一种旋转机械故障数据集属性权重的确定及评价方法与流程
本发明涉及一种旋转机械故障数据集属性权重的确定及评价方法,具体涉及粗糙集属性重要度理论和旋转机械滚动轴承、齿轮箱故障诊断方法。
背景技术:
滚动轴承和齿轮箱是旋转机械设备容易发生故障的主要部件,由于缺少针对这些部件的检测诊断环节或者检测技术落后,极有可能引发大型机组的安全生产事故,造成极大的经济财产损失,因此对滚动轴承和齿轮箱的早期故障诊断是一个主要的研究领域。
针对旋转机械的故障诊断方法主要有三类:基于知识的故障诊断方法、基于解析模型的故障诊断方法和基于信号处理的故障诊断方法。基于知识的故障诊断方法适应于不易建立机理模型、传感器数目不足、信息缺乏的系统。基于解析模型的方法适应于传感器数目充足、信息充足的系统,需要充分了解过程的机理,并能够建立精确的定量数学模型。基于知识和基于解析的故障诊断方法常用于监控过程参数较少的情况。随着过程参数的增加,目前较为流行的故障诊断方法是基于数据驱动的故障诊断方法。
波形、峰值、脉冲、裕度和峭度是用于旋转机械故障诊断的5个重要的无量纲指标,基于无量纲指标的故障诊断方法是一类重要的数据驱动故障诊断方法。在利用机器学习、证据理论等方法和无量纲指标进行故障诊断时,通常要先确定无量纲指标权重,因此,提供一种无量纲指标属性权重确定方法显得尤为必要。
技术实现要素:
本发明所要解决的技术问题是克服现有技术的缺陷,提供一种旋转机械故障数据集属性权重的确定及评价方法。
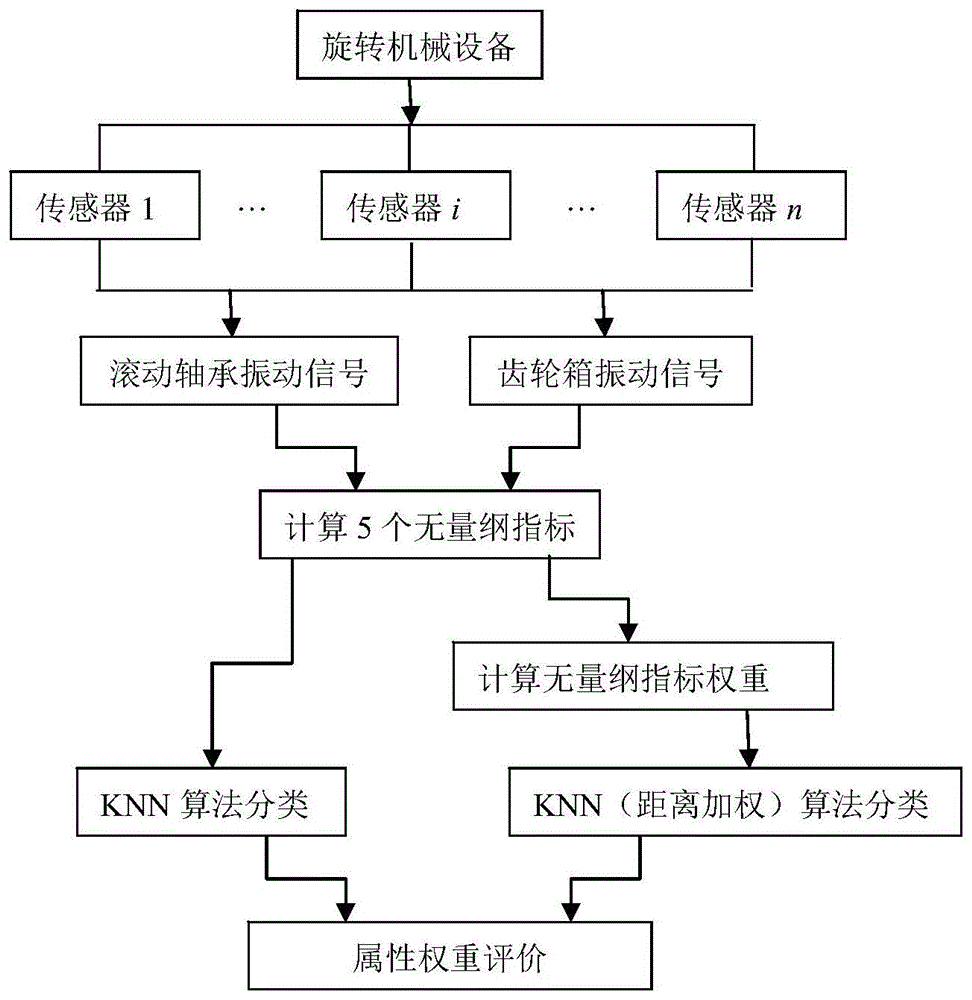
为解决上述技术问题,本发明提供一种旋转机械故障数据集属性权重的确定方法,其特征在于,包括如下步骤:
1)采集旋转机械滚动轴承和齿轮箱的振动信号;
2)计算5个无量纲指标;
3)按各无量纲指标取值,对故障数据集进行离散化处理;
4)计算各无量纲指标对所有多属性组合的边际重要度累积;
5)对边际重要度累积进行归一化处理,得到5个无量纲指标的属性权重。
进一步的,所述步骤1)具体步骤如下:利用数据采集器采集旋转机械滚动轴承和齿轮箱包含的故障振动信号。
进一步的,所述步骤2)具体步骤如下:
波形指标:
峰值指标:
脉冲指标:
裕度指标:
峭度指标:
式中,xrms为信号的均方根值,
进一步的,所述步骤3)具体步骤如下:利用k-means聚类算法对各无量纲指标取值进行聚类,将无量纲指标的数据变为字符型。
进一步的,所述步骤4)具体步骤如下:(1)按如下公式计算m个指标属性组合的边际重要度贡献;
式中,c表示条件属性集合,d表示决策属性,ci表示c中第i个条件属性,i和jl表示属性下表索引,1≤jl≤n,l=1,2,…,m-1,n表示条件属性集合c的元素个数,
(2)按如下公式计算边际重要度累积
进一步的,所述步骤5)具体步骤如下:按如下公式对边际重要度累积进行归一化处理,得到5个无量纲指标的属性权重,
一种旋转机械故障数据集属性权重的评价方法,其特征在于,利用knn算法对无量纲指标的属性权重进行评价,具体步骤如下:设x(x1,x2,x3,x4,x5)和y(y1,y2,y3,y4,y5)为旋转机械故障数据集的两个样本,knn算法采用的欧氏距离计算公式如下:
利用步骤5)得到的无量纲指标权重w(ci)对两个样本点的加权距离公式如下:
分别采用l2(x,y)和
本发明所达到的有益效果:
本发明提供的一种旋转机械故障数据集属性权重的确定和评价方法,改进了粗糙集属性重要度理论,提出了属性边际重要度,并基于边际属性重要度建立了无量纲指标的属性权重确定方法,基于边际重要度的权重确定方法综合考虑了所有多属性组合边际重要度对权重的影响,利用本发明方法得到的权重对knn学习算法进行加权实现,可以通过分类效果对属性权重进行评价。
附图说明
图1是本发明的流程示意图。
具体实施方式
下面结合附图对本发明作进一步描述。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。
参见图1和表1,本发明提供一种旋转机械故障数据集属性权重的确定及评价方法,包括以下步骤:
1)将不同的滚动轴承和齿轮箱故障件安装在此实验平台上,振动信号由安装在轴承座上的加速度传感器来提取,通过emt490数据采集器来采集故障振动信号。实验参数如下:转速为1000r/min,采样频率为1000hz,计算无量纲指标的采样点数为8192点;
2)将采集到的振动加速度故障数据导入到电脑上,并利用matlab软件对其进行读取。本实验的轴承故障主要包括三种:轴承内圈磨损,轴承外圈磨损和轴承却滚珠,齿轮箱故障包括三种:大齿轮缺齿,小齿轮缺齿,大小齿轮均缺齿,故障状态加上正常状态总共七种,对这七种状态下的振动信号分别进行采样,每种状态采样点数为819200个;
3)利用连续的8192个采样点计算出5个无量纲指标:波形指标,峰值指标,脉冲指标,裕度指标,峭度指标,并以实施方式步骤2)中旋转机械运转状态标记样本的决策属性取值;
波形指标:
峰值指标:
脉冲指标:
裕度指标:
峭度指标:
式中,xrms为信号的均方根值,
4)利用k-means聚类算法对各无量纲指标取值进行聚类,将无量纲指标的数据变为字符型。
5)按如下公式计算m个指标属性组合的边际重要度贡献;
式中,c表示条件属性集合,d表示决策属性,ci表示c中第i个条件属性,i和jl表示属性下表索引,1≤jl≤n,l=1,2,…,m-1,n表示条件属性集合c的元素个数,
按如下公式计算边际重要度累积
6)按如下公式对边际重要度累积进行归一化处理,得到5个无量纲指标的属性权重,
7)利用knn算法对无量纲指标的属性权重进行评价,具体步骤如下:设x(x1,x2,x3,x4,x5)和y(y1,y2,y3,y4,y5)为旋转机械故障数据集的两个样本,knn算法采用的欧氏距离计算公式如下:
利用步骤5)得到的无量纲指标权重w(ci)对两个样本点的加权距离公式如下:
分别采用l2(x,y)和
表1分类准确率对比
从表1可以看出,利用本发明方法确定的属性权重对knn算法欧氏距离进行加权改进明显改进了各状态样本的分类准确率。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!