一种基于排序卷积神经网络的人脸表情分析方法及系统与流程
本发明属于图像处理和模式识别技术领域,具体涉及一种基于排序卷积神经网络的人脸表情分析方法及系统。
背景技术:
人脸表情分析是一个涉及模式识别、图像处理、人工智能等多学科的综合性课题。所谓人脸表情分析,是指让计算机对给定的表情图像进行特征提取,并结合人类已有的先验知识,展开学习、推理、判断,进而理解人类情绪的过程。人脸表情分析广泛应用于情感计算、人机交互、情感机器人、医疗保健等领域,是当前的研究热点。
人脸表情分析主要由表情识别和表情强度估计两个部分组成。表情识别的工作主要是分类六类基本表情,包括:生气、厌恶、恐惧、高兴、悲伤、惊讶;而表情强度估计则主要判断情绪的表达强弱程度。心理学研究指出,仅仅分类基本表情并不能完全理解人的情绪。为了全面的理解人的情绪,有必要同时估计表情的类别和强度。
表情强度估计面临的主要困难在于无法获得足够的有强度标记的表情样本,无法通过有监督的方法来估计表情的强度。为了解决这一问题,可以将表情强度估计问题转化为排序问题,利用表情序列的顺序信息作为约束条件来训练排序模型,从而估计序列中任意两张表情的强弱关系。目前在该领域已开展了诸多研究,但依旧存在表情强度估计精度低,易受噪声干扰等问题。
技术实现要素:
针对现有技术存在的问题和改进需求,本发明提供了一种人脸表情分析方法及系统,利用排序卷积神经网络对表情的类别和强度进行估计,能有效抑制个体差异、光照条件等干扰,提高准确率。
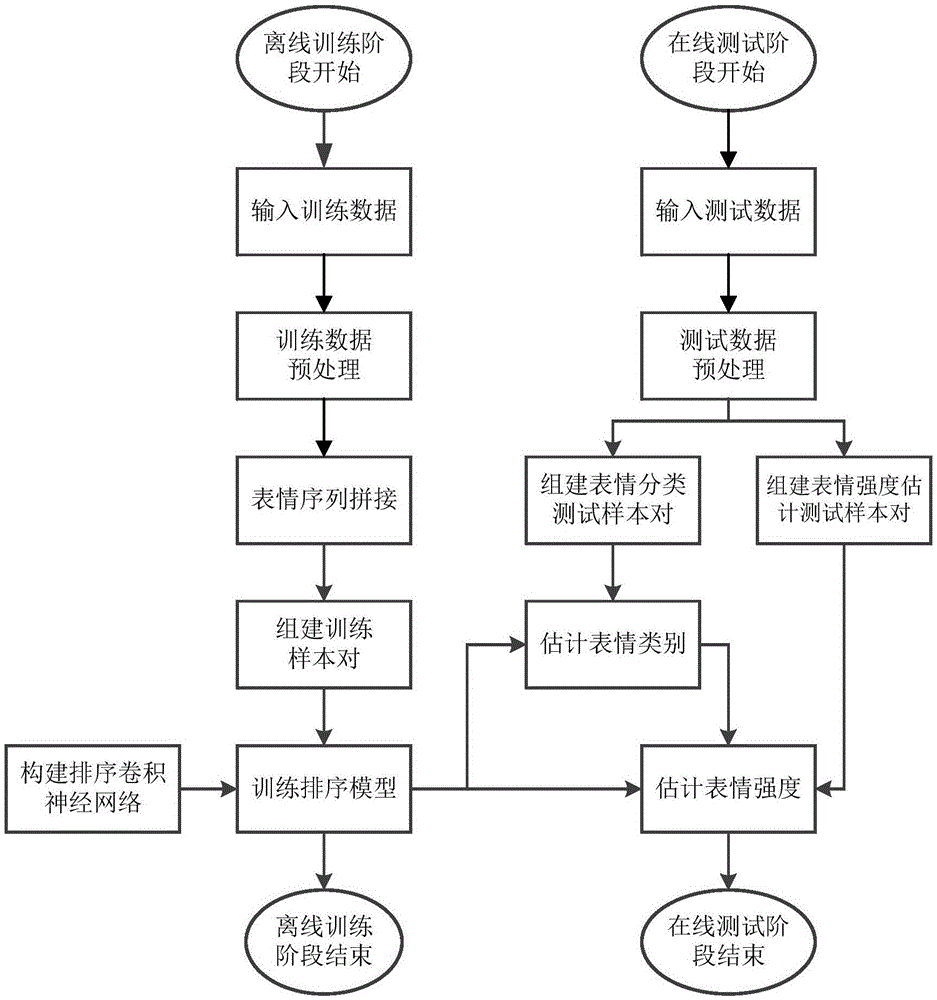
一种基于排序卷积神经网络的人脸表情分析方法,包括离线训练部分和在线分析部分;
所述述离线训练部分包括以下步骤:
(s1)提取n个人的训练人脸图像序列,记录每张训练图像的表情类型;
(s2)以第j种表情类型作为感兴趣表情,对第i个人的训练人脸图像序列进行抽取拼接,由此建立第j种表情类型与训练人脸图像子序列的映射关系,i=1,…,n,j=1,…,m,m为表情类型数量;
所述抽取拼接是指从第i个人的训练人脸图像序列中分别抽取第z种和第j种表情图像序列,并将抽取的两种表情图像序列拼接,z∈{1,…,m},z≠j,其中,第z种表情图像序列按照表情强度值由峰值逐渐减小到中性值的顺序排列,第j种表情图像序列按照表情强度值由中性值逐渐增大到峰值的顺序排列;
(s3)在第j种表情的n*m个训练人脸子图像子序列中,两两不同帧组合为训练样本对;
(s4)将组合得到的多个训练样本对作为排序卷积神经网络的输入,训练得到第j种表情的强度排序模型;
所述在线分析部分包括以下步骤:
(t1)采集待测人员的测试人脸图像序列;
(t2)从测试人脸图像序列中提取任意一帧与参考中性表情图像组成表情测试样本对;
(t3)将表情测试样本对送入第j种表情的强度排序模型,j=1,…,m,强度排序模型的输出值中最大者对应的表情类型即为待测人员的表情类型;
(t4)在测试人脸图像序列中,两两不同帧图像组合为表情强度测试样本对;
(t5)将表情强度测试样本对送入待测人员表情类型的强度排序模型,获得表情强度变化状态。
一种基于排序卷积神经网络的人脸表情分析系统,包括离线训练部分和在线分析部分;
所述述离线训练部分包括以下模块:
样本提取模块,用于提取n个人的训练人脸图像序列,记录每张训练图像的表情类型;
映射构建模块,用于以第j种表情类型作为感兴趣表情,对第i个人的训练人脸图像序列进行抽取拼接,由此建立第j种表情类型与训练人脸图像子序列的映射关系,i=1,…,n,j=1,…,m,m为表情类型数量;
所述抽取拼接是指从第i个人的训练人脸图像序列中分别抽取第z种和第j种表情图像序列,并将抽取的两种表情图像序列拼接,z∈{1,…,m},z≠j,其中,第z种表情图像序列按照表情强度值由峰值逐渐减小到中性值的顺序排列,第j种表情图像序列按照表情强度值由中性值逐渐增大到峰值的顺序排列;
样本对构建模块,用于在第j种表情的n*m个训练人脸子图像子序列中,两两不同帧组合为训练样本对;
模型训练模块,用于将组合得到的多个训练样本对作为排序卷积神经网络的输入,训练得到第j种表情的强度排序模型;
所述在线分析部分包括以下模块:
采集模块,用于采集待测人员的测试人脸图像序列;
表情测试样本对组建模块,用于从测试人脸图像序列中提取任意一帧与参考中性表情图像组成表情测试样本对;
表情判定模块,用于将表情测试样本对送入第j种表情的强度排序模型,j=1,…,m,强度排序模型的输出值中最大者对应的表情类型即为待测人员的表情类型;
表情强度测试样本对组建模块,用于在测试人脸图像序列中,两两不同帧图像组合为表情强度测试样本对;
强度判定模块,用于将表情强度测试样本对送入待测人员表情类型的强度排序模型,获得表情强度变化状态。
进一步地,所述抽取拼接得到的训练人脸图像子序列中,抽取的第z种表情图像序列排在前,抽取的第j种表情图像序列排在后;定义从图像子序列中提取的样本对为xp和xq,其中p和q为序列的帧号且满足1≤p<q≤l,l表示拼接序列的总长度,将顺序排列的样本对(xp,xq)作为正样本,将逆序排列的样本对(xp,xq)作为负样本。
进一步地,所述抽取拼接得到的训练人脸图像子序列中,抽取的第j种表情图像序列排在前,抽取的第z种表情图像序列排在后;定义从图像子序列中提取的样本对为xp和xq,其中p和q为序列的帧号且满足1≤p<q≤l,l表示拼接序列的总长度,将顺序排列的样本对(xi,xj)作为负样本,将逆序排列的样本对(xj,xi)作为正样本。
进一步地,所述排序卷积神经网络是vggnet、googlenet、resnet中的任意一种。
进一步地,所述表情类型包括生气、厌恶、恐惧、高兴、悲伤和惊讶。
与现有技术相比,本发明的优点和效果在于:
1、本发明利用表情序列的顺序训练排序模型,无需花费大量的人力对表情图像的强度进行手工标定,有利于解决训练表情强度估计模型时表情强度标签不足的问题;
2、本发明采用端到端的排序卷积神经网络来估计表情强度,无需手工提取图像特征,能在最大化保留人脸表情信息的同时,消除个体差异以及环境噪声,所用方法大大提高了表情强度的估计的正确率和鲁棒性;
3、本发明能同时估计表情的类别和强度,有利于计算机更好的理解人类的情绪,具有较强的现实应用。
附图说明
图1为本发明人脸表情强度估计方法的实现流程图;
图2为本发明人脸表情拼接序列图;
图3为本发明基于vgg-face的差分卷积神经网络结构图;
图4为本发明vgg-face模型的结构图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
附图1为本发明人脸表情分析方法的实现流程图。基于排序卷积神经网络的人脸表情分析方法,包括训练部分和测试部分。
所述训练部分包括以下步骤:
(s1)提取n个人的训练人脸图像序列,记录每张训练图像的表情类型。
可对训练数据预处理。使用现有人脸检测技术提取每张表情图像的人脸区域;对提取的人脸图像进行仿射变换,实现图像尺度归一化和人脸对齐。变换后,所有图像的尺寸保持一致,所有图像中眼睛的眼睛中心坐标保持一致。然后采用现有的任何技术识别和记录表情类型。
仿射变换将原坐标(x,y)变换为新坐标(x′,y′)计算公式如下:
x′=m11*x+m12*y+m13
y′=m21*x+m22*y+m23
其中,(m11,m12,m13;m21,m22,m23)为仿射变换矩阵中的变换参数,通过上面公式可以计算出原图像经过变换后的对齐图像。
(s2)(s2)以第j种表情类型作为感兴趣表情,对第i个人的训练人脸图像序列进行抽取拼接,由此建立第j种表情类型与训练人脸图像子序列的映射关系,i=1,…,n,j=1,…,m,m为表情类型数量。
在训练数据中,同一人有多种基本表情序列,本发明以六种表情示例说明,即生气、厌恶、恐惧、高兴、悲伤、惊讶。每一个表情序列都满足“中性—峰值”的演化模式,即面部肌肉从完全松弛状态到极限拉伸状态,将处于中性值的表情图像称为中性表情图像。
本发明将六种基本表情中的一种设置为感兴趣表情,分别与其他五种表情进行拼接。
拼接的第一种具体方式为:选取一种其他表情序列倒序排列,使其满足“峰值—中性”的演化模式,然后连接顺序排列的感兴趣表情序列,使得整个序列由“其他表情峰值”到“中性表情”再到“感兴趣表情峰值”。拼接序列参见附图2,图2中将高兴作为感兴趣表情,拼接时将生气峰值排在首帧,然后慢慢减弱,到不生气状态,接着慢慢变为高兴,最终到达高兴峰值。
拼接的第二种具体方法为:选取感兴趣表情倒序排列,使其满足“峰值—中性”的演化模式,然后连接顺序排列的其他一种表情序列,使得整个序列由“感兴趣表情峰值”到“中性表情”再到“其他一种表情峰值”。
(s3)在第j种表情的n*m个训练人脸子图像子序列中,两两不同帧组合为训练样本对。
按照一种优选的方式,对拼接的序列进行等间隔采样,选择采样后的序列中任意两帧作为训练样本对,这样由于邻近样本之间表情强度变化不明显,具有较少无效训练样本的好的技术效果。
定义从图像子序列中提取的样本对为xp和xq,其中p和q为序列的帧号且满足1≤p<q≤l,l表示拼接序列的总长度。对应拼接的第一种具体方式,将顺序排列的样本对(xp,xq)作为正样本,标记为1;将逆序排列的样本对(xp,xq)作为负样本,标记为0。或者,对应拼接的第二种具体方式,将顺序排列的样本对(xi,xj)作为负样本,将逆序排列的样本对(xj,xi)作为正样本。
(s4)将组合得到的多个训练样本对作为排序卷积神经网络的输入,训练得到第j种表情的强度排序模型。
构建排序卷积神经网络模型,构建的模型可同时处理两张图像所构成的样本对,模型前端为特征主干网,由多个卷积层和池化层构成,通过参数共享方式用于分别从两张图像中提取特征,然后经过差分层计算二者之间的差分特征,最后输入全连接层,用于实现由差分特征映射到样本对标记。网络模型参见附图3。网络模型的参数由预训练的模型进行初始化。
所述步骤(s4)所采用的排序卷积神经网络可以是vggnet、googlenet、resnet中的一种。其中,vggnet是牛津大学计算机视觉组和deepmind公司共同研发一种深度卷积网络。googlenet(也称inceptionnet)是2014年christianszegedy提出的一种全新的深度学习结构,它使用1x1的卷积来进行升降维同时在多个尺寸上进行卷积再聚合,能更高效的利用计算资源,在相同的计算量下能提取到更多的特征,从而提升训练结果。resnet在2015年被微软研究院团队研究员何恺明提出,在imagenet的classification、detection、localization以及coco的detection和segmentation上均斩获了第一名的成绩。
对步骤(s3)组建的样本输入步骤(s4)构建的排序卷积神经网络进行训练,训练过程使用sgd算法对交叉熵损失函数进行最优化,得到感兴趣表情的排序模型。
分别设置六种基本表情作为感兴趣表情,重复步骤(s1)(s2)(s3)(s4)(s5)训练六种基本表情的强度排序模型。
所述在线测试部分包括以下步骤:
(t1)采集待测人员的测试人脸图像序列。对测试图像序列的每一帧进行人脸检测和人脸对齐,得到表情序列。
(t2)从测试人脸图像序列中提取任意一帧与参考中性表情图像组成表情测试样本对。
(t3)将表情分类测试样本对分别送入六类感兴趣表情对应的模型中,得到的强度最大值的模型,则样本的类别即为模型的感兴趣表情类别。即按照以下公式计算图像的类别:
其中,m为估计的图像类别,sm为第m个表情强度排序模型的softmax层输出。
(t4)在测试人脸图像序列中,两两不同帧图像组合为表情强度测试样本对。
(t5)将表情强度测试样本对送入待测人员表情类型的强度排序模型,获得表情强度变化状态。
(t5)将表情强度估计测试样本对输入表情强度排序模型,表情强度排序模型的类别由步骤(t3)的输出决定,模型的输出可以判断强度估计测试样本对之间的表情强弱关系。如以下公式所示:
其中,r(x)为样本x的表情强度,y为表情强度排序模型的输出。
实例:
采用卡内基梅隆大学创建的ck+表情库,包含123个18-30岁的成年人,共计593个表情序列,其中65%为女性,35%为男性。本发明从123个人中选择选取96个人,每人至少含有2个基本表情序列可用于拼接,选择其中64个人用于训练,其余32个人用于测试。具体实现步骤如下:
1.对人脸表情图像进行预处理
(1.1)使用viola和jones提出的类haar特征和adaboost学习算法来检测每张表情图像的人脸区域;
(1.2)对步骤(1.1)提取的人脸图像进行仿射变换,实现图像尺度归一化和人脸对齐。变换后,所有图像的尺寸归一化至224×224,所有图像中眼睛的中心坐标保持一致,图中左眼坐标均为(63,63),右眼坐标均为(161,63);根据变换前后眼睛的坐标求取变换参数(m11,m12,m13;m21,m22,m23)。仿射变换将原坐标(x,y)变换为新坐标(x′,y′),计算公式如下:
x′=m11*x+m12*y+m13
y′=m21*x+m22*y+m23
通过上面公式可以计算出原图像经过变换后的新图像。
2.将同一人的感兴趣表情序列与其它表情序列拼接得到新的序列,组建训练样本库。
将用于训练的64个人的序列进行拼接,按照步骤(s2)所述方法,分别将高兴、生气、恐惧、悲伤、厌恶、惊讶6类表情设置为感兴趣表情,建立6类拼接序列库,按照步骤(s3)方法按间隔3进行采用,采样后的样本两两组对,得到训练样本库。
3.训练排序卷积神经网络
排序卷积神经网络的输入为来自训练样本对的两张图片(xi,xj)。网络的前端为特征提取主干网,使用vgg-face深度模型,vgg-face模型来自牛津大学vgg小组的工作,由vgg-16深度卷积神经网络对百万数量级的人脸样本训练得到,vgg-face结构参见附图4,包含多个卷积层和一个全连接层(fc1),分别提取图片xi和xj的特征,所提取的特征用f(xi;θ)和f(xj;θ)表示,其中f表示经过特征提取主干网(卷积层和fc1层)对图像进行的一系列特征提取操作,θ为特征主干网中的网络权值。将两个fc1层的输出相减构成差分层,差分层的输出为:dij=f(xj;θ)-f(xi;θ)。差分层后再接两个全连接层(fc2和fc3)。
两个全连接层的操作用g表示,用于对表情强度的排序。整个差分卷积神经网络的输出可表示为:
其中,
4.利用排序卷积神经网络估计表情类别和强度
将用于测试的32个人按照步骤(t2)组建表情分类测试样本,分别输入6个表情强度模型,根据步骤(t4)估计表情的类别;按照步骤(t3)组建表情强度测试样本对,输入根据(t5)估计表情类别对应的表情强度排序模型,估计测试样本对的表情强弱关系。
应用上述步骤得到的分类器进行表情分析,在ck+库上的表情识别率为91.5%,强度排序正确率为86.2%,优于现有利用深度模型得到的结果,表明本发明有效的抑制种族、性别、年龄等人体差异对表情识别造成的干扰。
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!