基于深度神经网络的电力检修文本挖掘方法与流程
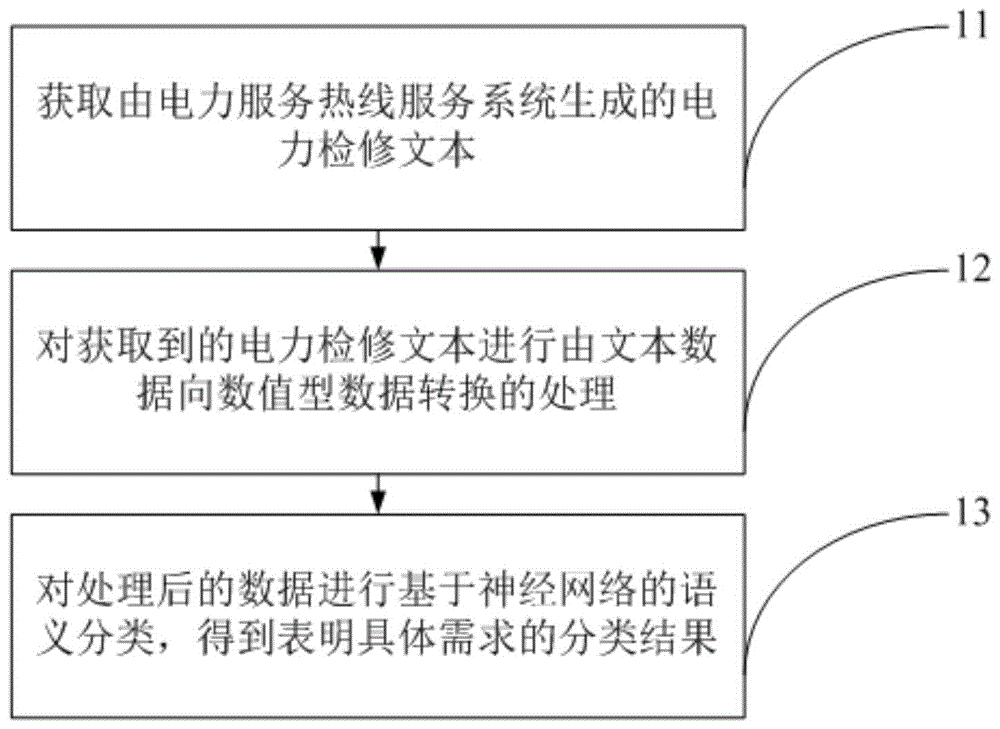
本发明属于文字处理领域,特别涉及基于深度神经网络的电力检修文本挖掘方法。
背景技术:
:随着各种文本数据的不断积累,电力行业中正在越来越多地使用文本挖掘技术。由于非结构文本数据的复杂性,使用传统文本挖掘方法已经越来越不能满足业务需求。在引入深度学习技术处理复杂文本的时,一种文本的分布式表示方法——词向量,已经成为文本挖掘任务中至关重要的一环。词向量表达能力的强弱,往往会直接影响后续文本挖掘任务。相比于传统的one-hot、tf-idf文本表示技术,词向量在向量化文本的过程中可有效的保留部分语义信息,向量空间的距离对应了相应词的语义相似度,这使得各种文本挖掘任务效果有了很大提升。以上研究中,使用的词向量都是由本领域专业语料库训练而来。然而,词向量的表达能力取决于训练语料库的大小和质量,由于电力行业语料库的匮乏,单个系统积累的文本往往难以达到这个级别,使得训练的词向量效果也相对较差。技术实现要素:为了解决现有技术中存在的缺点和不足,本发明提供了基于深度神经网络的电力检修文本挖掘方法,通过使用神经网络算法能够提高文本识别的准确性。为了达到上述技术目的,本发明提供了基于深度神经网络的电力检修文本挖掘方法,所述文本挖掘方法,包括:获取由电力服务热线服务系统生成的电力检修文本;对获取到的电力检修文本进行由文本数据向数值型数据转换的处理;对处理后的数据进行基于神经网络的语义分类,得到表明具体需求的分类结果。可选的,所述对获取到的电力检修文本进行由文本数据向数值型数据转换的处理,包括:使用skip-gram模型的中word2vec分布式表示方法完成词向量的训练过程,变量xk为输入词语,y1j,y2j...ycj为xk对应的上下文词语。hi为隐层变量,词向量即为模型训练完成后隐层的偏置矩阵。可选的,所述对处理后的数据进行基于神经网络的语义分类,得到表明具体需求的分类结果,包括:对处理后的数据进行包括数据清洗在内的预处理操作;为了对比不同的词向量对算法的影响,模型会输入不同预训练词向量,然后将词向量输入到不同的神经网络模型中进行训练和分类。本发明提供的技术方案带来的有益效果是:本文首先研究了电力行业文本挖掘技术,发现已有研究大多使用本行业小规模专业语料库进行词向量的训练。这种研究方式由于语料库词汇规模的限制,在一定程度上影响了词向量的表达能力。本文以95598系统的检修记录作为研究对象,引入外部大规模通用预训练词向量到电力行业文本挖掘中来。并通过基于深度神经网络的text-cnn和bilstm分类模型来验证不同词向量对文本分类任务的影响。实验证明,大规模外部通用预训练词向量的引入可以大幅提升文本分类效果,这说明引入外部知识可以有效地提升电网行业文本挖掘任务的效果。附图说明为了更清楚地说明本发明的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。图1是本发明提供的基于深度神经网络的电力检修文本挖掘方法的流程示意图;图2是本发明提供的基于skip-gram的词向量模型示意图;图3是本发明提供的bilstm网络结构示意图;图4是本发明提供的text-cnn网络结构示意图;图5是本发明提供的基于深度神经网路的文本分类模型示意图;图6(a)是本发明提供的显示了分别使用5种预训练词向量训练bilstm模型后准确率变化示意图;图6(b)是本发明提供的基于不同词向量的网络模型在训练过程中误差loss变化示意图;图7(a)是本发明提供的预训练词向量训练text-cnn模型后准确率变化示意图;图7(b)是本发明提供的不同的text-cnn模型的在训练过程中loss变化示意图。具体实施方式为使本发明的结构和优点更加清楚,下面将结合附图对本发明的结构作进一步地描述。实施例一本发明提供了基于深度神经网络的电力检修文本挖掘方法,所述文本挖掘方法,如图1所示,具体包括:11、获取由电力服务热线服务系统生成的电力检修文本;12、对获取到的电力检修文本进行由文本数据向数值型数据转换的处理;13、对处理后的数据进行基于神经网络的语义分类,得到表明具体需求的分类结果。本文以全国电力系统的服务热线95598系统积累的检修文本为例,将故障原因抽象为5类,并对故障文本进行故障分类。在此基础上,本文探索了大规模公开的通用预训练词向量在电网文本挖掘中的应用,将开源的通用预训练词向量直接应用到电力行业检修文本分类任务中去,而不再使用电网文本单独训练词向量。电力行业自动化系统众多,每天运行产生大量各种非结构化和半结构化的文本数据。本文采用全国电力95598服务热线系统产生的文本数据作为研究对象。95598热线系统会记录用户的来电信息并追踪用户来电事件,根据接报信息筛选事件类型,将事件下派至相应的抢修班进行现场抢修。在进行现场的抢修的过程中,抢修人员会根据具体的现场抢修详情上传现场抢修记录。95598热线具体的文本结构如图1所示,主要包括抢修单位、现场抢修记录、接报时间、发生地点等部分。其中,现场抢修记录完的记录了整个抢修的事件的全过程,是重要的文本挖掘资源。现场抢修记录完整描述了整个抢修事件的各个要素,包含故障类型、故障时间、故障地点、故障描述、故障原因、抢修人、抢修完成时间等。但是,由于记录内容是人为手工录入,文本内容格式不完全固定,并且存在很多错误内容。这使得使用传统的技术自动地进行文本挖掘的难度较大。本文在引入预训练词向量的基础上,尝试使用基于深度神经网络的模型对现场抢修文本进行精确分类。可选的,所述对获取到的电力检修文本进行由文本数据向数值型数据转换的处理,包括:使用skip-gram模型的中word2vec分布式表示方法完成词向量的训练过程,变量xk为输入词语,y1j,y2j...ycj为xk对应的上下文词语。hi为隐层变量,词向量即为模型训练完成后隐层的偏置矩阵。在实施中,计算机系统中,图像、语音等多媒体以采样值为基本单位,可以直接进行数值运算。不同于图像、语音等,文本数据则以字符为基本单位,不能直接进行数值运算。因此,在进行文本挖掘之前,首先要将文本数据转换为数值型数据。自然语言处理技术中,将这个过程称为文本的向量化表示过程,并且文本表示的效果对后续的文本挖掘任务有十分直接的影响。传统的文本表示方法采用向量空间(vectorspacemodel,vsm)对文本进行向量化。vsm的概念由salton等[4]人于60年代提出,并成功地应用于著名的smart文本检索系统。其主要思想是使用矩阵对句子集合进行表示,根据选取特征方式的不同,有one-hot编码、词频–逆文档频率(tf-idf)表示等。传统的文本表示方法随着文本规模的增大存在特征维度过高、数据稀疏、无法保留词序信息、存在语义鸿沟等缺陷。自深度学习兴起后,一种来源于神经网络语言模型(neuralnetworklanguagemodel,nnlm[5])的分布式表示方法——词向量word2vec[6],被提出并大规模使用。word2vec使用低维紧凑的连续词向量对上下文进行表示,解决了传统文本表示方法带来的数据稀疏、语义鸿沟等问题。word2vec的实现方法中,主要有skip-gram和cbow(continuousbag-of-wordsmodel)两种模型。从实现方式上看,skip-gram是给定输入词来预测该词的上下文;而cbow是给定一个上下文,来预测输入词。本文采用基于skip-gram模型的word2vec来训练词向量,其模型结构如图2所示。图2中,变量xk为输入词语,y1j,y2j...ycj为xk对应的上下文词语。hi为隐层变量,词向量即为模型训练完成后隐层的偏置矩阵。数据集字符数词数95598工单138.6万1.3万微博13600万85万知乎38400万111.7万人民日报66300万166.4万百度百科74500万542.2万表1语料库规模词向量的表达能力往往取决于训练语料库的规模和质量等因素。较小规模的语料库往往由于训练样本较少,词语覆盖度低,导致词向量的表达效果不佳,从而对后续的文本挖掘任务造成影响。如表1所示,展示了95598工单文本库和常用几种开源的中文语料库在规模上的巨大差异。由于只需要满足于单一领域的需求,专业领域的语料库往往规模较小,词语覆盖面较窄。这也使得使用专业领域的语料库训练的词向量虽然可以覆盖一些本专业词语,但其整体表达能力有限。如表2所示,展示了使用不同的语料库训练得到词向量后,分别获取的与“漏电”最相近的9个词语。从表2可以看出,使用95598工单文本库训练的词向量在表达能力上最差;使用大规模语料库训练的词向量则有较好的表达能力,同时也在一定程度上覆盖了电力领域的专业词汇。表2不同词向量中的词语相似度可选的,所述对处理后的数据进行基于神经网络的语义分类,得到表明具体需求的分类结果,包括:对处理后的数据进行包括数据清洗在内的预处理操作;为了对比不同的词向量对算法的影响,模型会输入不同预训练词向量,然后将词向量输入到不同的神经网络模型中进行训练和分类。在实施中,相比于朴素贝叶斯、支持向量机等传统的文本分类模型,基于深度网络的文本分类模型具有强大的特征自学习、强大的非线性拟合能力,对于相对复杂的文本分类任务表现出更好的分类效果。本文分别使用循环神经网络和卷积神经网络作为分类模型,以验证大规模预训练的词向量在电力文本中的表达能力。传统的前馈神经网络中,层与层之间的神经元是全连接的,层内部的神经元无连接。这种神经网络对存在前后依赖关系的序列数据是无能为力的。为此,具有特殊结构的循环神经网络(recurrentneuralnetwork,rnn)被提出,它可以保存序列间的前后关系,形成所谓的“记忆”。但是,循环神经网络很难通过反向传播算法来训练。主要的困难在于梯度消失和梯度爆炸问题,这意味着通过网络传播回来的梯度要么衰减,要么呈指数膨胀。长短期时记忆网络(longshort-termmemory,lstm[7])对传统的循环神经网络结构进行了修改,避免了消失梯度问题,保持了训练算法的稳定性。作为一种单向的神经网络,lstm只能保存前向的序列信息,这对一些同时需要获取序列上下文信息的任务效果有限。双向长短期记忆网络(bidirectionalrecurrentneuralnetworks,bilstm)是长短期记忆网络lstm的一种扩展,它由双层lstm组成。一个前向的lstm层可以捕捉序列前向的信息内容,另一个后向的lstm可以从后向前“看”,从而捕捉序列后向的信息内容。如图3所示,展示了bilstm的基本网络结构。bilstm对于文本分类等需要依赖输入上下文内容的任务具有很好的效果。卷积神经网络(convolutionalneuralnetworks,cnn)最早被用在图像识别任务中,在数字图像处理领域中取得了巨大的成功。随着深度学习技术在自然语言处理领域的应用,卷积神经网络也被成功的引入到自然语言处理中。经典的cnn往往由卷积层、池化层、全连接和softmax分类层组成。卷积层通过卷积核对输入矩阵进行不断的卷积操作,得到的featuremap在max-pooling等池化层操作下降维,最后经过全连接和softmax层后完成分类。在文本分类中,句子的长度往往不统一,而经典的cnn结构往往要求输入为固定尺寸。为了解决这个问题,nlp任务中一般采用单层cnn结构(一对卷积层和池化层),并在进行卷积时以行(每行为一个词)为基本单位。这样即使输入矩阵尺寸不固定,经过卷积池化操作后,矩阵也会变为统一尺寸的一维向量,从而可以继续完成后续的分类操作。这种结构的卷积神经网络被称为text-cnn,如图4所示。在实验时,首先使用95598文本数据进行数据清洗、中文分词等预处理操作。为了对比不同的词向量对算法的影响,模型会输入不同预训练词向量,然后将词向量输入到不同的神经网络模型中进行训练和分类。具体的算法流程如图5所示。本文对比了多种公开的预训练词向量对电网故障文本分类任务的影响,以及多种神经网络在故障文本分类中的效果。实验证明,公开的大规模预训练词向量完全可以直接应用到电网行业文本挖掘任务中去,并且分类效果良好。本发明提供了本文以全国电力系统的服务热线95598系统积累的检修文本为例,将故障原因抽象为5类,并对故障文本进行故障分类。在此基础上,本文探索了大规模公开的通用预训练词向量在电网文本挖掘中的应用,将开源的通用预训练词向量直接应用到电力行业检修文本分类任务中去,而不再使用电网文本单独训练词向量。本文对比了多种公开的预训练词向量对电网故障文本分类任务的影响,以及多种神经网络在故障文本分类中的效果。实验证明,公开的大规模预训练词向量完全可以直接应用到电网行业文本挖掘任务中去,并且分类效果良好。实验准备为了充分验证深度神经网络和预训练词向量在电力文本挖掘中的效果,本实验尽可能多的收集了实验样本。实验数据为2014年至2018年,杭州市95598电力服务热线的接报后的故障检修记录数据。数据的主要内容和格式如论文第2部分介绍。实验首先对数据进行了初步清洗,去除错误和缺失的数据,并根据文本内容对数据进行人工类别标注。将检修记录根据引起故障的原因分为5大类,建立电力检修文本语料库,具体类别标签如表3所示。建立的电力检修文本语料库共有5大类,约62098条检修文本记录。在训练模型时,随机选择49677条记录作为训练集,剩下的12421条数据作为测试集。表3故障文本分类为了研究大规模预训练词向量在不同网络结构中的效果,本文使用了bilstm和cnn两种网络结构,两种网络的网络参数如表4所示。在两种网络结构中,都加入了嵌入层(embedding层),以便导入预训练的词向量。网络训练时,embedding层参数将会被初始化为预训练的词向量矩阵,并将该层设置为不可训练,参数不参与网络的更新。为了探究预训练词向量对分类模型的影响,本文使用了常用的开源预训练词向量[8]。根据使用的训练语料库不同,预训练词向量分别为,微博词向量、知乎词向量、人民日报词向量和百度百科词向量。它们分别所含的词汇量如表1所示。此外,本文使用95598文本库和开源的词向量训练工具gensim[9]训练了基于955985文本库的本地词向量。以上所有词向量均为300维。表4网络模型参数本实验分类模型基于开源深度框架keras进行搭建。实验使用的计算机cpu为intelcorei7-6700hq,内存为32gb,gpu为nvidiageforcegtx1080ti;操作系统为64位ubuntu14.04lts。实验结果和分析本实验首先使用基于bilstm的文本模型进行实验。实验使用95598工单检修记录文本作为输入,每条记录为一个单独样本。分别根据不同的预训练词向量训练不同的bilstm分类模型。测试时,使用5种分类的平均准确率作为评价指标。如图6(a)所示,显示了分别使用5种预训练词向量训练bilstm模型的过程中,随着训练次数epoch的增加,平均准确率变化的情况。可以看出,使用大规模预训练词向量的模型,准确率迅速上升,并最终达到了99%以上。而使用本地95598工单训练词向量的准确率则缓慢上升,最终只达到了80%左右,与基于开源预训练词向量的模型分类效果差距明显。图6(b)则展示了基于不同词向量的网络模型在训练过程中误差loss变化的过程。从图中可以明显看出,使用开源预训练词向量的网络loss迅速下降,网络收敛速度更快。而使用本地95598文本训练词向量的网络,loss下降到一定程度不再下降。同样,使用不同的词向量来训练基于text-cnn的文本分类模型。图7(a)展示了分别使用5中预训练词向量训练text-cnn模型的过程中,随着训练次数epoch的增加,平均准确率变化的情况。从图中可以看出,基于开源预训练词向量的模型随着epoch的增大准确率同样迅速增加,并且最终的准确率也都在99%以上;而使用本地95598工单词向量的网络准确率则只达到了88%左右。图7(b)显示的不同的text-cnn模型的在训练过程中loss变化与图6(b)基本一致,说明使用大规模预训练词向量的分类模型效果远远优于未使用本地词向量的。最终,基于不同的词向量的两种网络模型的分类效果如表5所示。从以上两种分类模型对比实验可以看出,使用大规模的预训练开源词向量的分类模型分类效果远远优于使用小规模专业语料库训练的本地词向量。这说明,通用的预训练词向量完全可以引入到电力行业的文本挖掘任务中,而不必担心缺乏专业词汇而导致效果较差问题。同时,从对比实验也可以看出,基于卷积神经网络的text-cnn模型在本任务的分类效果更佳,并且训练过程text-cnn模型也比bilstm的效率更高,收敛速度更快。词向量95598微博知乎人民日报百度百科bilstm76.1898.3898.9099.3899.50text-cnn88.2299.1299.4599.5099.87表5模型分类准确率本文首先研究了电力行业文本挖掘的现状,发现文本任务中使用的词向量多由本行业小规模语料库训练而来。这在一定程度上覆盖了部分专业词汇,但使得词向量的表达能力减弱,影响后续的文本挖掘任务。本文以95598服务热线的记录数据为研究对象,探索了大规模开源通用预训练词向量在电网文本挖掘中的应用,对比了多种神经网络在检修文本分类中的效果。实验证明,引入通用的大规模预训练词向量,并没有因为专业词语覆盖度降低而影响分类效果,反而使得分类准确率大幅提升。这说明大规模外部词向量的引入,对提升电力行业复杂文本挖掘任务的效果有重要意义。上述实施例中的各个序号仅仅为了描述,不代表各部件的组装或使用过程中的先后顺序。以上所述仅为本发明的实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1