一种内分泌干扰物高通量筛选模型及筛选方法与流程
本发明涉及内分泌干扰物的虚拟筛选与活性预测领域,更具体地说,涉及一种内分泌干扰物高通量筛选模型及筛选方法。
背景技术:
人体中含有48个核受体,其中12个核受体是药物发现史上最成功的分子靶点之一,每个核受体都有一个或多个同源的人工合成配体用作药物,这类核受体被称为经典核受体(classicalnuclearreceptor)。经典核受体包括雄激素受体(androgenreceptor,ar)、雌激素受体(estrogenreceptorα/β,erα/β)、糖皮质激素受体(glucocorticoidreceptor,gr)、盐皮质激素受体(mineralocorticoidreceptor,mr)、孕激素受体(progesteronereceptor,pr)、视黄酸受体(retinoicacidreceptorα/β/γ,rarα/β/γ)、甲状腺激素受体(thyroidhormonereceptorα/β,trα/β)和维生素d受体(vitamindreceptor,vdr)。经典核受体是一类依靠天然激素调节的转录因子,天然激素通过配体-受体的竞争结合,进而引起一系列关键事件,最终对内分泌系统产生调节作用。然而,大量研究发现一些人为合成的和天然的化合物,可以模仿或抵抗天然激素,并干扰人类和野生动物正常的内分泌系统,这种化合物被称为内分泌干扰物(endocrinedisruptingchemicals,edcs)。目前,已有许多化合物质被检测出对经典核受体存在明显干扰活性,例如多溴联苯醚、双酚a、菊酯农药等,这些化学物质也受到人们的广泛关注。为了筛查潜在的内分泌干扰物,人们发展了各种有效地体内和体外实验方法,其中包括竞争结合、报告基因、酵母双杂交和荧光偏振等体外试验和小鼠子宫增重体内试验等。然而,一方面,采用这些试验方法费时费力。而且还相当昂贵;另一方面,环境中存在成千上万的化学物质,很难逐一筛查。
针对内分泌干扰物的筛查,现有技术也给出了一些解决方案,例如发明创造名称:一种人运甲状腺素蛋白干扰物虚拟筛选方法(专利公开号:cn106407665a,公开日:2017-02-15),该方案公开了一种人运甲状腺素蛋白干扰物的虚拟筛选方法,属于环境内分泌干扰物筛选方法领域。其虚拟筛选过程是首先基于十个基团将化学品进行分类,然后使用定量结构-活性关系模型预测每类化学品对人运甲状腺素蛋白的干扰效应,进而根据预测的效应值判断化学品是否具有干扰人运甲状腺素蛋白转运甲状腺素的能力及干扰能力的强弱。该方案公布的筛选人运甲状腺素蛋白干扰物的流程简明合理,可适用于应用域内潜在人运甲状腺素蛋白干扰物的虚拟筛查及潜在干扰物优先级设定。但是,该方案的不足之处在于:该方案虽然通量高,但适用范围狭窄,且无法有效地给出机制上的解释。
还有发明创造名称:基于分子动力学模拟的核受体介导内分泌干扰物质的虚拟筛选方法(专利公开号:cn103324861a,公开日:2013-09-25),该方案公开了一种基于分子动力学模拟的核受体介导内分泌干扰物质的虚拟筛选方法,属于环境可疑内分泌干扰物的虚拟筛选与活性预测领域。该方案是将受试小分子经过优化后和实验或者同源模建获得的受体文件进行对接组成复合物,然后用gromacs软件包进行分子动力学模拟。对受体的12号螺旋进行运动轨迹分析,空间位置的均方根偏差分析随时间的变化曲线来鉴别具有受体活性的污染物质,在规定时间内,曲线趋于稳定的可以认为对应的螺旋定位到确定的位置,于是具有生物活性。然后再通过考察定位的位置来判断拟性还是抗性。但是,该方案不足之处在于:虽然从机制上研究了配体-受体之间的作用关系,但耗时常,面对目前已有cas号的一亿余个化学物质,无法提供有效地高通量筛查手段。
结构警示子来源于结构-效应关系,是一种与特定生物活性相关的、存在机制原理的活性化合物结构片段。将结构警示子与分子启动事件相练习可以从源头移除大量的生物信息复杂性,并给结构特征和有害结局提供更为紧密的联系。除此之外,结构警示子还可以提供对生物化学作用机制上的解析,展现出现在高通量研究各类内分泌干扰物的可行性。结构警示子已被用与关注药理学和药物安全方面的靶标研究,并且已经取得了显著成果,如筛查潜在的肝毒性化合物、线粒体毒性化合物等等。
虽然结构警示子作为一种补充方法已被用于研究内分泌干扰物,但在高通量筛查识别潜在内分泌干扰物方面还存在一个缺口。利用结构警示子来研究配受体结合可以理解干扰活性产生的第一步。因此,结构警示子可以作为一种无偏差方法,将不同来源的内分泌干扰物进行聚类,并将干扰活性与化学结构特征联系起来,给高通量筛查潜在内分泌干扰物提供一个可能。文献检索结果表明,还未发现利用分级警示结构方法构建一种高通量筛查潜在核受体介导的内分泌干扰物的方法报道。因此设计并实施一个筛查潜在的内分泌干扰物的方法是很有必要的。
技术实现要素:
1.发明要解决的技术问题
本发明的目的在于克服现有技术中,不能有效地高通量筛查潜在核受体介导的内分泌干扰物的不足,提供了一种内分泌干扰物高通量筛选模型及筛选方法,可以对潜在核受体介导的内分泌干扰物进行高通量筛查,并且可以判断出核受体介导的内分泌干扰物的受体竞争活性和拟抗活性。
2.技术方案
为达到上述目的,本发明提供的技术方案为:
本发明的一种内分泌干扰物高通量筛选模型,首先针对核受体提取化合物的一级警示结构、二级警示结构以及三级警示结构,然后将一级警示结构、二级警示结构和三级警示结构组成核受体高通量筛选模型;其中,化合物具有竞争结合实验,报告基因实验和细胞毒性实验的三种体外实验数据;一级警示结构的提取:基于pubchemfingerprint分子指纹库,利用子结构频率分析和子结构占比分析提取化合物的一级警示结构;二级警示结构的提取:利用sarpy软件对满足一级警示结构的化合物进行二级警示结构的提取;三级警示结构的提取:利用sarpy软件对同时满足一级警示结构和二级警示结构的化合物进行三级警示结构的提取。
优选地,核受体为雄激素受体、雌激素受体α、雌激素受体β、糖皮质激素受体、盐皮质激素受体、孕激素受体、视黄酸受体α、视黄酸受体β、视黄酸受体γ、甲状腺激素受体α、甲状腺激素受体β和维生素d受体任意一种。
优选地,利用
利用
其中上述的frequencyofafragment:代表子结构频率;percentageofafragment:代表子结构占比;
本发明的一种内分泌干扰物高通量筛选的方法,采用上述的一种内分泌干扰物高通量筛选模型,具体步骤为:
步骤一:结构数据的收集
从公开数据库中选取不存在相关活性数据的目标化合物的化学结构,并且以smiles号表示;
步骤二:确定目标核受体
根据目标化合物需要预测的干扰活性确定目标核受体;
步骤三:一级警示结构的匹配
根据确定的目标核受体选取目标核受体高通量筛选模型,利用padel-descriptor软件的pubchemfingerprints分子指纹库,计算目标化合物的分子指纹,将计算的结果与目标核受体高通量筛选模型的一级警示结构相匹配;
步骤四:二级警示结构的匹配
将满足一级警示结构的目标化合物根据一级警示结构进行分组,再利用sarpy软件将目标化合物与目标核受体高通量筛选模型的二级警示结构相匹配;
步骤五:三级警示结构的匹配
将同时满足一级警示结构和二级警示结构的目标化合物根据二级警示结构进行分组,利用sarpy软件将与目标核受体高通量筛选模型的三级警示结构相匹配。
优选地,步骤四的目标化合物的分组方法为:先将目标核受体高通量筛选模型的一级警示结构进行分组,将含有极性原子和芳香环键的一级警示结构作为type1;将含有芳香键的一级警示结构作为type2;再将含有氧原子的碳链类的一级警示结构作为type3;最后将不存在氧原子和芳香键的任意碳链类的一级警示结构作为type4;type1、type2、type3和type4的优先级依次递减,将目标化合物的一级警示结构与各小组中的一级警示结构进行匹配,而后将目标化合物从匹配成功的的小组中分类至优先级最大的小组。
优选地,步骤五的目标化合物的分组方法为:先将目标核受体高通量筛选模型的二级警示结构进行分组,将只存在于抗性化合物的二级警示结构作为type1-1;再将只存在于拟性化合物的二级警示结构作为type1-2,最后将存在于又拟又抗化合物的二级警示结构作为type1-3;type1-1、type1-2和type1-3的优先级依次递减,将目标化合物的二级警示结构与各小组中的二级警示结构进行匹配,而后将目标化合物从匹配成功的的小组中分类至优先级最大的小组。
优选地,还包括步骤六:配体-受体结合模式分析
通过目标核受体高通量筛选模型选取同时满足一级警示结构、二级警示结构和三级警示结构的目标化合物,而后根据目标化合物的干扰活性从rcsbpdbdatabase中选择模式蛋白受体结晶,利用autodockvina软件进行分子对接,再利用ligplus软件进行配体-受体结合模式分析;
步骤七:结合活性与干扰活性的半定量预测
具有相同警示结构的目标化合物具有相似的配体-受体结合模式和相似的结合活性,当结合活性与干扰活性正相关时,根据目标化合物的一级警示结构、二级警示结构和三级警示结构,将目标化合物进行分组并进行半定量预测目标化合物的结合活性和干扰活性。
优选地,利用公式:
优选地,目标核受体高通量筛选模型为雄激素受体高通量筛选模型、雌激素受体α高通量筛选模型以及糖皮质激素受体高通量筛选模型任意一种。
优选地,目标化合物为有机物。
3.有益效果
采用本发明提供的技术方案,与已有的公知技术相比,具有如下显著效果:
(1)本发明的一种内分泌干扰物高通量筛选模型及筛选方法,通过构建内分泌干扰物高通量筛选模型,而后对目标化合物进行分级警示结构的匹配,从而可以定性判断内分泌干扰物的受体竞争活性和拟抗活性,利用拟性、又拟又抗、抗性三种内分泌干扰机制识别出不同类型的内分泌干扰物所对应的警示结构,成功建立起活性与内在机制间的联系,半定量预测干扰物的结合活性大小和部分干扰物干扰活性的大小。
(2)本发明的一种内分泌干扰物高通量筛选模型及筛选方法,利用分级警示结构的新方法构建了全新的基于警示结构的内分泌干扰物高通量筛查模型,半定量预测干扰物的结合活性和干扰活性的大小,其预测效果比传统qsar模型优良;
(3)本发明的一种内分泌干扰物高通量筛选模型及筛选方法,通过对目标化合物进行配体-受体结合模式分析,可以预测目标化合物与何种氨基酸产生的作用而导致产生了干扰活性,进而可以预测干扰活性的产生机制。
(4)本发明一种内分泌干扰物高通量筛选模型及筛选方法,具有相同警示结构的化合物具有相似的配体-受体结合模式和相似的结合活性,当结合活性与干扰活性正相关时,根据化合物的一级警示结构、二级警示结构和三级警示结构,将化合物进行分组并进行半定量预测化合物的结合活性和干扰活性,定性和半定量的预测结果也更为可靠。
4.附图说明
图1为以雄激素受体为例基于核受体分子启动事件的分级警示结构识别与高通量筛查的流程图;
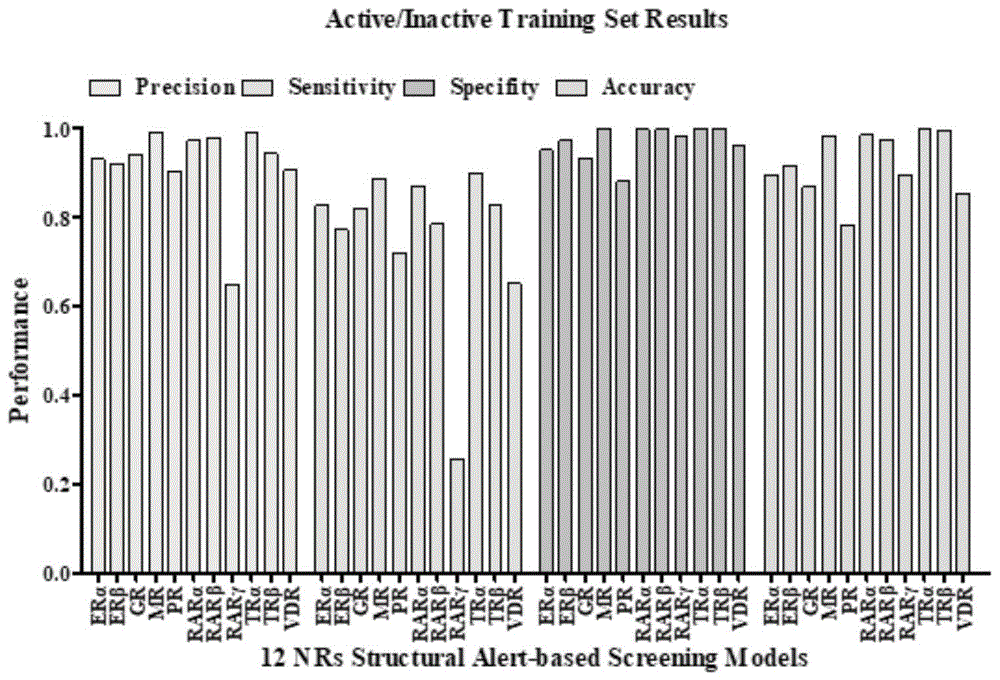
图2为雄激素受体、雌激素受体、糖皮质激素受体、盐皮质激素受体、孕激素受体、视黄酸受体、甲状腺激素受体和维生素d受体对活性/非活性模块的训练集和测试集的预测结果图;
图3为雄激素受体、雌激素受体、糖皮质激素受体、盐皮质激素受体、孕激素受体、视黄酸受体、甲状腺激素受体和维生素d受体对干扰活性模块的训练集和测试集的预测结果图;
图4为雌激素受体α为例基于警示结构分级筛查潜在活性内分泌干扰物的预测流程图;
图5为雌激素受体α的警示结构图;
图6为雄激素受体的警示结构图;
图7为雌激素受体β的警示结构图;
图8为糖皮质激素受体的警示结构图;
图9为孕激素受体的警示结构图;
图10为盐皮质激素受体的警示结构图;
图11为视黄酸受体α的警示结构图;
图12为视黄酸受体β的警示结构图;
图13为视黄酸受体γ的警示结构图;
图14为甲状腺激素受体α的警示结构图;
图15为甲状腺激素受体β的警示结构图;
图16为维生素d受体的警示结构图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例;而且,各个实施例之间不是相对独立的,根据需要可以相互组合,从而达到更优的效果。因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
为进一步了解本发明的内容,结合附图和实施例对本发明作详细描述。
实施例1
结合图1-3所示,其中图1以雄激素受体(androgenreceptor,ar)为例基于核受体分子启动事件的分级警示结构识别与高通量筛查的流程图;图2为雄激素受体(androgenreceptor,ar)、雌激素受体(estrogenreceptorα/β,erα/β)、糖皮质激素受体(glucocorticoidreceptor,gr)、盐皮质激素受体(mineralocorticoidreceptor,mr)、孕激素受体(progesteronereceptor,pr)、视黄酸受体(retinoicacidreceptorα/β/γ,rarα/β/γ)、甲状腺激素受体(thyroidhormonereceptorα/β,trα/β)和维生素d受体(vitamindreceptor,vdr)对活性/非活性(active/inactive)模块的训练集和测试集的预测结果图;图3为雄激素受体(androgenreceptor,ar)、雌激素受体(estrogenreceptorα/β,erα/β)、糖皮质激素受体(glucocorticoidreceptor,gr)、盐皮质激素受体(mineralocorticoidreceptor,mr)、孕激素受体(progesteronereceptor,pr)、视黄酸受体(retinoicacidreceptorα/β/γ,rarα/β/γ)、甲状腺激素受体(thyroidhormonereceptorα/β,trα/β)和维生素d受体(vitamindreceptor,vdr)对干扰活性(agonist/a-anta/antagonist)模块的训练集和测试集的预测结果图。
本实施例的一种内分泌干扰物高通量筛选模型,首先针对核受体提取化合物的一级警示结构、二级警示结构以及三级警示结构,具体地,先从公开数据库(toxcast/tox21、chembl)中具有竞争结合实验,报告基因实验和细胞毒性实验的三种体外实验数据的化合物(如表1所示),并对所得的化合物数据集进行分类,将化合物数据集任意分为训练集和测试集的方法可以是利用knime中的partitioningmode(https://www.knime.com/),在firstpartition中选择relative[%],输入60%~80%的数值,再选择drawrandomly将数据集任意分为训练集和测试集,其中训练集用来提取分级警示结构,进而构建高通量筛选模型,测试集用来进行外部验证。化合物可以分为活性、非活性、拟性、抗性、又拟又抗五类,其中,活性(active):存在竞争结合活性,同时至少存在一种报告基因实验活性,且两种活性数值都必须大于细胞毒性实验数值。如存在cas号为13311-84-7的化合物flutamide,其竞争结合实验活性数值为6.39,存在抗雄报告基因实验活性数值为4.7,其细胞毒性实验数值为4.4,细胞毒性数据同时小于竞争结合活性数值和抗雄报告基因活性数值,证明该化合物为活性化合物;非活性(inactive):既不存在竞争结合活性又不存在报告基因活性(包括拟雄报告基因实验和抗雄报告基因实验)。如存在cas号为100-00-5的化合物1-chloro-4-nitrobenzene,其竞争结合活性数值为0,拟雄报告基因实验活性为0,同时抗雄报告基因实验活性为0,证明该化合物为非活性化合物;而后提取化合物的一级警示结构:根据活性、非活性化合物的定义,将整个数据集分为活性化合物和非活性化合物两部分,然后利用利用子结构频率分析和子结构占比分析提取出一级活性警示结构。具体步骤为:
首先利用padel-descriptor软件中的pubchemfingerprint数据库计算出所有化合物含有的子结构,利用padel-descriptor软件计算子结构的具体方法是在general中的descriptors栏中选择fingerprints,standardize中选择removesalt、detectaromaticity和standardizenitrogroups,再在fingerprints中勾选pubchemfingerpints分子指纹库,进行所有化合物的子结构计算。利用
library(pheatmap)
tot<-read.csv("c:/agonist.csv",row.names=1)
pheatmap(tot,cluster_cols=false,border_color=na,fontsize_row=3)
上述的frequencyofafragment:代表子结构频率;percentageofafragment:代表子结构占比;
表1
而后对化合物进行二级警示结构(secondarystructuralalert)的提取:
首先,基于一级警示结构的结构特征,将含有一级警示结构的活性/非活性化合物进行分类(组间化合物无交叉);将化合物分类的具体方法为:以芳香环键为重要结构特征,以极性原子(如氧原子、氮原子)为次等重要结构特征,于是将含有极性原子和芳香环键的一级警示结构作为type1(第一大类),再将只含有极性原子(如氧原子、氮原子)而不存在芳香环键作为type2(第二大类),最终将任意碳链作为type3(第三大类)。根据所含的一级警示结构将化合物分为三类,每一类中不存在交集;
然后,针对每一组化合物,利用sarpy软件提取特征警示结构。对特征警示结构进行人为的验证和筛除无关小碎片集,剩下的关键警示结构即为二级警示结构。同时,若活性化合物个数与非活性化合物个数之间存在显著性偏差,无法提取有效的警示结构,则利用相关物理化学性质对活性/非活性化合物进行区分。具体是:对每一类的化合物分别进行特征二级警示结构的识别的方法是:将训练街的活性化合物活性设定为1,非活性化合物的活性设定为0,将其名称、结构smiles号和设定的活性数值形成csv文件,导入sarpy软件(http://sarpy.sourceforge.net/),在getadataset模块中,选取相应smilescolumn和activityattribution后,setnumericthreshold设定为0,在selectthedesiredsplitting(thresholdbelongsto“low”or“high”class)中选取low<=0<high,勾选binarize(optional)为activity>0为active,activity<=0为inactive,loading数据集。在getaruleset模块中,selectthetargetactivityclass中选取active,同时其他参数设定分别为:customizesinglealertprecision(auto:max),highspecificity(minimizefalsepositive),点击extractandvalidate,提取二级警示结构;
最终,二级警示结构以smartsstrings来表示。物理化学性质计算的具体方法是:利用padel-descriptor软件,在general中的descriptors栏中选择1d&2d和3d,standardize中选择removesalt、detectaromaticity和standardizenitrogroups,再在1d&2d中全选,3d中全选,进行化合物的物化性质计算。
步骤(6)三级警示结构(tertiarystructuralalert)的提取:基于一级警示结构和二级警示结构的筛查,区分出了活性化合物和非活性化合物,进而基于满足二级警示结构的活性化合物来提取三级警示结构,预测活性化合物的干扰活性。首先,将每一小组中的活性化合物依据其体外实验活性结果分为拟性、又拟又抗、抗性三类,再依据相应二级警示结构进行分析,对不同干扰活性化合物存在显著性区分的二级警示结构定义为三级警示结构,对不同干扰活性化合物不存在显著性区分的二级警示结构及其相关化合物利用sarpy软件进一步进行三级警示结构的提取。最终,拟性/又拟又抗/抗性三类三级警示结构以smartsstrings来表示。值得说明的是,拟性(agonist)指的是在已定义的活性化合物中,存在拟性报告基因实验活性,却没有抗性报告基因实验活性,即拟性报告基因实验活性>0且>细胞毒性,抗性报告基因实验活性=0或≤细胞毒性,则化合物为拟性干扰物;
又拟又抗(a-anta)指的是在已定义的活性化合物中,既存在拟性报告基因实验活性,又存在抗性报告基因实验活性,即拟性报告基因实验活性>0且>细胞毒性,抗性报告基因实验活性>0且>细胞毒性,则化合物为又拟又抗干扰物;
抗性(antagonist)指的是在已定义的活性化合物中,不存在拟性报告基因实验活性,却存在抗性报告基因实验活性,即拟性报告基因实验活性=0或≤细胞毒性,抗性报告基因实验活性>细胞毒性,则化合物为抗性干扰物。
值得说明的是:显著性区分是指在统计学意义上某一个警示结构基本上只存在于某一种活性(拟性(agonist)、抗性(antagonist)或又拟又抗(a-anta))的化合物中,则将这个警示结构作为这种活性化合物的特征警示结构。比如只有拟性化合物具有警示结构a,其他两种干扰活性的化合物不具有警示结构a,则把这个警示结构a作为拟性化合物的特征警示结构。其中,显著区差异的判定方法为:利用one-wayanova(andnonparametric)统计学算法进行分析,当计算出的p值小于0.05,即认为在统计学上具有显著性差异。
其中选取三级警示结构数据集和相关三级警示结构提取的方法是:将训练集中满足一级警示结构及其相关二级警示结构的活性化合物作为新的训练集来提取三级警示结构。首先,将每个小组内的活性化合物根据其干扰活性分为三类(拟性干扰物、抗性干扰物、又拟又抗干扰物),然后再将活性化合物的名称、smiles号、活性数值(统一设定为1)构建csv文件导入sarpy软件,在getaruleset模块中的loadruleset中,以text文件格式导入二级警示结构smarts信息和taget(active)信息,在predictandvalidate模块中,点击predict和validate,再savepredictions,得到活性化合物所含二级警示结构信息。再将预测结果中的active设定为1,none设定为0,利用r语言中的pheatmap算法,将其聚类分析。
library(pheatmap)
tot<-read.csv("c:/agonist.csv",row.names=1)
pheatmap(tot,cluster_cols=false,border_color=na,fontsize_row=3)
根据热图分析,首先将唯一存在于某一种干扰活性条件下的特征二级警示结构设定为相关三级警示结构,同时对干扰化合物进行高通量筛查(tier1),然后对于特征二级警示结构无法区分的活性化合物利用sarpy软件,采用与前步骤相同的参数设定,进行相关特征三级警示结构的提取(tier2)。通过tier1和tier2两步,核受体介导内分泌干扰物的三级警示结构提取完毕。
然后将提取的一级警示结构、二级警示结构和三级警示结构组成核受体高通量筛选模型;需要说明的是,核受体只能为雄激素受体、雌激素受体α、雌激素受体β、糖皮质激素受体、盐皮质激素受体、孕激素受体、视黄酸受体α、视黄酸受体β、视黄酸受体γ、甲状腺激素受体α、甲状腺激素受体β和维生素d受体(如表2所示)。
表2
本实施例的一种内分泌干扰物高通量筛选的方法,采用上述的内分泌干扰物高通量筛选模型对目标化合物进行筛选,具体步骤如下,
步骤一:结构数据的收集
从公开数据库中选取不存在相关活性数据的目标化合物的化学结构,并且以smiles号表示;具体地,首先从公开数据库中查找选取不存在相关活性数据的目标化合物的化学结构,公开数据库包括chembl、pubchem、chemicalbook和chemspider等。目标化合物的化学结构以smiles号表示,再将目标化合物的smiles号导入chembiodrawultra14.0软件进行检查,若目标化合物的结构没有错误,则该目标化合物可以用来进行干扰活性预测。值得说明的是,目标化合物为有机物,不可以为混合物、重金属等化合物,因为高通量筛选模型只支持有机物的干扰活性预测。
步骤二:确定目标核受体
根据目标化合物需要预测的干扰活性确定目标核受体;即根据需要预测的干扰活性,选择合适的目标核受体,其中,目标核受体只能为雄激素受体(androgenreceptor,ar)、雌激素受体(estrogenreceptorα/β,erα/β)、糖皮质激素受体(glucocorticoidreceptor,gr)、盐皮质激素受体(mineralocorticoidreceptor,mr)、孕激素受体(progesteronereceptor,pr)、视黄酸受体(retinoicacidreceptorα/β/γ,rarα/β/γ)、甲状腺激素受体(thyroidhormonereceptorα/β,trα/β)和维生素d受体(vitamindreceptor,vdr)。
步骤三:一级警示结构的匹配
根据确定的目标核受体选取目标核受体高通量筛选模型,利用padel-descriptor软件的pubchemfingerprints分子指纹库,计算目标化合物的分子指纹,将计算的结果与目标核受体高通量筛选模型的一级警示结构相匹配;具体地,首先根据确定的目标核受体选取对应的目标核受体高通量筛选模型,目标核受体高通量筛选模型的一级警示结构都以smartsstrings来表示,用来和目标化合物的化学结构进行匹配。以雌激素受体alpha为例,当目标核受体为雌激素受体alpha(estrogenreceptorα,erα)时,存在18个一级警示结构,都以smartsstrings来表示(eg.c-c:c-o-[#1])。将目标化合物的smile号导入padel-descriptor软件中,在general中的descriptors栏中选择fingerprints,standardize中选择removesalt、detectaromaticity和standardizenitrogroups,再在fingerprints中勾选pubchemfingerpints分子指纹库,进行目标化合物的pubchemfingerprints子结构的计算。将得到的目标化合物的分子指纹与目标化合物的一级警示结构库相比对,当目标化合物至少满足一个一级警示结构时,判定该目标化合物具有潜在干扰目标核受体调节的内分泌调节过程,判定目标化合物为活性化合物。反之,当目标化合物不满足任意一个一级警示结构时,判定目标化合物为非活性化合物。
步骤四:二级警示结构的匹配
将满足一级警示结构的目标化合物根据一级警示结构进行分组,再利用sarpy软件将目标化合物与目标核受体高通量筛选模型的二级警示结构相匹配;具体地,先将目标核受体高通量筛选模型的一级警示结构进行分组,将含有极性原子和芳香环键的一级警示结构作为type1;将含有芳香键的一级警示结构作为type2;再将含有氧原子的碳链类的一级警示结构作为type3;最后将不存在氧原子和芳香键的任意碳链类的一级警示结构作为type4;type1、type2、type3和type4的优先级依次递减,将目标化合物的一级警示结构与各小组中的一级警示结构进行匹配,而后将目标化合物从匹配成功的的小组中分类至优先级最大的小组。为进一步说明,以激素受体alpha(estrogenreceptorα,erα)为例,将其18个一级警示结构分成既有氧原子又有芳香键的警示结构(type1),存在芳香键的警示结构(type2),存在氧原子的碳链类(type3)和不存在氧原子和芳香键的任意碳链类(type4)共四类。并按照优先级依次递减的方式将化合物分成独立的三大组,各组之间不存在交集。如目标化合物存在type1、type2、type3和type4四类一级警示结构,依据优先级递减规则,目标化合物被分类到type1小组,进行后续type1小组内特异二级警示结构的匹配。
而后再利用sarpy软件将目标化合物与目标核受体高通量筛选模型的二级警示结构相匹配,即对分组的目标化合物进行组内特异二级警示结构的匹配,为详细的说明,以雌激素受体alpha(estrogenreceptorα,erα)的type1小组为例,当目标化合物被分类于该组,则需与相应的27个二级警示结构相匹配(都以smartsstrings来表示,eg.cccc(c)c1ccccc1)。匹配方法为将目标化合物的活性设定为1,将其名称、结构smiles号和设定的活性数值形成csv文件,导入sarpy软件,在getadataset模块中,选取相应smilescolumn和activityattribution后,setnumericthreshold设定为0,在selectthedesiredsplitting(thresholdbelongsto“low”or“high”class)中选取low<=0<high,勾选binarize(optional)为activity>0为active,activity<=0为inactive,loading数据集。在getaruleset模块中的loadruleset中,以text文件格式导入该27个二级警示结构的smartsstrings信息和taget(active)信息,在predictandvalidate模块中,点击predict和validate,再savepredictions,得到目标化合物是否满足二级警示结构的结果及其相关二级警示结构信息。
步骤五:三级警示结构的匹配
将同时满足一级警示结构和二级警示结构的目标化合物根据二级警示结构进行分组,利用sarpy软件将与目标核受体高通量筛选模型的三级警示结构相匹配。具体地,先将目标核受体高通量筛选模型的一级警示结构进行分组,将含有极性原子和芳香环键的一级警示结构作为type1;将含有芳香键的一级警示结构作为type2;再将含有氧原子的碳链类的一级警示结构作为type3;最后将不存在氧原子和芳香键的任意碳链类的一级警示结构作为type4;type1、type2、type3和type4的优先级依次递减,将目标化合物的一级警示结构与各小组中的一级警示结构进行匹配,而后将目标化合物从匹配成功的的小组中分类至优先级最大的小组。
如目标化合物存在type1-1、type1-2和type1-3三类二级警示结构,依据优先级递减规则,化合物被分类到type1-1小组,进行后续type1-1小组内特异三级警示结构的匹配,即利用sarpy软件将与目标核受体高通量筛选模型的三级警示结构相匹配。需要说明的是,拟性(agonist)指的是干扰物存在拟性干扰而不存在抗性干扰;又拟又抗(a-anta)指的是干扰物既存在拟性干扰又存在抗性干扰;抗性(antagonist)指的是干扰物不存在拟性干扰而存在抗性干扰;
进一步说明小组内特异三级警示结构的匹配,以雌激素受体alpha(estrogenreceptorα,erα)的type1-1小组为例,当目标化合物被二级分类到type1-1小组后,由于type1-1的二级警示结构只有抗性活性干扰物拥有,即目标化合物满足至少一个type1-1中的任意一个警示结构后,认定该目标化合物的干扰类型属于抗性,不再需要进行三级干扰警示结构进行匹配。以type1-3小组为例,组内存在5个二级警示结构,当目标不满足type1-1、type1-2的二级警示结构,却至少满足type1-3的5个二级警示结构之一时,认定目标化合物属于活性化合物,并归于type1-3类活性化合物,进而判定目标化合物是否满足type1-3-1内的4个警示结构之一。当目标化合物至少满足4个警示结构之一时,认定目标化合物为a-anta类活性干扰物,否则属于拟性类活性干扰物。匹配方法为将目标化合物的活性设定为1,将其名称、结构smiles号和设定的活性数值形成csv文件,导入sarpy软件(http://sarpy.sourceforge.net/),在getadataset模块中,选取相应smilescolumn和activityattribution后,setnumericthreshold设定为0,在selectthedesiredsplitting(thresholdbelongsto“low”or“high”class)中选取low<=0<high,勾选binarize(optional)为activity>0为active,activity<=0为inactive,loading数据集。在getaruleset模块中的loadruleset中,以text文件格式导入type1-3-1的4个三级警示结构的smartsstrings信息和taget(a-anta)信息,在predictandvalidate模块中,点击predict和validate,再savepredictions,得到目标化合物是否满足三级警示结构的结果及其相关干扰活性类别信息。
通过构建内分泌干扰物高通量筛选模型,而后对目标化合物进行分级警示结构的匹配,从而可以定性判断内分泌干扰物的受体竞争活性和拟抗活性,利用拟性、又拟又抗、抗性三种内分泌干扰机制识别出不同类型的内分泌干扰物所对应的警示结构,成功建立起活性与内在机制间的联系,半定量预测干扰物的结合活性大小和部分干扰物干扰活性的大小。
步骤六:配体-受体结合模式分析
通过目标核受体高通量筛选模型选取同时满足一级警示结构、二级警示结构和三级警示结构的目标化合物,而后根据目标化合物的干扰活性从rcsbpdbdatabase中选择模式蛋白受体结晶,利用autodockvina软件进行分子对接,再利用ligplus软件进行配体-受体结合模式分析。具体地,配体-受体结合模式预测是依据干扰活性类别分为拟性配体-受体结合模式,又拟又抗配体-受体结合模式,和抗性配体-受体结合模式。结合模式由两方面构成:目标化合物与目标核受体口袋的关键极性氨基酸形成的氢键作用、目标化合物与目标核受体口袋的关键非极性氨基酸之间产生的疏水性作用。为进一步说明,以雌激素受体alpha(estrogenreceptorα,erα)的type1-1小组为例,当目标化合物满足三级警示结构(特征二级结构)oc1ccc2c(n(ccc2c1))时,干扰活性为抗性,预测出的配体-受体结合模式为arg394&his524(与arg394和his524两个极性氨基酸产生氢键作用)。即被分到type1-1的化合物,具有相同的一级、二级、三级警示结构,存在相似的以arg394&his524为主的配体-受体结合模式。
需要说明的是,配体-受体结合模式分析只适用于雄激素受体(androgenreceptor,ar)、雌激素受体alpha(estrogenreceptorα,erα)和糖皮质激素受体(glucocorticoidreceptor,gr)三个核受体,即目标核受体高通量筛选模型只能为雄激素受体高通量筛选模型、雌激素受体α高通量筛选模型以及糖皮质激素受体高通量筛选模型。且该配体-受体结合模式分析都是针对第一口袋,与第二口袋和其他口袋没有关系。第一口袋(ligandbondingdomain,lbd指的是人类核受体与天然激素相结合的结合位点,这个口袋也是绝大多数环境污染物进入,并且干扰天然激素与核受体结合的部位,但是近年来,也有研究者发现,很多污染物可以不进入这个结合位点,在核受体其他的空腔里面也能与受体相结合,导致了受体进行了变构,进而影响了异常地转录上调或者下调,最终造成了内分泌的紊乱。本发明针对第一结合位点进行研究,进一步能够预测化合物与何种氨基酸产生的作用而导致产生了干扰活性,进而可以预测干扰活性的产生机制。
步骤七:结合活性与干扰活性的半定量预测
具有相同警示结构的目标化合物具有相似的配体-受体结合模式和相似的结合活性,当结合活性与干扰活性正相关时,根据化合物的一级警示结构、二级警示结构和三级警示结构,将目标化合物进行分组并进行半定量预测化合物的结合活性和干扰活性。值得说明的是,利用公式:
因此,依据目标化合物已有的一级、二级、三级警示结构,将化合物聚类于特定小组内,即可半定量预测化合物的结合活性和干扰活性;当结合活性与干扰活性不存在正相关关系时,即证明除了配体-受体竞争结合以外,共调解因子招募过程也是决定化合物干扰活性的关键步骤,对于这类化合物,预测结果会给出警告信息。为进一步说明,以雌激素受体alpha(estrogenreceptorα,erα)的type1-1小组为例,当化合物满足三级警示结构oc1ccc2c(n(ccc2c1)时,干扰活性为抗性,其结合活性强度为强,导致的拟抗性干扰活性也为强。
结合步骤六和步骤七,具有相同警示结构的化合物具有相似的配体-受体结合模式和相似的结合活性,当结合活性与干扰活性正相关时,根据化合物的一级警示结构、二级警示结构和三级警示结构,将化合物进行分组并进行半定量预测化合物的结合活性和干扰活性,定性和半定量的预测结果也更为可靠。
实施例2
本实施例基本内容同实施例1,其不同之处在于:结合图5-16所示(12种核受体的警示结构),本发明的一种内分泌干扰物高通量筛选模型及筛选方法,本实施例采用的目标核受体为人类的雌激素受体alpha(estrogenreceptorα,erα),具体步过程如下:
结构数据的收集:依据步骤一的化合物为有机物的类型限定,选取cas号为55-56-1的化合物chlorhexidine作为目标化合物进行干扰活性的预测。从chembl数据库和pubchem数据库中搜索到的smiles号为:
clc1=cc=c(nc(=n)nc(=n)nccccccnc(=n)nc(=n)nc2=cc=c(cl)c=c2)c=c1。并将smiles号导入chembiodrawultra14.0软件进行检查,发现结构正确,可进行后续干扰活性预测。
目标核受体的确定:依据步骤二的目标核受体限制在12种人类经典核受体,并选择对应的核受体高通量筛选模型,本实施例选择雌激素受体alpha(estrogenreceptorα,erα)作为靶点核受体进行内分泌干扰活性的预测。
一级警示结构的匹配:依据步骤三,雌激素受体alpha(estrogenreceptorα,erα)存在18个一级警示结构(如图5所示)。
将目标化合物chlorhexidine的smile号导入padel-descriptor软件中,在general中的descriptors栏中选择fingerprints,standardize中选择removesalt、detectaromaticity和standardizenitrogroups,再在fingerprints中勾选pubchemfingerpints分子指纹库,进行化合物的pubchemfingerprints子结构的计算。将得到的目标化合物的分子指纹与目标核受体的一级警示结构相比对,发现化合物能满足雌激素受体erα高通量筛选模型中的7个一级警示结构(c:c-c-c,c:c-c:c,c:c-c=c,c-c:c:c-c,c=c-c=c,[#1]-c=c-[#1],c=c-c-c-c)。
二级警示结构的匹配:依据步骤四,将雌激素受体alpha(estrogenreceptorα,erα)的18个一级警示结构分成既有氧原子又有芳香键的警示结构(type1),存在芳香键的警示结构(type2),存在氧原子的碳链类(type3)和不存在氧原子和芳香键的任意碳链类(type4)共四类。并按照优先级依次递减的方式将化合物分成独立的三大组,各组之间不存在交集。化合物满足的7个一级警示结构中4个属于type2(c:c-c-c,c:c-c:c,c:c-c=c,c-c:c:c-c),3个属于type4(c=c-c=c,[#1]-c=c-[#1],c=c-c-c-c),则将化合物分类为type2,并进行二级警示结构的匹配。雌激素受体alpha(estrogenreceptorα,erα)的type2中存在7个二级警示结构(如图5所示)。将目标化合物chlorhexidine的活性设定为1,将其名称、结构smiles号和设定的活性数值形成csv文件,导入sarpy软件(http://sarpy.sourceforge.net/),在getadataset模块中,选取相应smilescolumn和activityattribution后,setnumericthreshold设定为0,在selectthedesiredsplitting(thresholdbelongsto“low”or“high”class)中选取low<=0<high,勾选binarize(optional)为activity>0为active,activity<=0为inactive,loading数据集。在getaruleset模块中的loadruleset中,以text文件格式导入该7个二级警示结构的smartsstrings信息和taget(active)信息,在predictandvalidate模块中,点击predict和validate,再savepredictions,发现化合物满足一个二级警示结构(cnc(=n)nccc),即确认该目标化合物是潜在干扰erα核受体介导内分泌调节系统的干扰物(预测为:active)。
三级警示结构的匹配:依据步骤五,雌激素受体alpha(estrogenreceptorα,erα)的type2中存在拟性、抗性和又拟又抗三类干扰类别。拟性、抗性和又拟又抗三类干扰类别分别存在各自的三级警示结构。将目标化合物chlorhexidine的活性设定为1,将其名称、结构smiles号和设定的活性数值形成csv文件,导入sarpy软件(http://sarpy.sourceforge.net/),在getadataset模块中,选取相应smilescolumn和activityattribution后,setnumericthreshold设定为0,在selectthedesiredsplitting(thresholdbelongsto“low”or“high”class)中选取low<=0<high,勾选binarize(optional)为activity>0为active,activity<=0为inactive,loading数据集。在getaruleset模块中的loadruleset中,以text文件格式导入agonist,a-anta,antagonist三类干扰类别分别存在各自的三级警示结构的smartsstrings信息和taget(agonist,a-anta,antagonist)信息,在predictandvalidate模块中,点击predict和validate,再savepredictions,发现化合物不存在任何三级警示结构,根据erα干扰活性的筛查流程(图4,图4以雌激素受体α为例基于警示结构分级筛查潜在活性内分泌干扰物的预测流程),即确认该目标化合物的潜在干扰活性是抗性(antagonist),即存在对erα有抗性干扰作用。
配体-受体结合模式的预测:依据步骤六,基于目标化合物chlorhexidine的一级、二级、三级警示结构,可以判定该化合物与erα存在的配体-受体结合模式为抗性构造,并且结合模式主要为his524&thr347,化合物与his524、thr347两个急性氨基酸存在氢键作用。
结合活性与干扰活性的预测:依据步骤七,具有相同警示结构的化合物具有相似的配体-受体结合模式,进而导致相似的结合活性,当结合活性与干扰活性正相关时,导致相似的干扰活性,绝大部分化合物的结合活性与干扰活性具有正相关关系。因此,依据目标化合物chlorhexidin已有的一级、二级、三级警示结构,预测其结合活性强度为中,干扰活性为中。
通过构建内分泌干扰物高通量筛选模型,并通过模型进行内分泌干扰物的筛选,不仅定性预测出了目标化合物对目标核受体是否存在干扰活性和干扰活性类别,还基于具有相同警示结构的化合物存在相似的结合模式,半定量预测出了目标化合物的竞争结合活性强度和干扰活性强度。
在上文中结合具体的示例性实施例详细描述了本发明。但是,应当理解,可在不脱离由所附权利要求限定的本发明的范围的情况下进行各种修改和变型。详细的描述和附图应仅被认为是说明性的,而不是限制性的,如果存在任何这样的修改和变型,那么它们都将落入在此描述的本发明的范围内。此外,背景技术旨在为了说明本技术的研发现状和意义,并不旨在限制本发明或本申请和本发明的应用领域。
- 还没有人留言评论。精彩留言会获得点赞!