结合多源特征学习和组稀疏约束的无监督物体识别方法与流程
本发明属于机器学习技术领域,特别涉及一种结合多源特征学习和组稀疏约束的无监督物体识别方法。
背景技术:
聚类技术旨在将待处理对象划分为多个相似的簇,进而提取数据的抽象语义,是应用非常广泛的一项技术,在图像物体识别领域中获得了巨大的成功。然而,传统图像物体识别领域中的聚类方法还存在以下缺陷:首先,图像数据一般由高维特征组成,这些高维图像数据中往往包含噪声特征,直接对其操作将严重影响聚类效果;其次,这些高维图像数据一般存在大量冗余特征,处理这类数据需要消耗昂贵的计算资源。在多媒体技术高速发展的今天,高维图像数据呈现爆发式增长,给传统聚类方法带来了巨大挑战。最新研究表明,若能有效选择数据最优特征子集,将能有效提高图像识别的准确率。
互联网技术的快速增长,扩大了数据收集来源的多样性,也使得数据特征呈现多源化。不同类型数据特征拥有不同的性质,其在图像识别应用中也发挥着不同的作用。为有效处理这些多源高维数据,现有的方法一般借助子空间学习和多视图学习,以获得高维数据在不同视图上的最优特征子空间。然而,这些方法需要借助降维方法定位特征子空间,其所获取的子空间与原始空间存在较大差异,很难满足实际应用中对数据语义理解的需求。另外,为处理多视图数据,这类方法需要单独确定每个视图的最优子空间,当视图数量增加时,其子空间搜索的复杂度将会陡然上升。
技术实现要素:
本发明的目的,在于提供一种结合多源特征学习和组稀疏约束的无监督物体识别方法,使得聚类方法能够高效利用多源数据特征间的相互关系和共享特征子空间,以提高聚类方法的准确度;利用组稀疏技术约束多源数据的联合特征选择矩阵,对联合特征进行综合排序,进而可快速定位最优特征子集;其还可有效抑制数据集中的噪声干扰,最终为机器学习、计算机视觉相关应用提供有效支持。
为了达成上述目的,本发明的解决方案是:
一种结合多源特征学习和组稀疏约束的无监督物体识别方法,包括如下步骤:
步骤1,从包含c个类别的待处理图像集中获取v种视图,并将其组成数据集x=[x1,x2,…,xn]∈rd×n,其中d代表数据的特征维度,n代表数据集的样本数;
步骤2,提取数据集x的总散度矩阵st;
步骤3,在步骤2的基础上构建基于线性判别分析的km聚类模型;
步骤4,在步骤3的基础上构建基于组稀疏约束和特征选择的多源数据联合聚类模型;
步骤5,求解步骤4得到的多源数据联合聚类模型的目标函数,并进行优化。
上述步骤2中,提取数据集的总散度矩阵st的公式是:
其中,
上述步骤3中,km聚类模型的目标函数如下:
其中,w=[w1,…,wd]t∈rd×m为特征选择矩阵,m为降维后的特征维度,i为单位矩阵,f=[f1,f2,…,fn]t∈rn×c为预测标签矩阵,g=[g1,g2,…,gc]∈rm×c为聚类中心矩阵,||·||2,1代表其l2,1范数且对于任意矩阵m∈rr×p,
上述步骤4中,多源数据联合聚类模型的目标函数如下:
其中,w=[w1,…,wd]t∈rd×m为特征选择矩阵,m为降维后的特征维度,i为单位矩阵,f=[f1,2,…,fn]t∈rn×c为预测标签矩阵,g=[g1,g2,…,gc]∈rm×c为聚类中心矩阵,||·||2,1代表其l2,1范数且对于任意矩阵m∈rr×p,
上述步骤5中,求解多源数据联合聚类模型的目标函数的过程是:
步骤a1,将目标函数转换为如下形式:
其中,e=[e1,e2,…,en]=xtw-fgt,且d,de和
步骤a2,设w,de,d,
其中,fi表示预测标签矩阵f的第i个列向量;
则f通过下式获得,即:
其中,gk表示聚类中心矩阵g的第k个列向量,k=1,…,c;fij表示f中的第i行第j列元素;
步骤a3,设f,de,d,
g=wtxdef(ftdef)-1
将所求得的g代入目标函数,目标函数转化为:
其中,sw=xdext-xdef(ftdef)-1ftdext;
定义λ为拉格朗日乘子,继而得拉格朗日函数:
将以上拉格朗日函数对w求导,得:
则最优解w*通过求解以下矩阵的m个最小特征值获得:
上述步骤5中,进行优化的具体过程是:
令t代表迭代次数
步骤b1,随机初始化特征选择矩阵w,类别中心矩阵g,初始化de,d,
步骤b2,在低维嵌入数据wtx上应用传统km方法求解f;
步骤b3,更新w为由
步骤b4,更新g=wtxdef(ftdef)-1;
步骤b5,更新de,d和
步骤b6,重复执行步骤b2-步骤b5,直到收敛,输出类别标签矩阵f和特征选择矩阵w,其中第i个特征的权重由||w1||2确定,而第v个视图的权重由
采用上述方案后,本发明的有益效果是:本发明可有效利用数据可区分信息和多源数据特征信息,且无需单独求解每一视图最优特征子空间,避免由于视图数量增加而造成的子空间搜索代价,从而能有效节约计算机资源。在模型学习过程中,利用l2,1范数损失函数评价模型与数据的拟合度,从而对数据集中噪声具有良好抗干扰性。最后,本发明还能有效提取多个视图数据之间共享信息,并以此约束模型,从而提高特征选择准度性和扩展性。
附图说明
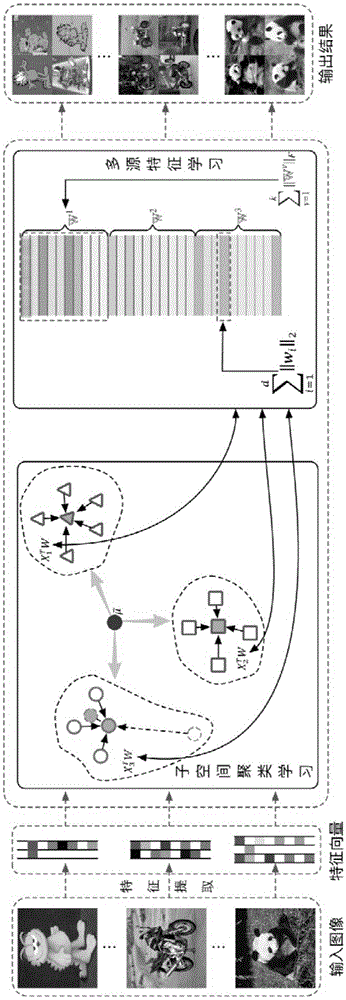
图1是本发明的示意图;
图2是本发明的流程图。
具体实施方式
以下将结合附图,对本发明的技术方案及有益效果进行详细说明。
如图1和图2所示,本发明提供一种结合多源特征学习和组稀疏约束的无监督物体识别方法,包括如下步骤:
(1)从包含c个类别的待处理图像集中获取v种类型特征(视图),并将这些特征组成数据集x=[x1,x2,…,xn]∈rd×n,其中d代表数据的特征维度,n代表数据集的样本数。
(2)提取数据集的总散度矩阵st:
其中,
(3)在步骤(2)的基础上构建基于线性判别分析的km聚类模型,目标函数如下:
其中,w=[w1,…,wd]t∈rd×m为特征选择矩阵,m为降维后的特征维度,i为单位矩阵,f=[f1,f2,…,fn]t∈rn×c为预测标签矩阵,g=[g1,g2,…,gc]∈rm×c为聚类中心矩阵,||·||2,1代表其l2,1范数且对于任意矩阵m∈rr×p,
(4)在步骤(3)的基础上构建基于组稀疏约束和特征选择的多源数据联合聚类模型,目标函数如下:
其中,
可以看出,以上目标函数具备以下几个特点:1)该模型中的g2,1范数对不同视图的特征选择矩阵进行稀疏约束,进而能够有效评估不同视图的重要性,即通过该约束将为相关性较高的视图数据特征分配较大的权重,反之则分配小的权重;2)该模型通过采用基于l2,1范数的损失函数扩展km聚类模型,能够有效减少噪声数据(即离群点)的干扰;3)模型采用基于l2,1范数的稀疏约束,可有效判定相同视图中不同数据特征重要性。
(5)求解目标函数
由于所述目标函数涉及组稀疏的l2,1和
1)将目标函数转换为如下形式:
其中,e=[e1,e2,…,en]=xtw-fgt,且d,de和
2)设w,de,d,
其中,fi表示预测标签矩阵f的第i个列向量;
则f可通过将传统km方法应用于低维嵌入数据wtx获得,即:
其中,gk表示聚类中心矩阵g的第k个列向量,k=1,…,c;fij表示f中的第i行第j列元素;
3)设f,de,d,
g=wtxdef(ftdef)-1
将所求得的g代入目标函数,目标函数可转化为:
其中,sw=xdext-xdef(ftdef)-1ftdext。
定义λ为拉格朗日乘子,继而可得拉格朗日函数:
将以上拉格朗日函数对w求导,可得
则最优解w*可通过求解以下矩阵的m个最小特征值获得:
4)模型迭代优化方法
基于以上求解过程,采用以下步骤对模型进行迭代优化:
令t代表迭代次数
步骤1:随机初始化特征选择矩阵w,类别中心矩阵g,初始化de,d,
步骤2:在低维嵌入数据wtx上应用传统km方法求解f;
步骤3:更新w为由
步骤4:更新g=wtxdef(ftdef)-1;
步骤5:更新de,d和
步骤6:重复执行步骤2-步骤5,直到算法收敛,输出类别标签矩阵f和特征选择矩阵w,其中第i个特征的权重由||w1||2确定,而第v个视图的权重由
为了验证本发明实施例所提供的结合多源特征学习和组稀疏约束的无监督物体识别方法,针对开源数据库caltech101进行验证分析。该数据库包含了9145张图片,共101个物体类别。本实施例中,筛选了caltech101中7个最常用的类别,进而生成了包含1474张图片的子集,该子集的物体类别有脸(face)、摩托车(motorbikes)、美元钞票(dollabill)、加菲猫(garfield)、史努比(snoopy)、停车标(stop-sign)、温莎椅(windsor-chair)等。对每个图像样本提取三种不同类型的特征,分别为:48维度的gabor特征、40维度的小波矩(waveletmoments,wm)、254维度的centrist特征。本实施例中,将这些特征划分为3个独立的视图,并和3个主流的方法进行效果的比较,分别是一个单视图方法:traceratioformulationandk-meansclustering(track)和二个多视图方法robustmulti-viewk-meansclustering(rmkmc)、discriminativeembeddingk-meansclustering(dekm),并采用两种评价指标衡量方法的有效性,分别是归一化互信息(normalizedmutualinformation,nmi)和纯度(purity)。下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清晰地描述:
表1多种算法在caltech101数据集上性能比较(±标准方差)
表1为多种算法在caltech101数据集上的性能比较结果,从表格的结果可以看出本发明提供的方法有着明显的优点:1)与单视图方法track相比,在nmi方面,本发明方法结果比其最好的结果(在wm特征上)还要高8%;2)与多视图方法dekm和rmkmc相比,本发明方法也获得了最好的效果。以上结果充分证明了本发明所提供方法的有效性。
综合上述,本发明一种结合多源特征学习和组稀疏约束的无监督物体识别方法,该方法包括以下内容:(1)将基于l2,1损失函数的鲁棒k均值聚类方法和线性判别分析方法相结合,可有效提取数据间的可区分信息和类别信息;(2)将特征选择融入聚类模型,并利用l2,1范数正则化技术约束特征选择矩阵,计算数据属性的贡献度,借此筛选最具代表性特征;(3)根据多源数据特征的多样性分组特征选择矩阵,并通过组稀疏技术约束和优化各分组,计算不同类型特征的贡献度,进而计算出最优特征选择矩阵;最后利用迭代优化方法对模型进行求解。本方法将特征选择和组稀疏约束技术融入到聚类方法中,能够充分考虑相同数据源特征间及不同数据源类型间的相关性,进而过滤冗余特征和噪声特征,从而解决了高维多源数据的负面影响。同时,该方法便于操作人员搜索多源数据的联合最优特征子空间,其聚类效果也优于传统聚类方法及其扩展方法。
以上实施例仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!