一种基于深度学习的隐写分析混合集成方法与流程
本发明涉及一种基于深度学习的隐写分析混合集成方法。
背景技术:
隐写技术是信息隐藏技术的一个重要分支,隐写术是以图像、文本等数字媒体作为载体,把要发送的秘密信息嵌入到载体信号内部,以不引起第三方注意的方式通过公共信道。隐写分析技术主要是揭示数字媒体中秘密信息的存在性。
图像隐写分析是判断图像中是否含有秘密信息。在隐写分析技术中,图像特征的提取十分重要,随着隐写技术的不断提高,特征的设计也越来越复杂,卷积神经网络因为其可以自动提取特征而备受关注。卷积神经网络是一类有效的深度学习框架,而深度学习是机器学习的一个重要分支,除了深度学习,机器学习还包含其他许多分类器,如xgboost、svm,它们都因训练速度较快、分类精度较高等特点而被广泛使用。在现有的分类方法中,卷积神经网络取得了不错的效果,但因为卷积神经网络匹配的sigmoid分类器结构简单,分类效果没有传统机器学习分类器好。
集成分类器通过对多个子分类器的分类结果进行某种组合来决定最终的分类结果,性能往往优于单一的分类器,集成学习的个体学习器有同质和异质两种情况,同质即所有个体学习器是同一个种类,异质即所有个体学习器不全是同一个种类,异质个体学习器增加了学习器之间的多样性,因此,我们通过卷积神经网络来提取图像特征,将xgboost、svm和knn分类器进行混合集成以提高分类精度。
技术实现要素:
本发明的目的是针对现有隐写分析的不足,提出一种基于深度学习的隐写分析混合集成方法。在使用卷积神经网络来提取图像相关特征并集成得到高维特征之后,用xgboost、svm和knn进行混合集成以提高模型的分类精度,更加适用于实际应用场景。
为达到上述目的,本发明采用如下技术方案:
一种基于深度学习的隐写分析混合集成方法,具体操作步骤如下:
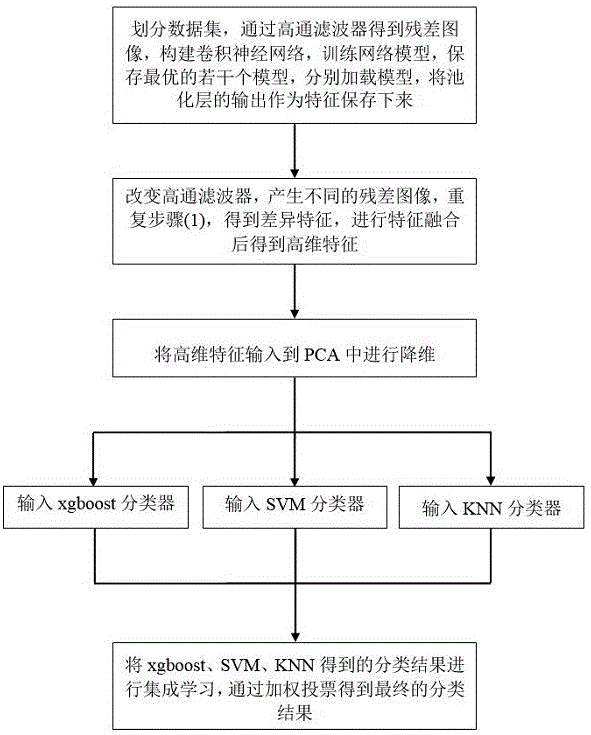
(1)划分数据集,通过高通滤波器得到残差图像,构建卷积神经网络,训练网络模型,保存最优的若干个模型,分别加载模型,将池化层的输出作为特征保存下来;
(2)改变高通滤波器,产生不同的残差图像,重复步骤(1),得到差异特征,进行特征融合后得到高维特征;
(3)将高维特征输入到pca中进行降维;
(4)将步骤(3)降维后的特征输入到xgboost分类器中进行分类;
(5)将步骤(3)降维后的特征输入到svm分类器中进行分类;
(6)将步骤(3)降维后的特征输入到knn分类器中进行分类;
(7)将步骤(4)、步骤(5)和步骤(6)得到的分类结果进行集成学习,通过加权投票得到最终的分类结果。
所述步骤(1)中,将数据集随机划分为测试集和训练集,从训练集中选取一部分数据作为验证集,通过高通滤波器得到噪声残差作为卷积神经网络的输入,卷积神经网络基本结构主要包括卷积层、批归一化层、relu层和池化层,训练网络模型,利用验证集选取效果最好的若干个模型保存,加载模型,将最后一个卷积模块的池化层输出作为特征保存。
所述步骤(2)中,通过改变高通滤波器,可以得到不同的残差图像,训练得到不同的模型,从而增加集成学习的多样性,得到更富于差异化的特征,将这些特征进行融合之后就得到表达能力更强的高维特征。
所述步骤(3)中,pca为主成分分析,将数据空间通过正交变换映射到低维空间,只保留包含绝大部分方差的维度特征,忽略包含方差几乎为0的特征维度,从而去除噪声和不重要的特征,实现降维。若高维特征直接输入到分类器中,会因为维度太高导致运行太慢,因此我们先将高维特征输入到pca中进行降维。
所述步骤(4)中,xgboost是在gdbt(梯度提升决策树)的基础上进行扩展和改进,xgboost在目标函数中加上了正则化项,防止模型过度复杂,降低了过拟合的可能性;损失函数是用泰勒展开式的二项逼近,而不是像gbdt的一阶导数;并且xgboost的树的节点分裂方式是经过优化推导后的,算法运行速度更快,准确率也相对更高一些。
所述步骤(5)中,svm指的是支持向量机,用来解决二分类问题的有监督学习算法,基本模型是在特征空间上找到最佳的分离超平面使得训练集上正负样本间隔最大,在引入了核函数之后svm也可以用来解决非线性问题,具有小样本下进行机器学习的优点。
所述步骤(6)中,knn也叫k近邻,算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在类别决策时,主要靠周围有限的邻近的样本,而不是靠判别类域的方法。
与现有技术相比,本发明具有如下的优点:
本发明方法把卷积神经网络当作特征提取装置,自适应的提取出图像相关特征,再输入到xgboost、svm、knn等机器学习分类器中进行分类,并将这三种分类器通过集成学习方法进行集成,在一定程度上提高了分类精确度。
附图说明
图1为本发明基于深度学习的隐写分析混合集成方法流程图。
图2为本发明基于深度学习的隐写分析混合集成方法集成分类器构成图。
图3为本发明基于深度学习的隐写分析混合集成方法准确率曲线图。
具体实施方式
为了便于本领域技术人员理解,下面将结合附图以及实施例对本发明进行进一步描述。
如图1所示,本实施例提出的一种基于深度学习的隐写分析混合集成方法,具体操作步骤如下:
(1)划分数据集,通过高通滤波器得到残差图像,构建卷积神经网络,训练网络模型,保存最优的若干个模型,分别加载模型,将池化层的输出作为特征保存下来;
(2)改变高通滤波器,产生不同的残差图像,重复步骤(1),得到差异特征,进行特征融合后得到高维特征;
(3)将高维特征输入到pca中进行降维;
(4)将步骤(3)降维后的特征输入到xgboost分类器中进行分类;
(5)将步骤(3)降维后的特征输入到svm分类器中进行分类;
(6)将步骤(3)降维后的特征输入到knn分类器中进行分类;
(7)将步骤(4)、步骤(5)和步骤(6)得到的分类结果进行集成学习,通过加权投票得到最终的分类结果。
本实例中,步骤(1)中,选取三种数据集进行实验,这三种数据集的嵌入率都为0.4,分别为wow数据集、s-uniward数据集和mvgg数据集。每种数据集有两万张图像,其中原始图像和加密图像各一万张,共一万对图像,随机选取其中的五千对作为测试集,五千对作为训练集,并从训练集中随机挑选一千对作为验证集;采用5种不同的卷积核生成的高通滤波器对训练集进行过滤,生成残差图像;整个卷积神经网络共包括六个卷积模块,每个卷积模块包括卷积层、批归一化层、relu层和池化层;将残差图像输入到卷积神经网络中进行训练,利用验证集得到分类效果最好的十个模型;加载模型进行测试,保存最后一个卷积模块的池化层输出为特征。
步骤(2)中,改变高通滤波器的卷积核,产生不同的残差图像,重复步骤(1)之后,将所有的特征进行融合得到高维特征,因为是5个不同的卷积核,每次选10个最优模型,因此最终高维特征维度为5*10*256=12800。
步骤(3)中,将12800维度的高维特征输入到pca中进行降维,主成分数n_components取0.99,表示降维后的数据能够保留99%的信息。
步骤(4)中,将步骤(3)降维后的特征输入到xgboost分类器中进行分类,其中树的最大深度设为7,学习率设为0.1,随机采样的比例subsample设为0.8,每棵树随机采样的列数的占比colsample_bytree设为0.8。
步骤(5)中,将步骤(3)降维后的特征输入到svm分类器中进行分类,采用rbf核函数。
步骤(6)中,将步骤(3)降维后的特征输入到knn分类器中进行分类,其中k取17。
步骤(7)中,如图2所示,将xgboost、svm和knn三种机器学习分类器进行集成,最后使用加权投票得到最终分类结果,其中xgboost、svm和knn的权重分别设置为2:3:1。
如图3所示,为三种数据集在不同的分类器下的分类准确率曲线,其中xgboost、svm、knn分别代表使用单个分类器得到的分类精度,而混合集成代表本发明提出的将xgboost、svm和knn进行集成得到的分类器。由图中曲线可知,基于本发明实施步骤,混合集成后的分类器的分类性能明显高于单个分类器。
- 还没有人留言评论。精彩留言会获得点赞!