基于CNN和RNN的序列化推荐方法与流程
本发明涉及推荐系统的算法设计,设计了一种基于cnn和rnn的序列化推荐方法,可广泛应用于互联网电商,新闻门户,娱乐等多种推荐场景。
背景技术:
在信息社会中,互联网已渗透在我们生活的各个方面。在日常的购物、音乐、电影等综合性强且上下文复杂的应用场景下,如何更好的利用用户及用户产生的行为数据,为广大互联网用户提供更好的推荐服务变得极为重要。
传统的基于用户历史行为偏好和基本信息进行推荐是一种基于全局的思考方式,属于对用户整体偏好的推荐,然而实际中用户的行为存在很多突变情况,用户的近期行为会对接下来的行为产生影响,如用户最近开始浏览新生儿用品,可能接下来用户会关注婴幼儿相关的新闻或商品。然而,这中短期行为的变化是一种很难被传统模型捕捉到的,因此序列化推荐算法应运而生。序列化推荐是一种基于序列的思想来进行推荐即用户的行为序列是存在一定的规律,最近的用户行为会对用户的下一次行为产生影响。常用的解决思路有基于马尔可夫链的序列推荐,马尔可夫的思想是认为用户的前一次行为会对用户的下一次行为产生影响,基于这个假设进行序列化推荐是可以实现的,但是这种强假设关系意味着用户的行为必须具有很强的规律性,显然很多场景是无法满足这一条件的。基于rnn的序列化推荐也是在此基础上进行改进,利用lstm对长短期关系的学习能一定程度上缓解马尔可夫模型带来的这种强假设的限制,但是对于现实场景中存在大量的突然行为,这种行为会严重影响到序列模型的准确性。为了减少上述行为的影响,有研究者提出了基于cnn的短期行为的局部捕捉和组合,利用cnn能有效跳跃短的突变行为,但是cnn无法把握长期的行为偏好,这也是cnn方法的缺陷。
技术实现要素:
本发明所要解决的技术问题是,针对现有技术存在的问题和不足,提出了一种基于cnn和rnn结合的序列化推荐方法,通过利用cnn和rnn各自优点,并将两者有效的结合起来,从而解决目前序列化推荐中通常存在的考虑到最近情况而忽略了历史情况或者考虑了历史情况而忽略了最近行为的情况,同时对跳跃行为这种只利用rnn等序列模型无法学习到的行为进行学习,让历史行为的表达更为丰富从而提高序列化推荐的准确性。
为解决上述技术问题,本发明所提出的技术方案是:一种基于cnn和rnn结合的序列化推荐方法。该方法包括以下步骤:
1)将每个用户的历史行为序列item映射为一个d维的embedding向量,生成一个n*d维的矩阵,其中n代表item数,d代表每个item映射的纬度;
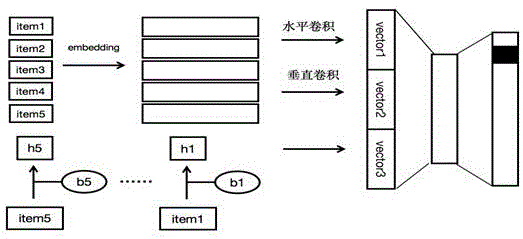
2)对于embedding向量,将每个映射的d维向量堆叠,利用cnn对堆叠结果的局部特征进行提取,采用多种不同大小的水平卷积核来学习多个item之间的特征关系,得到输出向量vector1;同时采用垂直卷积核对每次输入的所有item的关系进行综合,得到输出向量vector2;采用经典的lstm作为序列模型单元,每次将一个item的embedding输入到网络中进行循环学习,将历史的n个item的embedding输入到lstm,最终得到一个综合的预测输出,即一个lstm学习到的基于历史item序列的预测向量vector3;
3)将向量vector1、vector2和vector3拼接并得到一个长向量,将该长向量输入到一个多层全联接的神经网络中,采用负采样的方法进行输出优化;最后根据模型输出结果进行用户推荐。
步骤1)中,采用item2vec的思想对每个item进行向量化,即将用户历史产生行为的item序列看作为一个句子,不同的用户产生大量的类似句子的item序列,将每个用户的历史行为序列看作为一个被分割为若干单词的句子,然后利用word2vec的处理方式对这些用户行为item进行训练,训练完后的embedding层即为每个item对应的embedding向量。
本发明的有意效果为:本发明将cnn和rnn两种方法有效结合起来,利用两种方法的各自优点对用户行为进行预测并给予推荐,该方法能解决目前序列化推荐中通常存在的一种问题:考虑到最近情况而忽略了历史情况和考虑了历史情况而忽略了最近行为的情况,同时该方法能克服单一rnn等序列模型无法学习到跳跃行为的问题,让历史行为的表达更为丰富从而提高序列化推荐的准确性。
附图说明
图1为流程图。
具体实施方式
本发明包括以下步骤:
1)基于深度学习的推荐算法模型首先要对每个用户历史行为的item特征进行embedding,即将每个item映射为一个d维向量。采用的是item2vec的思想对每个item进行向量化,这样就可以生成一个n*d维的矩阵,其中n代表item数,d代表每个item映射的纬度。这个矩阵即图1中embedding操作的权重向量。
2)对步骤1产生的embedding向量进行处理。在图1上半部分使用的是cnn的卷积操作,具体操作方式是将每个映射的d维向量堆叠(如图1),这里利用cnn的思想对其局部特征进行提取,分别采用水平卷积核和垂直卷积核。这里采用双向卷机的优势在于可利用多个水平卷积核(卷积核大小为l*d其中l表示卷积核高度,d表示卷积核宽度)提取各个相邻item之间的特征关系。由于传统的序列预测模型中会忽略一种跳跃行为和单元影响,但因为人的行为存在非常多的随机性,使得这种行为关系在序列模型中经常出现。所以这里采用多种不同大小的水平卷积核来学习多个item之间的这种局部关系,同时采用垂直卷积核(卷积核大小l*1,其中l是每次输入的所有item的数量)对每次输入的所有item的关系进行综合,这样能有一定的全局信息加入到模型。通过两种不同方式的卷积共同作用分别得到各自的输出向量vector1和vector2。在使用cnn卷积操作时需注意,水平卷积的卷积核宽度为整个向量的纬度,该卷积核宽度保持不变才能保证整个item向量的不割裂。图1下半部分是与cnn操作并行的rnn操作,这里采用经典的lstm作为序列模型单元,每次将一个item的embedding输入到网络中进行循环学习,将历史的n个item的embedding输入到lstm最终会得到一个综合的预测输出,即一个lstm学习到的基于历史item序列的预测向量vector3。
3)将步骤2中产生的向量vector1、vector2和vector3进行拼接得到一个长向量,将该长向量输入到一个多层全联接的神经网络中,这里全联接神经网络可将不同纬度学习到的特征进行融合,因此采用一个简单的单隐层神经网络。通常情况下由于item数量非常大,输出时采用softmax进行概率化会非常耗时,这里采用负采样的思想进行输出的优化,具体方法即对于每一个正样本,随机选取若干个负样本(一般5-10个),采用交叉熵的形式进行训练,这样比全量item的softmax更加省时而且效果上基本没有区别。
4)通过上述学习模型,给定一个输入样本,则输出与每个item对应一个概率值。由于输出概率表示用户未来会对这个item产生行为的概率,因此对所有概率值排序并取出概率最大的前m个item推荐给对应的用户,其中m表示在不同应用场景下可选取不同推荐数目。
上述方案中采用的item2vec是一种基于word2vec思想而来的行为序列向量化算法,将用户历史产生行为的item序列看作为一个句子,这样不同的用户就能产生大量的类似句子的item序列,我们将每个用户的历史行为序列视为一个被分割为若干单词的句子,然后利用上述word2vec的处理方式对这些用户行为item进行训练。我们指定有序单词中的某一个单词为中心词,利用中心词周围的若干个单词,将这些单词映射为指定维度的中间层(即embedding层,将每个单词看作为一个item),输出用负采样的方式进行训练,最终当模型训练完成后中间层的向量即为每个item对应的embedding向量。
方案中的负采样的思想是借鉴于word2vec中的负采样技术,这里我们对于每一个目标item选取若干个负样本(一般5-10个),然后利用交叉熵的思想进行训练。采样算法如下(1),交叉熵如下(2)
上述表达式计算的是每个词的采样概率,其中counter(w)表示每个itemw在数据集上出现的次数,len(w)表示itemw的采样概率,d代表整个数据集中的item
上述表达式是交计算交叉熵的,其中x表示每个item的embedding向量,θ表示对应的权重向量,σ是sigmoid函数表示一个正样本的概率,neg(w)表示采样的负样本。
- 还没有人留言评论。精彩留言会获得点赞!