通用大数据实时处理开发平台及其数据处理方法与流程
本发明涉及数据处理技术领域,尤其涉及一种通用大数据实时处理开发平台及其数据处理方法。
背景技术:
目前,在数据处理领域中有诸多不同但本质又相似的解决方案,这些方案对数据的处理流程通常包含:数据采集、数据传输、数据处理、数据存储这四个步骤,每个步骤都可以作为一个单独模块,在设计数据处理是系统时,可以将上述的单独模块进行自研或采用开源组件进行排列组合。对于中小科技公司来说自身业务中少不了对数据的处理部分,如果采用自研路线,每实现一个业务可能都需要从头到尾重复开发这些数据处理系统,这其中的工作量占据了一大半的项目开发时间,而且完成系统后由于耦合了业务特点,还需安排专人对不同业务系统进行维护,对公司的资源是一种严重的浪费。如果采用开源或者混合方案,需要在众多开源组件里针对不同业务进行技术选型,技术选型中存在一定的甄别难度。
有鉴于此,有必要提出对目前的数据处理系统进行进一步的改进。
技术实现要素:
为解决上述至少一技术问题,本发明的主要目的是提供一种通用大数据实时处理开发平台及其数据处理方法。
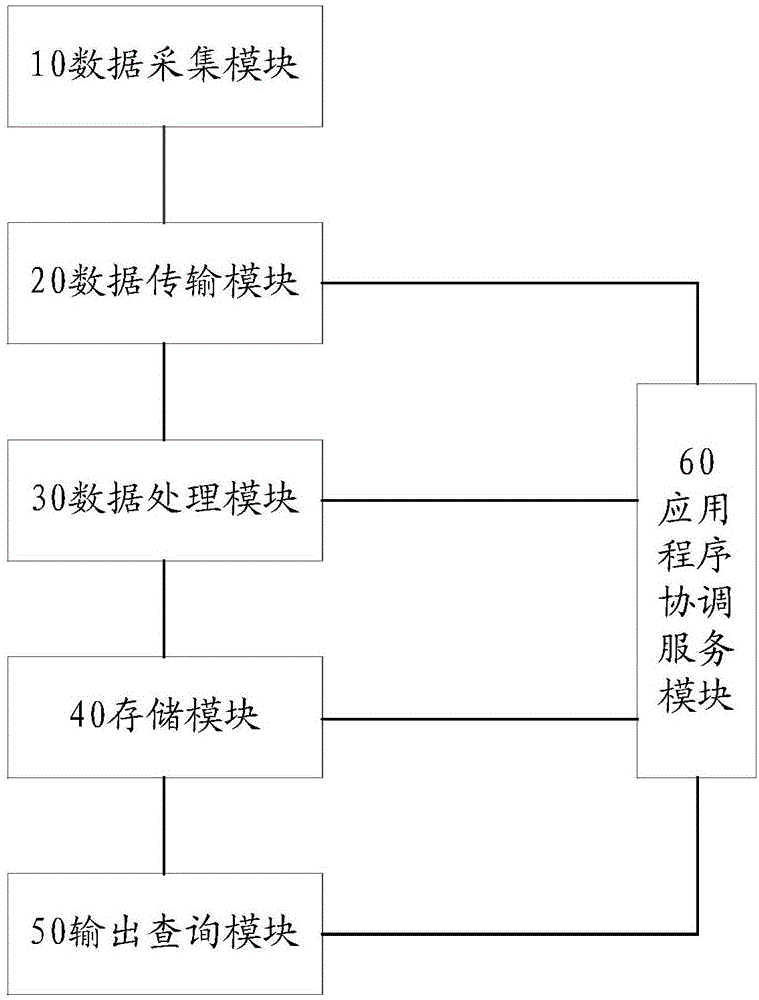
为实现上述目的,本发明采用的一个技术方案为:提供一种通用大数据实时处理开发平台,包括:
数据采集模块,用于从数据库中获取多个异构数据源;
数据传输模块,所述数据传输模块与数据采集模块电连接,用于将多个异构数据源进行发布;
数据处理模块,所述数据处理模块与数据传输模块电连接,用于分别对多个异构数据源中的批量数据及流数据进行处理并调用相应的预设数据库,以构建业务应用,其中,所述数据处理模块预设有应用数据库;
存储模块,所述存储模块与数据处理模块电连接,用于对经处理的批量数据及流数据进行存储;
输出查询模块,所述输出查询模块与存储模块电连接,用于对存储的批量数据及流数据进行查询;
应用程序协调服务模块,所述应用程序协调服务模块分别与数据传输模块、数据处理模块、存储模块及输出查询模块电连接,用以监测各模块的处理事件,以在某一处理事件异常时,调用相应的服务来处理对应的数据。
其中,所述数据采集模块采集的数据类型包括mysql、oracle、hdfs、hive、oceanbase、hbase、ots及odps中至少一种,且所述数据采集模块具体为阿里开源datax。
其中,所述数据传输模块采用kafka集群,以将多个异构数据源进行分布式发布。
其中,所述数据处理模块具体为通用实时计算引擎spark集群,以构建多个并行应用并调用对应的应用数据库,并分别对多个异构数据源中的批量数据及流数据进行并行处理。
其中,所述应用数据库包括sql、dataframes、mllib、graphx及spark集群streaming中的至少一种。
其中,所述数据处理模块具体为列式存储器kudu集群,以对经并行处理的批量数据及流数据分别进行存储。
其中,所述输出查询模块具体为分布式查询引擎impala集群,以对存储的批量数据及流数据进行并发查询。
其中,所述应用程序协调服务模块具体为分布式应用程序协调服务zookeeper。
为实现上述目的,本发明采用的另一个技术方案为:提供一种通用大数据实时处理开发平台的数据处理方法,包括:
s10、从数据库中获取多个异构数据源;
s20、将多个异构数据源进行发布;
s30、分别对多个异构数据源中的批量数据及流数据进行处理并调用相应的预设数据库,以构建业务应用;
s40、对经处理的批量数据及流数据进行存储;
s50、对存储的批量数据及流数据进行查询;
s60、监测步骤s20-s50中对异构数据源处理得到的处理事件,以在某一处理事件异常时,调用相应的服务处理对应的数据。
本发明的技术方案主要包括数据采集模块、数据传输模块、数据处理模块、存储模块、输出查询模块以及应用程序服务模块构成通用大数据实时处理开发平台,通过上述模块的配合协作,提供了通用的分布式实时计算分析能力,同时也提供了一系列高可用、高性能、高伸缩性的基础设施,为不同的业务提供了一种通用的开发平台,减少了低效的、重复的共性组件的开发,有利于提高数据处理系统的开发效率,降低开发成本。
附图说明
图1为本发明一实施例通用大数据实时处理开发平台的模块方框图;
图2为本发明通用大数据实时处理开发平台运行环境图;
图3为本发明一实施例通用大数据实时处理开发平台的数据处理方法的方法流程图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
需要说明,本发明中涉及“第一”、“第二”等的描述仅用于描述目的,而不能理解为指示或暗示其相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。另外,各个实施例之间的技术方案可以相互结合,但是必须是以本领域普通技术人员能够实现为基础,当技术方案的结合出现相互矛盾或无法实现时应当认为这种技术方案的结合不存在,也不在本发明要求的保护范围之内。
请参照图1,图1为本发明一实施例通用大数据实时处理开发平台的模块方框图。在本发明实施例中,该通用大数据实时处理开发平台,包括:
数据采集模块10,用于从数据库中获取多个异构数据源;
数据传输模块20,所述数据传输模块20与数据采集模块10电连接,用于将多个异构数据源进行发布;
数据处理模块30,所述数据处理模块30与数据传输模块20电连接,用于分别对多个异构数据源中的批量数据及流数据进行处理并调用相应的预设数据库,以构建业务应用,其中,所述数据处理模块30预设有应用数据库;
存储模块40,所述存储模块40与数据处理模块30电连接,用于对经处理的批量数据及流数据进行存储;
输出查询模块50,所述输出查询模块50与存储模块40电连接,用于对存储的批量数据及流数据进行查询;
应用程序协调服务模块60,所述应用程序协调服务模块60分别与数据传输模块20、数据处理模块30、存储模块40及输出查询模块50电连接,用以监测各模块的处理事件,以在某一处理事件异常时,调用相应的服务来处理对应的数据。
本实施例中,该数据采集模块10可以采集不同数据库中的多个异构数据源,支撑任意异构数据系统离线数据交互。数据传输模块20,可以多个异构数据源进行分布,以传输至数据处理模块30。数据处理模块30可以对多个异构数据源中批量数据及流数据进行处理并通过与用户的交互调用相对应的预设数据库,以构建需要的业务应用;存储模块40,可以对经批量数据及流数据进行存储;输出查询模块50以对存储的批量数据及流数据进行查询;应用程序协调服务模块60,可以协调处理数据传输模块20、数据处理模块30、存储模块40及输出查询模块50,在各模块的某一处理事件异常时,调用相应的服务来处理对应的数据,以保证平台的高可用及一致性服务。
本发明的技术方案主要包括数据采集模块10、数据传输模块20、数据处理模块30、存储模块40、输出查询模块50以及应用程序服务模块构成通用大数据实时处理开发平台,通过上述模块的配合协作,提供了通用的分布式实时计算分析能力,同时也提供了一系列高可用、高性能、高伸缩性的基础设施,为不同的业务提供了一种通用的开发平台,减少了低效的、重复的共性组件的开发,有利于提高数据处理系统的开发效率,降低开发成本。
在一具体的实施方式中,所述数据采集模块10采集的数据类型包括mysql、oracle、hdfs、hive、oceanbase、hbase、ots及odps中至少一种,且所述数据采集模块10具体为阿里开源datax。本实施例中,需要处理的原始数据可以存储于mysql、oracle、hdfs、hive、oceanbase、hbase、ots及odps中至少一种数据库内,通过阿里开源datax进行数据采集,可以实现各种异构数据源之间高效的数据同步,datax采用了框架+插件的模式,可以方便的应对不同数据源的差异,还具有较佳的扩展能力。
在一具体的实施方式中,所述数据传输模块20采用kafka集群,以将多个异构数据源进行分布式发布。kafka集群为分布式流处理平台,具备对消息的发布订阅能力类似消息队列或者企业级消息系统、具备对消息的持久化容错能力以及实时消息处理能力,以将多个异构数据源进行分布式发布。
在一具体的实施方式中,所述数据处理模块30具体为通用实时计算引擎spark集群,以构建多个并行应用并调用对应的应用数据库,并分别对多个异构数据源中的批量数据及流数据进行并行处理。本实施例中,通用实时计算引擎spark集群内置有有向无环图调度器、查询优化器和物理执行引擎,可以实现对批量数据和流数据的高性能处理,还提供了超过80种高阶操作符使得可以通过它方便的构建并行应用也可以通过scala、python、r、sqlshells很方便的进行交互操作。另外,spark集群设有应用数据库,具体包括sql、dataframes、mllib、graphx及spark集群streaming中的至少一种,以方便开发者的使用。
在一具体的实施方式中,所述数据处理模块30具体为列式存储器kudu集群,以对经并行处理的批量数据及流数据分别进行存储。该kudu集群能够提供快速的插入、更新操作和高效的列扫描,其专为在频繁更新的数据上进行分析的场景而设计,显著降低了spark集群及后续impala集群的查询延迟。
在一具体的实施方式中,所述输出查询模块50具体为分布式查询引擎impala集群,以对存储的批量数据及流数据进行并发查询。本实施例中,impala集群提供了低延迟高并发的查询效率,即使在并发环境中也有较佳的线性伸缩能力。进一步的,所述应用程序协调服务模块60具体为分布式应用程序协调服务zookeeper。本实施例中,zookeeper能够保证分布式系统的高可用性和一致性,还能够提供配置维护、域名服务、分布式同步、组服务等功能。
请参照图2,图2为本发明通用大数据实时处理开发平台运行环境图。通用大数据实时处理开发平台中的数据采集模块10应用于数据采集层,数据传输模块20应用于数据传输层,数据处理模块30应用于数据处理层,存储模块40应用于数据存储层,输出查询模块50应用于数据查询层,源数据层可以方便导入开发人员输入的原始数据。
请参照图3,图3为本发明一实施例通用大数据实时处理开发平台的数据处理方法的方法流程图。在本发明的实施例中,该通用大数据实时处理开发平台的数据处理方法,包括:
s10、从数据库中获取多个异构数据源;
s20、将多个异构数据源进行发布;
s30、分别对多个异构数据源中的批量数据及流数据进行处理并调用相应的预设数据库,以构建业务应用;
s40、对经处理的批量数据及流数据进行存储;
s50、对存储的批量数据及流数据进行查询;
s60、监测步骤s20-s50中对异构数据源处理得到的处理事件,以在某一处理事件异常时,调用相应的服务来处理对应的数据。
本实施例中,从数据库中获取的多个异构数据源,以获取需要处理的原始处理,然后将多个异构数据源进行分布,进而对对多个异构数据源中批量数据及流数据进行处理并通过与用户的交互调用相对应的预设数据库,以构建需要的业务应用,而后对经批量数据及流数据进行存储;以及对存储的批量数据及流数据进行查询;在上述步骤s20-s50中还包括监测并协调处理对异构数据源处理得到的处理事件,具体的,在各模块的某一处理事件异常时,调用相应的服务处理对应的数据,以保证平台的高可用及一致性服务。
以上所述仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是在本发明的发明构思下,利用本发明说明书及附图内容所作的等效结构变换,或直接/间接运用在其他相关的技术领域均包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!