一种基于二叉树的人体行为识别方法与流程
本发明涉及计算机视觉领域,更具体地,涉及一种基于二叉树的人体行为识别方法。
背景技术:
基于特征的人体行为识别方法的方法流程大致包括轨迹采样、特征提取、特征编码和行为分类等步骤。在轨迹采样和特征提取阶段,现有的方法中表现良好的是改进密集轨迹方法(idt,improveddensetrajectory),这个方法会密集采样特征点并对其进行跟踪,选取显著的轨迹,再提取出轨迹的特征描述符。该方法能够根据视频帧中的rgb特征提取出显著的轨迹,以及具有表现力的描述符mbh(运动边界直方图)、hog(方向直方图)、hof(光流直方图)。然而,idt方法在采样时没有考虑到光流特征,以及描述符也没有考虑到轨迹之间的相互关系,因而准确率仍未达到令人满意的水平。除此之外,在编码该方法时也是简单地把所有特征进行编码,而研究表明人的运动可以分为运动主体和该运动主体的辅助部分,因此在编码的时候可以将特征分为两类,做到更加细致地提取特征的中层语义。
技术实现要素:
本发明为克服上述现有技术采样时没有考虑到光流特征,描述符没有考虑到轨迹之间的相互关系以及对运动部分的特征提取不够细致的缺陷,提供一种基于二叉树的人体行为识别方法。
为解决上述技术问题,本发明的技术方案如下:一种基于二叉树的人体行为识别方法,包括与以下步骤:
s1:输入视频,对视频帧中的特征点进行采样,对采样后的特征点进行跟踪,生成轨迹,再对轨迹进行筛选;
s2:计算筛选后轨迹的显著值,提取出综合显著轨迹;
s3:根据求得的综合显著轨迹计算轨迹的特征描述符,用来量化轨迹特征;
s4:根据轨迹特征将轨迹进行分类,并利用谱聚类方法将视频的轨迹分类到若干集合中,即分类到二叉树节点中,构造中层语义二叉树;
s5:对若干集合内的轨迹进行编码得到编码向量,采用子空间随机投影对编码向量进行降维,并将若干集合的降维后的编码向量进行融合,用来表示一个视频;
s6:利用线性核的svm对视频进行分类,得到视频行为的类别标签并输出结果。
优选地,s1的具体步骤为:
s11:利用3×3的sobel算子计算视频帧中每一个像素点的梯度,得到该视频帧两个方向上的梯度矩阵dx和dy;
s12:选取像素点p的3×3邻域s(p)内的梯度自相关矩阵的最小特征值作为该像素点的特征值;
s13:选择特征值大于特征点阈值的像素点作为特征点,阈值大小为所有像素点的特征值中最小的值的倍数;
s14:按照设定的步长将视频帧划分为网格,并对其中存在的特征点进行采样,选取特征值大于预设的起点特征点阈值的特征点作为轨迹的起点;
s15:以缩放因子对原始视频帧进行八个尺度的缩小,生成八层金字塔;
s16:采用
其中,pt=(xt,yt)表示第t帧处的采样点,x表示横轴上的值,y表示纵轴上的值,m是中值滤波核,w是
s17:根据轨迹的运动位移来筛选轨迹,分为x轴和y轴方向上的两个指标,为:
其中,
优选地,步骤s11至s14是在八层金字塔的八个尺度空间上进行。
优选地,为了防止运动发生漂移,本方法对特征点跟踪轨迹进行截断:设置轨迹长度l,超过视频跨度阈值便不再追踪,若在该邻域没有追踪点,将该特征点纳入追踪点中进行追踪,一条从第t帧开始生成的轨迹可以被表示成:
tt=(pt,pt+1,...,pt+l-1,pt+l)
令轨迹形状作为特征描述符,表示为trajshap’:
trajshape'=(△pt,...,△pt+l-1)
△pt=(pt+1-pt)=(xt+1-xt,yt+1-yt)
规范化的轨迹形状为:
其中i表示第i帧。
优选地,步骤s2的具体步骤包括:
s21:分别提取轨迹的灰度显著值以及光流显著值;
灰度显著值:
diffg(px)=|g(px)-g(a(px))|
其中,g()为高斯滤波后的灰度值,
a(px)={(u,v)||ux-u|≤△u,|vx-v|≤△v}
△u=min(ux,w-ux),△v=min(vx,h-vx),ux表示第x帧的横坐标的值,vx表示第x帧纵坐标的值,w与h分别为视频帧的宽与高;
光流显著性:
其中,hj(px)为在px处的光流直方图hof中的第j个bin值,而
s22:通过灰度显著值以及光流显著值得到视频帧的综合显著值:
其中,β为权重;定义一个视频中的以特征点pi开始追踪的轨迹为ti=(pi1,pi2,...,pi|l+1|),其显著值定义为该轨迹上所有特征点的显著值的平均值,sg(ti)为其灰度显著值,so(ti)为其光流显著值,sc(ti)为其综合显著值,分别为:
s23:根据综合显著值提取出显著轨迹。
优选地,s23中提取出显著轨迹的方法为:
tsalient={ti|ti∈twarped,sc(ti)>thresholdsaliency(τi)}
其中,显著轨迹阈值为:
优选地,步骤s3根据求得的综合显著轨迹计算轨迹的特征描述符的具体步骤包括:
s31:计算第从第i帧处开始采样的轨迹在第f帧(i≤f≤i+l)的采样点平均位置值为:
其中,n表示相同起始帧和采样尺度的轨迹数目,
s32:计算从第i帧处开始采样的第n轨迹在第f帧的采样点相对于平均位置的位移为:
△rin(f)=pin(f)-ai(f)
对相对位移进行归一化处理:
s33:由归一化处理结果得到第i帧处开始采样的第n条轨迹的均衡描述符:
优选地,步骤s4的具体步骤包括:
s41:利用轨迹之间的欧氏距离d作为轨迹之间的相似度,并对欧氏距离采用高斯核化;
s42:采用归一化切割n-cut对轨迹聚类,获得离散解;
s43:利用k均值方法对特征向量组成的矩阵e进行处理,从而获得每一条特征的类别;
s44:利用
s45:将行为视频显式地划分为语义上的两类特征,其中一类为行为的主体部分,另一类则为辅助主体部分的人、物、或其他运动部分。
优选地,步骤s41中轨迹之间的相似度为:
wij=exp(-γd(ti,tj)2)
其中,轨迹相似矩阵w是非负对称矩阵,
优选地,步骤s5的具体步骤为:
s51:采用子空间随机投影方法rp处理若干集合的fv向量,随机投影后其维度为r的n条数据的集合yn×r为:
yn×r=xn×drd×r
其中,xn×d为n条d维原始数据的集合,rd×r为随机生成的转换矩阵,r即随机投影因子,其下限为数据条数n的对数,将原始高维空间中两个向量的欧氏距离记作||x1-x2||,在随机投影之后,欧氏距离为
s52:采用以不同概率p随机生成转换矩阵r的元素,为:
三个维度为d的费舍尔向量fv被降低至维度为r的数据空间,并最终进行特征融合,融合成为3r视频表示。
与现有技术相比,本发明技术方案的有益效果是:本发明利用了视频中的光流信息以及轨迹之间的相互关系,在改进密集轨迹idt的基础上提出整流密集轨迹以及均衡描述符,通过融合光流显著性和灰度显著性,选取更加具有表现力的轨迹,移除背景的干扰;同时根据轨迹之间的相互关系构建均衡描述符,显式地表示轨迹之间位置和动作关系,便于后续构建中间语义。另一方面,由于人体运动基本可以划分为两个部分,而大部分方法都忽视这一细节,为了充分利用该语义信息,本发明方法提出二叉树的编码方法,将视频的特征分别表示成第一层的全局信息特征和第二层的运动主体特征和运动辅助特征,显式地表示视频的中层语义,提高识别准确度。
附图说明
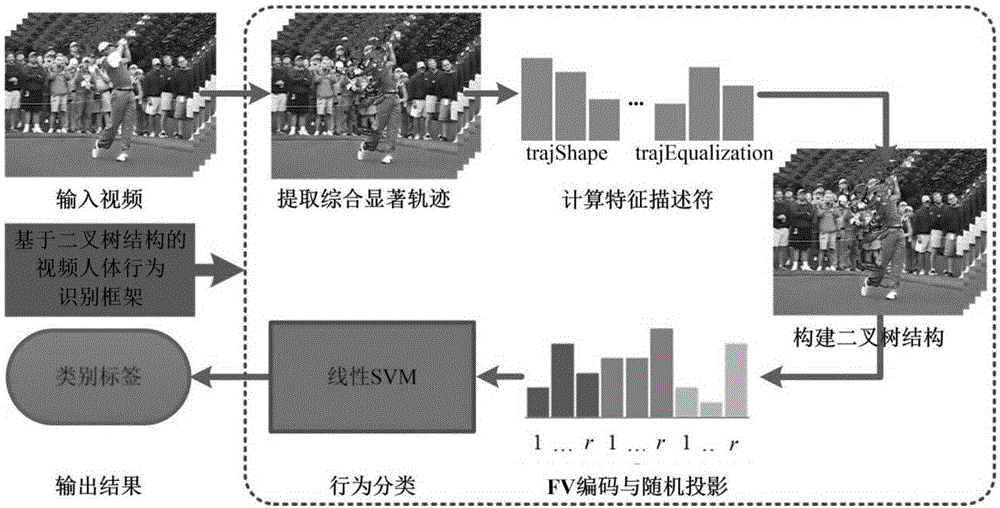
图1为本发明基于二叉树结构的视频人体行为识别研究框架图。
图2为本发明综合显著轨迹的提取流程图。
图3为本发明轨迹均衡描述符示例图。
图4为本发明ucfsports数据集中两个diving视频中轨迹聚类效果的连续四帧可视化图。
图5为本发明三个节点的fv经由随机投影生成视频表示示意图。
图6为本发明基于二叉树结构的识别方法在ucfsports数据集上的混淆矩阵图。
图7为基于二叉树结构的识别方法在hmdb51数据集上的混淆矩阵图。
其中,图2(a)为原始视频;图2(b)为视频灰度显著值;图2(c)为视频光流显著值;图2(d)为视频综合显著值;图2(e)为整流密集轨迹;图2(f)为综合显著轨迹;图5(g)为三个树节点的fv;图5(h)为随机投影后的特征向量;图5(i)为三个树节点的特征向量融合。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
下面结合附图和实施例对本发明的技术方案做进一步的说明。
实施例1
图1为本发明基于二叉树结构的视频人体行为识别研究框架图,其具体流程包括:
s1:输入视频,对视频帧中的特征点进行采样,对采样后的特征点进行跟踪,生成轨迹,再对轨迹进行筛选;
s11:利用3×3的sobel算子计算视频帧中每一个像素点的梯度,得到该视频帧两个方向上的梯度矩阵dx和dy;
s12:选取像素点p的3×3邻域s(p)内的梯度自相关矩阵的最小特征值作为该像素点的特征值;
s13:选择特征值大于特征点阈值的像素点作为特征点,阈值大小为所有像素点的特征值中最小的值的倍数;
s14:按照设定的步长将视频帧划分为网格,并对其中存在的特征点进行采样,选取特征值大于预设的特征点阈值的特征点作为轨迹的起点;
s15:以缩放因子对原始视频帧进行八个尺度的缩小,生成八层金字塔,其中,s11至s14的过程分别在八层金字塔的八个尺度空间上进行;
s16:采用
其中,pt=(xt,yt)表示第t帧处的采样点,x表示横轴上的值,y表示纵轴上的值,m是中值滤波核,w是
tt=(pt,pt+1,...,pt+l-1,pt+l)
令轨迹形状作为特征描述符,表示为trajshap’:
trajshape'=(△pt,...,△pt+l-1)
△pt=(pt+1-pt)=(xt+1-xt,yt+1-yt)
规范化的轨迹形状为:
s17:根据轨迹的运动位移来筛选轨迹,分为x轴和y轴方向上的两个指标,为:
其中,
s2:计算筛选后轨迹的显著值,提取出综合显著轨迹;
s21:输入如图2(a)的原始视频,分别提取轨迹的灰度显著值以及光流显著值,如图2(b)和图2(c);
灰度显著值:
diffg(px)=|g(px)-g(a(px))|
其中,g()为高斯滤波后的灰度值,
a(px)={(u,v)||ux-u|≤△u,|vx-v|≤△v}
△u=min(ux,w-ux),△v=min(vx,h-vx),ux表示第x帧的横坐标的值,vx表示第x帧纵坐标的值,w与h分别为视频帧的宽与高;
光流显著性:
其中,hj(px)为在px处的光流直方图hof中的第j个bin值,而
s22:通过灰度显著值以及光流显著值得到视频帧的综合显著值:
其中,β为权重;定义一个视频中的以特征点pi开始追踪的轨迹为ti=(pi1,pi2,...,pi|l+1|),其显著值定义为该轨迹上所有特征点的显著值的平均值,sg(ti)为其灰度显著值,so(ti)为其光流显著值,sc(ti)为其综合显著值,分别为:
s23:根据综合显著值提取出如图2(f)所示的的显著轨迹:
tsalient={ti|ti∈twarped,sc(ti)>thresholdsaliency(τi)}
其中,显著轨迹阈值为:
s3:根据求得的综合显著轨迹计算轨迹的特征描述符,用来量化轨迹特征,其过程示意图如图3所示:
s31:计算第从第i帧处开始采样的轨迹在第f帧(i≤f≤i+l)的采样点平均位置值为:
其中,n表示相同起始帧和采样尺度的轨迹数目,
s32:计算从第i帧处开始采样的第n轨迹在第f帧的采样点相对于平均位置的位移为:
△rin(f)=pin(f)-ai(f)
对相对位移进行归一化处理:
s33:由归一化处理结果得到第i帧处开始采样的第n条轨迹的均衡描述符:
s4:根据轨迹特征将轨迹进行分类,并利用谱聚类方法将视频的轨迹分类到三个集合中,即分类到二叉树的三个节点中,构造中层语义二叉树;
s41:利用轨迹之间的欧氏距离d作为轨迹之间的相似度,并对欧氏距离采用高斯核化;轨迹之间的相似度为:
wij=exp(-γd(ti,tj)2)
其中,轨迹相似矩阵w是非负对称矩阵,
s42:采用归一化切割n-cut对轨迹聚类,获得离散解;
s43:利用k均值方法对特征向量组成的矩阵e进行处理,从而获得每一条特征的类别;
s44:利用
s45:如图4所示,二叉树的方法可以将视频特征划分为两部分将行为视频划分为语义上的两类特征,其中一类为行为的主体部分,另一类则为辅助主体部分的人、物、或其他运动部分。
s5:对三个节点的轨迹进行编码得到编码向量,采用子空间随机投影对编码向量进行降维,并将三个节点降维后的编码向量进行融合,用来表示一个视频,具体过程如图5所示:
s51:采用子空间随机投影方法rp处理三个节点的fv向量,随机投影后其维度为r的n条数据的集合yn×r为:
yn×r=xn×drd×r
其中,xn×d为n条d维原始数据的集合,rd×r为随机生成的转换矩阵,r即随机投影因子,其下限为数据条数n的对数,将原始高维空间中两个向量的欧氏距离记作||x1-x2||,在随机投影之后,欧氏距离为
s52:采用以不同概率p随机生成转换矩阵r的元素,为:
三个维度为d的fv被降低至维度为r的数据空间,并最终进行特征融合,融合成为3r视频表示。
s6:利用线性核的svm对视频进行分类,得到视频行为的类别标签,并输出结果。
在具体实施过程中,利用混淆矩阵cm(confusionmatrix)以及平均准确率map(meanaverageprecision)进行评价。
设该混淆矩阵为m,则其元素为:
其中,对角线上的数据表示每个行为类别被正确划分的比例,该数据越大则表示分类越准确,当其为一时,说明该行为类别分类完全正确。
平均准确率map(meanaverageprecision):其计算公式为:
其中,c为数据集的行为类别数目,mii为每类行为被正确识别的比率。平均准确率的值越大,说明该方法的整体分类效果越好。
实验结果:混淆矩阵如图6所示,本发明识别方法平均识别率在ucfsports为94.68%,图7中本发明识别方法平均识别率在hmdb51上为60.58%。实验结果表明,本发明识别方法取得较好的识别效果,与现有的方法比较,具有显著性的进步。
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!