基于Apriori的社保业务关联规则挖掘和推荐装置及方法与流程
本发明涉及计算机应用技术领域,具体涉及一种基于apriori的社保业务关联规则挖掘和推荐装置及方法。
背景技术:
目前的社保业务经办、社保服务还是一种被动式的业务办理、被动式的服务模式,这种陈旧的服务模式成为制约服务水平提升的难点、痛点。缺乏精准感知个体需求和服务体验的能力,没有准确掌握个体的行为特征和业务状态,无法为服务对象提供更具个性化的主动服务。同时社保领域沉淀积累了大量的数据,这些数据对于科学决策、有效管理、服务社会来说是一个宝贵的资源,从目前的数据应用情况来说,尚未能够充分利用数据挖掘技术对沉淀积累的数据展开分析利用,没有形成服务诉求的预判能力,业务经办人员业务办理选择多、工作效能低下,造成服务对象排队多、排队长、办事不方便、耗时长等问题。因此如何利用数据挖掘技术和理念为公众提供更为精准化、个性化的服务,成为构建方便快捷、公平普惠、优质高效的人社服务体系的重要内容和必然要求。
因此,需要探索一种新的技术解决上述问题。
技术实现要素:
(一)解决的技术问题
针对现有技术的不足,本发明提供了基于apriori的社保业务关联规则挖掘和推荐装置及方法,解决了参保人员选择多、排队耗时长的问题,通过生成社保业务关联规则实现了预测参保人未来办理的业务。
(二)技术方案
为实现以上目的,本发明通过以下技术方案予以实现:一种基于apriori的社保业务关联规则挖掘与推荐装置,用于预测参保人员的需求,所述的装置包括:
获取模块,用于存储参保人的业务日志信息和个人状态信息;
构建apriori模型模块,通过自连接和基于置信度的剪枝处理得到频繁项集单元,从频繁项集单元中生成满足最小置信度的强关联规则,再将生成的关联规则的集合进行排序,得到apriori模型;
社保业务关联规则模块,用于将获取模块的信息转化成apriori模型的数据形式,并输入到apriori模型中,分析得出个人属性项与业务办理项之间的关联关系,得到社保业务关联规则;
预测模块,基于社保业务关联规则预测出参保人所要办理的业务。
优选的是,所述装置还包括模型优化模块,所述模型优化模块是基于评估指标对apriori模型进行优化。
优选的是,所述获取模块还包括:
日志信息采集单元和状态信息生成单元,所述日志信息采集单元基于自定义的日志信息采集规则,且对相关社保业务系统的日志进行收集并存储到业务日志信息中;
所述状态信息生成单元用于获取个人状态信息,且将业务过程中产生的数据和个人的基础数据映射到标签单元中并存储到个人状态信息中。
优选的是,所述频繁项集单元获取的项集为满足最小支持度阈值的所有项集。
优选的是,所述业务日志信息用于存储参保人的业务属性项信息;所述个人状态信息用于存储个人属性项信息。
优选的是,所述业务日志信息与个人状态信息之间通过个人id进行关联。
基于apriori的社保业务关联规则挖掘与推荐方法,其特征在于:用于实现权利要求1-6所述的基于apriori的社保业务关联规则挖掘与推荐装置,所述方法包括以下步骤:
获取参保人的业务日志信息和个人状态信息;
将业务日志信息和个人状态信息转化成apriori模型中的数据形式,并将数据传输到apriori模型中的频繁项集单元;
通过迭代方法挖掘频繁项集,并在频繁项集中生成满足最小置信度的关联规则;
基于apriori模型评估指标,优化apriori模型,生成社保业务关联规则,并将社保业务关联规则存储于业务规则库中;
当参保人办理业务时,获取并更新参保人的最新的业务状态信息和个人属性信息;
将最新的业务状态信息和个人属性信息传送至业务规则库中,分析得出个人属性项与业务办理项之间的关联规则及其规则的置信度;
将生成的关联规则排序,得到置信度最大的关联规则作为预测规则,并将预测结果推荐给业务员。
优选的是,所述方法还包括,当参保人办理完业务后,将业务信息存储于业务日志信息中。
(三)有益效果
本发明具备以下有益效果:
1、构建基于apriori的社保业务关联规则挖掘和推荐装置及方法,利用数据挖掘技术对多元数据展开分析,全面动态掌握服务对象行为特征规律、业务状态,可以辅助判断参保人员的待遇享受资格;
2、通过生成社保业务关联规则实现了预测参保人未来办理的业务,减少参保人员的排队,提高业务办理人员的工作效率和质量。
附图说明
图1为基于apriori的社保业务关联规则挖掘和推荐装置流程图。
图2为基于apriori的社保业务关联规则挖掘和推荐方法流程图。
图3为获取模块流程图。
图4为构建apriori模型模块流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
apriori算法:是一种最有影响的挖掘布尔关联规则频繁项集的算法;其核心是基于两阶段频集思想的递推算法;该关联规则在分类上属于单维、单层、布尔关联规则。
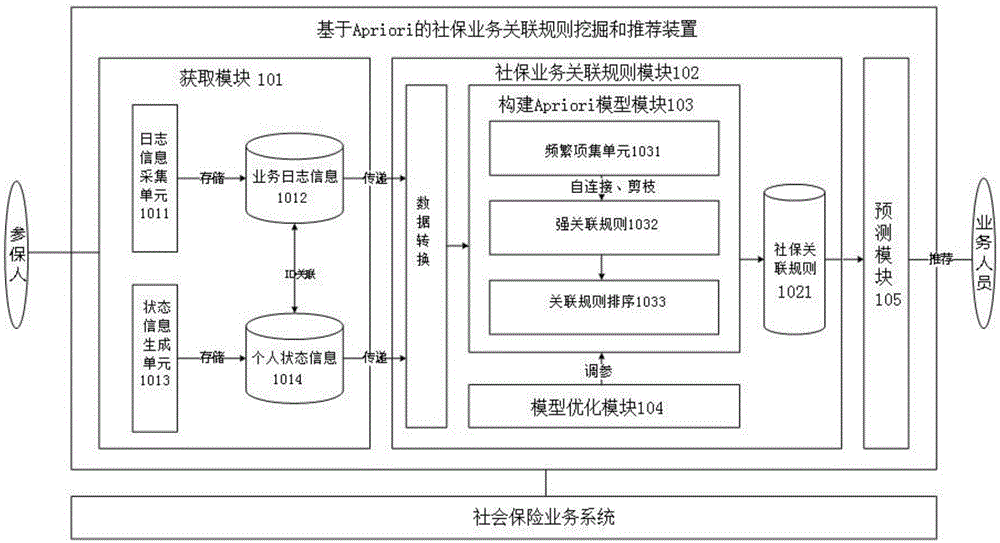
本发明的实施方式一:参见图1、图3和图4,基于apriori的社保业务关联规则挖掘和推荐装置,由获取模块101、构建apriori模型模块103、社保业务关联规则模块102和预测模块104四大部分组成。
获取模块101包括日志信息采集单元1011、业务日志信息1012、状态信息生成单元1013和个人状态信息1014;社保业务关联分析模块102包括数据变换、构建apriori模型模块103、模型优化模块104、社保业务关联规则1021生成;构建apriori模型模块103包括频繁项集生成单元1031、强关联规则生成1032、关联规则排序1033。
获取模块101,用于分析数据的获取,从相关数据源中获取所需要的相关数据作为分析数据;日志信息采集单元1011,用于采集需要的日志信息,基于自定义的日志采集规则对社保业务系统的日志进行收集、过滤、分析,将采集的系统业务日志存储于业务日志信息库中;业务日志信息1012,用于存储参保人业务发生的时间、地点、业务经办人员、业务办理内容等信息,为社保业务关联规则的挖掘提供信息支撑;状态信息生成单元1013,用于获取个人状态信息,用于将业务过程数据、个人基础数据等映射到构建的标签模型中,将经过数据标签化处理后生成的个人状态属性信息存储于个人状态信息库中;个人状态信息1014,用于存储参保人个人属性信息以及养老、医疗、工伤、生育、失业等最新社保业务状态信息,为社保业务关联规则的挖掘提供信息支撑。
社保业务关联规则模块102,用于分析生成社保业务关联规则1021,基于获取的业务日志信息1012、个人状态信息1014,构建基于apriori算法的关联规则分析模型,经过模型分析得出个人属性项与业务办理项之间的关联关系,生成社保业务关联规则1021,存储于社保业务关联规则库中,采用模型评估指标对模型参数不断调整优化,提高模型的精准度;数据变换,用于变换数据的形式,通过平滑聚集,数据概化,规范化等方式将业务日志信息1012、个人状态信息1014等数据转换成apriori算法模型可以处理的数据形式;社保业务关联规则1021,用于存储挖掘生成的社保业务关联规则,为预测分析参保人可能办理的业务及向业务人员进行推荐提供依据。
构建apriori模型模块103,用于构建基于apriori算法的关联规则模型;频繁项集单元1031,用于生成频繁项集,是经过自连接、基于置信度的剪枝处理,产生满足最小支持度阈值的所有项集;强关联规则1032,用于产生强关联规则,从频繁项集合中生成满足最小置信度的关联规则;关联规则排序1033,对生成的关联规则集合进行排序,按照置信度,支持度,集合基数,标签频度依次排序。
模型优化模块104,基于模型评估指标,不断调整参数优化模型,提升关联规则模型的可信度、置信度、提升度。
预测模块105,用于预测推荐参保人可能办理的业务,基于社保业务关联规则库,预测参保人有可能办理的业务并将其预测结果推荐给业务办理人员。
本发明的实施方式二:参见图1-4,基于apriori的社保业务关联规则挖掘和推荐方法,包括以下步骤:
第一步:通过日志信息采集单元1011,按照预定义的日志采集规则采集社保业务系统的业务日志信息1012,存储于业务日志信息1012中,待后续数据挖掘分析建模使用。
第二步:通过状态信息生成单元1013,将业务过程数据、个人基础数据等映射到构建的标签模型中,将经过数据标签化处理后生成的个人状态属性信息存储于个人状态信息1014中,待后续数据挖掘分析建模使用。
第三步:将业务日志信息1012、个人状态信息1014经过数据变换处理转换成apriori算法模型可以处理的数据形式,并将数据传递至apriori算法模型构建模块中的频繁项集单元。
第四步:使用逐层搜索的迭代方法,通过频繁项集单元1031挖掘频繁项集。扫描搜索出候选1项集以及对应的支持度,剪枝去掉低于支持度的候选1项集,得到频繁1项集,该集合记做l1;对剩下的频繁1项集进行自连接,得到候选2项集,筛选去掉低于支持度的候选2项集,得到频繁2项集,该集合记做l2;如此迭代下去,直到不能再找到任何频繁k项集。
第五步:利用强关联规则1032,从频繁项集合中生成满足最小置信度的关联规则。
第六步:利用模型优化模块104,调整参数优化模型,提升关联规则模型的可信度、置信度、提升度。
第七部:将优化后的模型产生的社保业务关联规则存储于社保业务关联规则库模块中,利用关联规则排序1033,对生成的关联规则集合进行排序,按照置信度,支持度,集合基数,标签频度依次排序。
第八步:当参保人办理业务时,获取参保人最新的个人属性状态数据、最新业务状态信息数据,更新个人状态信息1014。
第九步:将最新个人状态信息传送至社保业务关联规则模块102,分析得出个人属性项与业务办理项之间的关联规则及其规则置信度。
第十步:对生成的关联规则集合进行排序,选取置信度最大的关联规则作为预测规则,并将预测结果推荐给业务办理人员,业务预测推荐是通过业务办理预测模块实现。
第十一步:在参保人业务办理完成后将本次的业务办理相关信息存储于业务日志信息1012中。
- 还没有人留言评论。精彩留言会获得点赞!