一种从老挝-汉语篇章级对齐语料中抽取对齐语句的方法与流程
本发明涉及一种从老挝-汉语篇章级对齐语料中抽取对齐语句的方法,特别是一种基于lstm(longshort-termmemory长短期记忆网络)的从老挝-汉语篇章级对齐语料中抽取对齐语句的方法,属于自然语言处理和机器学习技术领域。
背景技术:
双语语料是统计机器翻译、跨语言检索、双语词典构建等研究领域的重要基础资源,双语语料的数量与质量很大程度上影响甚至决定了相关任务的最终结果。而平行句对的挖掘则是构建双语语料的关键技术,因而具有重要的研究价值。很多情况下,双语语料我们可以获得,但是得到的文本通常并不是以句子为单位对齐的,例如有些是以段落或者按照整篇文章来对齐的。这种情况下,就需要将这些不是以句子为单位对齐的语料整理成句子对齐格式,从而进行平行句对的抽取。
技术实现要素:
本发明要解决的技术问题是:提供一种从老挝-汉语篇章级对齐语料中抽取对齐语句的方法,用于解决从汉语-老挝语的对齐语料中抽取对齐语句,能够有效提高句子对齐的准确率。
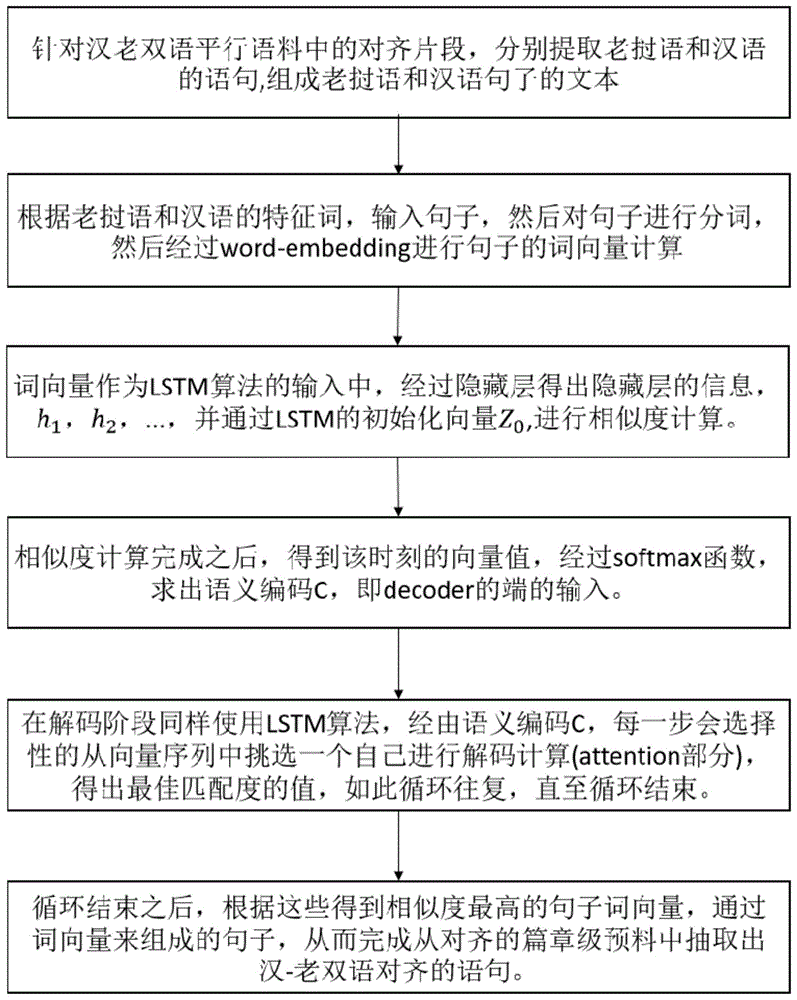
本发明采用的技术方案是:一种从老挝-汉语篇章级对齐语料中抽取对齐语句的方法,包括如下步骤:
step1,将汉-老双语语料先通过python代码使用正则表达式来进行噪声处理,然后对这些对齐片段进行数据集划分,其中,已对齐的训练集占90%,乱序测试集占10%;
step2,根据训练集以及测试集的句子,统计其中的互异的词组,以及每个词组出现的次数,经过word-embedding计算句子的词向量;
step3,将step2得出词向量作为lstm算法的输入,即此时lstm算法作为encoder部分,并将这些词向量作为encoder端的输入,encoder部分通过lstm算法的初始化向量进行相似度计算;
step4,每个词向量经由encoder部分输出,经过softmax函数,求出各个句子词向量的语义编码c,组成一个向量序列;
step5,将step4中得到的向量序列,作为decoder部分的初始输入,在decoder部分加入了attention机制,解码的时候,每一步都会选择性地从语义编码c的向量序列中挑选一个子集进行进一步的处理;所以在decoder部分中,每个时刻的输出作为下一时刻的输入,每一个输出,都能够做到充分利用输入序列携带的信息,以此类推,直到结尾;
step6,经过encoder与decoder部分的相似度的计算,得出相似度最高的句子词向量,通过词向量来组成的句子,从而完成从对齐的篇章级语料中抽取出汉-老双语对齐的语句。
具体地,所述step1中所述的对齐片段为经过噪声处理过后的对齐篇章语料。
具体地,所述step2通过python编码,对最初的篇章级对齐语料进行句子分词,通过代码实现单个句子老挝语句子以及中文句子的分词,并统计词数。
具体地,所述step3的具体步骤如下:
输入分出来的句子,将句子进行分词,经过word-embedding之后作为输入,输入到lstm中,然后经过隐藏层得出隐藏层信息h1,h2,...,在这个时候encoder部分的第一个时刻的hidden-state假设为z0(初始变量),然后使用z0和h1,h2,...进行相似度计算,得出各个时刻的a10,a20,a30,…aij,其中,a的下标i表示encoder中隐藏层信息的下标,a的下标j表示神经网络的初始变量的下标。
具体地,所述步骤step5在decoder阶段每一步解码,都能够有一个输入,对输入序列所有隐藏层的信息h1,h2,…ht进行加权求和,也就是每次在预测下一个词时都会把所有输入序列的隐藏层信息都看一遍,决定预测当前词时和输入序列的那些词最相关,attention机制代表了在解码decoder阶段,每次都会输入一个上下文的向量ci,隐藏层的新状态si根据上一步的状态si-1,yi,ci三者的一个非线性函数得出,如公式(1),其中ci为encoder阶段的每时刻输出状态的加权平均和,求解方式为公式(2),si-1,yi分别为decoder阶段的前一状态和前一次输出的预测值,这里hj为encoder阶段的每个时刻输出状态,aij为每个decoder阶段的输入i对应的hj的权重值大小;
si=f(si-1,yi,ci)(1)
具体地,所述步骤step6在经过相似度计算之后,通过词向量来组成的句子,从而完成从对齐的篇章级语料中抽取出汉-老双语对齐的语句。
本发明的有益效果是:
(1)该基于基于lstm的从老挝-汉语篇章级对齐语料中抽取对齐语句方法中,相对比单方面的encoder-decoder的算法模型在汉语-老挝语抽取中准确率有所提高。
(2)该基于lstm的从老挝-汉语篇章级对齐语料中抽取对齐语句方法中,使用了lstm算法,相比较其他算法,在特征提取的效果上有了比较不错的提高。
(3)该基于lstm的从老挝-汉语篇章级对齐语料中抽取对齐语句方法中,融入老挝语语法特征以及中文的语法特征,通过深度学习可以自动识别出来,相比于人工识别,速度更快,泛化性更强,省时省力。
附图说明
图1为本发明中的流程图;
图2为本发明所使用的lstm训练词向量的基本结构图;
图3为本发明attention机制的encoder-decoder模型示意图;
图4是本发明attention模型计算词向量示意图。
具体实施方式
实施例1:如图1-4所示,一种从老挝-汉语篇章级对齐语料中抽取对齐语句的方法,包括如下步骤::
step1,将汉-老双语语料先通过python代码使用正则表达式来进行噪声处理,然后对这些对齐片段进行数据集划分,其中,已对齐的训练集占90%,乱序测试集占10%;
step2,根据训练集以及测试集的句子,统计其中的互异的词组,以及每个词组出现的次数,经过word-embedding计算句子的词向量;
step3,将step2得出词向量作为lstm算法的输入,即此时lstm算法作为encoder部分,并将这些词向量作为encoder端的输入,encoder部分通过lstm算法的初始化向量进行相似度计算;
step4,每个词向量经由encoder部分输出,经过softmax函数,求出各个句子词向量的语义编码c,组成一个向量序列;
step5,将step4中得到的向量序列,作为decoder部分的初始输入,在decoder部分加入了attention机制,解码的时候,每一步都会选择性地从语义编码c的向量序列中挑选一个子集进行进一步的处理;所以在decoder部分中,每个时刻的输出作为下一时刻的输入,每一个输出,都能够做到充分利用输入序列携带的信息,以此类推,直到结尾;
step6,经过encoder与decoder部分的相似度的计算,得出相似度最高的句子词向量,通过词向量来组成的句子,从而完成从对齐的篇章级语料中抽取出汉-老双语对齐的语句。
进一步地,所述step1中所述的对齐片段为经过噪声处理过后的对齐篇章语料。
进一步地,所述step2通过python编码,对最初的篇章级对齐语料进行句子分词,通过代码实现单个句子老挝语句子以及中文句子的分词,并统计词数。
进一步地,所述step3的具体步骤如下:
输入分出来的句子,将句子进行分词,经过word-embedding之后作为输入,输入到lstm中,然后经过隐藏层得出隐藏层信息h1,h2,...,在这个时候encoder部分的第一个时刻的hidden-state假设为z0(初始变量),然后使用z0和h1,h2,...进行相似度计算,得出各个时刻的a10,a20,a30,…aij,其中,a的下标i表示encoder中隐藏层信息的下标,a的下标j表示神经网络的初始变量的下标。
进一步地,所述步骤step5在decoder阶段每一步解码,都能够有一个输入,对输入序列所有隐藏层的信息h1,h2,…ht进行加权求和,也就是每次在预测下一个词时都会把所有输入序列的隐藏层信息都看一遍,决定预测当前词时和输入序列的那些词最相关,attention机制代表了在解码decoder阶段,每次都会输入一个上下文的向量ci,隐藏层的新状态si根据上一步的状态si-1,yi,ci三者的一个非线性函数得出,如公式(1),其中ci为encoder阶段的每时刻输出状态的加权平均和,求解方式为公式(2),si-1,yi分别为decoder阶段的前一状态和前一次输出的预测值,这里hj为encoder阶段的每个时刻输出状态,aij为每个decoder阶段的输入i对应的hj的权重值大小;
si=f(si-1,yi,ci)(1)
进一步地,所述步骤step6在经过相似度计算之后,通过词向量来组成的句子,从而完成从对齐的篇章级语料中抽取出汉-老双语对齐的语句。
双语语料库最为作为自然语言研究领域的重要语言资源,语言信息处理的研究深入,在语料的获取,处理有了长足的进步。本发明主要融合了老挝语语言学特征到算法模型中,在模型的使用中选择了多种模型融合的方法,提高识别精度,使用attention机制(注意力机制),并拿lstm作为encoder-decoder(编码器-解码器)。首先将篇章级对齐的语料使用python进行正则表达式的处理,去除掉噪音数据,并作为输入,由于老挝语与中文的句子排序是一致的,所以可以先将篇章级的语料处理为单个的对齐语句,之后将对齐的语句进行拆分。之后将这些对齐的语句进行分词,将分词的此语作为lstm的输入,通过保留lstm编码器对输入序列的中间输出结果,训练一个模型来对这些输入进行选择性地学习并且在模型输出时将输出序列进行关联,从而从双语语料库中抽取出平行句对。本发明在老挝语平行句对抽取上有一定的研究意义。
以上结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!