一种基于深度神经网络的简历抽取方法与流程
本发明涉及文本处理技术领域,特别是涉及一种基于深度神经网络的简历抽取方法。
背景技术:
现代信息技术和存储技术的快速发展以及互联网的迅速蔓延,使得人们在日常生活会频繁接触到各种的文本信息,文本信息已经成为互联网传输数据最多的部分。在大数据时代,人们缺少的并不是信息,而是从海量纷繁复杂的信息中获取有用的、人们所关注的信息。对于简历的信息元的抽取系统,现有多为基于规则模板抽取的方式,其存在有缺陷:1、前期分词效果不佳,词表示的好坏将会直接影响最后信息元标注和识别的结果,目前在中文环境下,首先要对中文进行分词,前期分词效果的好坏将会直接的影响到后面的命名实体识别环节,但因为词与词之间没有明显的边界,前期分词在业界一直是个瓶颈问题;2、在中文组词中,词具有很强的灵活性,使得词汇数量巨大,同时词汇特征丰富而不易学习,而且将关键词看作是词汇组合使得词汇角色非常复杂,例如关键词的组成部分可能被切分到其他非关键词中,也就是说利用词切分后获得特征的方法,大大提高了机器学习的复杂性;3、传统的简历信息抽取主要基于规则模板,其定制的规则只能针对特定的某中特定格式的简历,在面对海量的纷繁复杂的简历文本就显得力不从心,不仅需要不断的添加修改和维护现有的规则,而且需要处理规则之间的冲突;4、目前传统的规则抽取首先要对关注的信息元进行识别和定位,然后根据语言学特征(比如词性特征或主谓宾的位置信息)和相关的格式信息(比如段落信息、标点符号信息)等定制相应的抽取规则,这样的抽取规则首先需要专业的领域知识,以及要对相应的语言学特征熟悉,并且字典库要不断更新维护,同时如果字典库中的信息元不存在就会被遗漏,因此泛用性差。现有技术中也有基于深度学习的简历解析方法,中国发明专利申请说明书cn106569998a公开一种基于bi-lstm、cnn和crf的文本命名实体识别方法,该方法包括如下步骤:利用卷积神经网络对文本单词字符层面的信息进行编码转换成字符向量;将字符向量与词向量进行组合并作为输入传到双向lstm神经网络来对每个单词的上下文信息进行建模;在lstm神经网络的输出端,利用连续的条件随机场来对整个句子进行标签解码,并标注句子中的实体;中国发明专利申请说明书cn108664474a一种基于深度学习的简历解析方法,其包括以下步骤:数据预处理:将简历统一转换为文本格式,确定简历的内容分段标签,并将简历文本按行进行数据标记;模型训练:利用神经网络将简历文本按行表达为一个固定长度的向量,在获得行向量后,根据所述行向量对简历进行内容分段;信息提取:在完成内容分段后,从指定的内容段中提取标签字段,获得相关信息;但是上述现有的技术均是将字符向量和词向量进行组合输入传到双向lstm神经网络中对每个单词的上下文信息进行建模,而对文本进行分词处理的好坏可以影响到判断上下文信息的准确性,同时也会影响到后面命名实体识别的结果。
技术实现要素:
为解决上述问题,本发明提供一种基于深度神经网络的简历抽取方法,其将字向量和字序列作为输入特征,减低分词的影响,且深度神经网络与基于规则的文本解析技术相结合,有效提高识别的准确率。
为解决上述目的,本发明采用的如下技术方案。
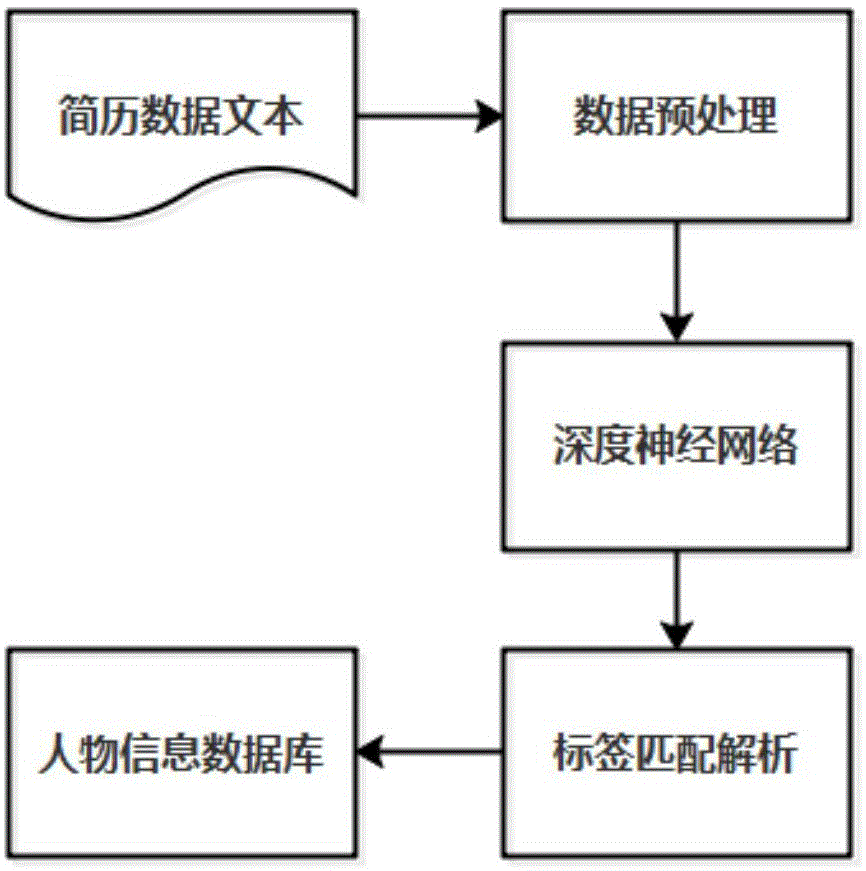
一种基于深度神经网络的简历抽取方法,其特征在于,包括如下步骤:数据预处理:获取简历数据文本,对获取简历数据文本进行分字,获取字向量特征和字序列特征,得到字向量数据集和字序列数据集;深度神经网络训练:训练得到深度神经网络训练模型,将字向量数据集和字序列数据集同时作为深度神经网络训练模型的特征输入,训练得到的语意特征作为输出特征,利用输出语意特征进行实体标注,得到简历数据文本的实体标签;标签匹配解析:根据预训练好的信息元抽取规则库中相应的抽取规则,匹配已标注的简历数据文本中的信息元词组,返回简历数据文本的信息元标签与信息元词组组对,并存入人物信息数据库。
进一步地,获取字向量特征及获得字向量数据集的步骤具体包括:将简历数据文本进行分割;利用分词模型对简历数据文本的词语、语句处理成多个单字;对得到的多个单字利用基于字的向量模型训练成字向量,得到字向量数据集。
进一步地,获取字序列特征及得到字序列数据集的步骤具体包括:将简历数据文本进行分割;利用分词模型对简历数据文本的词语、语句处理成多个单字;定义字序列,将多个单字根据字序列的定义组合成字序列,得到字序列数据集。
进一步地,字序列的定义为b={b_1,b_2,b_3……b_4|n>0},其中b_n为汉字或者符号串,字序列用于描述语言片段的上下文语境特征。
进一步地,在得到字向量数据集或字序列数据集之后的步骤还可包括:观察采用的模型输入的数据集数据的格式,把待输入的数据的格式处理成与即将采用模型的数据集格式。
进一步地,对数据预处理中得到的字向量数据集进行分割,得到字向量训练集、字向量测试集和字向量验证集;对数据预处理中得到的字序列数据集进行分割,得到字序列训练集、字序列测试集和字序列验证集;在训练得到深度神经网络训练模型步骤中具体包括:预训练字向量处理;把分割成的字向量训练集和字序列训练集同时当作长短期记忆网络lstm的输入特征,在长短期记忆网络lstm的输出端的线性层中根据每种特征所占的不同权重形成得到的语意特征作为输出特征;利用输出语意特征进行实体标注,得到训练集中简历数据文本的实体标签;再利用字向量验证集和字序列验证集,持续训练得到深度神经网络训练模型。
进一步地,所占的不同权重的获取过程具体为:权重在[0,1]区间内,先给定预设权重,利用深度神经网络训练模型测试训练数据集,记录系统性能结果;权重逐步从0增加到1,每次增加1/m,并得到多个系统性能结果;比较多个系统性能结果,选择获得系统性能结果最优的权重;系统性能结果可为预测标签的准确率。
进一步地,预训练好的信息元抽取规则库获得过程具体为:按照标点符号对获得的简历数据文本进行分割,输出多个文本段;判断每个文本段中所包含的信息元是否有简历信息中所要抽取的信息元,并把包含有的信息元的文本段提取出来形成文本段集;将文本段集与相应信息元标签数据对作为训练数据,训练出相应的信息元抽取规则,并存放信息;得到预训练好的信息元抽取规则库。
本发明的有益效果如下:
1.采用字向量和字序列作为特征输入,有效降低分词的影响,避免前期分词效果不好而直接影响后面命名实体识别准确率,且由于字切分后获得特征比词切分获得的特征少,能够大大降低机器学习的复杂性;
2.采用规则提取和深度神经网络相结合可以高速精确地识别简历数据文本中的信息元,同时经过标注后的简历数据文本结合规则抽取,相比利用传统的规则抽取,维护及抽取更为轻松。
3.在简历匹配解析中,将深度学习理论与基于规则的文本解析技术相结合,解析出的简历可用于构建人物信息数据库,利于后续的数据挖掘,对推荐系统等应用具有非常大的帮助。
附图说明
图1为本发明的一个实施例的简历抽取方法流程图;
图2为本发明的一个实施例的训练深度神经网络训练模型关键步骤的流程图;
图3为本发明的一个实施例的预训练字向量处理流程图;
图4为本发明的一个实施例的标签匹配解析关键步骤的流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处描述的具体实施例仅仅用以解释本发明,并不用于限定申请。可以理解,本发明所使用的术语“第一”、“第二”等可在本文中用于描述各种元件,但这些元件不受这些术语限制。这些术语仅用于将第一个元件与另一个元件区分。
图1示出,本实施例的一种基于深度神经网络的简历抽取方法,包括如下步骤:步骤s1,数据预处理:获取简历数据文本,对获取简历数据文本进行分字,获取字向量特征和字序列特征,得到字向量数据集和字序列数据集;步骤s2,深度神经网络训练:训练得到深度神经网络训练模型,将字向量数据集和字序列数据集同时作为深度神经网络训练模型的特征输入,训练得到的语意特征作为输出特征,利用输出语意特征进行实体标注,得到简历数据文本的实体标签;步骤s3,标签匹配解析:根据预训练好的信息元抽取规则库中相应的抽取规则,匹配已标注的简历数据文本中的信息元词组,返回简历数据文本的信息元标签与信息元词组组对,并可存入人物信息数据库;本发明采用字向量和字序列作为特征输入,有效降低分词的影响,避免前期分词效果不好而直接影响后面命名实体识别准确率,且由于字切分后获得特征比词切分获得的特征少,能够大大降低机器学习的复杂性;同时采用规则提取和深度神经网络相结合可以高速精确地识别简历数据文本中的信息元,同时经过标注后的简历数据文本结合规则抽取,相比利用传统的规则抽取,维护及抽取更为轻松;在简历匹配解析中,也将深度学习理论与基于规则的文本解析技术相结合,解析出的简历可用于构建人物信息数据库,利于后续的数据挖掘,对推荐系统等应用具有非常大的帮助。
本实施例的采用字向量和字序列同时作为深度神经网络训练模型的特征输入,本实施例在数据预处理步骤中,对于获取字向量特征及获得字向量数据集的步骤具体包括:步骤s101,将获取到的简历数据文本d={d_1…d_n}进行处理、分割,其中d_n表示第n个数据文本;步骤s102,利用分词模型对简历数据文本的词语、语句处理成多个单字,用训练好的分词模型把简历数据文本d={d_1…d_n}里面的词语、语句处理成为一个个的单字w={wd_1…wd_n},其中wd_n表示第n个字,如:“电光防爆科技股份有限公司|||林飞|||林飞先生,中国国籍,无永久境外居留权,1968年出生”,处理之后得到的结果为:电光防爆科技股份有限公司|||林飞|||林飞先生,中国国籍,无永久境外居留权,1968年出生”;步骤s103,对得到的多个单字利用基于字的向量模型训练成字向量,得到字向量数据集,对于在步骤步骤s102中得到的单字w={wd_1…wd_n},读取预先训练好的基于字的向量模型,采用google的word2vec中的步骤skip-gram模型和步骤stanford的glove模型进行向量表示形成维度d=100维的字向量v={v_1…v_n},得到字向量数据集。
本实施例在数据预处理步骤中,对于获取字序列特征及得到字序列数据集的步骤具体包括:步骤s110,将获取到的简历数据文本d={d_1…d_n}进行处理、分割,其中d_n表示第n个数据文本;步骤s111,利用分词模型对简历数据文本的词语、语句处理成多个单字,用预先训练好的分词模型把文本段里面的词语、语句处理成为一个个的单字w={wd_1…wd_n},其中wd_n表示第n个字;步骤s112,定义字序列,字序列的定义为b={b_1,b_2,b_3……b_4|n>0},其中b_n为汉字或者符号串,字序列用于描述语言片段的上下文语境特征,例如:“电光防爆科技股份有限公司”对应的字序列为{电,光,防,爆,科,技,股,份,有,限,公,司},字序列是最基本的观察序列,由于汉字的自身特点及其固定的排列,使得序列中的每个汉字都表现出一定的角色特征;步骤s113,将多个单字根据字序列的定义组合成字序列,获得字固定长度l=n的字序列数据集s={wd_1…wd_n}。
简历数据文本经过数据预处理后得到字向量数据集和字序列数据集,对数据预处理中得到的字向量数据集进行分割,得到字向量训练集、字向量测试集和字向量验证集;对数据预处理中得到的字序列数据集进行分割,得到字序列训练集、字序列测试集和字序列验证集;将字向量数据集和字序列数据集同时当做神经网络训练模型的输入特征,有效降低分词的影响,大大降低了机器学习的复杂性。
参照图2,本实施例中训练得到深度神经网络训练模型的步骤中具体包括:步骤s201,预训练字向量处理:图3示出的预训练字向量处理流程中,以中文wiki百科语料库以及步骤sogouca互联网新闻语料库或其他现有的语料库在word2vec模型以及glove模型上训练维度d=100维的字向量,其中d=100维是工程经验取的参数,用于初始化神经网络字向量表,然后在深度神经网络中进行微调;步骤s202,把分割成的字向量训练集和字序列训练集同时当作长短期记忆网络l步骤stm的输入特征,其中设置的dropout=n,n为工程经验参数,防止过拟合;步骤s203,在长短期记忆网络l步骤stm的输出端的线性层中根据每种特征所占的不同权重形成得到的语意特征作为输出特征;步骤s204,利用输出语意特征进行实体标注,得到训练集中简历数据文本的实体标签;步骤s205,再利用字向量验证集和字序列验证集,持续训练得到深度神经网络训练模型。在步骤204中的每种特征所占的不同权重的获取过程具体可为:权重在[0,1]区间内,先给定预设权重,利用深度神经网络训练模型测试训练数据集,记录系统性能结果;权重逐步从0增加到1,每次增加1/m,并得到多个系统性能结果;比较多个系统性能结果,选择获得系统性能结果最优的权重;系统性能结果可为预测标签的准确率。
本实施例在获取字向量数据集或字序列数据集之后还包括步骤:观察采用的模型输入的数据集数据的格式,把待输入的数据的格式处理成与即将采用模型的数据集格式。
本实施例中涉及的基于规则提取的方法是将文本与信息元抽取规则进行匹配识别出命名实体,例如:“林飞先生,中国国籍,无永久境外居留权,1968年出生”->中国国籍用国籍定位per步骤s.country,林飞先生定位先生为男性per步骤s.male,林飞定位为姓名per步骤s.name,1968年出生定位1968年为生日per步骤s.birth。在训练标签匹配解析过程中涉及的信息元抽取规则库之前,获取人工编写的信息元抽取规则,而在标签匹配解析过程中涉及的预训练好的信息元抽取规则库的获得过程具体为:步骤s301,按照标点符号对获得的简历数据文本进行分割,输出多个文本段p={p_1,p_2…p_n};步骤s302,判断每个文本段p={p_1,p_2…p_n}中所包含的信息元是否有简历信息中所要抽取的信息元,并把包含有的信息元的文本段提取出来形成文本段集p2={pr_1,pr_2…pr_n};步骤s303,判断在包含所需要抽取的信息元之后,将文本段集p2={pr_1,pr_2…pr_n}与相应信息元标签数据对作为训练数据,训练出相应的信息元抽取规则,并存放信息;得到预训练好的信息元抽取规则库;涉及的信息元标签数据为预先人工编好的。
图4示出,本实施例中标签匹配解析处理步骤包括:根据预训练好的信息元抽取规则库中相应的抽取规则,匹配已标注的简历数据文本中的信息元词组,返回简历数据文本的信息元标签与信息元词组组对;完成匹配解析后,可存入人物信息数据库,而在规则提取过程中,需要加入部分专家干预与校验,确保规则的准确性。通过结合深度学习理论与基于规则的文本解析技术,解析出的简历可用于构建人物信息数据库,利于后续的数据挖掘,对推荐系统等应用具有非常大的帮助。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!