一种文字识别训练系统及方法与流程
本发明涉及一种文字识别技术,特别是涉及中文文字识别训练方法。
背景技术:
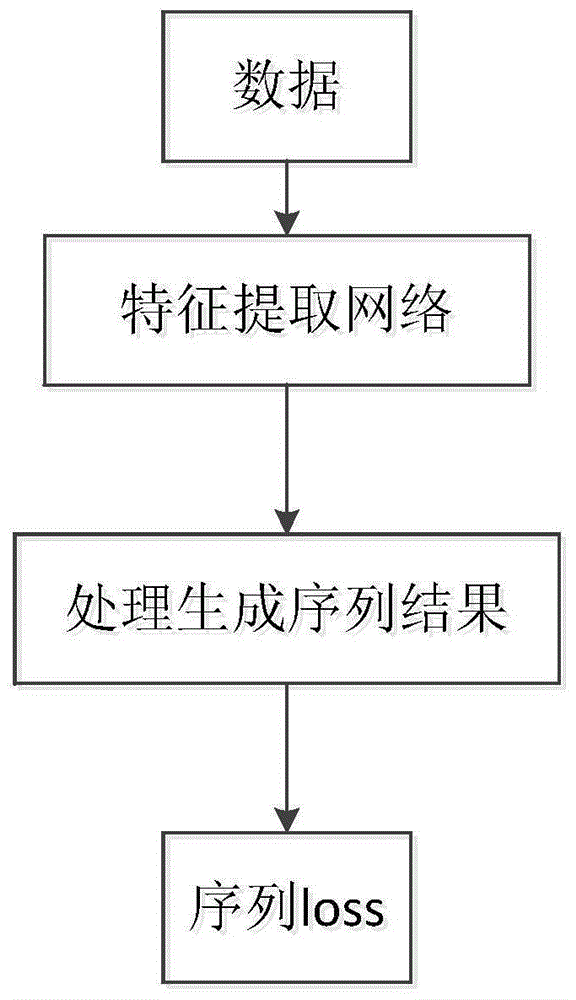
现今基于深度学习的文字识别训练结构大都如图1所示,首先由卷积神经网络等特征提取模型提取图片特征,之后使用循环神经网络或者自然语言处理等方法生成文字序列结果,采用序列模型的损失函数进行对齐和计算损失。训练过程中,通过序列损失函数间接调整特征提取模型,使之能提取出最具表达能力的特征。这在英文的文字识别模型中得到了很好的结果。但是中文的文字识别比英文文字识别在任务的复杂度上有明显的区别,首先是巨大的字符数量差异,英文只需识别26个字母,但是中文仅常用字库就有三四千的数目;并且,很多中文文字形状相似但意义大不相同,这也给准确识别带来了难度,例如对于像“莱”、“菜”这种形似的字符,容易产生混淆。观察发现,多数文字识别错误的原因是检错文字类别。特别是在自动驾驶、辅助驾驶领域,文字的正确识别是实现自动或辅助驾驶的重要环节。亟待需要一种用于自动驾驶、辅助驾驶的文字识别方法和系统。
技术实现要素:
现有技术中对于文字的识别较少采用神经网络进行训练,更没有对已有神经网络进行优化。鉴于现有技术中存在的问题,本发明提供一种文字识别训练系统,其特征在于
特征提取单元、文字识别单元和损失函数单元;
所述特征提取单元对待识别文字的图片或图像进行特征提取;
所述文字识别单元将输入的所述特征进行文字识别得到识别结果;
所述系统还包括:通过待识别文字的图片或图像的预先标注,与所述识别结果进行对比,并构建损失函数,并存储于损失函数单元,由所述损失函数单元中的所述损失函数逐级反向传导,逐级修正所述文字识别单元和所述特征提取单元;
所述损失函数由两种不同类型的损失函数之和构成。
优选地,所述两种不同类型的损失函数分别为序列损失函数和分类损失函数。
优选地,所述分类损失函数表达字形相同的文字出现识别错误的概率。
优选地,所述系统的损失函数=a*序列损失函数+b*分类损失函数,其中a、b为权重系数。
优选地,所述文字识别单元包括第一文字识别单元和第二文字识别单元,其分别对应列损失函数和分类损失函数。
优选地,所述系统还包括映射单元,其通过词典或字典的映射来预测所述识别结果。
优选地,所述系统还包括预处理单元,其用于对样本集进行标注以及对所有中文文字进行分类。
本发明还提供了一种利用上述系统进行文字识别的训练方法,其特征在于:所述方法包括以下步骤:
特征提取步骤:对待识别文字的图片或图像进行特征提取;
文字识别步骤:输入的所述特征进行文字识别得到识别结果;
修正步骤:所述系统通过待识别文字的图片或图像的预先标注,与所述识别结果进行对比,并构建所述损失函数,最后由所述损失函数逐级反向传导,逐级修正所述文字识别单元和所述特征提取单元;
所述损失函数由两种不同类型的损失函数之和构成。
优选地,所述特征提取单元为卷积神经网络,所述文字识别单元为循环神经网络。
优选地,所述两种不同类型的损失函数分别为序列损失函数和分类损失函数。
本发明的发明点包括但不限于以下几点:
(1)本发明提出了以分类损失函数来修正神经网络;很多中文文字形状相似但意义大不相同,这也给准确识别带来了难度,观察发现,多数文字识别错误的原因是检错文字类别,分类损失函数有效的解决了中文文字形状相似但意义大不相同的这类字的识别。
(2)本发明提出了损失函数由序列损失函数和分类损失函数之和来表达;通过设置不同情况下,两者之间的权重,可解决文字识别中顺序错误的问题和检错文字的问题;采用序列损失函数和分类损失函数之和来表达损失函数,并且用于文字识别上,在现有技术中未曾出现。
(3)本发明还可同时使用两个文字识别单元,即两个循环神经网络,两者可分别有针对性的工作,提高工作效率,其中使用的损失函数和分类函数是专门针对文字识别处理而提供的,实践表明对文字识别有很好的效果。
附图说明
图1是传统方法中基于深度学习的文字识别训练结构;
图2是本发明中基于深度学习的文字识别训练结构;
图3是实施例1的文字识别训练结构;
图4是实施例2的文字识别训练结构。
具体实施方式
下面结合附图并通过具体实施方式来进一步说明本发明的技术方案。
为更好地说明本发明,便于理解本发明的技术方案,本发明的典型但非限制性的实施例如下:
本发明提供了一种基于深度学习的文字识别训练方法,首先确定待识别文字的图片或图像,通过卷积神经网络(convolutiongalneuralnetwork,cnn)对输入的图像或图片进行特征提取,然后将提取的特征输入到循环神经网络(recurrentneuralnetwork,rnn)中,然后由循环神经网络输出识别结果,再通过待识别文字的图片或图像的标注,即具体文字的内容,与识别结果进行对比,并构建损失函数,最后由损失函数逐级反向传导,依此逐级修正神经网络来实现训练的目的。
实施例1
本发明的文字识别训练系统如图3所示,包括预处理单元、特征提取单元、文字识别单元、损失函数和映射单元;其中特征提取单元具体为卷积神经网络cnn,文字识别单元具体为循环神经网络rnn。
预处理单元需要(1)为训练样本集,即包括文字内容的图片,进行标注,这里的标注具体指标识出具体的文字;(2)训练集中每张图片对文字库中文字类别的标注,图片中包含的文字类别标注不为0,图片中不包含的文字类别标注为0。具体如下:
若图片包含文字为“前方道路直行”,则“前”“方”“道”“路”“直”“行”每个汉字对应一个类别,而再字库中,每个汉字都有自己对应的编码,例如:
“前”对应编码0001
“方”对应编码0002
“道”对应编码0003
“路”对应编码0004
“直”对应编码0005
“行”对应编码0006
而字库中其他的没有文字的类别,例如空白或者标点符合等标注为0。
通过汉字与编码的一一对应,以此作为分类损失函数,实现了准确的纠错。
这种分类方式可同样适用于语音识别技术,其方式与文字识别技术相类似,都是通过卷积神经网络进行特征提取,再由循环神经网络进行分类,最后再由损失函数进行修正,最后完成训练,区别在于特征的不同,一个是图片或图像的特征,另一个是音频的特征。
特征提取单元通过构建卷积神经网络cnn来实现,卷积神经网络首先通过卷积核对相片或图像进行初步的特征提取,初步提取的特征可包括部分文字,可以是一个也可以是多个;然后由卷积神经网络中的二次提取层或多次提取层逐级对上一级别提取的特征再次进行特征提取,得到需要的精准特征,去除了冗余特征;最后由卷积神经网络的全连接层将由同一图片或图像特征提取形成的所有子图像串联起来组成完整的提取特征集。
文字识别单元通过构建循环神经网络rnn来实现,循环神经网络rnn的输入包括两种种数据,第一类数据为卷积神经网络cnn提取的特征数据,第二类数据为上一时候循环神经网络rnn的输出数据,最后循环神经网络rnn输出文字识别结果;为了确保文字识别的准确性通常需要考虑文字的通常用法,因此,在以上的基础上,循环神经网络rnn的输入还可包括第三类数据,即上一时候循环神经网络rnn对该时候的预测结果,该第三类数据可通过词典或字典的映射得到。
经过卷积神经网络cnn和循环神经网络rnn得到图片或图像的识别结果,然后和图片或图像预先的标注进行对比,当对比结果有差异时,再将数据进行反向传播,在反向传播过程中,逐渐修正各神经网络;重复上述过程直至识别结果的正确率或误差率达到设定的阈值。
以上识别结果与预先标注的对比通过损失函数来体现,而根据以往的经验对比的误差主要为两类,一类为顺序误差,一类为类别误差;
对于顺序误差可通过序列损失函数间接调整特征提取模型,使之能提取出最具表达能力的特征;具体序列损失函数如下:
其中x={ii,li}i表示训练集样本,ii为训练图片,li为训练图片对应的标注序列,yi为模型输入训练图片ii得到的输出序列。损失函数的目的是最小化生成序列与标注序列的条件概率的负对数似然。
序列损失函数在英文的文字识别模型中得到了很好的结果,但是中文的文字识别比英文文字识别在任务的复杂度上有明显的区别,首先是巨大的字符数量差异,英文只需识别26个字母,但是中文仅常用字库就有三四千的数目,所以类别误差不能忽视,对于类别误差,本发明提供了分类损失函数,针对一张训练集图片,具体分类函数如下:
其中m为字库中总的类别个数,ti为第i类文字的标注,即当前图片是否包含第i类文字,若包含则为1,反之,为0。pi为模型对第i类文字类别的预测概率。
本发明总的损失函数为序列损失函数+分类损失函数,由此可以很好的解决中文识别中的顺序误差和类别误差。
实施例2
本发明的文字识别训练系统如图4所示,包括预处理单元、特征提取单元、文字识别单元1、损失函数1、文字识别单元2、损失函数2和映射单元;其中特征提取单元具体为卷积神经网络cnn,文字识别单元具体为循环神经网络rnn。
预处理单元需要(1)为训练样本集,即包括文字内容的图片,进行标注,这里的标注具体指标识出具体的文字,并保证顺序;(2)训练集中每张图片对文字库中类别的标注,图片中包含该类文字类别则标注不为0,图片中不包含的文字类别标注为0,具体分类如下:
若图片包含文字为“前方道路直行”,则“前”“方”“道”“路”“直”“行”每个汉字对应一个类别,而再字库中,每个汉字都有自己对应的编码,例如:
“前”对应编码0001
“方”对应编码0002
“道”对应编码0003
“路”对应编码0004
“直”对应编码0005
“行”对应编码0006
而字库中其他的没有文字的类别,例如空白或者标点符合等标注为0。
通过汉字与编码的一一对应,以此作为分类损失函数,实现了准确的纠错。
然后通过特征提取单元对输入的图像或图片进行特征提取,将提取的特征同时分别输入到文字识别单元1和文字识别单元2中,然后由文字识别单元1和文字识别单元2输出识别结果;再通过待识别文字的图片或图像的标注,即具体文字的内容,与识别结果进行对比,并构建损失函数,最后由损失函数逐级反向传导,依此逐级修正神经网络来实现训练的目的。
以上损失函数为a序列损失函数+b分类损失函数,其中a、b为权重系数,且a+b=1。
这里文字识别单元1和文字识别单元2即第一循环神经网路和第二循环神经网络可侧重不同方向,连接分类损失函数的第二循环神经网络可专门识别特定类型的文字,如字形相同的文字(类别1),而连接序列损失函数的第一循环神经网络可侧重于识别文字的序列。
在该实施例中,特征提取单元是共用的,除此之外还可公用文字识别单元(图中未出示出),然后文字识别单元将结果同时分别输出到损失函数1和损失函数2。
以上详细描述了本发明的优选实施方式,但是,本发明并不限于上述实施方式中的具体细节,在本发明的技术构思范围内,可以对本发明的技术方案进行多种简单变型,这些简单变型均属于本发明的保护范围。
另外需要说明的是,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合,为了避免不必要的重复,本发明对各种可能的组合方式不再另行说明。
此外,本发明的各种不同的实施方式之间也可以进行任意组合,只要其不违背本发明的思想,其同样应当视为本发明所公开的内容。
- 还没有人留言评论。精彩留言会获得点赞!