支持用户策略配置的基于Web网络的非结构化文本获取方法与流程
本申请涉及一种信息采集与获取方法,具体的,涉及一种支持用户实时/准实时地进行策略配置的基于web网络的非结构化文本获取方法。该方法可以用于电力行业非结构化文本数据的获取与汇聚,为非结构化文本数据的统一管理奠定基础,应用于组织内部的信息资源统一管理与知识管理等场景。
背景技术:
非结构化文本数据是一个组织内部极为重要的信息资源,有效管理信息资源,实现信息资源的快速检索、分析挖掘,可以为日常的办公、管理、协调、监督、决策等活动提供数据和信息支撑,降低日常运营成本,积累形成组织内部包括显式知识与隐式知识的知识库,深化组织的信息储备,为组织的成长、发展构建知识基础。
非结构化文本的采集、处理、分析、存储、管理、查询、表达、应用与结构化数据有着相当差异。结构化数据由于类型明确、长度固定,同时表达与处理的理论与方法较为成熟,通常采用关系模型进行表达和存储,因此相对而言技术方案较为统一。结构化数据的采集与获取通常使用etl工具进行数据的转换与处理以达成。非结构化文本数据的采集与获取相对而言更为复杂。首先在于文本数据的通常形式为非数字形式,即以印刷品、出版物与打印件的形式存在,通常需要人工输入或ocr等技术将上述内容转化为数字形式,这些技术都需要耗费大量的人力成本。即使文本数据以数字化的文件格式存在,将散布在一个组织内部多台工作终端与计算设备内的文本相关格式的文件进行采集汇总也是较为繁重、复杂的工作。总体而方,非数字化的文本与文件格式保存的文本数据采集与获取的成本较为高昂。
自web网络成为信息发布与信息获取的主要渠道以来,web应用逐渐取代单机模式或客户机/服务器模式的应用软件成为一个组织内部开展日常工作的应用软件的主要形式,同时文本数据也大多以网页文本的形式呈现。利用web网络进行文本数据的采集具有灵活方便、成本较低、采集速度快等特点,因而该方法成为文本数据采集的重要技术之一。
基于web网络的文本数据采集通常以网络爬虫作为技术手段实现自动化信息采集,网络爬虫程序的实现包括数据提取规则的制定、无效链接的识别、重复链接的删除以及爬虫的增量采集等。网络爬虫程序按照某一特定的算法主动采集网页内容的脚本或程序,它可以自动并且快速地采集所有能够访问到的网页,以便获得这些网站的数据资源,并配合下载器的使用,将数据资源保存到指定的存储系统中。网络爬虫根据功能用途和实现技术一般分为两种:通用爬虫和主题爬虫。通用爬虫的采集策略是尽可能多的采集网页,对网页内容并没有过多的限制,因此通用网络爬虫所捕获的目标网页是巨大的,采集范围是非常广泛的,对硬件和软件的性能要求相对较高,它被广泛应用于通用搜索引擎中。主题爬虫的采集策略是丢弃与采集目标无关的网页,尽可能抓取与收集目标相关的网页,它的优势是:爬虫执行效率较高、使用较少的内存空间以及拥有较高的搜索准确率,它被广泛应用于垂直搜索引擎中。
web网络爬虫存在策略配置不够灵活,且策略配置无法根据已收集的数据的特性进行灵活调整的缺陷。无论是通用爬虫还是主题爬虫,其初始采集策略一旦配置完成,爬虫在整个采集过程中即根据此策略进行数据采集,然而实际的数据采集过程中往往需要根据用户的需求以及已采集数据的特性来调整爬虫的采集策略,即将整个web网络的访问过程作为一个带有用户评估已爬取的数据特性同时进行策略调整的具有反馈机制的闭环。
如何对诸如网络爬虫的web网络文本采集系统的策略进行动态的调整,,实现在一个特定的组织内更好与更高效的文本数据采集与高质量的文本数据资源池的构建,成为现有技术亟需解决的技术问题。
技术实现要素:
本发明的目的在于提出支持用户实时/准实时的策略配置的基于web网络的非结构化文本采集与获取方法,能够应用于电力专业领域和行业内文本数据的在线采集获取,实现在很短的时期内即可将具有丰富特征的文本数据建立起信息资源池,提高爬虫效率,节省信息采集的周期。
为达此目的,本发明采用以下技术方案:
一种支持用户策略配置的基于web网络的非结构化文本获取方法,包括如下步骤:
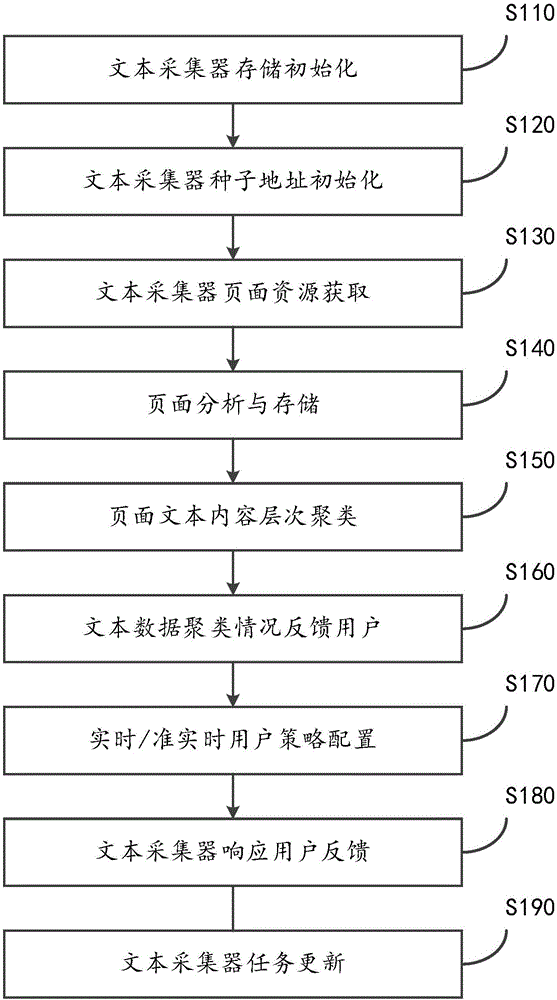
文本采集器存储初始化步骤s110:将文本数据采集器的存储空间进行初始化,同时设立层次聚类算法,设置层次聚类算法的触发条件为每当存储空间中新增的页面数量超过阈值数量n即启动进行层次聚类;
文本采集器种子地址初始化步骤s120:将种子地址集,输入文本数据采集器,作为前沿边界页面库(frontierurlqueue)的初始值;
文本采集器页面资源获取s130:根据预先设置的多线程并行处理参数p,同时进行多个页面的获取,页面地址采用最大优先队列法取出前沿边界库中的页面地址,按照最大权值最先出队的原则,取出页面地址然后取得页面资源,每个页面地址的权重值计算遵循以下原则:
(1)若当前页面未被聚类过程归为某一类别,则将其权重值设置为
(2)若当前页面已被聚类过程归为某一类别,则将该页面在层次聚类中的类别深度d与类别规模s来确定,即权重值为
页面分析与存储步骤s140:将取来的页面进行内容分析,提取出的文本内容写入s110步骤中初始化过的文本数据采集器的存储空间,提取出的页面链接url经过重复性检测后放入前沿边界库;
页面文本内容层次聚类步骤s150:若文本数据存储系统中新增的页面数量触发了增量聚类过程,则对未聚类的页面文本进行聚类,以用于将其页面内所包含的url的权重值根据新形成的聚类进行更新;
文本数据聚类情况反馈步骤s160:每次文本数据经过增量聚类之后,将层次化聚类结果,即层次聚类权重值及其相互关系,以图形化的方式传送给启动文本采集任务的用户;
实时/准实时用户策略配置步骤s170:用户收到聚类结果之后,调整各聚类的优先级别,即进行权重值修正,为前沿边界库中页面权重值做出调整;
文本采集器响应用户反馈步骤s180:文本数据采集器在文本采集的过程中使用用户调整加权之后的前沿边界库进行页面权重的计算与页面地址的赋权。
可选的,还具有:文本采集器任务更新步骤s190:根据页面采集器的页面重访策略配置,进行页面重访,以获取页面更新之后的内容,根据重访的页面结果按规则触发层次聚类,并将层次聚类结果进行持久化保存。
可选的,在所述文本采集器存储初始化步骤s110,所述阈值数量n为2000。
可选的,所述前沿边界页面库为queuelib结构
可选的,在文本采集器页面资源获取s130中,参数p的取值范围为[32,1024]。
可选的,在文本数据聚类情况反馈步骤s160中,层次化聚类结果的信息通过邮件、短信、即时消息等形式进行传送。
本发明还公开了一种存储介质,用于存储计算机可执行指令,其特征在于:所述计算机可执行指令在被处理器执行时执行上述的支持用户策略配置的基于web网络的非结构化文本获取方法。
因此,本发明能够对已爬取的资源的评估来动态地调整web网络文本采集系统即网络爬虫的选择策略,实现在一个特定的组织内更好与更高效的文本数据采集与高质量的文本数据资源池的构建,实现在很短的时期内即可将具有丰富特征的文本数据建立起信息资源池,提高爬虫效率,节省信息采集的周期。
附图说明
图1是根据本发明具体实施例的支持用户策略配置的基于web网络的非结构化文本获取方法的流程图;
图2是根据本发明具体实施例的以可视化的方式将文本数据聚类反馈给用户,并进行相对权值调整的示意图。
具体实施方式
下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部结构。
本发明主要基于层次聚类算法,对已经收集的页面进行聚类分析,对门户站点地址根据是否聚类设定不同的权重,并动态的调整前沿边界库中页面权重值,从而定期的进行页面重访,以获取页面更新之后的内容。根据该方法,能够对已爬取的资源的评估来动态地调整web网络文本采集系统即网络爬虫的选择策略,实现在一个特定的组织内更好与更高效的文本数据采集与高质量的文本数据资源池的构建,实现在很短的时期内即可将具有丰富特征的文本数据建立起信息资源池,提高爬虫效率,节省信息采集的周期。
参见图1,示出了支持用户策略配置的基于web网络的非结构化文本获取方法的流程图,该方法包括如下步骤:
文本采集器存储初始化步骤s110:将文本数据采集器的存储空间进行初始化,同时设立层次聚类算法,设置层次聚类算法的触发条件为每当存储空间中新增的页面数量超过阈值数量n即启动进行层次聚类。
在一个可选的实施例中,所述阈值数量n为2000。
文本采集器种子地址初始化步骤s120:将种子地址集,通常为一个门户站点地址的集合,输入文本数据采集器,作为前沿边界页面库(frontierurlqueue)的初始值。
在一个可选的实施例中,前沿边界页面库可以为queuelib结构。
文本采集器页面资源获取s130:根据预先设置的多线程并行处理参数p,示例性的参数p的取值范围为[32,1024],同时进行多个页面的获取,页面地址采用最大优先队列法取出前沿边界库中的页面地址,按照最大权值最先出队的原则,取出页面地址然后取得页面资源,每个页面地址的权重值计算遵循以下原则:
(1)若当前页面未被聚类过程归为某一类别,则将其权重值设置为
(2)若当前页面已被聚类过程归为某一类别,则将该页面在层次聚类中的类别深度d与类别规模s来确定,即权重值为
页面分析与存储步骤s140:将取来的页面进行内容分析,提取出的文本内容写入s110步骤中初始化过的文本数据采集器的存储空间,提取出的页面链接url经过重复性检测后放入前沿边界库。
页面文本内容层次聚类步骤s150:若文本数据存储系统中新增的页面数量触发了增量聚类过程,则对未聚类的页面文本进行聚类,以用于将其页面内所包含的url的权重值根据新形成的聚类进行更新;
文本数据聚类情况反馈步骤s160:每次文本数据经过增量聚类之后,将层次化聚类结果,即层次聚类权重值及其相互关系,以图形化的方式传送给启动文本采集任务的用户。
在一个可选的实施例中,层次化聚类结果的信息可以通过邮件、短信、即时消息等形式进行传送。
实时/准实时用户策略配置步骤s170:用户收到聚类结果之后,通过诸如在线程序以图形化操作的方式调整各聚类的优先级别,即进行权重值修正,为前沿边界库中页面权重值做出调整。
文本采集器响应用户反馈步骤s180:文本数据采集器在文本采集的过程中使用用户调整加权之后的前沿边界库进行页面权重的计算与页面地址的赋权。
因此,利用上述的步骤,本发明实现了利用已经采集的信息通过层次化聚类后对前沿边界库进行页面权重的计算与页面地址的赋权,即实现了web网络文本采集系统即网络爬虫的选择策略的动态调整。
进一步的,本发明还定期的利用调整后的前沿边界库进行页面重访,以获取页面更新之后的内容,具体为:
文本采集器任务更新步骤s190:根据页面采集器的页面重访策略配置,进行页面重访,以获取页面更新之后的内容,根据重访的页面结果按规则触发层次聚类,并将层次聚类结果进行持久化保存。
实施例1:
1、文本采集器存储初始化
建立一个redis存储服务器并初始化完成,设立层次聚类算法,设置每当新增未分类的页面达到1000时,启动层次聚类算法对所有未分类页面进行分类并纳入到已有的聚类类别中。
2、起始页面设置
建立一个queuelib结构作为前沿边界页面库(frontierurlqueue),将初始url地址,如www.yn.csg.cn、www.csg.cn、www.sgcc.com.cn等,输入前沿边界页面库。上述三个地址所获取的页面均未进行聚类,因此其权重值分别设置为
3、文本采集器页面资源获取
在前沿边界页面库中按照最大权值最先出队的原则,取出页面地址然后取得页面资源,提取出页面内的url地址,将其放入前沿边界页面库,权值计算遵循以下原则:
(1)若当前页面未被聚类过程归为某一类别,则将其权重值设置为
(2)若当前页面已被聚类过程归为某一类别,则将该页面在层次聚类中的类别深度d与类别规模s来确定,即权重值为
4、页面分析与存储步骤
将取来的页面进行内容分析,提取出的文本内容写入redis存储服务系统。页面中提取出的链接url经过重复性检测后再放入前沿边界库。
5、页面文本内容层次聚类
若redis存储系统中新增的页面数量触发了增量聚类过程,即对未聚类的页面文本进行层次聚类,并将其页面内所包含的url的权重值根据新形成的聚类进行更新,即调整其在前沿边界页面库的权重值;
6、文本数据聚类情况反馈用户
每次文本数据经过增量聚类之后,将层次化聚类结果,即层次聚类权重值及其相互关系,以图形化的方式传送给启动文本采集任务的用户,信息的传送方式可以通过邮件、短信、即时消息、web应用链接等形式。
7、实时/准实时用户策略配置
用户收到聚类结果之后,可以通过在线程序以图形化操作的方式调整各聚类的优先级别,即进行权重值修正,为前沿边界库中页面权重值做出调整,例如用户将图2中的聚类b的权值调整为原值的110%,则处于b聚类中的页面上的链接将具有相对其他链接10%的优势,将能够有更多机会被访问到;
8、响应用户反馈及页面内容更新
文本数据采集器在文本采集的过程中使用用户调整加权之后的前沿边界库进行页面权重的计算与页面地址的赋权。基本的页面资源获取完成之后,为获取各个网站中的更新内容,会设置重访时间进行页面重访。根据重访的页面结果按规则触发层次聚类,并将层次聚类结果进行持久化保存。
进一步的,本发明还公开了一种存储介质,用于存储计算机可执行指令,其特征在于:所述计算机可执行指令在被处理器执行时执行上述的支持用户策略配置的基于web网络的非结构化文本获取方法。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施方式仅限于此,对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单的推演或替换,都应当视为属于本发明由所提交的权利要求书确定保护范围。
- 还没有人留言评论。精彩留言会获得点赞!