一种MB-kmeans++聚类方法及基于其的用户会话聚类方法与流程
本发明属于数据挖掘
技术领域:
,具体涉及web用户会话聚类处理。
背景技术:
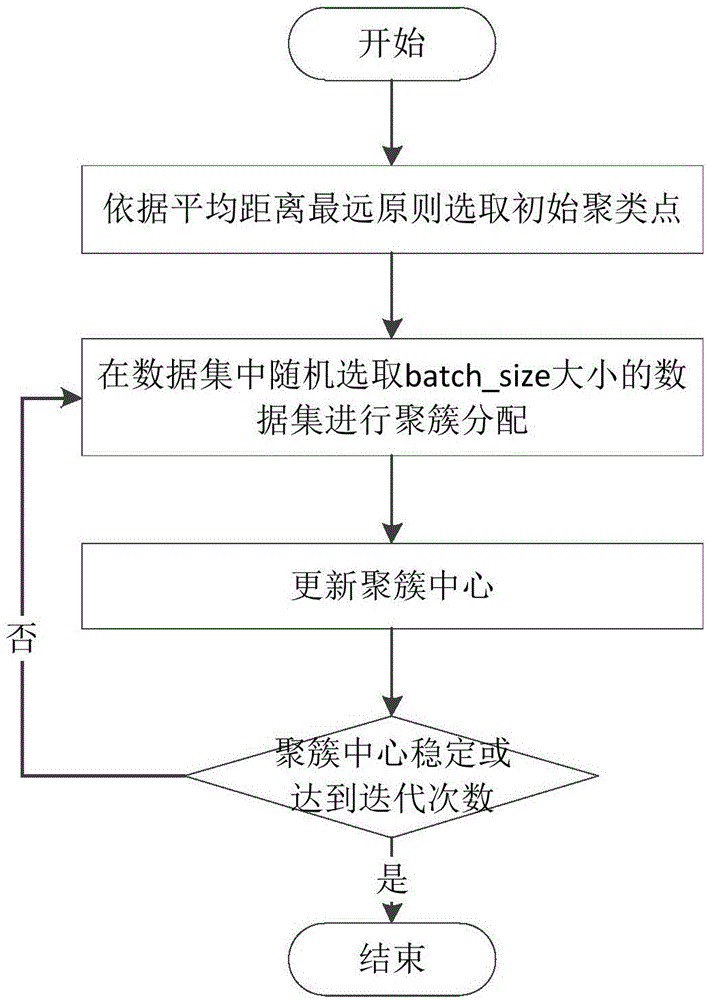
:用户会话聚类主要任务是通过挖掘用户访问记录,发现具有相似网络访问兴趣的用户群体,是用户行为分析的常用手段之一。在挖掘的过程中,需要将有相似网络访问行为的用户划分在一起,也就是说,同一聚簇内的用户会话具有相同的兴趣点,不同聚簇内的用户会话兴趣点差别较大,在得到用户会话聚类后,可以针对不同用户操作习惯进行个性化推荐或网络服务,也可以针对用户网络社交行为进行舆情管理和监控。随着用户访问量的增大,如何快速高效的处理大量快速增长的数据集为日志挖掘算法提出了新的挑战,传统的日志挖掘从研究对象分为两类,第一类是基于ip地址来定位用户,即一个ip对应一个固定的用户,随后对用户进行特征选取,针对浏览行为进行用户聚类。第二类是不区分用户,以所有用户访问过的页面作为研究对象,进行页面聚类。但是上述两种研究方法都有自身的局限性,如当前社区一般情况下采用动态ip分配,同一个ip地址只能在很短时间内标记一个用户,长时间内可能存在多个用户在不同时段对应同一个ip地址的情况,所以这种以ip地址为对象的研究方法需要优化。同时现在大部分社交网站允许用户自主发帖,所以引入了动态页面扩展技术,页网站面数量不再固定,且路径互不相同,这就导致了页面特征的维度大大增加。其次,不管哪种方式,都存在需要对大量数据进行聚类的问题,当前聚类算法通常在聚类时间上存在短板。技术实现要素:本发明的发明目的在于:针对上述存在的问题,提供一种mb-kmeans++数据聚类方法,以及基于其的用户会话聚类方法。对传统k-means++算法进行改进,使其能适应高维度稀疏矩阵的处理,在较大数据量的情况下缩短处理时间。同时本发明以用户会话为基础进行聚类处理改进,并针对庞大的页面维度进行缩减,对用户会话特征有效降维。本发明的mb-kmeans++数据聚类方法,包括下列步骤:步骤1:输入待聚类的样本数据集x,以及确定聚类中心个数k,子集合的分配数量b;步骤2:依据平均距离最远原则选取k个初始聚类中心:步骤201:从样本数据集x中随机采样一个点,作为一个聚类中心,并添加到聚类中心集中,其中聚类中心集的初始值为空集;步骤202:判断聚类中心集的个数是否达到k,若是,则进入步骤3;否则进入步骤203;步骤203:根据距离概率从样本数据集x中选择下一个初始聚类中心并添加到聚类中心集中,再继续执行步骤202;其中,选择下一个初始聚类中心具体为:计算样本数据集x中,每个数据样本xi与聚类中心集中的已知聚类中心的距离,记为d(xi);然后根据公式计算每个样本数据xi(i∈1,…,n)被选择为下一个聚类中心的概率;最后,将最大概率值所对应的样本数据xi作为下一个初始聚类中心;步骤3:从样本数据集x中随机选取b个样本数据,得到子集合m;步骤4:基于当前子集合m更新计算k个聚类中心:步骤401:对子集合m中的每个元素x,从聚类中心集中查找距离x最近的聚类中心,并将查找到的聚类中心定义为元素x的质点p;步骤402:依次遍历子集合m中的每个元素x,基于元素x的质点p所对应的聚类中心c,更新该聚类中心对应的聚簇包含的数据样本数量vc=vc+1;其中vc的初始值为0;再基于元素x更新聚类中心c为:c=(1-η)c+ηx,其中更新学习率当遍历完子集合m中的所有元素后,进入步骤5;步骤5:判断是否达到最大迭代次数,或者最近两次得到的聚类中心是否稳定,若是,则执行步骤6;否则继续执行步骤3;步骤6:基于当前k个聚类中心位置,对样本数据集x进行k聚类处理,输出聚类结果。本发明的mb-kmeans++数据聚类方法适用于大数据量的数据聚类处理,能适应高维度稀疏矩阵的处理,在较大数据量的情况下缩短处理时间。基于本发明的mb-kmeans++数据聚类方法的用户会话聚类方法步骤如下:(1)对原始日志数据进行清洗,过滤无效信息;(2)对步骤(1)处理后的日志数据进行用户识别处理,以及用户会话识别处理,其中用户会话的定义可以描述为:用户通过一次或多次点击而请求的页面的有限集合;基于对用户访问行为的不同定义,常用的用户会话识别模型包括页面类型模型、参引长度模型、最大前向参引模型、时间窗口模型等。本发明中优选,时间窗口模型进行用户会话识别处理。(3)对步骤(2)得到的用户会话进行优化处理:依据url相似度,将相似度超过预设阈值的url作为待合并对象,并对待合并对象进行合并处理,优化url个数;依据web页面路径相似度规则,对相似度超过预设阈值的用户会话进行会话内url合并,优化url维度;(4)建立用户访问偏好加权矩阵:用户访问时间离散化,建立用户时间-url矩阵,其中行为用户,列为url,每个元素为用户i对第j个页面urlj的访问时长离散值;用户访问频度离散化,建立用户频度-url矩阵,其中行为用户,列为url,每个元素为用户i对第j个页面urlj的访问频度离散值;基于用户时间-url矩阵和用户频度-url矩阵建立用户访问偏好加权矩阵,其中行为用户,列为url,元素为用户i对第j个页面urlj的访问时长离散值和访问频度离散值的加权融合(用户访问度量值);(5)根据用户访问偏好加权矩阵,将步骤(3)优化处理后的用户会话表征为:访问页面及其用户访问度量值;并采用本发明的mb-kmeans++数据聚类方法对用户会话进行聚类处理,输出聚类结果。综上所述,由于采用了上述技术方案,本发明的有益效果是:能适应高维度稀疏矩阵的处理,在较大数据量的情况下缩短处理时间。附图说明图1是具体实施方式中,基于mb-kmeans++算法的聚类流程图;图2是具体实施方式中,基于mb-kmeans++算法的用户会话聚类流程图;图3是具体实施方式中,网页层次赋权图示意图;图4是实施例中,iris数据集示意图;图5是实施例中,预处理后的用户会话示意图;图6是实施例中,基于k-means算法的聚类效果图;图7是实施例中,基于k-means++算法的聚类效果图;图8是实施例中,基于mb-kmeans++算法的聚类效果图;图9实施例中,不同ρ值聚类结果对比图。具体实施方式为使本发明的目的、技术方案和优点更加清楚,下面结合实施方式和附图,对本发明作进一步地详细描述。当前,基于web日志数据的用户会话聚类包括用户行为分析,用户热点事件分析等,往往数据量大且难以分类。虽然传统的k-means++算法具有很好的效果,但是还是不能直接适用于服务器日志分析处理。在k-means++算法中,其优化问题是寻找聚类中心集c,其中聚类中心集c中的每个聚类中心(聚簇中心)c∈rm,即c是维度为m的实数,且聚类中心的个数为k,即|c|=k。为了使簇内样本特征相差最小,簇间相差最大,对于数据集x的样本x∈rm,其目标函数为:其中函数f(c,x)表示返回x基于欧式距离的最近的聚类中心c。众所周知,尽管此问题一般是np-hard的,虽然梯度下降法在初始数据集上可以获得局部收敛最优解,但是也伴随着其他问题,例如不适用于高纬度稀疏矩阵的处理,在大数据量时的处理时间长等。因为经典的全样本k-means算法对于大型数据集来说时间复杂度是非常大的。但是在大数据量,且存在噪声的情况下,基于单样本的在线随机梯度下降sgd虽收敛速度较快,但是聚类质量仍然不及基于少量抽样理论进行聚类。本发明根据小批量处理理论,针对k-means++选点之后的样本特征矩阵进行优化。可以在用少量样本的情况下大程度的拟合全数据集样本特征,同时优化目标函数。虽然理论上损失了一定的聚类精度,但是在大量(一万以上)样本的数据集处理上拥有很大速度优势,并且精度与全样本集精度相差很小。为了以示区分,本发明将其改进后的距离算法定义为mb-kmeans++算法,参见图1,基于所输入的样本数据集x(x={x1,...,xn}),以及确定聚类中心个数k,子集合的分配数量batch_size,迭代次数上限t,其具体处理过程为:步骤s1:依据平均距离最远原则选取k个初始聚类中心:s101:从样本数据集x中随机一个样本数据,作为第一个初始聚类中心,并添加到聚类中心集c中,其中c的初始值为空集;同时更新vc=0;其中vc表示每个聚类中心c所对应的聚簇包括的数据样本数量;s102:判断|c|是否小于k,若是,则进入步骤s103;否则执行步骤s2;其中k为预设值;s103:根据距离概率从样本数据集x中选择下一个初始聚类中心:计算样本数据集x中,每个数据样本与已知聚类中心的距离,记为d(xi);然后根据公式计算每个样本数据xi(i∈1,…,n)被选择下一个聚类中心的概率;最后,将最大概率值所对应的样本数据xi作为下一个初始聚类中心,并将其添加到聚类中心集c中,即更新c=c∪{xi};然后继续执行步骤02。在计算距离d(xi)时,例如用s1表示随机选择的第一个初始聚类中心,每个数据样本与已知聚类中心的距离为:而对于已知前面两个初始聚类中心s1和s2,则每个数据样本与已知聚类中心的距离为:即数据样本xi分别与各已知聚类中心的距离的最小值。步骤s2:在数据中随机选取子集合m,即基于预设的子集合的大小b(b=batch_size),在数据中随机选取该大小的数据集进行聚簇分配;步骤s3:基于当前子集合m,更新k个聚类中心的位置:s301:对子集合m中的每个元素x,从聚类中心集c中查找距离x最近的聚类中心,并将查找到的聚类中心定义为元素x的质点p,即根据函数f(c,x)获取元素x的质点p并保存;s302:依次遍历子集合m中的每个元素x,基于元素x的质点p所对应的聚类中心c,更新该聚类中心对应的vc为:vc=vc+1;再根据公式c=(1-η)c+ηx更新聚类中心c;其中更新学习率即每遍历一个元素x,则对对应的聚类中心的位置进行迭代更新,当遍历完子集合m中的所有元素后,进入步骤s4;步骤s4:判断是否达到最大迭代次数,或者最近两次得到的聚类中心是否稳定(各距离偏差均不超过预设阈值),若是,则对聚类中心的迭代更新结束,进行步骤s5;否则继续执行步骤s2。步骤6:基于当前k个聚类中心({c1,...,ck}),对样本数据集x进行k聚类处理,输出聚类结果。参见图2,基于本发明的mb-kmeans++算法的web用户会话聚类具体为:在进行用户会话聚类之前,需要进行一定的预处理工作,即首先需要进行用户会话识别,识别之后的用户会话向量表示形式也非常重要,需要能明确的体现出用户访问兴趣,并且可以易于特征融合分析。然后根据用户会话向量的表示形式,采用本发明的mb-kmeans++聚类算法以准确的进行用户会话聚类。web用户聚类具体步骤:(1)对原始日志数据进行清洗,过滤无效信息;主要涉及下述三个方面:(1)服务器响应路径的扩展名。用户访问行为通常由用户对网站发起请求开始,随着网站建设越来越人性化和多元化,其中有大量非基础业务功能的渲染,如声音、图片和视频。此类数据也会单独作为一次响应被网页加载,但是却不能反应用户的主观需求,需要清除。(2)服务器交互方式。用户对网站的请求方式主要有get和post两种方式,其中,get代表用户主动拉取服务器信息,post代表用户主动向服务器推送信息并可选择是否拉取信息。其他方式如put和head不能代表用户有效访问意愿。所以一般情况下只保留get和post方式日志。(3)http状态码(statuscode)。http状态码表示服务器对用户访问的响应情况,协议中规定状态码由三位数字组成:2开头的状态码代表用户访问成功,已被服务端受理并进行响应;3开头的表示资源问题,其中包括客户端可使用自身缓存,资源需要重定位等;4开头表示客户端请求错误;5开头表示服务端无法进行服务。所以,4和5开头的无法表示一个完整的交互流程,应该去除。在清洗完无效日志之后,再针对日志中无效字段进行清洗,如日志中记录的服务器名称、ip地址和访问控制权限等。网络用户访问的页面都会映射为url(统一资源定位符)。本发明在清洗的过程中对所有有效页面url进行编号标识,以数字代替页面路径本身,方便后续处理。(2)识别用户,并根据时间规则识别用户会话;本具体实施方式中,识别用户会话具体为:若用户ip地址之前从未出现过,则判定为新开始的会话;而对于之前出现过的ip地址,则设定一个时间阈值,在时间阈值范围之内判定为同一个会话;如间隔超过时间阈值,则判定为新的会话。即对于每个用户行为,首先将第一个用户请求加入会话集中,后续同ip请求依据上一个请求计算间隔时间,如果超过时间阈值θ,则关闭当前会话,创建新的会话,并将其作为初始会话。识别出来的用户会话需要一定的形式进行表示,在本具体实施方式中,将用户会话表示为一定时间阈值内访问网站的url集合,这个url集合反映出用户访问网站的特点,假设一段时间内所有被访问的url集合u中共有n个url,则u可以被表示为:u={url1,url2,...,urli}(i=1,2,...,n);用w表示用户访问的页面集合(w也是u的子集),用m表示在当前日志数据内共识别出的用户会话数,则用户会话集合可以表示为:s={s1,s2,...,sj}(j=1,2,...,m),其中sj是u的非空子集,可以表示为:其中,用户会话sj中ip地址表示为ipj,表示用户在当前会话中访问的第l个url,表示用户在该页面所停留的时间。(3)对提取的用户会话进行优化处理,并将优化后的每个用户会话定义为一个四元组对的规范化表示:s=<sid,urli,ti,fi>,其中sid表示当前会话元组所属会话id,urli表示会话中第i个页面,ti是用户在当前会话中对该页面的访问时间,单位是秒;fi是用户在当前会话中,对该页面的访问次数。优化处理包括:合并相似度较高的url,优化url个数;以及依据web页面路径相似度,对相似度超过预设阈值的用户会话进行会话内url合并,优化url维度;其中,web页面路径相似度的度量方式可以采用以下两种方式之一:方法一:计算两路径间重合部分占路径比重,其相似度计算公式为:其中,p1表示从网站根节点到url1终端页面的路径,|p1|表示路径绝对长度(包含边的个数),|p1∩p2|代表两路径之间相同边的个数,相同边的个数则决定了路径的重叠程度,两路径相似度介于0和1之间。方法二:在网站中,上级域名和底层域名代表的含义有所不同,对网页的性质决定程度也有所不同。所以,可以从顶级域名开始,为每一层预设一个权值,每一个路径都可以用一串数字进行表示。例如:url1:weibo.com/ttarticle/p/show?id=230969,可以表示为“0111”,url2:weibo.com/tech/show?id=01008,可以表示为“011”。计算方法为:首先根据两者中较长路径,记录长度l,并从高到低进行赋权,然后从路径的最高层开始对比,当出现不一致情况时,此位及后续各位均标记为1,如图3所示。在图3所示的两路径对比中,l=4,sim(url1,url2)=4/(4+3+2+1)=0.4,所以两路径相似度为0.4。现实情况中,路径的高层域名决定了路径的大部分属性,低层域名只是进行进一步细分,所以在计算中,高层需要被赋予较高的权值,低层权值相对较小。所以,基于网页路径相似性度量会话相似性公式为:其中,n=min(length(sj),length(sk))。当计算得到的路径相似度大于预设阈值时,则对其进行合并处理,本具体实施方式中,优选的相似度阈值设置为0.7。以图3为例,sim(url1,url2)=4/(4+3+2+1)=0.4,该两个页面中,一个代表微博中实事板块,一个代表微博中科技板块,虽然都拥有同一个顶级域名,但是类别很分明,相似度只有0.4,不能将科技板块合并到实事板块中。在计算中从较长的网页路径开始对比,对达到相似度条件的网页路径进行合并,删除较长的路径,并将相对应的点击次数和访问时长相加到短路径上,这样即缩减了网页维度,也不会丢失用户兴趣精度。如url3:weibo.com/ttarticle/p/show?id=230969,t3=2min,f3=2;url4:weibo.com/ttarticle/p/tech?id=01008,t4=4min,f4=4,s(url3,url4)=0.9,故将url4合并到url3,t3=6min,f3=6,同时将url4删除。4)建立用户访问偏好加权矩阵:1)用户访问时间(浏览时长)离散化,建立用户时间-url矩阵,其中行为用户会话,列为url:矩阵tm×n中,m为用户数,n为站点url的个数,si,j为用户i访问第j个页面的总时长。本具体实施方式中,浏览时长离散表如表1所示:表1浏览时长离散表浏览时长离散值≤50(5,30]1(30,60]2>603在浏览时长离散化中,如果用户在当前页面停留时间不超过5秒表示为0,则说明用户是偶然点开页面,或在页面中没有发现感兴趣内容,当浏览时长大于5秒且小于30秒时,一般说明用户对页面进行了基本的访问,当大于30秒且小于60秒时,说明用户对页面内容比较感兴趣,当时长超过60秒时,可能用户需要长时间对页面内容进行仔细浏览,或用户短暂离开,只为其赋值为3,而不会再增加。2)用户访问频度离散化,建立用户频度-url矩阵,其中行为用户,列为url:矩阵mm×n中,m表示用户,n表示当前时段中服务器内记录的url个数;hi,j为用户i在一段时间内访问第j个页面的次数。本具体实施方式中,点击次数(用户访问频度)离散表如表2所示:表2点击次数离散表点击次数离散值00(0,2]1(2,4]2>43其中,离散值0表示用户i在当前会话中没有页面j的浏览记录;1表示对页面进行了偶然性访问或浅浏览,说明兴趣度较小;2表示页面的内容对用户来说比较重要,但又不是长期必须内容;3表示此页面时用户的常用页面或重度依赖页面。3)建立用户访问偏好加权矩阵,矩阵为高维稀疏矩阵,其中行为用户,列为url;通过对矩阵tm×n和mm×n进行加权处理,可以得到用户访问偏好加权矩阵rm×n:其中,rm×n的每个元素wi,j记载着当前会话对当前页面的访问加权情况(访问度量值),即wi,j=αhi,j+βsi,j(α>0,β>0),为了简化处理过程,本具体实施方式中,设置α+β=1;当然在实际处理中,也可以根据研究偏好,对α和β赋予不同比例权值,可以侧重研究倾向用户访问频率和用户访问时长的加权关联矩阵。在实际情况中,会话和整体社区用户访问的url数量都非常庞大,所以导致矩阵具有很高的维度。同时,同一会话内访问的url数量一般较少,导致矩阵中大部分数据为0。所以此关联矩阵属于典型的大稀疏矩阵。(8)根据用户访问偏好加权矩阵,对每个用户会话向量的规范化表示进行更新,即去掉其中的有关访问时长和访问次数的描述直接替换为对应用户访问度量值,然后采用mb-kmeans++聚类算法对各用户会话进行聚类处理,基于各类簇的聚类结果,得到具有相似访问行为的用户。在聚类处理时,采用欧式距离直接计算用户会话间的相似度,避免了建立相似度矩阵的时间消耗,降低了聚类成本。实施例为了进一步验证本发明的聚类方法的与现有的聚类算法(k-means、k-means++)的性能优势,采用下述两组实验数据集进行对比实验分析:1.实验数据集。(1)iris数据集。著名统计学家r.a.fisher在20世纪30年代中期提出iris(鸢尾花)数据集,该数据集是数据挖掘中占有非常重要的位置,其数据分为三类,分别是:versicolour、setosa和virginica。数据共150个,每类50个,每数据个体包含四个数值型属性:花萼长、花萼宽、花瓣长和花瓣宽。例如:(5.1,3.5,1.4,0.2)表示花萼长为5.1,花萼宽为3.5,花瓣长为1.4,花瓣宽为0.2。在本实施例中,分别取数据的三维属性:花萼长(sepallength)、花瓣长(petallength)和花瓣宽(petalwidth)进行聚类分析。数据完整格式如图4所示。(2)网关服务器数据集。web数据来自于网关服务器,本实施例中选取其中30000条记录用户日志记录和部分数据字段进行分析。在选取的日志中,共记录了用户的源ip地址,访问时间、访问方式、访问路径和访问控制等。在进行了无效记录清洗后剩余4963条,共637个用户,发现826个独立会话,其中共包含271个网页路径。在数据中,特别标注了会话id,用户访问时间time和频率frequency,如图5所示。在日志数据预处理的基础上,利用网页路径相似性特征进行合并,缩减之后url数量降至136个,大大减小了会话内路径维度。再合并路径的同时,将被合并路径的访问时长和点击频率增加到合并路径上。2.性能度量。对于聚类算法性能可以通过聚类中心、聚类速度、聚类精度、簇间相似度等进行度量。本实施例中,通过两种指标对聚类算法效果进行评估。针对iris数据集采用簇内相似度来检验聚类算法效果,对真实web日志数据采用聚类准确率来进行评价。(1)簇内相似度f:聚类的目的是将具有相似特征的对象分类到同一类中,好的聚类算法可以做到类内对象相似度极高,而类间相似度很低。所以,可以利用类内对象的相似性来度量聚类算法的效果。所采用的相似度(适应度)函数其中f(li)表示簇内相似度,该值越小,说明同一聚簇内相似性越小,内聚性越差,也就说明聚类算法的效果较差,反之说明簇内相似度越高,聚类算法效果较好;s(xi,zj)表示第i个样本数据xi和第j个聚类中心的相似度,可基于欧式距离计算。k-means、k-means++、mb-kmeans++算法均可以用该值进行度量。本实施例中,基于iris数据集进行测试,经过试验,得到最佳batch_size大小为数据量的10%。三种聚类算法效果图分别如图6、7和8所示。实验中,每组进行50次实验,取平均值作为最后的评价结果。三种算法平均适应度值如表3所示,在三组数据中,本发明的mb-kmeans++算法在精度方面较两种经典算法有一定损失,但是总体相差不大。是在大量(一万以上)样本的数据集处理上拥有很大速度优势表3三种聚类算法的适应度对比k-meansk-means++mb-kmeans++10.83230.83270.817220.85780.85530.849830.82870.82930.8251(2)聚类准确率。对于来自网关服务器的真实日志数据,由于用户自身使用情况比较复杂,且具有较强的使用场景分类,所以会话聚类的效果一般采用聚类准确率进行度量。本实施随机选取70%的数据作为训练集,剩下30%作为测试集,并利用类标记法对已有聚类进行标记,后对测试集进行聚类,判断是否数据样本被正确归类。首先利用训练集确定本数据集下ρ(ρ表示访问时长权重系数,即ρ=α,β=1-α)的取值(0~1之间),针对每个取值,分别进行10次实验,取结果的平均值。当ρ<0.5时,用户对网页的访问频率占主要作用,但是可以发现,随着ρ的变小,聚类效果也会变得越差。这说明有些情况下,用户虽然只浏览了某网页一次,但是却花费了大量的时间,说明用户对该页面中的内容有很大的兴趣,但是依据频率判断却得出了相反的结论,导致聚类效果下降。在ρ>0.5时,用户访问时长占主导作用,由结果可以看出ρ在很大时,聚类效果也会变差,说明用户在访问某页面时离开的行为,会对结果进行误导,当ρ=0.7会话聚类结果的准确性最高,具体结果见图9。表4给出了ρ=0.7时,在训练集上聚类的结果。整个实验数据中共包含13种主题路径,聚为五个聚簇,分别是社交、新闻、学校、购物和搜索引擎。聚类之间会话内容基本没有交叉,由此可见其聚类效果较好,可以有效的根据会话浏览路径进行会话归类。表4聚类包含信息聚类聚类中路径主题1社交评论(weibo、bbs、zone)2新闻热点(news.ouhu、news.163、xinhua)3校园相关(uestc、idas.uestc)4搜索引擎(baidu、so)5购物(taobao、jd、z)由表4的结果可以看出,实验数据整体可以划分为5类,依次标记为1至5,在对测试集数据进行会话聚类前,需要对其中会话263个会话手工标记所属类别,方便后续统计。依据会话内页面所属主题占比判断当前会话所属类别,如对页面http://www.weibo.com.cn占比较大的会话应标记为1,对页面http://www.souhu.com.cn占比较大的会话应标记为2。在对所有会话标记完成后,用三种聚类算法进行聚类,并统计准确归类会话数量和时间,进行聚类效果比较。表5所示为k-means算法、k-means++算法和mb-kmeans++算法在测试集上测试后的聚类结果的准确性和聚类时间比较。表5web数据三种算法对比k-meansk-means++mb-kmeans++准确聚类会话个数188191185准确率0.7130.7250.703聚类时间(s)11.4811.724.75综上,本发明的聚类方法可以在用少量样本的情况下大程度的拟合全数据集样本特征,同时优化目标函数。针对大量样本的数据集处理上拥有很大速度优势。以上所述,仅为本发明的具体实施方式,本说明书中所公开的任一特征,除非特别叙述,均可被其他等效或具有类似目的的替代特征加以替换;所公开的所有特征、或所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以任何方式组合。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1