一种基于FPGA片外存储器的数据调用方法与流程
本发明属于图像分类识别技术领域,尤其涉及一种基于fpga片外存储器的数据调用方法。
背景技术:
近五年来,卷积神经网络在图像特征提取、分类识别等领域取得了很好的效果。由于卷积神经网络架构灵活多变,现在的卷积神经网络主要通过cpu和gpu等软件平台实现。但是,现在的工程应用中,对于系统实时性、低功耗的需求越来越突出,因此利用硬件平台对卷积神经网络的计算进行加速并达到降低系统功耗的目的,日益成为卷积神经网络在工程应用中的研究热点问题。现场可编程门阵列(fpga)就是其中一种很有前途的解决方案。但是,fpga的片上存储资源很难满足卷积神经网络中图像数据、参数以及中间结果的存储,因此在利用fpga加速卷积神经网络的计算时,需要调用fpga片外的存储资源来满足系统的存储需求。因此,研究fpga的片外存储的合理调用问题成为当前研究的重点。
由于fpga片外存储的合理调用,可以使得基于fpga设计的卷积神经网络计算单元,充分发挥卷积神经网络算法中并行计算的特点,最大程度地加速卷积计算,提高系统的吞吐量。因此,fpga片外存储的调用优化问题已成为未来卷积神经网络在fpga上实现加速计算发展的重要研究方向之一。
现有的关于fpga片外存储调用的优化方法中,主要是基于fpga片外存储器的结构进行存储的优化。fpga的片外存储器中数据分bank存储,当前的方法主要的思路是将卷积神经网络中不同的输入特征图数据尽量的存储在fpga片外存储器不同的bank中,但是这样的方法需要频繁地跳址访问片外存储器,读写效率低下,特别是在遇到大规模的卷积神经网络计算时,更加无法满足数据调用的效率要求。
技术实现要素:
为解决上述问题,本发明提供一种基于fpga片外存储器的数据调用方法,没有直接去调用fpga片外存储器的数据,避免了复杂的地址跳变,大大提高了调用fpga片外存储器数据的效率。
一种基于fpga片外存储器的数据调用方法,应用于卷积神经网络,包括以下步骤:
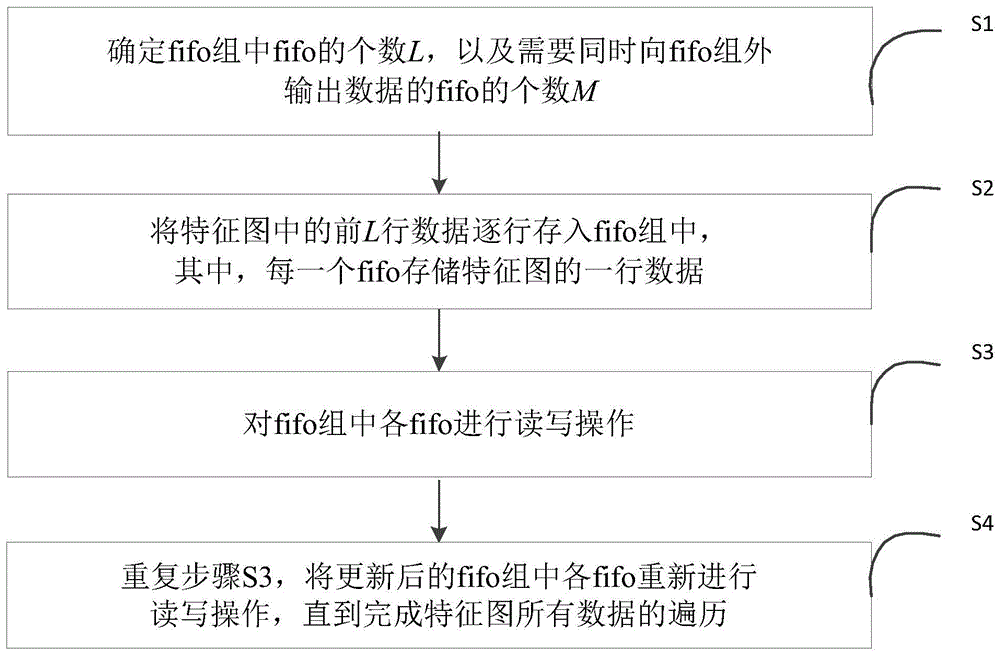
s1:在fpga片内存储器中设置fifo组,其中,fifo组包括l个fifo,然后将各fifo依次编号为1至l,并确定需要同时向fifo组外输出数据的fifo的个数m,具体的:
l=2×kernel+stride×(n-2)
m=kernel+stride×(n-1)
其中,kernel为预设的卷积核大小,stride为卷积计算中所采用的滑窗的步长,n为需要同时生成的滑窗数据的组数,其中,n≥2;
s2:将fpga片外存储器中特征图中的前l行数据逐行存入fifo组中,其中,每一个fifo存储特征图的一行数据,且fifo的深度depth大于特征图的尺寸;
s3:对fifo组中各fifo进行读写操作,其中所述读写操作具体为:
对于从前面数的前m个fifo,每个fifo存储的第一个数据输出fifo组外作为卷积神经网络的滑窗数据,同时第二个数据成为第一个数据;对于倒数的后m个fifo,每个fifo存储的第一个数据写入比其编号小l-m的编号对应的fifo存储的数据尾部,同时,将特征图第l+1行的第一个数据写入第l-1个fifo存储的数据尾部,将特征图第l+2行的第一个数据写入第l个fifo存储的数据尾部,完成fifo组中各fifo的更新;
s4:重复步骤s3,将更新后的fifo组中各fifo重新进行读写操作,直到完成特征图所有数据的遍历。
有益效果:
本发明提供一种基于fpga片外存储器的数据调用方法,将特征图的数据逐行按顺序存储在fifo中,每次读写操作前m个fifo输出当前存储的第一个数据,后m个fifo将当前存储的第一个数据会写到比其编号小l-m的编号对应的fifo存储的数据尾部,同时,将特征图第l+1行的第一个数据写入第l-1个fifo存储的数据尾部,将特征图第l+2行的第一个数据写入第l个fifo存储的数据尾部,这样使得fifo不断将数据按序输出fifo组外时,特征图剩下的数据又按序写入到fifo组中等待读取,直到完成整幅特征图的数据遍历;因此,本发明在fpga片内利用fifo构建fifo组,按照卷积计算所需的数据顺序要求,各fifo将存储于fpga片外存储器的整幅特征图的数据逐一输出到组外的卷积计算单元,则在这个由fpga片外存储器到fpga片内存储器数据调用的过程中,没有直接去调用fpga片外存储器的数据,避免了复杂的地址跳变,大大提高了调用fpga片外存储器数据的效率。
附图说明
图1为本发明提供的一种基于fpga片外存储器的数据调用方法的流程图;
图2为本发明提供的未进行读写操作时,fifo组中各fifo的数据存储示意图;
图3为本发明提供的进行第一次读写操作后,fifo组中各fifo的数据存储示意图;
图4为本发明提供的进行第二次读写操作后,fifo组中各fifo的数据存储示意图;
图5为本发明提供的进行第三次读写操作后,fifo组中各fifo的数据存储示意图。
具体实施方式
为了使本技术领域的人员更好地理解本申请方案,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述。
实施例一
参见图1,该图为本实施例提供的一种基于fpga片外存储器的数据调用方法的流程图。一种基于fpga片外存储器的数据调用方法,应用于卷积神经网络,特别是卷积神经网络计算中采用滑窗的方式对大小为s×s的特征图的进行数据提取的过程,包括以下步骤:
s1:在fpga片内存储器中设置fifo组,其中,fifo组包括l个fifo(firstinputfirstoutput,先入先出队列),然后将各fifo依次编号为1至l,并确定需要同时向fifo组外输出数据的fifo的个数m,具体的:
l=2×kernel+stride×(n-2)(1)
m=kernel+stride×(n-1)(2)
其中,kernel为预设的卷积核大小,stride为卷积计算中所采用的滑窗的步长,n为需要同时生成的滑窗数据的组数,其中,n≥2。
需要说明的是,在计算机中,先入先出队列是一种传统的按序执行方法,先进入的指令先完成并引退,跟着才执行第二条指令。
s2:将fpga片外存储器中特征图中的前l行数据逐行存入fifo组中,其中,每一个fifo存储特征图的一行数据,且fifo的深度depth大于特征图的尺寸s。
s3:对fifo组中各fifo进行读写操作,其中所述读写操作具体为:
对于从前面数的前m个fifo,每个fifo存储的第一个数据输出fifo组外作为卷积神经网络的滑窗数据,对于倒数的后m个fifo,每个fifo存储的第一个数据写入比其编号小l-m的编号对应的fifo存储的数据尾部,同时,将特征图第l+1行的第一个数据写入第l-1个fifo存储的数据尾部,将特征图第l+2行的第一个数据写入第l个fifo存储的数据尾部,完成fifo组中各fifo的更新。
需要说明的是,对于倒数的后m个fifo,每个fifo存储的第一个数据写入比其编号小l-m的编号对应的fifo存储的数据尾部,就是将第l-m+1个fifo中的第一个数据回写入第一个fifo存储的数据尾部,第l-m+2个fifo中的第一个数据回写入第二个fifo存储的数据尾部,依次类推,直到将第l个fifo中的第一个数据回写入第m个fifo存储数据尾部。
需要说明的是,在实际的fpga片内存储器的物理存储中,每个fifo当前存储的第一个数据输出fifo组外后,由于fifo遵循先进先出的存储策略,则各fifo中存储的数据会将自身的存储位置依次向前移动一位,即第二个数据变成第一个数据,第三个数据变成第二个数据,以此类推,直到最后一位空出,才能将倒数的后m个fifo,每个fifo存储的第一个数据写入比其编号小l-m的编号对应的fifo存储的数据尾部,同时,将特征图第l+1行的第一个数据写入第l-1个fifo存储的数据尾部,将特征图第l+2行的第一个数据写入第l个fifo存储的数据尾部。
s4:重复步骤s3,将更新后的fifo组中各fifo重新进行读写操作,直到完成特征图所有数据的遍历。
实施例二
基于以上实施例,本实施例以特征图的尺寸为15×15,卷积核的大小为3×3,特征图卷积计算时滑窗的步长stride为1以及fpga片上卷积计算单元的个数为2个,即需要同时处理的滑窗个数n=2为例,对一种fpga片外存储器调用方法进行详细说明。
步骤一、确定fifo组中fifo的个数l
根据卷积计算中卷积核的大小(kernel)、特征图卷积计算时滑窗的步长(stride)以及fpga片上卷积计算单元的个数(n)这三个参数确定每个fifo组中fifo的个数l,满足以下式子:
l=2×3+2×(2-2)=6
也就是说,fifo组中有6个fifo。
步骤二、确定需要同时向fifo组外输出数据的fifo的个数m
根据假定的情况,卷积核的大小(kernel)为3、特征图卷积计算时滑窗的步长(stride)为1、fpga片上卷积计算单元的个数(n)为2,所以根据这三个参数可以确定每个fifo组需要同时输出m个fifo中的数据,满足以下式子:
m=3+(2-1)×1=4
也就是说,每次fifo读写操作需要同时向fifo组外输出4个fifo的数据。
步骤三、确定fifo的深度
根据式子:depth≥size可以知道,每个fifo的深度可选为16。
步骤四、将特征图中的前6行数据逐行存入fifo组中,其中,每一个fifo存储特征图的一行数据。
参见图2,该图为本实施例提供的未进行读写操作时,fifo组中各fifo的数据存储示意图。其中,fifo组中各fifo的编号从上至下依次为1~6。假定输入的特征图前八行的数据编号分别为1至120,在进行fifo读写操作之前,fifo组中的fifo分别写入输入特征图1至6行的数据,其中,编号为1的fifo写入第一行的数据,编号为2的fifo写入第二行的数据,依次类推,fifo组中各fifo的数据存储情况如图2所示。
参见图3,该图为本实施例提供的进行第一次读写操作后,fifo组中各fifo的数据存储示意图。编号为1至4的4个fifo中存储的第一个数据输出fifo组外,即特征图编号为1,16,31,46的4个数据同时输出fifo组外,存入fpga片上的两个卷积计算单元中;编号为3至6的4个fifo中存储的第一个数据写入比其编号小2的编号对应的fifo存储的数据尾部,其中,编号为3的fifo中存储的第一个数据31写入编号为1的fifo存储的数据尾部,编号为4的fifo中存储的第一个数据46写入编号为2的fifo存储的数据尾部,编号为5的fifo中存储的第一个数据61写入编号为3的fifo存储的数据尾部,编号为6的fifo中存储的第一个数据76写入编号为4的fifo存储的数据尾部;同时,特征图第7行的第一个数据91写入编号为5的fifo存储的数据尾部,特征图第8行的第一个数据106写入编号为6的fifo存储的数据尾部,完成fifo组中各fifo的更新,如图3所示。
参见图4和图5,分别为本实施例提供的进行第二次、第三次读写操作后,fifo组中各fifo的数据存储示意图。其中,fifo组中各fifo存储的数据转移方式与第一次读写操作类似,本实施例对此不作赘述。
由此可见,本实施例提供的一种fpga片外存储器调用方法,将特征图的数据逐行按顺序存储在fifo中,每次读写操作前m个fifo输出当前存储的第一个数据,后m个fifo将当前存储的第一个数据会写到比其编号小l-m的编号对应的fifo存储的数据尾部,同时,将特征图第l+1行的第一个数据写入第l-1个fifo存储的数据尾部,将特征图第l+2行的第一个数据写入第l个fifo存储的数据尾部,这样使得fifo不断按序输出数据fifo组外时,特征图剩下的数据又按序写入到fifo组中等待读取,直到完成整幅特征图的数据遍历;因此,本实施例在fpga片内利用fifo构建fifo组,按照卷积计算所需的数据顺序要求,各fifo将整幅特征图的数据逐一输出到组外的卷积计算单元,其中,卷积计算单元也属于fpga片内存储器,则在这个由fpga片外存储器到fpga片内存储器数据调用的过程中,没有直接去调用fpga片外存储器的数据,避免了复杂的地址跳变,大大提高了调用fpga片外存储器数据的效率。
此外,现有的fpga片外存储器的调用优化方法容易受到卷积计算中输入特征图个数的影响,当输入特征图的个数大于片外存储器的bank数时,也会遇到跳址访问的问题,而本实施例的方法不受输入特征图个数的影响,可以灵活满足不同卷积神经网络结构计算的需要。
再者,现有的fpga片外存储器的调用优化方法,很难满足卷积神经网络计算中需要根据不同卷积核大小、不同特征图滑窗步长以及不同卷积计算单元个数灵活配置卷积计算数据输入的要求,而本实施例的方法可以通过公式(1)和公式(2)确定fifo组中fifo的个数l,以及需要同时向fifo组外输出数据的fifo的个数m,从而调整每个fifo组中fifo的个数,完成灵活的配置。
当然,本发明还可有其他多种实施例,在不背离本发明精神及其实质的情况下,熟悉本领域的技术人员当然可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!