户,游戏的主要目标就是为用户提供情感体验,如乐趣和兴奋等,而情感识别能够得到用户在游戏过程中的实时情感来调整游戏难度或内容从而保证用户的参与度,以增强游戏体验。目前情感识别主要通过两种途径实现,一是通过获取被测试对象的情感行为,如面部表情,面部微动作,语音等;二是通过检测被测试对象的生理信号,如心率、心率变异性等。然而,人的表情可以受到自身控制,仅依靠表情判断其情感状态的真实性和可靠性较低。通常生理信号不受主观意识支配,用来进行情感识别更具客观性。研究表明结合面部信息与生理信号能得到更好的识别效果。对游戏用户进行情感识别,需要做到不干扰用户的游戏进程以保持他/她的参与度从而得到用户的真实情感。一方面目前大量的情感识别方法都是侵入式的,导致被测者产生一定的心理负担,使识别结果与被测者真实的情感有所偏差;另一方面人的情感是通过持续的方式感知的,因此以连续的方式判别人的情感更为准确。
技术实现要素:
本发明的目的在于获得用户的真实情感以及时调整游戏的行为以最大化用户的娱乐或学习,提出了一种结合心率与面部表情面向游戏用户的非接触式情感识别方法,包括心率的频率计算和模式分类,人脸面部表情的识别以及融合心率与面部表情的情感判定,它可以实现对“兴奋”、“愤怒”、“悲伤”、“平静”四种情绪的非接触式识别并达到了87.3%的平均识别准确率,同时心率频率反映了情感的强烈程度。
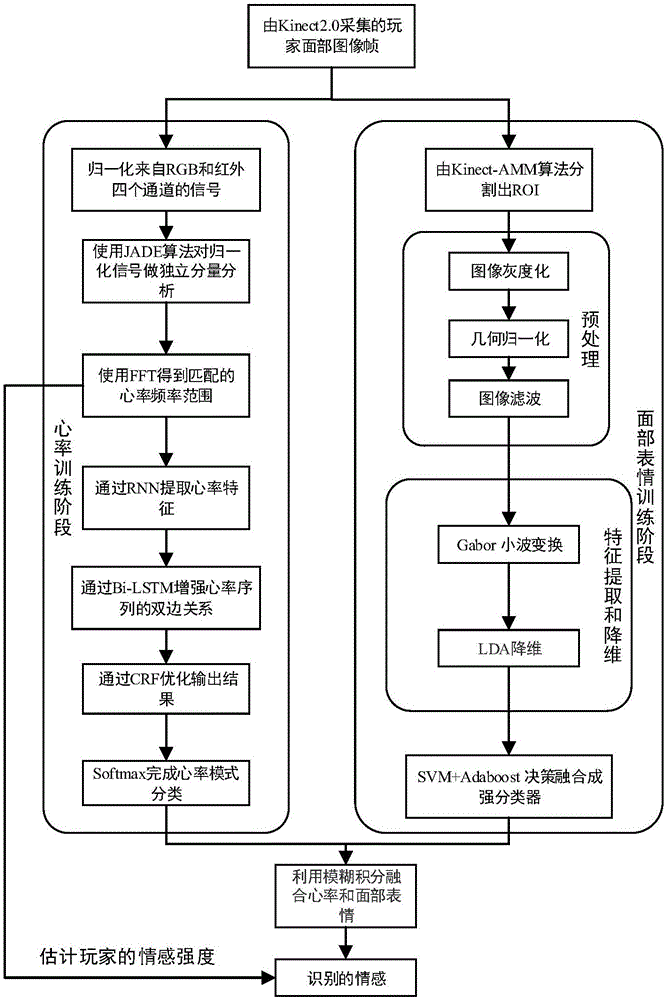
一种结合心率与面部表情面向游戏用户的非接触式情感识别方法,包括心率的频率计算和模式分类,人脸面部表情的识别以及融合心率与面部表情的情感判定;该方法包括如下步骤:
s1.信息采集阶段:使用kinect2的rgb(red-green-blue)颜色摄像头和红外摄像头采集玩家的面部信息;
s2.心率训练阶段:对采集的rgb数据和红外数据利用jade(jointapproximationdiagonalizationofeigen-matrices,特征矩阵联合相似对角化)算法和fft(fastfouriertransform,快速傅里叶变换)计算出玩家的心率频率范围,再通过rnn(recurrentneuralnetwork,递归神经网络)和bi-lstm-crf(bidirectionallongandshorttermmemorynetworkconditionalrandomfield,双向长短期记忆网络条件随机场)识别心率包含的情感,最后通过softmax分类器实现心率模式的分类;
s3.面部表情训练阶段:利用kinectamm算法对采集到的人脸视频帧实时分割出roi(regionofinterest,感兴趣区),接着对经过预处理的roi进行gabor函数特征提取和lda(lineardiscriminantanalysis,线性判别分析)降维,再通过svm(supportvectormachine,支持向量机)和adaboost(迭代算法)融合成的强分类器实现面部表情的分类;s4.情感判定阶段:先利用心率频率和面部表情识别结果根据情感判定规则(如表1所示)对玩家的情感进行初步判断,提前检测最终识别情感的正确性;再利用模糊积分融合心率和面部表情进行情感判定。
表1情感判定规则
进一步的,所述步骤s1具体包括:待玩家(身体状况良好)的心率趋于正常值后,玩家在环境光条件下保持身体正直坐于电脑前进行游戏,玩家位于kinect2的检测范围内同时保持玩家的面部能被kinect2的摄像头捕捉到,使用rgb颜色摄像头和红外摄像头以30fps(framepersecond,帧/秒)的工作频率,连续采集玩家30秒内的面部信息。
进一步的,所述步骤s2包括以下步骤:对从rgb和红外四个通道采集到数据的信号进行归一化,再使用jade算法对四个通道信号的归一化值进行独立分量分析实现信号的分离,独立分量分析的步骤如下所示:
①形成样本协方差
②形成白化过程
③通过归一化矩阵
④可以估计
再对经过分离的四个独立分量信号调用fft得到匹配的心率频率范围。我们使用rnn将具有速度和方向的连续动作心率信号点序列(n个采集点)编码为矢量并将其记录为{hn}。当前的输出是由视频序列、当前输入和先前状态确定的。一般情况下,假定当前给定的输入由下列等式表示:x={x1,x2,…,xt,…,xt},在这个方程中,t代表第t帧,t代表总帧数。我们可以得到:
ht=σh(wxhxt+whhht-1+bh)
式中ht表示隐藏层在t时刻的输出,wxh表示代表从输入层到隐藏层的权重矩阵,whh表示来自隐藏层的权重矩阵,bh表示隐藏层的偏差,σh表示激活函数,最后我们可以得出下式:
yt=σy(whoht+bo)
式中yt表示第t个序列的预测标签,who表示从隐藏层到输出的权重矩阵,bo代表了输出的偏差,σy表示激活函数。
除了外部rnn循环,lstm还具有内部“lstm细胞”循环(自循环)。因此,lstm不会简单地将非线性元素应用于输入和循环单元的变换。然而,自循环本身的权重(或相关的时间常数)由遗忘门
式中x(t)是当前的输入矢量,h(t)是当前隐藏层的矢量并且包含lstm细胞的所有输出,bf,uf和wf分别为偏置,输入权重和遗忘门的循环权重。因此,lstm细胞的内部状态如下更新,其中存在条件自环权重
式中b,u和w分别是lstm细胞中遗忘门的偏差,输入权重和循环权重,外部输入门单元
lstm细胞的输出
式中b°,u°和w°分别是偏置,输入权重和遗忘门的循环权重,在b°,u°和w°这些变量中,你可以选择使用细胞状态
yt=σ(ht)
式中
进一步的,所述步骤s3包括以下步骤:利用kinectamm算法对捕捉的人脸图像帧实时分割出roi,roi由5个面部特征点确定:左眼、右眼、鼻子和左右嘴角5个特征点;再对roi进行图像灰度化,几何归一化,图像滤波这些预处理,成为归一化的标准图像,再用圆形高斯包络gabor小波变换对标准图像进行特征提取,gabor小波变换的内核函数定义如下:
式中i是复数运算符,σ是高斯窗口的宽度与正弦波波长的比值,
式中
再采用线性鉴别分析算法进行降维,lda算法可以从高维特征空间里提取出最具有判别能力的低维特征,这些特征能帮助将同一个类别的所有样本聚集在一起,并将不同类的样本尽量地分开,即选择使得样本类间离散度和样本类内离散度的比值最大的特征。lda算法如下:设一组训练样本的列矢量集为:
定义训练样本的类间与类内距离之比为:
lda的目标就是要求出j(wl)取最大值时对应的特征向量。因此,对j(wl)按变量wl求导并令其为∧,即可得出所要求的wl,wl也可由如下等式求出。
sbwl=swwl∧
人脸图像帧经过gabor的特征提取和lda的降维后,需要对其进行分类才能得到面部表情识别结果。svm的基本思想是将训练样本经非线性变换映射到另一高维空间中,在变换后的高维空间内寻找一个最优的分界面,不但能将训练样本无错误或接近无错误分开,而且使类与类之间的间隙最大化,利用svm的优势可以解决小样本数据的分类问题,但对于新增训练样本的分类,往往需要借助较为复杂的算法提高其准确度。adaboost训练以分类最小错误率为标准,不断加大分类错误类别的权值,经过t次迭代,逐渐加强分类器的分类能力,对svm有较好的的提升效果。
假设有两类训练样本m个,在某维空间rn线性可分,则将训练样本分开的平面(超平面)满足:
w·x+b=0,w∈rn
在满足条件的超平面中,找到能较好分开两类训练样本且错误率较小的平面,即
式中:ξ为松弛变量,c为使用者选定的正参数,求出最优解w*和b*,得到svm的决策函数:
式中,
本发明采用的核函数是径向基核函数:k(xi,x)=exp(-‖xi-xj‖2/2σ2),由于只有一个参数,可降低计算复杂度。将svm推广到多类,在每一对类别之间都训练一个svm,按照投票方式得出结果。再利用adaboost训练加强svm分类器的分类能力。首先归一化各个svm分类器的权重:
εj=∑jwj|hj(x)-yj|
式中yj是训练样本,在计算的所有错误率中求出最小错误率εmin,若分类错误,按下式更新权重:
经过t次上述更新权重的步骤后,错误率小的分类器被赋以较小的权值,错误率高的分类器被赋以较大的权值,从而提升了分类器的分类能力,进而使得识别率得到有效的提高。
所述步骤s4包括以下步骤:
首先利用心率频率和面部表情识别结果根据情感判定规则(如表1所示)对玩家的情感进行初步判断,提前检测最终识别情感的正确性;再利用模糊积分将两种不同模态的决策信息(心率和面部表情)进行融合,得到最终的情感识别结果,模糊积分的关键是模糊密度的确定和判决模糊密度刻画分类器在融合过程中的重要性,本发明利用训练样本先验静态信息结合各传感器判决包含的动态信息对模糊密度进行自适应动态赋值,原理如下:
设总共有n个传感器{s1,s2,…,sn},m类目标{w1,w2,…,wm},对一待识别目标x,传感器si输出的识别结果di(x)=[di1(x),di2(x),…,dim(x)]是目标x属于各类目标的信度,利用sugeno模糊积分进行融合,对模糊密度进行自适应动态赋值的过程如下:
(1)根据各传感器对训练样本的识别结果对每个传感器定义一个系ai(x),ai(x)表示了传感器si对目标x的识别结果的置信度系数,反映了目标x在传感器si的特征空间中处于非重叠区域的可能性;
其中
(2)模糊密度
根据训练样本采用式(2)对各传感器的模糊密度确定初始值,设为
(3)对待识别目标x,根据各传感器识别结果利用式(1)计算各传感器的系数ai(x);
(4)将各传感器模糊密度的初始值乘于各自对应的系数ai(x)作为对目标x进行融合识别时各传感器的模糊密度
本发明相对于现有技术具有如下的优点及效果:
本发明提出了一种结合心率与面部表情面向游戏用户的非接触式情感识别方法,用kinect2的rgb颜色摄像头和红外摄像头实现了玩家面部信息的非接触式采集并且红外摄像头减少了光照条件的干扰,融合了心率与面部表情提高了情感识别的准确度和可靠性,对玩家进行连续30秒的情感识别符合人的情感被持续感知的特点,这些都增强了情感识别结果的真实性,它可以实现对“兴奋”、“愤怒”、“悲伤”、“平静”四种情绪的非接触式识别并达到了较高的平均识别准确率,同时心率频率反映了情感的强烈程度。
附图说明
图1是面向游戏评估结合心率与面部表情的非接触式情感识别方法流程图。
具体实施方式
以下结合实施例对本发明作进一步详细的描述,但本发明的实施方式不限于此,以下若有未特别详细说明之处,均是本领域技术人员可参照现有技术实现或理解的。
一种结合心率与面部表情面向游戏用户的非接触式情感识别方法,包括如下步骤:
s1.信息采集阶段:使用kinect2的rgb(red-green-blue)颜色摄像头和红外摄像头采集玩家的面部信息;
s2.心率训练阶段:对采集的rgb数据和红外数据利用jade(jointapproximationdiagonalizationofeigen-matrices)算法和fft(fastfouriertransform)计算出玩家的心率频率范围,再通过rnn(recurrentneuralnetwork)和bi-lstm-crf(bidirectionallongandshorttermmemorynetworkconditionalrandomfield)识别心率包含的情感,最后通过softmax实现心率模式的分类;
s3.面部表情训练阶段:利用kinectamm算法对采集到的人脸视频帧实时分割出roi(regionofinterest),接着对经过预处理的roi进行gabor特征提取和lda(lineardiscriminantanalysis)降维,再通过svm(supportvectormachine)+adaboost融合成的强分类器实现面部表情的分类;
s4.情感判定阶段:先利用心率频率和面部表情识别结果根据我们的情感判定规则(如表1所示)对玩家的情感进行初步判断,提前检测最终识别情感的正确性;再利用模糊积分融合心率和面部表情进行情感判定。
所述步骤s1具体包括:
待玩家(身体状况良好)的心率趋于正常值后,玩家在环境光条件下保持身体正直坐于电脑前进行游戏,玩家位于kinect2的检测范围内同时保持玩家的面部能被kinect2的摄像头捕捉到,使用rgb颜色摄像头和红外摄像头以50fps(framepersecond)的工作频率连续采集玩家30秒内的面部信息。
进一步的,所述步骤s2包括以下步骤:对从rgb和红外四个通道采集到的数据信号进行归一化,再使用jade算法对其进行独立分量分析实现信号的分离,独立分量分析的步骤如下所示:
①形成样本协方差
②形成白化过程
③通过归一化矩阵
④可以估计
再对经过分离的四个独立分量信号调用fft得到匹配的心率频率范围。我们使用rnn将具有速度和方向的连续动作心率信号点序列(n个采集点)编码为矢量并将其记录为{hn}。当前的输出是由视频序列、当前输入和先前状态确定的。一般情况下,假定当前给定的输入由下列等式表示:x={x1,x2,…,xt,…,xt},在这个方程中,t代表第t帧,t代表总帧数。我们可以得到:
ht=σh(wxhxt+whhht-1+bh)
式中ht表示隐藏层在t时刻的输出,wxh表示代表从输入层到隐藏层的权重矩阵,whh表示来自隐藏层的权重矩阵,bh表示隐藏层的偏差,σh表示激活函数,最后我们可以得出下式:
yt=σy(whoht+bo)
式中yt表示第t个序列的预测标签,who表示从隐藏层到输出的权重矩阵,bo代表了输出的偏差,σy表示激活函数。
除了外部rnn循环,lstm还具有内部“lstm细胞”循环(自循环)。因此,lstm不会简单地将非线性元素应用于输入和循环单元的变换。然而,自循环本身的权重(或相关的时间常数)由遗忘门
式中x(t)是当前的输入矢量,h(t)是当前隐藏层的矢量并且包含lstm细胞的所有输出,bf,uf和wf分别为偏置,输入权重和遗忘门的循环权重。因此,lstm细胞的内部状态如下更新,其中存在条件自环权重
式中b,u和w分别是lstm细胞中遗忘门的偏差,输入权重和循环权重,外部输入门单元
lstm细胞的输出
式中b°,u°和w°分别是偏置,输入权重和遗忘门的循环权重,在b°,u°和w°变量中,你可以选择使用细胞状态
yt=σ(ht)
式中
所述步骤s3包括以下步骤:
利用kinectamm算法对捕捉的人脸图像帧实时分割出roi,roi由5个面部特征点确定:左眼、右眼、鼻子和左右嘴角5个特征点;再对roi进行图像灰度化,几何归一化,图像滤波预处理,使图像成为归一化的标准图像,再用圆形高斯包络gabor小波变换进行特征提取,gabor小波变换的内核函数定义如下:
式中i是复数运算符,σ是高斯窗口的宽度与正弦波波长的比值,
式中
再采用线性鉴别分析(lineardiscriminantanalysis,lda)算法进行降维,lda算法可以从高维特征空间里提取出最具有判别能力的低维特征,这些特征(左右眼,鼻子,左右嘴角)能帮助将同一个类别的所有样本聚集在一起,别的样本尽量地分开,即选择使得样本类间离散度和样本类内离散度的比值最大的特征。lda算法如下:设一组训练样本的列矢量集为:
定义训练样本的类间与类内距离之比为:
lda的目标就是要求出j(wl)取最大值时对应的特征向量。因此,对j(wl)按变量wl求导并令其为∧,即可得出所要求的wl,就是满足如下等式的解。
人脸图像帧经过gabor的特征提取和lda的降维后,需要对其进行分类才能得到面部表情识别结果。svm的基本思想是将训练样本经非线性变换映射到另一高维空间中,在变换后的高维空间内寻找一个最优的分界面,不但能将训练样本无错误或接近无错误分开,而且使类与类之间的间隙最大化,利用svm的优势可以解决小样本数据的分类问题,但对于新增样本的分类,往往需要借助较为复杂的算法提高其准确度。adaboost训练以分类最小错误率为标准,不断加大分类错误类别的权值,经过t次迭代,逐渐加强分类器的分类能力,对svm有较好的的提升效果。
假设有两类训练样本m个,在某维空间rn线性可分,则将训练样本分开的平面(超平面)满足:
w·x+b=0,w∈rn
在满足条件的超平面中,找到能较好分开两类样本且错误率较小的平面,即
式中:ξ为松弛变量,c为使用者选定的正参数,求出最优解w*和b*,得到svm的决策函数:
式中,
本发明采用的核函数是径向基核函数:k(xi,x)=exp(-‖xi-xj‖2/2σ2),由于只有一个参数,可降低计算复杂度。将svm推广到多类,在每一对类别之间都训练一个svm,按照投票方式得出结果。再利用adaboost训练加强svm分类器的分类能力。首先归一化各个svm分类器的权重:
εj=∑jwj|hj(x)-yj|
式中yj是训练样本,在计算的所有错误率中求出最小错误率εmin,若分类错误,按下式更新权重:
经过t次上述更新权重的步骤后,错误率小的分类器被赋以较小的权值,错误率高的分类器被赋以较大的权值,从而提升了分类器的分类能力,进而使得识别率得到有效的提高。
所述步骤s4包括以下步骤:
首先利用心率频率和面部表情识别结果根据情感判定规则(如表1所示)对玩家的情感进行初步判断,提前检测最终识别情感的正确性;再利用模糊积分将两种不同模态的决策信息(心率和面部表情)进行融合,得到最终的情感识别结果,模糊积分的关键是模糊密度的确定和判决模糊密度刻画分类器在融合过程中的重要性,本发明利用训练样本先验静态信息结合各传感器判决包含的动态信息对模糊密度进行自适应动态赋值,原理如下:
设总共有n个传感器{s1,s2,…,sn},m类目标{w1,w2,…,wm},对一待识别目标x,传感器si输出的识别结果di(x)=[di1(x),di2(x),…,dim(x)]是目标x属于各类目标的信度,利用sugeno模糊积分进行融合,对模糊密度进行自适应动态赋值的过程如下:
(1)根据各传感器对训练样本的识别结果对每个传感器定义一个系ai(x),ai(x)表示了传感器si对目标x的识别结果的置信度系数,反映了目标x在传感器si的特征空间中处于非重叠区域的可能性;
其中
(2)模糊密度
根据训练样本采用式(2)对各传感器的模糊密度确定初始值,设为
(3)对待识别目标x,根据各传感器识别结果利用式(1)计算各传感器的系数ai(x);
(4)将各传感器模糊密度的初始值乘于各自对应的系数ai(x)作为对目标x进行融合识别时各传感器的模糊密度
经过步骤s1,s2,s3,s4后,结合心率与面部表情面向游戏用户的非接触式情感识别方法在实验测试中得到如表2所示的识别准确率。
表2四种情感的识别准确率
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!