一种基于自然语言处理技术的政策分析系统及方法与流程
本发明涉及数据处理技术领域,特别涉及一种基于自然语言处理技术的政策分析系统及方法。
背景技术:
现有的政策分析系统,一般侧重数据采集与结构化统计分析,利用多源的数据多样性的汇聚与分析,为政策分析提供技术支持与辅助。
但是现有的政策分析系统不能实现非结构化的数据分析,系统需依靠较好的数据规范与标准完成数据的采集,对于数据价值比较低的数据分析能力不足,无法实现互联网上政策资讯类离散数据的数据价值挖掘分析与使用。
针对国家及各级政府的政策类信息,本发明提出了一种基于自然语言处理技术的政策分析系统及方法。
技术实现要素:
本发明为了弥补现有技术的缺陷,提供了一种简单高效的基于自然语言处理技术的政策分析系统及方法。
本发明是通过如下技术方案实现的:
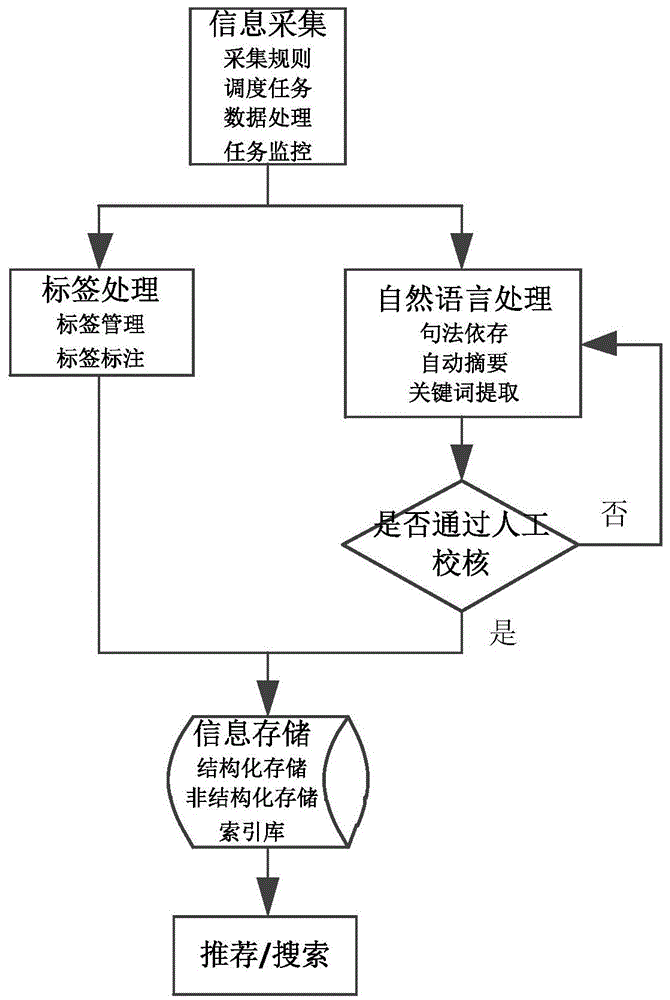
一种基于自然语言处理技术的政策分析系统,其特征在于:包括信息采集模块,信息处理模块,信息存储模块和推荐与搜索模块,所述信息采集模块通过信息处理模块连接到信息存储模块,所述推荐与搜索模块与信息存储模块相连;所述信息处理模块包括标签处理单元,自然语言处理单元和校核单元,所述标签处理单元和自然语言处理单元分别与信息采集模块相连,所述自然语言处理单元通过校核单元连接到信息存储模块,所述标签处理单元直接连接到信息存储模块,所述信息存储模块包括结构化存储单元,非结构化存储单元和索引库单元。
本发明基于自然语言处理技术的政策分析系统的分析方法,其特征在于,包括以下步骤:
(1)信息采集模块采集互联网政策信息,对采集到的信息进行分类管理,并将采集到的信息发送到信息处理模块;
(2)信息处理模块的标签处理单元接收到信息后,根据预设的领域和学科预设标签,实现各类政策信息的标签处理及映射,然后将标签标注及其与各类政策信息的映射关系发送到信息存储模块保存备用;
(3)信息处理模块的自然语言处理单元接收到信息后,利用自然语言技术对各类政策精要信息进行计算和提取,然后将计算和提取结果发送到信息存储模块保存备用;
(4)推荐与搜索模块通过各类政策信息的标签标注,关联信息结合用户的特征信息,实现政策信息的推荐功能;通过提取的各类政策信息的精要信息及分词技术实现对各类政策信息的搜索功能;用户通过推荐与搜索模块输入搜索关键词,推荐与搜索模块根据搜索关键词从信息存储模块中搜索并读取相关信息,实现政策信息的快速分类阅读,同时根据用户输入的搜索关键词推荐相关关键词信息和政策信息,供用户进行延伸阅读。
所述步骤(1)中,对互联网政策信息进行采集配置和分类管理,包括分类管理采集信息,配置信息采集规则,配置管理采集任务以及监控配置采集任务。
所述步骤(1)具体包括以下步骤:
(a)通过分类管理对采集的信息进行分组,方便政策信息的管理;
(b)通过可视化的流程配置信息采集规则,并对信息采集规则效验调整;
(c)对采集任务进行调度管理,包括对采集任务进行编辑,删除及启停操作;
(d)对采集任务进行监控,监控内容包括采集任务的运行状态,采集到的结果数据及预警通知。
所述步骤(2)中,标签处理单元利用预设的标签标注信息,对采集入库的各类政策数据的进行实体标注,属性标注,事件标注和关联关系标注,并将标注的数据关联关系存储到信息存储模块,以实现各类政策数据的标签处理及映射。
所述步骤(3)中,通过校核单元人工定义关键摘要词汇,对关键摘要词汇进行管理,并将定义的关键摘要词汇信息与基本语料库相结合,利用自然语言技术完成关键词提取,然后将关键词发送到信息存储模块保存备用。
所述步骤(3)中,自然语言处理单元用于利用自然语言技术对采集到的各类政策精要信息进行计算和提取,以句法依存分析技术为基础提取关键词并自动生成摘要,然后将关键词和摘要发送到信息存储模块保存备用。
所述句法依存分析技术基于tfidf(termfrequency–inversedocumentfrequency,信息检索数据挖掘的常用加权技术)算法模型,统计政策信息中词语的频率并提取高频信息,进而生成关键词。
所述句法依存分析技术基于textrank构建拓图模型,对信息进行分析,并提取出简洁、精炼的信息,进而生成自动摘要。
本发明的有益效果是:该基于自然语言处理技术的政策分析系统及方法,以自然语言处理技术为核心,通过配置人工参与定义关键摘要词汇,逐步提高数据分析精度,实现了各政策类离散数据的摘要分析,利用一系列的互联网数据采集功能、领域及标签处理功能、自然语言处理功能及人工标签校核功能,构建半自动化的政策分析系统,有效实现了各类离散格式数据的挖掘分析与处理,提高了政策信息的价值阅读与精准获取。
附图说明
附图1为本发明实基于自然语言处理技术的政策分析系统的分析方法示意图。
具体实施方式
为了使本发明所要解决的技术问题、技术方案及有益效果更加清楚明白,以下结合附图和实施例,对本发明进行详细的说明。应当说明的是,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
该基于自然语言处理技术的政策分析系统,包括信息采集模块,信息处理模块,信息存储模块和推荐与搜索模块,所述信息采集模块通过信息处理模块连接到信息存储模块,所述推荐与搜索模块与信息存储模块相连;所述信息处理模块包括标签处理单元,自然语言处理单元和校核单元,所述标签处理单元和自然语言处理单元分别与信息采集模块相连,所述自然语言处理单元通过校核单元连接到信息存储模块,所述标签处理单元直接连接到信息存储模块,所述信息存储模块包括结构化存储单元,非结构化存储单元和索引库单元。
本发明基于自然语言处理技术的政策分析系统的分析方法,其特征在于,包括以下步骤:
(1)信息采集模块采集互联网政策信息,对采集到的信息进行分类管理,并将采集到的信息发送到信息处理模块;
(2)信息处理模块的标签处理单元接收到信息后,根据预设的领域和学科预设标签,实现各类政策信息的标签处理及映射,然后将标签标注及其与各类政策信息的映射关系发送到信息存储模块保存备用;
(3)信息处理模块的自然语言处理单元接收到信息后,利用自然语言技术对各类政策精要信息进行计算和提取,然后将计算和提取结果发送到信息存储模块保存备用;
(4)推荐与搜索模块通过各类政策信息的标签标注,关联信息结合用户的特征信息,实现政策信息的推荐功能;通过提取的各类政策信息的精要信息及分词技术实现对各类政策信息的搜索功能;用户通过推荐与搜索模块输入搜索关键词,推荐与搜索模块根据搜索关键词从信息存储模块中搜索并读取相关信息,实现政策信息的快速分类阅读,同时根据用户输入的搜索关键词推荐相关关键词信息和政策信息,供用户进行延伸阅读。
所述步骤(1)中,对互联网政策信息进行采集配置和分类管理,包括分类管理采集信息,配置信息采集规则,配置管理采集任务以及监控配置采集任务。
所述步骤(1)具体包括以下步骤:
(a)通过分类管理对采集的信息进行分组,方便政策信息的管理;
(b)通过可视化的流程配置信息采集规则,并对信息采集规则效验调整;
(c)对采集任务进行调度管理,包括对采集任务进行编辑,删除及启停操作;
(d)对采集任务进行监控,监控内容包括采集任务的运行状态,采集到的结果数据及预警通知。
所述步骤(2)中,标签处理单元利用预设的标签标注信息,对采集入库的各类政策数据的进行实体标注,属性标注,事件标注和关联关系标注,并将标注的数据关联关系存储到信息存储模块,以实现各类政策数据的标签处理及映射。
所述步骤(3)中,通过校核单元人工定义关键摘要词汇,对关键摘要词汇进行管理,并将定义的关键摘要词汇信息与基本语料库相结合,利用自然语言技术完成关键词提取,然后将关键词发送到信息存储模块保存备用。
所述步骤(3)中,自然语言处理单元用于利用自然语言技术对采集到的各类政策精要信息进行计算和提取,以句法依存分析技术为基础提取关键词并自动生成摘要,然后将关键词和摘要发送到信息存储模块保存备用。
所述句法依存分析技术基于tfidf(termfrequency–inversedocumentfrequency,信息检索数据挖掘的常用加权技术)算法模型,统计政策信息中词语的频率并提取高频信息,进而生成关键词。
所述句法依存分析技术基于textrank构建拓图模型,对信息进行分析,并提取出简洁、精炼的信息,进而生成自动摘要。
该基于自然语言处理技术的政策分析系统及方法,是一种以自然语言处理技术为核心的数据分析与挖掘方法,通过配置人工参与定义关键摘要词汇,逐步提高数据分析精度,实现了互联网离散数据格式的分析挖掘,尤其是针对国家及各级政府的政策类信息,实现了高效的分析处理,提高了政策信息的价值阅读与精准获取。
- 还没有人留言评论。精彩留言会获得点赞!