一种基于大数据的房屋价格自动评估方法与流程
本发明涉及信息技术领域,尤其涉及一种基于大数据的房屋价格自动评估方法。
背景技术:
我国现阶段的房屋价格评估方法是利用市场比较法对单个房产项目进行人为的评估和定价。房屋价格的个案评估无法保证高效率、低成本的评估工作;同时,个案评估因评估师们对房地产价值的影响因素和修正幅度的判断不同,从而会造成评估结果不具有一致性和连贯性;此外,个案评估还容易引起违反职业道德的评估腐败等问题。
进入到二十一世纪后,我国的房地产行业的发展呈现出一派繁荣的景象,这也进一步推动了房地产估价行业的快速发展。而随着房产税各项安排的逐步落地,房产评估将得到更大范围以及更多领域的使用。在这样的背景下,传统的个案评估不再适合我国现阶段房地产市场发展的要求,高质量的、自动的批量评估方法与系统将成为我国房地产市场发展的重要保障。然而批量评估需要大量数据与科学的计算方法的保障,如果没有足够的数据量与数据质量作为支撑,会导致价格的测算在实际的实践中具有相当大的难度。
技术实现要素:
为了克服上述现有技术的不足,本发明提供一种基于大数据的房屋价格自动评估方法与系统,可有效解决上述问题。本发明具体采用的技术方案如下:
一种基于大数据的房屋价格自动评估方法包括以下步骤:
1)通过网页抓取和gis技术自动收集各小区的房屋交易信息及其房屋特征数据,所述房屋交易信息为房屋的价格信息,所述房屋特征数据包括建筑特征、小区特征和位置坐标;
2)将所有收集到的数据进行清洗分类,并对房屋特征数据进行量化后得到房屋的特征变量数据,建立房屋特征变量-价格信息数据库;
3)基于改进的knn近邻算法计算测试房屋对象的价格,具体计算过程包括:
3-1)循环计算测试房屋对象和数据库中每个样本房屋对象的特征变量相似度,所述相似度计算使用欧几里得距离d,计算公式如下:
其中n为房屋的特征变量数量,ai和bi分别表示测试房屋a和样本房屋b的第i个特征;
3-2)使用topk算法改进最近邻查找,首先随机建立一个大小为k的堆,堆中元素的值初始化为0;之后将数据库中所有样本房屋对象与测试房屋对象的d值逐个与堆中元素的值进行比较,若大于则将该d值放入堆中,若不大于则继续遍历,直到遍历结束得到测试房屋对象的k个最邻近样本房屋对象;
3-3)对上一步得到的k个最邻近样本房屋对象进行加权计算得到测试房屋对象的价格估值p,计算分两种情况:当d存在零值时,p取k个最邻近样本房屋对象的算术平均值;当d不存在零值时,p为最邻近样本房屋对象的价格乘权的总和与对应权值总和的比值,具体计算公式如下:
其中wm为第m个最邻近样本房屋对象的权值,其价格为pm,其相似度为dm;
4)输出房源价格评估结果。
作为优选,步骤1)中所述的价格信息包括挂牌价格、签约价格;所述的建筑特征包括建筑面积、房龄、当前层、总层数、性质;所述的小区特征包括外部资源即教育配套、医疗资源、菜场、公交、地铁、公园、湖泊、商业综合体和内部环境即绿化率、内部设施;所述的位置坐标为经纬度。
作为优选,步骤1)中所述的自动收集的数据来源包括中介网站、百度地图和自有渠道。所述的一种基于大数据的房屋价格自动评估方法,其特征在于所述的中介网站包括链家网、我爱我家、中原、华邦、中联、搜房、58同城和安居客。
作为优选,步骤2)所述的对房屋特征数据进行量化步骤如下:
2-1)小区性质分类:将小区性质分类分为住宅、商业及工业三大类和细分类别;
2-2)评分评价:对小区周边学区、医院和商业配套进行评分;
2-3)距离量化及标准化:对小区到周边环境的距离进行量化,并采取标准化手段进行统一,所述周边环境包括公园、河流、湖泊;
2-4)经纬度转化:将小区经纬度转化为区域划分的区域等级。
本发明考虑了在典型场景下考核影响房屋价格的多项特征变量,通过自动收集相关数据、数据清洗、分类、量化后建立了房屋特征变量-价格信息数据库;同时提出了一种基于改进的knn近邻算法的房屋价格估算模型,该模型通过循环比较测试房屋对象和数据库中样本房屋对象的相似度最终得到测试房屋对象的估算价格,方法为房屋价格的评估提供了科学的理论支撑。相比于传统的房屋价格评估方法,本发明具有如下收益:
上述技术方案具有如下有益效果:1、具有自动数据采集、数据准确与样本量大的优点;2、本发明使用近邻价格算法,避免了主观认知对价格的影响,符合客观情况;3、实时自动评估与输出房屋价格,避免信息滞后性,提高评估效率。
附图说明
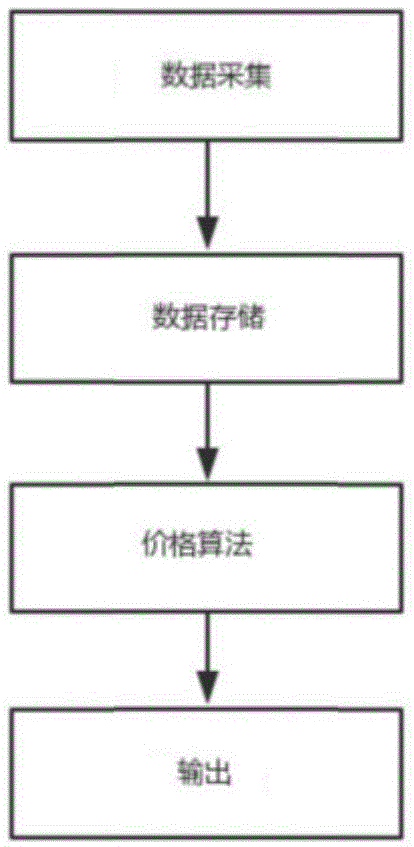
图1是本发明的整体流程示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
相反,本发明涵盖任何由权利要求定义的在本发明的精髓和范围上做的替代、修改、等效方法以及方案。进一步,为了使公众对本发明有更好的了解,在下文对本发明的细节描述中,详尽描述了一些特定的细节部分。对本领域技术人员来说没有这些细节部分的描述也可以完全理解本发明。
参考图1,一种基于大数据的房屋价格自动评估方法包括以下步骤:
1)数据采集:利用网页抓取程序和gis技术自动收集各小区的房屋交易信息及其房屋特征数据,所述房屋交易信息为房屋的价格信息,所述房屋特征数据包括建筑特征、小区特征和位置坐标。
该步骤中,所述的价格信息包括挂牌价格、签约价格;所述的建筑特征包括建筑面积、房龄、当前层、总层数、性质;所述的小区特征包括外部资源即教育配套、医疗资源、菜场、公交、地铁、公园、湖泊、商业综合体和内部环境即绿化率、内部设施;所述的位置坐标为经纬度。部分可直接从网页抓取的数据可以通过程序自动抓取,部分地理相关数据(如位置经纬度、距离等)可通过gis技术获取。
2)数据存储:将所有收集到的数据进行清洗分类,并对房屋特征数据进行量化后得到房屋的特征变量数据,建立房屋特征变量-价格信息数据库并存储。
在该数据库中每套房屋均对应有其具体的价格信息和特征变量数据。
该步骤中,自动收集的数据来源包括中介网站、百度地图和自有渠道。所述的中介网站包括链家网、我爱我家、中原、华邦、中联、搜房、58同城和安居客。
对房屋特征数据进行量化步骤如下:
2-1)小区性质分类:将小区性质分类分为住宅、商业及工业三大类和细分类别;
2-2)评分评价:对小区周边学区、医院和商业配套进行评分;
2-3)距离量化及标准化:对小区到周边环境的距离进行量化,并采取标准化手段进行统一,所述周边环境包括公园、河流、湖泊;
2-4)经纬度转化:将小区经纬度转化为区域划分的区域等级。
3)价格算法构建:基于改进的knn近邻算法计算测试房屋对象的价格,具体包括以下步骤:
3-1)循环计算测试房屋对象和数据库中每个样本房屋对象的特征变量相似度,所述相似度计算使用欧几里得距离d,计算公式如下:
其中n为房屋的特征变量数量,ai和bi分别表示测试房屋a和样本房屋b的第i个特征;
3-2)使用topk算法改进最近邻查找,首先随机建立一个大小为k的堆,堆中元素的值初始化为0;之后将数据库中所有样本房屋对象与测试房屋对象的d值逐个与堆中元素的值进行比较,若大于则将该d值放入堆中,若不大于则继续遍历,直到遍历结束得到测试房屋对象的k个最邻近样本房屋对象;
3-3)对上一步得到的k个最邻近样本房屋对象进行加权计算得到测试房屋对象的价格估值p,计算分两种情况:当d存在零值时,p取k个最邻近样本房屋对象的算术平均值;当d不存在零值时,p为最邻近样本房屋对象的价格乘权的总和与对应权值总和的比值,具体计算公式如下:
其中wm为第m个最邻近样本房屋对象的权值,pm为第m个最邻近样本房屋对象的价格,dm为第m个最邻近样本房屋对象的相似度,即欧几里得距离。
4)结果输出:根据实际需求的格式或者要求,输出房源价格评估结果。
下面将上述方法应用于具体实施例中,以便本领域技术人员能够更好地理解本发明的效果。
实施例
本实施例步骤与具体实施方式相同,在此不再进行赘述。下面就实施结果进行展示:
表1为通过步骤1)自动获取的各小区的房屋交易信息及其房屋特征数据,包括价格信息、建筑特征、小区特征和位置坐标。其中价格信息包括挂牌价格、签约价格;建筑特征包括房龄、建筑面积、所在层、总楼层、性质;小区特征包括公园距离、太湖距离、商业综合体距离、小区环境、生活配套、运动设施、教育配套、交通便利;所述位置坐标为经纬度。
表2为通过本发明方法估算后的部分房屋价格与实际成交价格的比较,从表中对比可以看出本发明的估算方法能够达到较高的准确度。
表1数据与评分量化表
表2样本特征与评估值
综上所述,结合本实施例的测试结果,本发明提出的一种基于大数据的房屋价格自动评估算法通过考虑在典型场景下考核影响房屋价格的多项特征变量,能够客观、准确、高效地实现房屋价格的自动估算,估算价格与实际成交价格十分接近能够为房屋价格的评估提供了科学的理论支撑。
以上所述的实施例只是本发明的一种较佳的方案,然其并非用以限制本发明。有关技术领域的普通技术人员,在不脱离本发明的精神和范围的情况下,还可以做出各种变化和变型。因此凡采取等同替换或等效变换的方式所获得的技术方案,均落在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!