一种信息处理系统的制作方法
本发明涉及信息处理领域,尤其涉及一种信息处理系统。
背景技术:
随着互联网技术的发展,用户数量的急剧增长,基于位置的服务(lbs)也逐渐成为移动终端用户的日常服务。这种背景下,移动终端用户对信息处理系统的处理效率和准确度提出了越来越高的要求,但现有技术中信息处理系统一般存在如下缺点:一是数据在存储时,查询内容关键词一般采用不分级的遍历的方式进行查询,查找速度慢;二是对于用户和内容数据提供者来说,缺少一种更为快捷有效的匹配和触达移动终端用户的方式,导致移动终端用户体验差,内容数据提供者的反馈也不满意。
技术实现要素:
为克服上述问题,本发明涉及一种信息处理系统,包括主服务器以及与所述主服务器通信连接的多个用户端,所述主服务器包括执行计算机程序的处理器、数据库及缓存器,所述缓存器用于存储所有m个第一内容信息;所述数据库用于存储n个第二内容信息;所述计算机程序被处理器执行以实现以下步骤:步骤s100,主服务器接收用户端的输入信息,所述输入信息包括用户的输入内容;步骤s200,主服务器根据输入内容与缓存器中存储的第一内容信息匹配,如果存在匹配的第一内容信息,那么处理器将匹配的第一内容信息推送至用户端进行显示;如果不存在匹配的第一内容信息,则执行步骤s300;步骤s300,主服务器根据输入内容与数据库中存储的第二内容信息匹配,如果存在匹配的第二内容信息,则将其发送到用户端进行显示。
本发明的有益效果:通过将内容数据划分为第一内容信息和第二内容信息,可以实现根据内容数据的优先级进行推送的效果,提高了信息处理系统的精确度,提高了推送效率。
附图说明
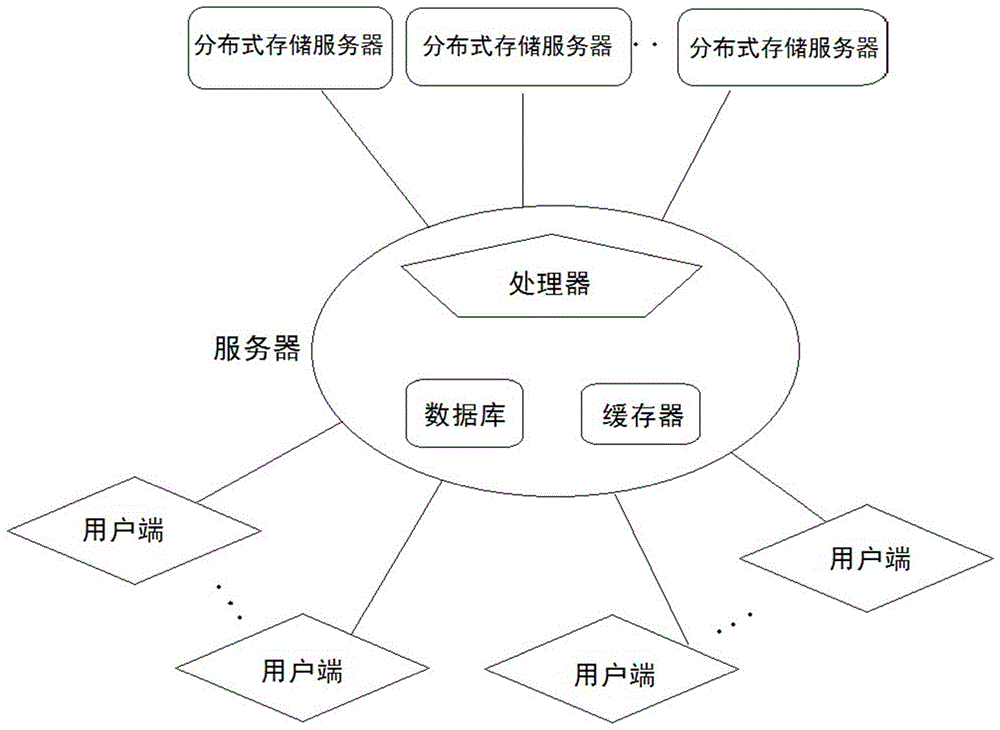
图1是本发明信息处理系统的结构图。
图2是本发明中计算机程序被执行的步骤流程图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,将结合附图对本发明作进一步地详细描述。这种描述是通过示例而非限制的方式介绍了与本发明的原理相一致的具体实施方式,这些实施方式的描述是足够详细的,以使得本领域技术人员能够实践本发明,在不脱离本发明的范围和精神的情况下可以使用其他实施方式并且可以改变和/或替换各要素的结构。因此,不应当从限制性意义上来理解以下的详细描述。
如图1所示,本发明提供了一种信息处理系统,包括主服务器以及与主服务器通信连接的多个用户端。根据本发明,主服务器包括执行计算机程序的处理器、数据库及缓存器;计算机程序可以被存储在非瞬时性的存储介质中,并且在主服务器执行时被加载到主服务器的内存中;处理器优选实现为适应于服务器的多核处理器;缓存器优选实现为处理器能够高速读取的易失性或非易失性存储器,即处理器读取缓存器的速度要超过或者远超过数据库,例如读取速度比数据库读取速度高1-2个数量级;数据库可以实现为本领域技术人员能够理解或获知的多种类型的数据库,例如文本型数据库、关系型数据库等。本领域技术人员理解,处理器和数据库的品牌、型号、参数等指标,以及计算机程序的编写语言和加载方式等不会对本发明的保护范围作出限制。根据本发明,用户端可以实现为包括pc、pad、和/或智能手机等现有技术中本领域技术人员能够理解或者获知的移动终端。
根据本发明,缓存器用于存储所有m个第一内容信息,优选的还存储有对应于m个第一内容信息的m个第一内容优先级。根据本发明,数据库用于存储n个第二内容信息,优选的还存储有对应的n个地理围栏坐标(p1,p2,...,pn),其中pi={(xi1,yi1),(xi2,yi2),......,(xin,yin)}为对应于第i个第二内容信息的地理围栏坐标,i的取值范围为1…n。进一步的,第一内容优先级为与地理围栏坐标等涉及位置信息无关。
可选的,本发明的信息处理系统还包括多个与主服务器通信连接的分布式存储服务器,分布式存储服务器中存储有与第一、二内容信息关联的内容文件;第一、二内容信息中包括内容文件在分布式存储服务器中的存储地址;当用户端操作显示的第一、二内容信息时,将第一、二内容信息的存储地址上传到主服务器。本领域技术人员理解,通过分布式存储服务器,使得主服务器中不必存储有具体的第一、二内容文件(尤其是第一、二内容为多媒体内容时),而只需要存储第一、二内容的地址信息,从而能够降低主服务器的负荷。本领域技术人员也能够理解,本发明中分布式存储服务器并不是必须的,也可以在主服务器中直接存储第一、二内容。
根据本发明,第一、二内容信息一般格式上实现为包括utf-8、gbt等字符串实现的文本格式,具体内容一般可以包括对目标对象的文本描述信息,或者是涵盖视频、图像、音频及其部分或全部组合的多媒体信息的元数据。
根据本发明,进一步的,如图2所示,计算机程序被处理器执行以实现以下步骤:
步骤s100,主服务器接收用户端的输入信息,输入信息包括用户的输入内容(例如用于检索或查询的关键词或关键字),进一步的,输入信息中还包括用户的位置信息。一个实施例中,用户的位置信息为地理坐标z1=(x0,y0),例如用户端通过百度、高德、谷歌、腾讯、搜狗等公司提供的地图服务,从而直接获得用户的位置的地理坐标。另一实施例中,用户的位置信息实现为文本位置信息,例如用户端通过搜狗、科大讯飞等汉字输入程序所接收到的用户直接输入或通过音频转换的文本信息,也可以是用户从用户端的本地存储介质中读取的已经存在的文本信息;该实施例中,文本位置信息的示例为“广州市天河区xx公司”。
步骤s200,主服务器根据输入内容与缓存器中存储的第一内容信息匹配,如果存在匹配的第一内容信息,那么处理器将匹配的第一内容信息推送至用户端进行显示。优选的,根据第一内容优先级排序的第一内容信息推送至用户端进行显示,即用户端上根据第一内容信息的优先级进行显示,从而使得高优先级的第一内容信息更容易被用户端呈现。如果不存在匹配的第一内容信息,则执行步骤s300。
步骤s300,主服务器根据输入内容与数据库中存储的第二内容信息匹配,如果存在匹配的第二内容信息(例如在数据库存储的n个第二内容信息中,存在x个匹配的第二内容信息),则将x个匹配的第二内容信息发送到用户端进行显示。进一步的,本发明中还根据用户的位置信息和x个匹配的第二内容信息对应的x(x≤n)个地理围栏坐标(q1,q2,...,qn)确定在用户端进行显示的顺序,其中qj={(xj1,yj1),(xj2,yj2),......,(xjn,yjn)}为第j个第二内容信息的地理围栏坐标,j的取值范围为1…x。
步骤s400(可选的),主服务器将根据存储地址查找到的第一、二内容信息所在的分布式存储服务器和用户端建立数据连接,并传输与第一、二内容信息关联的内容文件到用户端。
根据本发明,缓存器中存储的第一内容信息要优于数据库中存储的第二内容信息,当输入信息存在满足查询条件的第一内容信息时,第二内容信息不进行查询及显示,如果不存在匹配的第一内容信息,则再在数据库中查询匹配的第二内容信息。同时设置处理器能够更快速读取的缓存器存储第一内容信息,可显著提高第一内容信息的查询匹配速度。综合以上两点,本发明能够使得更贴合用户端查询或匹配的第一内容信息被优先显示给用户,从而提升了用户获取信息的有效性和整体系统反应速度。
根据本发明的一个实施例,当用户的位置信息为地理坐标z1时,本发明中的步骤s300进一步包括:
步骤s310,对于x个匹配的第二内容信息中的第j个第二内容信息(即qj对应的第二内容信息),如果dis1≤d,那么执行步骤s320,否则,执行步骤s330;其中,
步骤s320,将第j个第二内容信息和对应的dis1推送到用户端,dis1用于确定用户端对第二内容信息的显示顺序。
步骤s330,不将第j个第二内容信息推送到用户端。
该实施例中,对于匹配的第二内容信息,增加了基于位置的约束条件,即只有在预设阈值d范围内的匹配结果,才被推送到用户端,基于此,能够有效降低用户端浏览的信息量,尤其是在一些场景中,过滤掉受距离约束较大的查询结果,有效提升用户端的浏览效率。
根据本发明的另一个实施例,主服务器中还存储有名称和坐标映射文件,名称和坐标映射文件中包括区域名称、以及和区域名称对应的地理围栏坐标。本领域技术人员理解,映射文件可以实现为结构化的文本文件(例如csv文件),或者数据库的关系表文件。示例性的一条记录中,区域名称可以精确到行政区县,例如是“罗湖区”、对应的地理坐标为现有技术和/或公知技术中提供的罗湖区边界的地理围栏坐标的集合。当用户的位置信息实现为文本位置信息(示例性的,深圳市罗湖区xx小区)时,本发明的的步骤s300进一步包括:
步骤s360,根据映射文件,解析文本位置信息获取位置信息的区域名称,以及位置信息对应的地理围栏坐标z2={(x01,y01),(x02,y02),......,(x0l,y0l)},其中l为z2中地理坐标的数量。根据本发明的一个实施例,通过将映射文件中的区域名称逐个遍历和文本位置信息进行匹配,能够获得位置信息的区域名称,例如前述例子中的“罗湖区”,进而在映射文件中,获取罗湖区对应的地理围栏坐标。
步骤s370,对于x个匹配的第二内容信息中的第j个第二内容信息,如果dis2≤d,那么执行步骤s380,其中,
步骤s380,将第j个第二内容信息和对应的dis2推送到用户端,dis2用于确定用户端对第二内容信息的显示顺序。
步骤s390,不将第j个第二内容信息推送到用户端。
该实施例中,与前述实施例相比,能够有效处理用户输入的文本位置信息情况下的距离约束,进而能够有效降低用户端浏览的信息量,尤其是在一些场景中,过滤掉受距离约束较大的查询结果,有效提升用户端的浏览效率。
根据本发明,d的取值可以为经验参数,例如固定的距离或者可以用户自定义的距离参数。但是优选的,d=k*max{[max(xj)-min(xj)],[max(yi)-min(yi)]},其中max和min分别为最大值和最小值函数,max(xj)和min(xj)分别为(xj1,xj2,......,xjn)的最大值和最小值,max(yj)和min(yj)分别为(yj1,yj2,......,yjn)的最大值和最小值;k为经验系数(优选的取值为0.5…1)。该优选方式中,通过动态设置预设阈值d的取值,能够更有效的提升位置匹配的精度。
根据本发明示例性的第一个应用方面,第一、二内容信息为视频内容(含短视频内容),即分布式存储服务器中存储有多个视频文件,主服务器中存储视频文件的提供者、正版标识和/或清晰度作为视频元数据,将上传视频数量超过特定阈值的视频提供者、具有正版标识和/或清晰度超过特定阈值的列为第一内容信息存储在缓存器中,其余的列为第二内容信息存储在数据库中。该方面中,第一内容信息对应的优先级例如是一段时间内的视频浏览次数、播放次数和/或下载次数等。这样,当用户端查询到第一内容信息(例如用户查询“点都德”)时,根据本发明可以将第一内容信息对应的视频内容传输到用户端,当用户端没有查询到第一内容信息时,根据本发明可以将第二内容信息传输到用户端,并根据提供者的地理围栏坐标和用户端的地理位置对第二内容信息进行排序,以便于用户端快速准确获知与“点都德”相关的视频内容。
根据本发明示例性的第二个应用方面,第一、二内容信息为产品信息,即分布式存储服务器中存储有多个与产品有关的介绍图像、视频和/或文本文件,主服务器中存储产品的描述信息,将经过权威机构认证的产品和其提供者列为第一内容信息存储在缓存器中,其余的列为第二内容信息存储在数据库中。该方面中,第一内容信息对应的优先级例如是一段时间内的产品的浏览次数和/或下单次数等。这样,当用户端查询到第一内容信息(例如用户查询“螺纹钢”)时,根据本发明可以将第一内容信息对应的产品和其提供者传输到用户端,当用户端没有查询到第一内容信息时,根据本发明可以将第二内容信息传输到用户端,并根据提供者的地理围栏坐标和用户端的地理位置对第二内容信息进行排序,以便于用户端快速准确获知与“螺纹钢”相关的内容。
本领域技术人员知晓,本发明的第一、二应用方面仅是本发明可以应用到的应用场景,其目的仅是促使本领域技术人员从具体示例的角度更好的理解本发明的技术方案,并不意味着本发明必然或者只能够应用到第一、二应用方面。发明也并不意图单独保护应用场景,即第一、二应用方面并不构成对本发明保护范围的限制。事实上,只要区分第一、二内容的并且采用本发明技术方案进行区分和处理的所有应用场景均将落入本发明的保护范围。
本发明公开的方法包括用于实现本发明目的的一个或多个步骤,方法步骤可彼此相互交换而没有离开本发明的范围。换言之,除非实施例的正常操作需要特定顺序的步骤,可修改具体步骤的顺序,而不会离开本发明精神的范围。尽管本发明主要描述了具体实施例和应用,但本领域技术人员应理解本发明并不局限于此。根据本发明公开的方法和系统,对于本领域技术人员明显的各种修改、变化以及改变均不背离本发明的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!