基于通用可重构处理器DBSS和MBSS的映射方法与流程
本发明涉及数据处理领域,具体地,涉及基于通用可重构处理器dbss(动态循环边界静态调度,dynamicboundary,staticschedule)和mbss(混合循环边界静态调度,mixedboundary,staticschedule)的映射方法。
背景技术:
目前,空间编程结构(例如fpga和cgra,coarse-grainedreconfigurablearchitectures)已被广泛用于计算密集型应用。fpga的并行度较高,但仅限于细粒度的计算。cgra作为一种粗细粒度混合的处理器架构,能在提供并行性的同时降低功耗和提升性能。但是cgra的性能在很大程度上依赖于编译器技术,针对复杂应用提供高效的算法映射依然是一种巨大的挑战。
一般来说,通用可重构处理器包括四个部分,第一个是pea阵列(运算单元阵列,processingelementarray),它是cgra的核心;第二个是指令寄存器,内核程序通过编译器的分析和优化,会生成数据流图(dfg,dataflowgraph),通过模调度映射将dfg转成配置信息存入指令寄存器,在控制器的调度下,依次读取指令执行;第三个是数据寄存器,数据寄存器用于数据存储,是pea阵列的主要数据来源,阵列运算后的结果也将存入数据寄存器;第四个是数据互连,为了减少面积和功耗开销,不同的pe单元只能和相邻的或者最多距离两个pe单元(运算单元,processingelement)进行通信。传统结构只能针对数据流图进行映射,对于带有控制流图(cfg,controlflowgraph)的映射会带来新的挑战。
此外,很多研究都在探讨循环体的并行性,为了提高并行性,现在的映射技术主要集中在循环体上,如部分预测、全预测和路径选择算法等。然而,这些方法都假设循环边界固定,采用了循环展开的技术。针对循环边界不固定的应用场景,现有的技术如会使用最大循环边界进行循环展开,这种技术会导致一些无效的指令被发射,不仅有速度低,效率瓶颈的问题,还会带来额外的功耗消耗。此外,dise和基于状态的全预测技术可以处理cfg的映射,但dise和基于状态的全预测主要处理分支(if-else)结构,而且只能处理最内层的循环体部分。针对循环边界不确定的dfg和cfg,以及嵌套的循环还没有现有的技术可以解决。
技术实现要素:
针对现有技术中的缺陷,本发明的目的是提供一种基于通用可重构处理器dbss和mbss的映射方法。
根据本发明提供的一种基于通用可重构处理器dbss的映射方法,包括:
循环分割步骤:将循环分割为循环控制基本块和循环体基本块,所述循环控制基本块包括基本算子,所述循环体基本块包括循环体;
数据流图构建步骤:根据所述循环体基本块的基本算子构建第一有向图描述数据依赖关系;
控制流图构建步骤:根据所述循环控制基本块的基本算子构建数据流图,根据循环控制基本块和循环体基本块之间的控制依赖关系构建第二有向图描述基本块之间的控制依赖关系;
混合步骤:将第一有向图和第二有向图合并为一个混合数据控制流图;
映射步骤:对混合数据控制流图进行映射。
较佳的,在所述映射步骤之后还包括:
优化步骤:对于没有数据依赖关系的算子,采用预测技术减小循环启动间隔。
较佳的,所述基本算子包括:循环变量初始化、循环条件判断和循环变量更新。
较佳的,在构建的第一有向图d=<vd,ed>中,将基本算子抽象为图上的节点,vd为所有基本算子的点集,ed为基本算子之间数据依赖边的集合,两个节点a,b∈vd,如果节点a是节点b的输入,则存在一条边ei=(a,b)∈ed。
较佳的,在构建的第二有向图c=<vc,ec>中,当两个基本块c1,c2∈vc之间存在一条边ei=(c1,c2)∈ec,就会在基本块c1和c2之间产生一条goto语句,vc为控制基本块的点集,ec为两个控制基本块节点之间的控制依赖边。
较佳的,在构建的混合数据控制流图h=<vh,eh>中,循环控制基本块和循环体基本块都有各自的数据流图,所以vh=vd1∪vd2,其中vd1和vd2分别是循环控制基本块和循环体基本块的数据流图的节点,对于两个基本块之间的控制依赖边ec可以转移到节点之间的控制依赖边ec′,再加上两个基本块之间的数据依赖边e′d,则eh=ed1∪ed2∪ec′∪e′d,vh为所有基本块内点集,eh为节点之间的控制依赖边和数据依赖边。
较佳的,所述控制流图构建步骤中,根据分支判断的控制语句构建数据流图。
较佳的,将vh划分为三个部分以简化控制流图的描述,vh=vo∪vp∪vi,其中vp是循环条件判断的节点,vo是由循环控制基本块中除去循环条件判断以外的节点,vi是循环体内的节点。
较佳的,对嵌套循环的控制流建立以下规则:算子pi∈vp是基本块ui的循环条件判断,对于映射f:pi→ui,表示pi控制着基本块ui的执行,对于嵌套基本块
根据本发明提供的一种基于通用可重构处理器mbss的映射方法,包括:
分析循环步骤:将循环分成循环边界固定的循环和循环边界不固定的循环两类,针对循环边界固定的循环采用通用方法循环展开,针对循环边界不固定的循环,采用下述步骤迭代;
循环分割步骤:将循环分割为循环控制基本块和循环体基本块,所述循环控制基本块包括基本算子,所述循环体基本块包括循环体;
数据流图构建步骤:根据所述循环体基本块的基本算子构建第一有向图描述数据依赖关系;
控制流图构建步骤:根据所述循环控制基本块的基本算子构建数据流图,根据循环控制基本块和循环体基本块质检的控制依赖关系构建第二有向图描述基本块之间的控制依赖关系;
混合步骤:将第一有向图和第二有向图合并为一个混合数据控制流图;
映射步骤:对混合数据控制流图进行映射。为,为为控制基本块的点集,为为,为为循环控制基本块内的基本算子和循环体基本块内的基本算子的集合,为循环控制基本块内的数据依赖边、循环体基本块内的数据依赖边、循环控制基本块内的节点和循环体基本块内的节点之间数据依赖边和控制依赖边组成。为,为。
与现有技术相比,本发明具有如下的有益效果:
本发明的动态循环边界静态调度的映射方法能够处理循环边界不确定的应用,以及处理静态循环边界和动态循环边界混合的应用;在动态循环边界静态调度的映射方法的基础上改进得到的混合循环边界静态调度的映射方法能够处理多层嵌套的循环。
相比于现有最佳的基于状态的全预测和处理分支最有效的dise方法,在处理循环边界不确定的应用上,本发明在速度、性能和功耗上都具有较大的优势。
附图说明
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
图1为本发明提出的改进的通用可重构处理器的拓扑结构;
图2为本发明增加控制端口和影子控制寄存器后改进的内部结构;
图3为本发明理解循环边界确定的一个实例;
图4为本发明一个实施例的循环边界不确定的算法;
图5为本发明方便阐述的一个2×2pea的示意图;
图6为本发明的流程图;
图7为本发明的图4的控制流图;
图8为本发明的混合控制流图;
图9为本发明的图8的时序扩展图(timeextendedcgra,tec);
图10为本发明提出的指令集。
具体实施方式
下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变化和改进。这些都属于本发明的保护范围。
本发明提供的一种基于通用可重构处理器dbss的映射方法,包括:
循环分割步骤:将循环分割为循环控制基本块和循环体基本块,所述循环控制基本块包括基本算子,所述循环体基本块包括循环体;
数据流图构建步骤:根据所述循环体基本块的基本算子构建第一有向图描述数据依赖关系;
控制流图构建步骤:根据所述循环控制基本块的基本算子构建数据流图,根据循环控制基本块和循环体基本块之间的控制依赖关系构建第二有向图描述基本块之间的控制依赖关系;
混合步骤:将第一有向图和第二有向图【备注:循环控制基本块内部有一些节点,块内部的节点会存在一些数据依赖关系(这将构成数据依赖图,也即数据流图);循环体基本块内部的节点也会存在数据流图;这两个基本块之间不仅存在控制依赖关系,也可能存在数据依赖关系,在合并的时候,需要做一种转换,这个转换包含两个步骤:a>将控制基本块之间块-块的控制依赖边转换到节点-节点之间的控制依赖边(细化);b>如果两个块内部的节点存在数据依赖关系,再添加相应的数据依赖边】合并为一个混合数据控制流图;
映射步骤:对混合数据控制流图进行映射。
优化步骤:对于没有数据依赖关系的算子,采用预测技术减小循环启动间隔。
所述基本算子包括:循环变量初始化、循环条件判断和循环变量更新。
在构建的第一有向图d=<vd,ed>中,将基本算子抽象为图上的节点,vd为所有基本算子的点集,ed为基本算子之间数据依赖边的集合,两个节点a,b∈vd,如果节点a是节点b的输入,则存在一条边ei=(a,b)∈ed。
在构建的第二有向图c=<vc,ec>中,当两个基本块c1,c2∈vc之间存在一条边ei=(c1,c2)∈ec,就会在基本块c1和c2之间产生一条goto语句,vc为控制基本块的点集,ec为两个控制基本块节点之间的控制依赖边。
在构建的混合数据控制流图h=<vh,eh>中,循环控制基本块和循环体基本块都有各自的数据流图,所以vh=vd1∪vd2,其中vd1和vd2分别是循环控制基本块和循环体基本块的数据流图的节点,对于两个基本块之间的控制依赖边ec可以转移到节点之间的控制依赖边ec′,再加上两个基本块之间的数据依赖边e′d,则eh=ed1∪ed2∪ec′∪e′d,vh为所有基本块内点集,eh为节点之间的控制依赖边和数据依赖边。
所述控制流图构建步骤中,根据分支判断的控制语句构建数据流图。
将vh划分为三个部分以简化控制流图的描述,vh=vo∪vp∪vi,其中vp是循环条件判断的节点,vo是由循环控制基本块中除去循环条件判断以外的节点,vi是循环体内的节点。
对嵌套循环的控制流建立以下规则:算子pi∈vp是基本块ui的循环条件判断,对于映射f:pi→ui,表示pi控制着基本块ui的执行,对于嵌套基本块
本发明还提供一种基于通用可重构处理器mbss的映射方法,包括:
分析循环步骤:将循环分成循环边界固定的循环和循环边界不固定的循环两类,针对循环边界固定的循环采用通用方法循环展开,针对循环边界不固定的循环,采用下述步骤迭代;
循环分割步骤:将循环分割为循环控制基本块和循环体基本块,所述循环控制基本块包括基本算子,所述循环体基本块包括循环体;
数据流图构建步骤:根据所述循环体基本块的基本算子构建第一有向图描述数据依赖关系;
控制流图构建步骤:根据所述循环控制基本块的基本算子构建数据流图,根据循环控制基本块和循环体基本块质检的控制依赖关系构建第二有向图描述基本块之间的控制依赖关系;
混合步骤:将第一有向图和第二有向图合并为一个混合数据控制流图;
映射步骤:对混合数据控制流图进行映射。
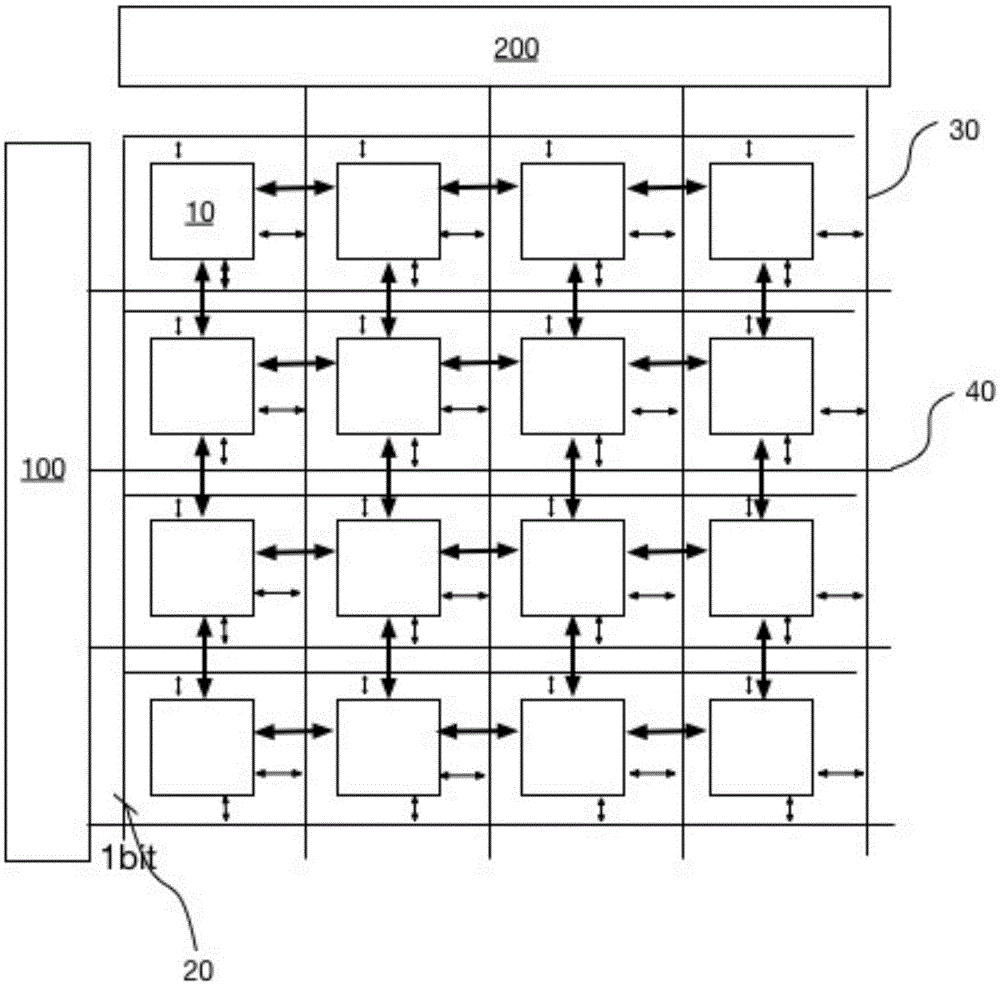
图1是本发明提出的改进的cgra结构,模块100描述的是数据寄存器,它作为pea数据来源和去向的途径之一。模块200描述的是指令寄存器,它存储了需要运行的所有指令,在本发明的一个实施例中,所述指令集进行了改进。模块10是一个pe单元,它是pea阵列的一个基本单元。模块300是指令取址单元,指令取址单元可取出指令寄存器里的指令。在本发明的一个实施例中,所述pe内部结构进行了细微的调整,详见图2。总线40,连接数据寄存器和pe的输入端口。总线30连接指令寄存器和控制寄存器,最终由控制寄存器负责指令的分发和执行。连线20是1-bit的控制全连接,它是本发明在传统结构上新增的部分,1-bit的控制信号网络和指令取址单元之间有连接,动态控制指令的取和发射。
图2描述的是pe的内部结构,输入端口24、25是32-bit的,它是输入来源有相邻pe的输出、本地数据寄存器23。寄存器14是一个影子控制寄存器sreg,是本发明改进的结构,它可以通过15输出到其它pe,通过16输出到指令取址单元,也可以输出到自己的数据选择器13。所述寄存器14可以在pe映射控制流算子的时候,缓存1-bit的输出信号。控制端口12是一个使能端,该端口是1-bit宽,但却可以控制alu21的执行与否。数据选择器13可以在控制端口12和影子控制寄存器14中选择一路作为输入。算数逻辑单元(alu)21执行相应的算术运算,输出寄存器17可以缓存alu的输出。
循环优化的一个重要指标是ii(initiationinterval),ii越小,性能越好。在本发明的一个实施实例中,上述改进的结构有利于循环的映射和提供低延时。
根据本发明实施例的方法,本发明对提出的全连接控制网络20和使用影子控制寄存器14的理由陈述如下:
1.每次循环的迭代,依然采取高效的预测执行。因此pe需要控制端口尽可能早的知道条件是否满足,这对pe之间控制信号的传输提出了低延时的要求。因此,对于控制信号,本发明提出了全互连的结构;
2.当循环迭代条件不满足时,应该及时终止循环的继续执行来保证正确性,并提高效率、减小能耗。终止循环的使能信号不仅要终止本次迭代,也要能终止接下来的迭代,这要求控制信号有很高的扇出;
3.本发明所述改进的结构,1位的全连接和1位的影子控制寄存器通过实施实例表明并未带来过多的面积和功耗开销;
4.结构的改进可以兼容fullpredication,在处理分支结构上也具有良好的性能,该结构是在传统结构的基础上改进而成,具有通用性。
图3为循环边界确定的一个示例,循环边界确定描述的是在编译器间就能分析得到循环的迭代次数,现有处理循环边界固定的最佳方法是通过循环展开技术。
对比图3,在本发明的一个实施实例中,图4展示的是循环边界不确定的一种简单应用。为了阐述本发明的映射过程,图5给出了2x2的pea映射结构图,包含4个pe单元。每个pe内部包含pe使能端口51(对应图2中的端口12),影子控制寄存器sreg52,和一个本地寄存器53。黑色实心箭头表示32-bit数据互连,空心箭头表示1-bit的控制全连接网络。
基于以上硬件结构,本发明的目的在于将循环控制基本块和循环体基本块同时映射在pea上,解决循环边界不确定的问题,最大程度提高性能,降低功耗。
在图5所示控制信号全连接网络的硬件结构上,以下详细介绍将循环边界不确定的图4采用动态循环边界静态调度的方法映射。
如图6所示,下面将详细阐述各个步骤。
在本发明提供的实施例中:
在循环分割步骤,将循环分成循环控制基本块basic1(图7的54)和循环体基本块basic2(图7的55)。
构建数据流图dfg步骤,在每个基本块内,都包含各自的dfg,图7中实心箭头表示dfg的数据依赖关系。
在构建控制流图cfg步骤,在两个基本块之间(54和55)之间存在控制依赖关系,如图7中的空心箭头所示。对应着中间源(ir,intermediaterepresentation)的goto语句。
在本发明的一个实施例中,节点
在构建混合数据控制流图cdfg步骤,通过将循环控制基本块basic1和循环体基本块basic2之间的控制依赖关系转换成节点之间的控制依赖(如图8中,节点p到节点d),同时基本块basic1和basic2之间如果存在数据依赖关系,就得加上数据依赖相关的边(如图8中,节点i到节点d)。
在本发明的一个实施例中,为了清晰描述嵌套循环中的控制流的前后关系,将cdfg的vh节点划分为三个部分,vh=vo∪vp∪vi.在图8中,vp点集中包含节点p,vo包含基本块basic1中除了节点p的部分,即节点i和节点a.vi点集包含循环体基本块basic2中的节点d.在图8的cdfg中,存在f:pi→ui这样的控制依赖,即预测节点p控制循环体基本块(包含节点d)的运行。
在映射步骤,将图8的cdfg混合数据控制流图中的算子映射到pea上。图9是通用可重构处理器的tec(timeextendedcgra)图,p0是初始化状态,各个pe是使能的。在cycle1时,节点i和节点a执行load操作。cycle2时,节点p执行循环判断操作,判断结果p1输出到影子寄存器sreg,如果p1返回true,pe3将在cycle3时执行计算。否则pe3不会执行计算。
在优化步骤,如果循环比较操作(节点p)与循环体基本块的执行没有数据依赖关系,可以将循环控制基本块预测执行。如图9所示,下次迭代的节点i和节点a在cycle2被预测执行。循环判断节点的p不仅控制着本次迭代循环体(节点d)的执行,也控制着之后某次迭代的控制基本块(cycle3时刻的pe0和pe1)的执行。这能保证迭代在某个时刻被及时终止,由于循环体vi的执行由本次迭代的pi∈vp控制。在映射中,存在f:pi→p′i,在时域上,下次迭代的p′i总是滞后pi的执行,即pi的预测结果能控制下次迭代p′i是否执行,而p′i控制下次迭代的vi′的执行。如果有多层嵌套循环,依次链式传导迭代。通过优化步骤,本发明的实施例ii减少为1。
在本发明的一个实施例中,基于改进的硬件结构,图10提出了新的指令集。字段60表示图2中端口12,使能端的初始值用p0表示;字段61表示影子控制寄存器的值(sreg),它来源于条件判断的结果,可以输出到其它所有pe,指令取址单元和自己的数据选择器;字段62表示五位的运算符,包括算术运算,逻辑运算和位运算;字段63和字段64是pe两个32-bit的数据输入端的地址,可以是来自router、sharedmemory、registerfile直接寻址和来自router、sharedmemory、registerfile的间接寻址;后面24位是其它预留位。
通过15个benchmarks的仿真测试,本发明提供的混合循环边界静态调度的方法平均达到2.2x的加速,19%的性能提升和更低的功耗。
本发明通过对循环实例的映射,和现有最高效的基于状态的全预测相比较,平均可以提高2.28×加速,相比较于处理嵌套控制流的laser方法,动态循环边界静态调度和混合循环边界静态调度在性能上,分别提升24%和38%的性能并达到更低的能耗。
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变化或修改,这并不影响本发明的实质内容。在不冲突的情况下,本申请的实施例和实施例中的特征可以任意相互组合。
- 还没有人留言评论。精彩留言会获得点赞!