面向网络直播场景的用户言论语义分析方法与流程
本发明涉及一种针对用户言论的语义分析方法,具体而言,涉及一种面向网络直播场景的用户言论语义分析方法,属于深度学习及文本内容技术领域。
背景技术:
近年来,网络直播行业发展极为迅速,各种直播平台层出不穷,观看直播的用户准入门槛低,其用户群体整体呈现低龄化态势。而网络直播平台的一个显著特点就是用户可以在评论区随意的发表自己的言论,同时这些言论会以弹幕的形式显示在直播间,使身处同一个直播间的所有用户(包括主播)都能看到。
但在实际的平台运营过程中,人们发现,总会出现有一些个人素质不高的用户,为了追求低级趣味,在弹幕上出口成脏,发表不雅、不健康的言论。由于弹幕的即时性和瞬时性特点,言论一出即成为既定事实,相关的管制措施往往起不到任何实质性的作用;同时由于弹幕的隐秘性,有些低俗弹幕不能被及时地发现并处理,这对青少年、对社会都造成了极大的危害。
目前,网络直播平台对于用户言论的监督大多还停留在对弹幕字词的简单屏蔽上,并未没有真正实现语义分析,监督效果不甚理想。由于弹幕具有多变化、多元化、碎片化等特性,使得一些不包含常见敏感词汇但是具有低俗趣味意义的言论得不到有效的处理;其次,弹幕一出直播间内所有人都能看到,对其进行简单屏蔽并不能从源头上解决问题,从而不能保证监督的实时性。
综上所述,如何在现有技术的基础上提出一种针对用户言论的语义分析方法,实现对网络直播平台内用户言论的有效监督,也就成为了本领域内技术人员亟待解决的问题。
技术实现要素:
鉴于现有技术存在上述缺陷,本发明的目的是提出一种面向网络直播场景的用户言论语义分析方法,包括如下步骤:
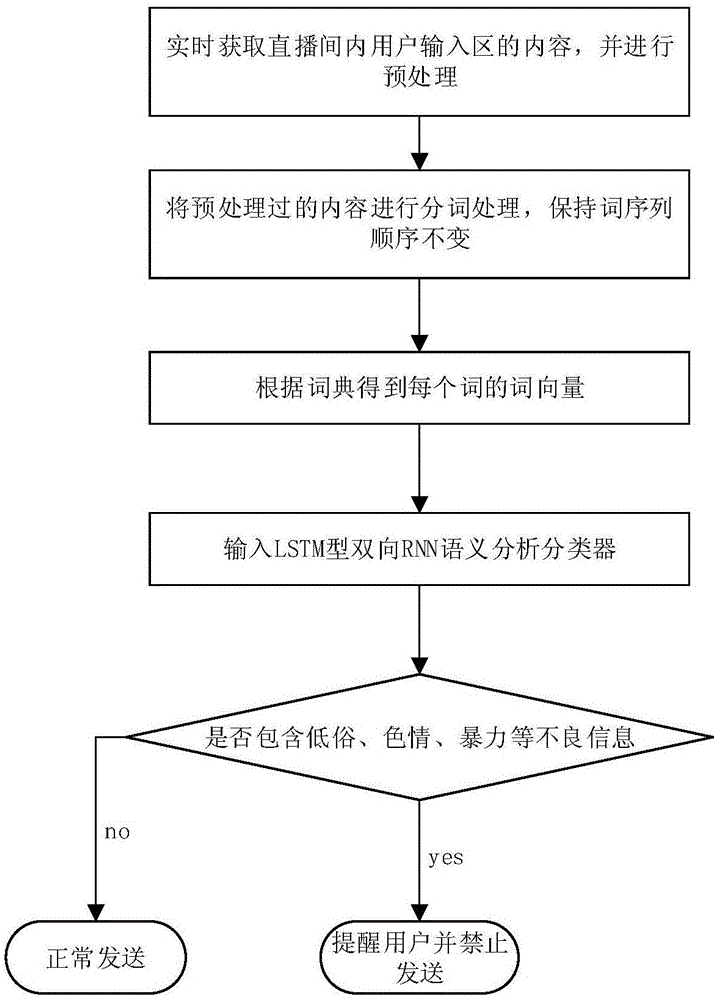
s1、实时获取网络直播平台直播间内用户输入区的内容,并进行预处理;
s2、将预处理过的内容进行分词处理,保持词序列顺序不变;
s3、根据语料词典得到每个词的词向量,进而得到用户输入内容的向量表示;
s4、构建并训练lstm型双向rnn语义分析分类器模型;
s5、依据s4中建立的模型判断用户输入内容是否包含不良信息,若不包含则正常发送,否则提醒用户并禁止发送。
优选地,s1中所述预处理具体包括:去除与文字内容无关的多余信息,所述多余信息包括表情图片、表情符号、数字符号以及拼音符号。
优选地,s3中所述根据语料词典得到每个词的词向量具体包括:将每个词表示成一个独热向量,向量的维度为语料词典的长度;所述语料词典由网络直播平台上的语料形成,所述语料词典中的字词不重复。
优选地,s4具体包括如下步骤:
s41、收集网络直播平台上各种类型直播中的用户输入内容,并逐条进行标记,将包含不良信息的内容标记为0,否则标记为1;
s42、将收集的用户输入内容进行预处理,划分训练集和测试集,构建语料词典;
s43、根据语料词典把用户输入文本内容用词向量的形式表示出来,按照词序列顺序将词向量进行连接;
s44、将带有标签的训练数据输入到lstm型双向rnn语义分析分类器中进行训练,获取最佳的神经网络模型参数,最终得到lstm型双向rnn语义分析分类器模型。
优选地,s44具体包括如下步骤:
s441、设计lstm型双向rnn结构、构建lstm型双向rnn语义分析分类器,得到lstm型双向rnn语义分析分类器模型;
s442、训练模型参数,完成对lstm型双向rnn语义分析分类器模型的训练。
优选地,s44中所述lstm型双向rnn语义分析分类器包括按序依次连接的输入层、隐藏层及输出层;
所述输入层的输入为代表文本内容的词序列;
所述隐藏层由多个lstm单元相连接而成,其中包括按照词序列正向传输的lstm单元和按照词序列反向传输的lstm的单元。
优选地,所述输出层为分类器,所述分类器为二分类器。
优选地,所述lstm单元为拥有三个门结构的特殊网络,三个门均由sigmoid函数控制,可有选择性的控制信息流的传递,三个门分别为输入门、遗忘门及输出门。
优选地,所述不良信息包括低俗信息、色情信息及暴力信息。
与现有技术相比,本发明的优点主要体现在以下几个方面:
本发明可以在无人工参与的情况下自动地完成对用户言论的语义分析、从源头上对网络直播平台内的用户言论进行监督,不仅能够保证监督的实时性和有效性,而且也降低了监督过程对于人工操作的依赖、节约了人工成本。
本发明采用lstm型的双向rnn神经网络结构进行语义分析,在分析过程中既参考了历史信息也参考了未来信息,有效地提升了监督的准确性。同时,本发明能够对所有直播平台上的所有用户进行具有实时性和有效性的监督,监督范围广、适用性强。
此外,本发明也为同领域内的其他相关问题提供了参考,可以以此为依据进行拓展延伸,运用于同领域内其他用户言论语义分析的技术方案中,具有十分广阔的应用前景。
以下便结合实施例附图,对本发明的具体实施方式作进一步的详述,以使本发明技术方案更易于理解、掌握。
附图说明
图1为本发明的流程示意图;
图2为本发明中的lstm型双向rnn语义分析分类器模型训练流程图;
图3为本发明中的双向rnn语义分析分类器模型结构框图。
具体实施方式
如图1~图3所示,本发明揭示了一种面向网络直播场景的用户言论语义分析方法,包括如下步骤:
s1、实时获取网络直播平台直播间内用户输入区的内容,并进行预处理。所述预处理具体为去除与文字内容无关的多余信息,所述多余信息包括表情图片、表情符号、数字符号以及拼音符号等。
s2、将预处理过的内容进行分词处理,保持词序列顺序不变。
s3、根据语料词典得到每个词的词向量,将每个词表示成一个独热向量,向量的维度为语料词典的长度。所述语料词典由网络直播平台上的语料形成,所述语料词典中的字词不重复。进而得到用户输入内容的向量表示。
s4、构建并训练lstm型双向rnn语义分析分类器模型。这一过程如图2所示,具体包括如下步骤:
s41、收集网络直播平台上各种类型直播中的用户输入内容,并逐条进行标记。
首先,利用网络爬虫搜集各大网络直播平台(如斗鱼,战旗,熊猫,yy等)上各种类型直播(如游戏直播,秀场直播,新闻直播等)中的用户言论,同时把平台管理员根据以往经验拦截下的一些用户言论也一并收集,形成语料库。收集的用户语句越多,则语料库就越完备。之后,将这些语句整理并标记,刨去相同的语句,将包含低俗,黄色,暴力等不良信息的言论标记为0,反之,把不包含这些信息的言论标记为1。
s42、将收集的用户输入内容进行预处理,划分训练集和测试集,构建语料词典。
所述预处理包括删除这些言论中一些无意义的符号,例如表情图片,表情符号、数字符号以及拼音、空格等,为保持言论语义完整,要保留标点符号。之后将这些言论分成两部分,其中75%作为训练集,剩下的为测试集,不管是测试集中还是训练集中都包含一定比例的正负样本,以防止样本的不均衡性对分类结果产生影响。然后,利用stanford-segmenter分词器对其中文分词,这是一款开源分词器,使用简单,分词效果好,待处理语句经过分词形成了输入模型的字词序列,将语料中所有的不重复的字词组合起来就形成了语料词典。
s43、根据语料词典把用户输入文本内容用词向量的形式表示出来,按照词序列顺序将词向量进行连接。
根据词典可以把字词序列中的每个词用一个很长的向量表示,向量的长度即为词典的长度,每个词为这个特征向量中的一个特征。假如有一个词典,词典中包含10个词,则一个词就需要用10维向量表示,如x('美丽')=[0,1,0,0,0,0,0,0,0,0],
x('大方')=[0,0,1,0,0,0,0,0,0,0]利用这种方法可以把每条用户言论数字化,转变成词向量序列,方便输入模型进行分析。
s44、将带有标签的训练数据输入到lstm型双向rnn语义分析分类器中进行训练,获取最佳的神经网络模型参数,最终得到lstm型双向rnn语义分析分类器模型。
所述lstm型双向rnn语义分析分类器包括按序依次连接的输入层、隐藏层及输出层。
所述输入层的输入为代表文本内容的词序列。所述隐藏层由多个lstm单元相连接而成,其中包括按照词序列正向传输的lstm单元和按照词序列反向传输的lstm的单元,用于提取输入文本的语义特征,根据上下文进行语义分析。所述输出层为分类器,用于根据所述隐藏层的语义分析结果进行分类判别,在其判别的过程中既依赖了文本的历史信息、也依赖了文本的未来信息,从而使得判别结果更加准确合理。所述分类器为二分类器,常用的强分类器,如svm、logistic回归效果都不错。
所述lstm单元为拥有三个门结构的特殊网络,三个门均由sigmoid函数控制,可有选择性的控制信息流的传递,三个门分别为输入门、遗忘门及输出门。
所述输入门用于控制有多少信息可以流入记忆单元;所述遗忘门用于控制上一时刻记忆单元中有多少信息可以流入当前记忆单元;所述输出门用于控制当前记忆单元中有多少信息可以流入当前隐藏状态中。
s44具体包括如下步骤:
s441、设计lstm型双向rnn结构、构建lstm型双向rnn语义分析分类器,得到lstm型双向rnn语义分析分类器模型。
本发明中的双向rnn语义分析分类器结构如图3所示,将向量化的词序列分别由首至尾和由尾到首输入到双向rnn神经网络中,隐藏层每一个lstm单元都具有记忆功能,能同时接收来自输入层和前一个lstm单元的数据,它们依次连接,最后一个lstm单元则包含以前所有的数据信息,所以只需将隐藏层的最后一个lstm单元的输出传给分类器进行判别,分类结果既依赖了以前信息也依赖了未来信息。其中隐藏层lstm单元的三个门结构赋予神经元判断力,控制力和记忆力,具体计算公式如下所示。
输入门:it=σ(wi·[ht-1,xt]+bi)
遗忘门:ft=σ(wf·[ht-1,xt]+bf);
当前时刻状态:;ct=ft*ct-1+it*tanh(wc·[ht-1,xt]+bc)
输出门:ot=σ(wo·[ht-1,xt]+bo);
lstm单元输出:ht=ot*tanh(ct);
其中,w为权重矩阵,b为偏置矩阵,xt为t时刻的输入,ht为t时刻隐藏层的输出,ct为t时刻lstm单元的状态,σ为三个控制门的激活函数,公式为:
激活函数tanh公式为:
文本信息通过该结构,可以自动提取用户言论语义特征,无需手动设置特征模板,不仅节省人力,通用性好,而且准确率较传统处理方法显著提高。
为了不增加模型的复杂度,该模型采用分类器为logistic回归,即在线性回归的基础上套用了一个逻辑函数,具体公式如下:
当最后输出hθ≥0.5时,判定用户言论无不良信息;当hθ≤0.5时,判定用户言论包含不良信息。
s442、训练模型参数,完成对lstm型双向rnn语义分析分类器模型的训练。
将经过人工标记的训练样本中用户言论的字词向量按时刻先正向输入双向rnn中,再反向输入rnn中,正向和反向输入过程中,各个时刻所述双向rnn的隐含层的输入信号除了包含当前时刻的输入向量数据外,还包括当前时刻的前一时刻隐含层的输出数据。
在训练过程中当预测结果与训练样本的标注结果具有偏差时,通过神经网络中经典的误差反向传播算法来调整神经网络中的各个权重,误差反向传播算法将误差逐级反向传播分摊到各层的所有神经元,获得各层神经元的误差信号,进而修正各神经元的权重。通过向前算法逐层传输运算数据,并通过向后算法来逐渐修改各神经元的权重的过程就是神经网络的训练过程;重复上述过程,直到预测结果的正确率达到设定的阈值,停止训练,此时可认为所述lstm型双向rnn模型已经训练完成。
在训练分类器的参数时采用梯度下降法,参数的更新公式如下:
其中,α为学习率一般取较小的值。
s5、依据s4中建立的模型判断用户输入内容是否包含不良信息,若不包含则正常发送,否则提醒用户并禁止发送。所述不良信息包括低俗信息、色情信息及暴力信息等。
本发明可以在无人工参与的情况下自动地完成对用户言论的语义分析、从源头上对网络直播平台内的用户言论进行监督,不仅能够保证监督的实时性和有效性,而且也降低了监督过程对于人工操作的依赖、节约了人工成本。
本发明采用lstm型的双向rnn神经网络结构进行语义分析,在分析过程中既参考了历史信息也参考了未来信息,有效地提升了监督的准确性。同时,本发明能够对所有直播平台上的所有用户进行具有实时性和有效性的监督,监督范围广、适用性强。
此外,本发明也为同领域内的其他相关问题提供了参考,可以以此为依据进行拓展延伸,运用于同领域内其他用户言论语义分析的技术方案中,具有十分广阔的应用前景。
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神和基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内,不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
- 还没有人留言评论。精彩留言会获得点赞!