一种预取机制下融合BTB的方法与流程
本发明涉及中央处理器技术领域,具体为一种预取机制下融合btb的方法。
背景技术:
传统cpu前端取指带宽依赖于分支方向预测和分支地址预测,并通过取指缓冲遮盖取指过程中的cachemiss或分支预测跳转带来的前端bubble,因此预测精度决定了整个前端取指的能效比,极端指令序列会使分支变得难以预测,不管是方向还是跳转地址的预测错误都将带来很大的性能损失,而且增大指令调度压力,为此,我们提出了一种预取机制下融合btb的方法。
技术实现要素:
本发明的目的在于提供一种预取机制下融合btb的方法,以解决上述背景技术中提出的极端指令序列会使分支变得难以预测,不管是方向还是跳转地址的预测错误都将带来很大的性能损失,而且增大指令调度压力的问题,并提供另一种设计思路:定义一类分支地址计算指令,并且拥有自己的体系结构寄存器,每次执行地址计算的同时,发起取指请求,并预先将cacheline储存,通过renaming将需要跳转地址的分支指令和地址计算预取的cacheline相关联,同时应用btb技术来弥补指令调度不足过程中地址计算指令和分支指令过近带来的前端bubble。
为实现上述目的,本发明提供如下技术方案:一种预取机制下融合btb的方法,具体步骤如下:
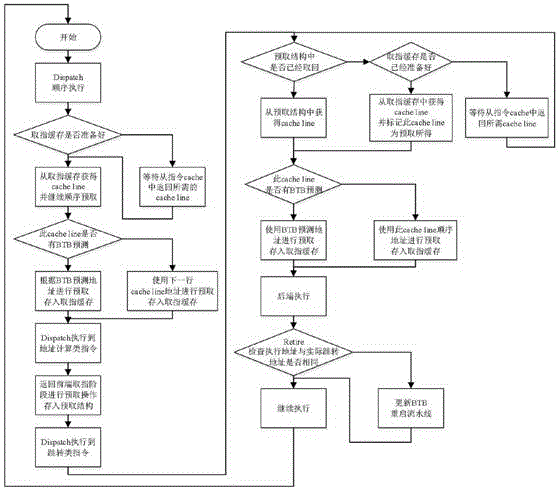
s1:disptach执行到地址计算类指令;
s2:返回前端取值阶段进行预取操作存入预取结构:n个与地址体系结构寄存器相关联的预取结构,每个结构里面有m个entry,entry等于对应体系结构寄存器重命名寄存器的个数,预取的取指缓存cacheline以乱序返回的形式存入对应的entry;
s3:disptach执行到跳转指令;
s4:判断预取结构中是否已经取回cacheline,若取回,则从预取结构中获得cacheline,若没有取回,则判断取指缓存是否已经准备好,若取指缓存准备好,则从取指缓存中获得cacheline,并标记此cacheline为预取所得,若取指缓存没有准备好,则等待从指令cache返回所需cacheline,并且重复该s4步骤,直到获得cacheline,在被预测指令被执行时,通过检查指令地址,判断之前分支指令是否预测错误,对于前端的取指请求,不论是对于预取结构还是取指缓存,如果未取回,则之后再取回的一瞬间可以被返回给dispatch;
s5:判断上述步骤获取的cacheline是否有btb预测,若cacheline有btb预测,则使用btb预测地址进行预取存入取指缓存,若acheline没有btb预测,则使用下一行cacheline地址进行预取存入取指缓存;
s6:后端执行;
s7:retire检查执行地址与实际跳转地址是否相同,若相同,则继续执行后结束,若不相同,则更新btb重启流水线后继续执行结束。
优选的,所述步骤s2中,取指缓存会进行顺序预取操作,取指缓存深度取决于cacheline宽度、前端取指延迟和dispatch宽度,对分支地址计算类指令,则根据其计算结果进行预取操作,结果保存到预取结构。
优选的,所述步骤s4中,从预取结构中获取到cacheline后,重新设置顺序取缓存的地址。
优选的,在被预测指令被执行时,通过检查指令地址,判断之前分支指令是否预测错误。
优选的,对于前端的取指请求,不论是对于预取结构还是取指缓存,如果未取回,则之后再取回的一瞬间可以被返回给dispatch。
与现有技术相比,本发明的有益效果是:该种预取机制下融合btb的方法,设计合理,既可以发挥预取机制的指令调度带来的性能增益,又可以通过btb弥补在极端指令序列下的预取不及时造成的前端取指性能不足,降低了因为btb预测错误造成性能损失的风险,发挥出编译器和硬件协同优化的优势,融合结构降低btb预测错误对前端取指带宽的影响,同时又充分缓解指令调度压力。
附图说明
图1为本发明在预取机制下融合btb方法流程图;
图2为本发明顺序执行情况流程图;
图3为本发明分支指令执行情况流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1-3,本发明提供一种技术方案:一种预取机制下融合btb的方法,该种预取机制下融合btb的方法,具体步骤如下:
s1:disptach执行到地址计算类指令;
s2:返回前端取值阶段进行预取操作存入预取结构:n个与地址体系结构寄存器相关联的预取结构,每个结构里面有m个entry,entry等于对应体系结构寄存器重命名寄存器的个数,预取的cacheline以乱序返回的形式存入对应的entry,取指缓存会进行顺序预取操作,取指缓存深度取决于cacheline宽度、前端取指延迟和dispatch宽度,对分支地址计算类指令,则根据其计算结果进行预取操作,结果保存到预取结构;
s3:disptach执行到跳转指令;
s4:判断预取结构中是否已经取回cacheline,若取回,则从预取结构中获得cacheline,若没有取回,则判断取指缓存是否已经准备好,若取指缓存准备好,则从取指缓存中获得cacheline,并标记此cacheline为预取所得,若取指缓存没有准备好,则等待从指令cache返回所需cacheline,并且重复该s4步骤,直到获得cacheline,从预取结构中获取到cacheline后,重新设置顺序取缓存的地址;
s5:判断上述步骤获取的cacheline是否有btb预测,若cacheline有btb预测,则使用btb预测地址进行预取存入取指缓存,若acheline没有btb预测,则使用下一行cacheline地址进行预取存入取指缓存;
s6:后端执行;
s7:retire检查执行地址与实际跳转地址是否相同,若相同,则继续执行后结束,若不相同,则更新btb重启流水线后继续执行结束。
预取指令机制下的必要结构梳理:
n个与地址体系结构寄存器相关联的预取结构,每个结构里面有m个entry,entry等于对应体系结构寄存器重命名寄存器的个数,预取的cacheline会以乱序返回的形式存入对应的entry。
顺序取指的缓存,深度取决于cacheline宽度,前端取指延迟以及dispatch宽度。
dispatch阶段如果顺序执行,那么会一直从顺序取指的缓存取指,如果遇到跳转指令,根据跳转的目标地址的体系结构寄存器号和重命名后的号,从对应的预取结构中拿cacheline。一旦成功从预取结构中获取到cacheline,重新设置顺序取缓存的地址。
每次当dispatch阶段发现跳转指令,并且成功将cacheline从预取结构取到后,更新顺序取指缓冲的地址,如果预取结构取出来的cacheline中有被btb预测命中的跳转指令,把预测的地址回填到顺序缓冲,由顺序缓冲发起一个或者多个btb嵌套请求。
dispatch阶段也发生了变化,当检测到跳转指令时,首先根据目标地址的体系结构寄存器号和重命名后的号,从对应的预取结构中拿cacheline,如果没有被取回,则尝试从顺序缓冲中取cacheline,这个是由btb预测的地址发起的请求,存回了顺序缓冲。
dispatch会先检测预取结构是否取回,这个可信度最高的,因此一旦地址预测错误,只需要更新btb,却不需要引发流水线cancel,因此不能在当前分支跳转指令提交时检查是否需要刷新流水线,每当一行cacheline被以btb预测的方式填入dispatch时,会有一个标志位与其一起跟随流水线被记录在reorderbuffer中,只有当头指针指向有这个标志位的entry时,需要检查体系结构寄存器真实值和当前指令地址是否相同,如果不同,取消整个流水线。设计每次分支跳转指令被retire时,记录跳转的体系结构寄存器号,当检查地址预测的时候,把对应的体系结构寄存器值读出来就可以用于对比和判断。
btb的更新通过在分支跳转指令retire时对比预测地址和实际跳转值而决定。
每次预取结构发请求时,把地址和顺序缓冲地址作比较,如果顺序缓冲的btb已经承担取指任务,则等待回填的时候一起填到两处。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!