基于社交网络推荐平台的数据融合排序方法与流程
本发明属于计算机
技术领域:
,更进一步涉及网络应用
技术领域:
中的一种基于社交网络推荐平台的数据融合排序方法。本发明可根据目标用户对数据融合排序推荐准确率、召回率、速度需求等,使用不同的特征计算方法分别处理数据的各个特征,得到每个数据的特征向量,将每个数据的特征向量输入神经网络构建的特征融合评分模型,得到每个数据的评分,对每个数据的评分进行排序,得到排序结果给目标用户推荐。
背景技术:
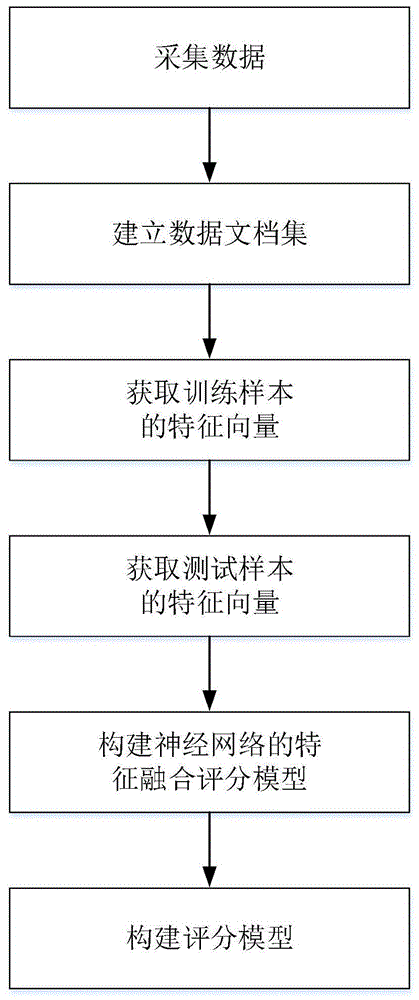
:数据融合排序技术是指利用计算机对文档观测数据进行特征提取,在一定准则下根据各特征的重要程度依据某种优化准则或算法组合来进行自动协调融合,产生对观测对象的一致性解释和描述,然后根据每个文档观测数据特征的综合表现进行排序,以完成所需的决策任务而进行的信息处理技术。实现数据的高效利用是推荐服务的重要问题,可以应用在社交网络推荐平台上。广东欧珀移动通信有限公司在其申请的专利文献“融合数据处理方法及装置”(专利申请号201711468874.x,申请公开号108090208a)中公开了一种融合数据处理方法。该方法的实施步骤是:第一步,所述线上系统获取多种异构数据源;第二步,所述线上系统使用所述价值模型集合处理所述多种异构数据源,得到每种异构数据源的统一评价指标;第三步,所述线上系统获取所述融合策略模型的损失量化评价指标;第四步,所述线上系统将所述每种异构数据源的统一评价指标和所述损失量化评价指标输入所述融合策略模型,得到所述多种异构数据源的融合排序推荐结果。该方法存在的不足之处是,统一评价指标无法全面评价数据的所有特征的重要程度,从而造成数据评价指标的普适性差,故将数据融合排序之后进行推荐的准确率和召回率低,不适用于社交网络推荐平台。南京邮电大学在其拥有的专利技术“一种融合社会化信息的个性化推荐方法”(专利申请号201610067099.6,授权公告号105740430b)中公开了一种融合社会化信息的个性化推荐方法。该专利技术的实施步骤是:第一步,构建用户-用户信任矩阵;第二步,构建项目-项目标签相似度矩阵;第三步,构建及训练模型;第四步,预测用户对于未知项目的偏好。该方法存在的不足之处是,采用的融合排序模型泛化能力低,不能迅速从训练集导出高效的特征集。当数据量达到一个饱和状态后,更多的数据并不能提高其性能,不适用于数据量巨大的社交网络推荐平台。技术实现要素:本发明的目的在于针对上述现有技术中数据评价指标的普适性差,采用的融合排序模型泛化能力低等局限,提出一种基于社交网络推荐平台的数据融合排序方法,以实现推荐准确率高与推荐召回率高情况下基于社交网络推荐平台的数据推荐。实现本发明目的的思路是:对数据进行数据预处理后,将数据信息归类为该数据文档,利用多相似度方法,量化分析数据文档各方面的特征,输入神经网络的特征融合评分模型算法求解数据文档的评分,将所有数据文档的评分进行排序,得到推荐的数据文档列表。本发明的步骤如下:(1)采集数据:采集社交网络平台的数据,将数据中的用户信息和项目信息分别存储到用户数据库和项目数据库中;(2)建立数据文档集:(2a)将采集的用户信息和每个项目信息依次进行数据清洗、数据规范处理;(2b)利用用户文档整理方法,将数据规范处理后的用户信息归类为用户文档;(2c)利用项目文档整理方法,将数据规范处理后的每个项目信息按列归类为该项目文档,将所有项目文档组成项目文档集;(3)获取训练样本的特征向量:(3a)从项目文档集的项目文档的项目时间中,随机选取早于用户请求时间的2000个项目文档,组成训练样本集;(3b)利用多相似度方法,得到训练样本集中每个项目文档的特征向量;(4)获取测试样本的特征向量:(4a)从项目文档集的项目文档的项目时间中,随机选取晚于用户请求时间的1000个项目文档,组成测试样本集;(4b)利用多相似度方法,得到测试样本集中每个项目文档的特征向量;(5)构建神经网络的特征融合评分模型:(5)构建神经网络的特征融合评分模型:(5a)搭建一个3层神经网络,其结构依次为:输入层→隐藏层→输出层;(5b)将神经网络中每个输入层权重均设置为满足标准差为0.1、均置为0的正态分布的随机数,将所有输入层权重组成第一个输入层权重向量a1,将神经网络中每个输出层权重均设置为满足标准差为0.1、均置为0的正态分布的随机数,将所有输出层权重组成第一个输出层权重向量b1;(5c)将第一个输入层权重向量a1、第一个输出层权重向量b1、训练样本集中每个项目文档的特征向量c依次输入到神经网络,得到第一个训练样本集中每个项目文档的预测标签值d1;(5d)将第一个训练样本集中每个项目文档的预测标签值d1和训练样本集中每个项目文档的真实标签值e输入到训练误差模型中,得到第一个训练样本集的训练误差f1;(5e)将第一个输入层权重向量a1和第一个训练样本集的训练误差f1,带入输入层权重向量公式,得到第二个输入层权重向量a2;(5f)将第一个输出层权重向量b1和第一个训练样本集的训练误差f1,带入输出层权重向量公式,得到第二个输入层权重向量b2;(5g)将第i个输入层权重向量ai、第i个输出层权重向量bi、训练样本集中每个项目文档的特征向量c依次输入到神经网络,得到第i个训练样本集中每个项目文档的预测标签值di;(5h)将第i个训练样本集中每个项目文档的预测标签值di和训练样本集中每个项目文档的真实标签值e,输入到训练误差模型中,得到第i个训练样本集的训练误差fi;(5i)将第i个输入层权重向量ai和第i个训练样本集的训练误差fi,带入输入层权重向量公式,得到第i+1个输入层权重向量ai+1;(5j)将第i个输出层权重向量bi和第i个训练样本集的训练误差fi,带入输出层权重向量公式,得到第i+1个输出层权重向量bi+1;(5k)判断迭代次数i是否等于500,若是,得到训练好的神经网络;否则,将迭代次数i的值加1后执行步骤(5g);(5l)将测试样本集中所有项目文档的特征向量、最后一个的输入层权重向量、最后一个的输出层权重向量输入评分模型,输出测试样本集中所有项目文档的评分;(6)构建排序模型:将测试样本集中所有项目文档的评分进行排序,选取评分前k高的k个项目文档,组成项目文档结果列表,k的值为{5,8,10,15};本发明与现有技术相比,具有以下优点:第一,由于本发明构建训练样本的特征向量或构建测试样本的特征向量时,利用多相似度方法计算训练样本或测试样本各方面的特征信息,克服了现有技术因利用单一相似度方法计算训练样本或测试样本各方面的特征信息导致训练样本或测试样本特征表征不准确的问题,使得本发明得到更加精确的数据融合评分。第二,由于本发明建立神经网络的数据融合评分模型,解决了现有数据融合评分技术中数据稀疏的问题,减小了数据融合的时间复杂度,使得本发明提高了数据融合的速度,实现了推荐准确率高与推荐召回率高情况下基于社交网络推荐平台的数据融合排序。附图说明图1为本发明的流程图;图2为本发明的构建神经网络的特征融合评分模型流程图;图3为本发明的仿真图。具体实施方式下面结合附图对本发明做进一步的描述。参照附图1,对本发明的具体实施步骤做进一步的描述。步骤1,采集数据。利用社交网络编程接口和爬虫工具采集社交网络平台的数据,将数据中的用户信息和项目信息分别存储到用户数据库和项目数据库中。步骤2,建立数据文档集。将采集的用户信息和每个项目信息依次进行数据清洗、数据规范处理。所述的数据清洗是指,对采集的每个用户信息和项目信息中的无效值和缺失值的码字设置为0,所述的数据规范是指,将每个用户信息和项目信息中所有格式的时间信息转换为协调世界时unix时间戳格式的时间信息。利用用户文档整理方法,将数据规范处理后的用户信息归类为用户文档。所述的项目文档整理方法是指,将数据规范处理后项目id、项目文本、项目时间、项目时间偏好向量、项目地点经度、项目地点纬度、项目文档的真实标签值依次录入项目文档的每一列;项目文档的真实标签值初始均置为0。利用项目文档整理方法,将数据规范处理后的每个项目信息按列归类为该项目文档,将所有项目文档组成项目文档集。所述的用户文档整理方法是指,提取数据规范处理后用户主题偏好向量、用户请求时间、用户时间偏好向量、用户地点经度、用户地点纬度依次录入用户文档的每一列。步骤3,获取训练样本的特征向量。从项目文档集的项目文档的项目时间中,随机选取早于用户请求时间的2000个项目文档,组成训练样本集。利用多相似度方法,得到训练样本集中每个项目文档的特征向量。所述的多相似度方法的具体步骤如下。第1步,从训练样本集或者测试样本集中选取一个项目文档的项目文本,利用贝叶斯推断的方法,从所选项目文本中得到每一个词对应每一个主题的条件概率分布;利用吉布斯抽样方法,根据每一个词对应每一个主题的条件概率分布,得到所选的项目文档主题分布概率前三高的主题,将项目文档主题分布概率前三高的主题组成所选的项目文档的主题偏好向量。所述的贝叶斯推断方法是指,根据贝叶斯定理,在有更多证据及信息时,更新特定假设的概率的方法。所述的吉布斯抽样方法是指,根据马尔可夫链蒙特卡尔理论,获取一系列近似等于指定多维概率分布来观察样本的方法。第2步,利用下述的动态内容偏好相似度公式,计算所选项目文档与用户文档的动态内容相似度。其中,c表示所选项目文档与和用户文档的动态内容相似度,n表示所选项目文档与和用户文档主题偏好向量的维数,∑表示求和操作,ui表示用户主题偏好向量的第i维主题偏好,ei表示所选项目文档的主题偏好向量的第i维主题偏好,表示求平方根操作,tu表示用户请求时间,te表示所选项目文档的项目时间。第3步,利用下述的时间偏好相似度公式,计算所选项目文档与用户文档的时间相似度。其中,q表示所选项目文档和用户文档的时间相似度,m表示时间偏好向量的维数,si表示用户时间偏好向量的第i维时间偏好,ri表示所选项目文档的时间偏好向量的第i维时间偏好。第4步,利用下述的空间相似度公式,计算所选项目文档与用户文档的空间相似度。其中,l表示所选项目文档和用户文档的空间相似值,log表示求以10为底对数函数值操作,exp表示求以e为底的指数函数值操作,xlat表示用户地点纬度,ylat表示所选项目文档的项目地点纬度,xlon表示用户地点经度,ylon表示所选项目文档的项目地点经度。第5步,将所选项目文档与用户文档的动态内容相似度,所选项目文档与用户文档的时间相似度,所选项目文档与用户文档的空间相似度组成所选项目文档的特征向量。第6步,判断是否选完所有项目文档的项目文本,若是,则得到训练样本集或测试样本集中每个项目文档的特征向量,否则,执行第1步。步骤4,获取测试样本的特征向量。从项目文档集的项目文档的项目时间中,随机选取晚于用户请求时间的1000个项目文档,组成测试样本集。利用多相似度方法,得到测试样本集中每个项目文档的特征向量。步骤5,构建神经网络的特征融合评分模型。(5.1)搭建一个3层神经网络,其结构依次为:输入层→隐藏层→输出层。(5.2)将神经网络中每个输入层权重均设置为满足标准差为0.1、均置为0的正态分布的随机数,将所有输入层权重组成第一个输入层权重向量a1,将神经网络中每个输出层权重均设置为满足标准差为0.1、均置为0的正态分布的随机数,将所有输出层权重组成第一个输出层权重向量b1。(5.3)将第一个输入层权重向量a1、第一个输出层权重向量b1、训练样本集中每个项目文档的特征向量c依次输入到神经网络,得到第一个训练样本集中每个项目文档的预测标签值d1。(5.4)将第一个训练样本集中每个项目文档的预测标签值d1和训练样本集中每个项目文档的真实标签值e输入到训练误差模型中,得到第一个训练样本集的训练误差f1。所述的训练误差模型是指。第一步,在训练样本集中随机选取两个项目文档项组成项目文档对。第二步,当两个项目文档中的第一个项目文档的当前迭代时预测标签值大于另一个项目文档的当前迭代时预测标签值时,将项目文档对的当前迭代时预测排序值设置为1,当小于时,将项目文档对的预测标签排序值设置为0。第三步,当两个项目文档中的第一个项目文档的真实标签值大于另一个项目文档的真实标签值时,将项目文档对的真实排序值设置为1,当小于时,将项目文档对的真实标签排序值设置为0。第四步,判断是否选完训练样本集中所有的项目文档,若是,则执行第五步,否则,执行第一步。第五步,按照下式,计算所有项目文档对的当前迭代时预测标签概率其中,表示第i个所有项目文档对的预测标签概率,e表示以自然常数e为底的指数操作,ri表示第i个项目文档对的预测排序值为1的所有项目文档对的个数。第六步,按照下式,计算所有项目文档对的真实标签概率:其中,p表示所有项目文档对的真实标签概率,q表示项目文档对的真实排序值为1的所有项目文档对的个数。第七步,按照下式,计算第i次时神经网络的训练误差:其中,fi表示第i个神经网络的训练误差,p表示项目文档对的真实标签概率,表示第i个项目文档对的预测标签概率。(5.5)将第一个输入层权重向量a1和第一个训练样本集的训练误差f1,带入输入层权重向量公式,得到第二个输入层权重向量a2。所述的输入层权重向量公式如下:其中,ai+1表示第i+1个输入层权重向量,1≤i≤500,且i为整数,ai表示第i个输入层权重向量,η为学习率,取值为0.001,fi表示第i个神经网络训练误差,表示求导操作。(5.6)将第一个输出层权重向量b1和第一个训练样本集的训练误差f1,带入输出层权重向量公式,得到第二个输入层权重向量b2。根据权利要求1所述的基于社交网络推荐平台的数据融合排序方法,其特征在于,步骤(5f)、步骤(5j)中所述的输出层权重向量公式如下:其中,bi+1表示第i+1个输入层权重向量,bi表示第i个输入层权重向量。(5.7)将第i个输入层权重向量ai、第i个输出层权重向量bi、训练样本集中每个项目文档的特征向量c依次输入到神经网络,得到第i个训练样本集中每个项目文档的预测标签值di。(5.8)将第i个训练样本集中每个项目文档的预测标签值di和训练样本集中每个项目文档的真实标签值e,输入到训练误差模型中,得到第i个训练样本集的训练误差fi。(5.9)将第i个输入层权重向量ai和第i个训练样本集的训练误差fi,带入输入层权重向量公式,得到第i+1个输入层权重向量ai+1。(5.10)将第i个输出层权重向量bi和第i个训练样本集的训练误差fi,带入输出层权重向量公式,得到第i+1个输出层权重向量bi+1。(5.11)判断迭代次数i是否等于500,若是,得到训练好的神经网络;否则,将迭代次数i的值加1后执行步骤5.7。(5.12)将测试样本集中所有项目文档的特征向量、最后一个的输入层权重向量、最后一个的输出层权重向量输入评分模型,输出测试样本集中所有项目文档的评分。所述的评分模型公式如下。其中,f表示测试样本集的项目文档的评分,g表示sigmod函数,m表示最后一个输出层权重向量的维数,wj表示最后一个输出层权重向量中第j维的输出层权重值,xi表示测试样本集的项目文档的第i维特征向量,n表示最后一个输入层权重向量维数,wi表示最后一个输入层权重向量中第i维的输入层权重值,bi表示输入层的偏置项,取值为1,bj表示输出层的偏置项,取值为1;构建该神经网络的特征融合评分模型的具体步骤如图2所示。步骤6,构建排序模型。将测试样本集中所有项目文档的评分进行排序,选取评分前k高的k个项目文档,组成项目文档结果列表,k的值为{5,8,10,15}。下面结合仿真实验,对本发明的效果做进一步的说明。1.仿真实验条件:本发明的仿真实验的运行环境是:处理器为intel(cr)celeron(r)cpu@2.50ghz,内存为2.00gb,硬盘为465g,操作系统为windows7,编程环境为python3.6,编程软件为spyder3。本发明的仿真实验在验证本发明在数据融合排序后进行推荐的推荐效果时所使用的数据集为kaggle.com收集的meetup数据集。meetup是一个社交网站,旨在将人们聚集在一起,并允许用户被推荐可能感兴趣的项目,在获取项目相关信息之后选择是否要在现实世界参加项目。meetup数据集包含455个用户的用户主题偏好向量、用户请求时间、用户时间偏好向量、用户地点经度、用户地点纬度和2279个项目的项目id、项目文本、项目时间、项目时间偏好向量、项目地点经度、项目地点纬度。2.仿真内容及其结果分析:仿真实验1:本发明的仿真实验1是采用本发明的方法与5种现有技术(基于热门项目的数据融合排序方法、基于项目协同过滤的数据融合排序方法、基于用户协同过滤的数据融合排序方法、基于线性组合评分的数据融合排序方法和基于上下文信息的数据融合排序方法),分别根据meetup数据集中各用户的信息,给出各用户一个项目评分。对各用户的项目评分进行排序,得到推荐的项目文档列表,并根据得到项目文档结果列表中目标用户需要的项目数量q、项目文档结果列表的项目数量m和目标用户需要的项目数量n,分别利用推荐率计算公式和推荐召回率计算公式计算推荐准确率p和推荐召回率r,即将10次重复运行的推荐准确率平均值和召回率平均值,作为最终的推荐准确率和推荐召回率,最后比较各方法的推荐准确率和推荐召回率,如图3所示,其中图3(a)表示各方法推荐准确率的对比图,推荐列表长度取5、8、10、15这四个取值,准确率取值分别为0.05,0,1,0.15,0.2,0.25,0.3,0.35,0.4这8个取值。图3(a)中以三角形标示的曲线表示基于热门项目的数据融合排序方法的准确率曲线。图3(a)中以菱形标示的曲线表示基于项目协同过滤的数据融合排序方法的准确率曲线。图3(a)中以四角星标示的曲线表示基于用户协同过滤的数据融合排序方法的准确率曲线,图3(a)中以正五边形标示的曲线表示基于线性组合评分的数据融合排序方法的准确率曲线。图3(a)中以正方形标示的曲线表示基于上下文信息的数据融合排序方法的准确率曲线。图3(a)中以圆形标示的曲线表示本发明的方法获得准确率曲线。图3(b)表示各方法召回率的对比图,图3(b)中推荐列表长度取值分别为5、8、10、15,召回率取值分别为0.05,0,1,0.15,0.2,0.25,0.3,0.35,0.4。图3(b)中以三角形标示的曲线表示基于热门项目的数据融合排序方法的召回率曲线。图3(b)中以菱形标示的曲线表示基于项目协同过滤的数据融合排序方法的召回率曲线。图3(b)中以四角星标示的曲线表示基于用户协同过滤的数据融合排序方法的召回率曲线,图3(b)中以正五边形标示的曲线表示基于线性组合评分的数据融合排序方法的召回率曲线。图3(b)中以正方形标示的曲线表示基于上下文信息的数据融合排序方法的召回率曲线。图3(b)中以圆形标示的曲线表示本发明的方法获得召回率曲线。仿真实验2:本发明的仿真实验2是采用本发明的方法与5种现有技术(基于热门项目的数据融合排序方法、基于项目协同过滤的数据融合排序方法、基于用户协同过滤的数据融合排序方法、基于线性组合评分的数据融合排序方法和基于上下文信息的数据融合排序方法),分别计算各方法的数据融合排序的时间,并对各方法得到的数据融合排序时间进行对比,对比结果如表1所示。表1六种数据融合排序方法的时间方法基于热门项目基于项目协同过滤基于用户协同过滤时间372s563s514s方法基于线性组合评分基于上下文信息本发明时间424s1272s306s由表1可以看出,基于热门项目的数据融合排序方法、基于项目协同过滤的数据融合排序方法、基于用户协同过滤的数据融合排序方法、基于线性组合评分的数据融合排序方法和基于上下文信息的数据融合排序方法数据融合排序的时间均较长,本发明方法数据融合排序的时间较短,说明了本发明能够更快速地进行基于社交网络推荐平台的数据融合排序。由图3(a)可以看出,本发明的准确率曲线位于基于热门项目的数据融合排序方法的准确率曲线、基于项目协同过滤的数据融合排序方法的准确率曲线、基于用户协同过滤的数据融合排序方法的准确率曲线、基于线性组合评分的数据融合排序方法的准确率曲线和基于上下文信息的数据融合排序方法的准确率曲线的上方,因此说明本发明的准确率是6种方法中最高的。由图3(b)可以看出,本发明的召回率曲线位于基于热门项目的数据融合排序方法的召回率曲线、基于项目协同过滤的数据融合排序方法召回率的曲线、基于用户协同过滤的数据融合排序方法的召回率曲线、基于线性组合评分的数据融合排序方法的召回率曲线和基于上下文信息的数据融合排序方法的召回率曲线的上方,因此说明本发明的召回率是6种方法中最高的。仿真结果表明,本发明进行基于社交网络推荐平台的数据融合排序后推荐准确率和召回率高,进行基于社交网络推荐平台的数据融合排序速度提高。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1