一种基于SVM和HMM的老挝语机构名称识别方法与流程
本发明涉及一种基于svm和hmm的老挝语机构名称识别方法,属于自然语言处理和机器学习技术领域。
背景技术:
命名实体识别一直是自然语言处理领域的重要任务,在信息检索、机器翻译等技术中占有举足轻重的地位。机构名称由于具有结构复杂、长短不一、组成多样的特点,是命名实体七大类中最难识别的一类。目前的机构名称识别的方法主要是以下三种:基于规则和词典的方法、基于机器学习的方法。基于规则和词典的方法,需要依赖专家知识,需要大量标记内容,耗时耗力。单独的基于机器学习的方法虽然比较容易搭建,但是准确率不太高。
技术实现要素:
本发明的目的是提供一种基于svm和hmm的老挝语机构名称识别方法,根据老挝语机构名称识别研究的现状,本发明主要使用基于机器学习的方法并融合一些老挝语语言学的特征,再用基于规则方法加以辅助识别,结合了现有技术中两种算法的优点,有助于准确率的提升。
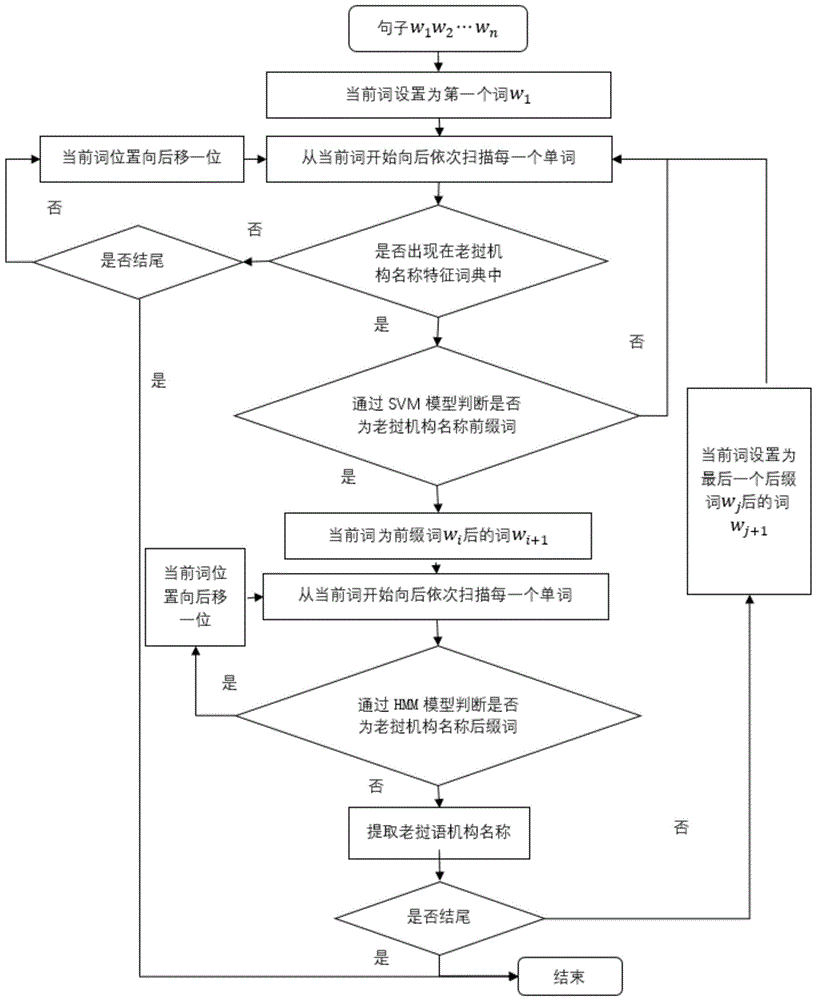
本发明采用的技术方案是:一种基于svm和hmm的老挝语机构名称识别方法,具体步骤如下:
step1、根据老挝语机构名称特征词在前的特点,将老挝语机构名称分为两类,单个词就是一个实体的称为简单机构名称,定义形式为s,多个词组成的一个实体名称称为复杂的机构名称,定义形式为s+p,其中s为特征词,也称前缀词,p为修饰词,也称后缀词;
step1.1、根据形式定义,将老挝语机构名称命名实体语料库中所有特征词s提取为一个特征词典;
step2、将当前词设置为第一个词;
step3、从当前词开始向后扫描,判断当前词是否出现在step1.1中的特征词典中,此时有两种情况:
第一种情况是当前词出现在step1.1中的特征词典中:
当第一种情况时,说明当前词可能为老挝语机构名称前缀词,根据特征向量转换过程将当前词转换为特征向量,然后执行步骤4;
第二种情况是当前词没有出现在step1.1中的特征词典中:
当第二种情况时,判断当前词是否为结尾,若是则结束,若否则当前词位置向后移一位,重复本步骤,继续向后扫描判断,直至结尾;
step4、根据出现在step1.1中的特征词典中的词的特征向量使用svm模型对其进行判断,是否为老挝语机构名称前缀词,如果是,则继续下面步骤,如果不是,则将当前词位置后移一位并返回step3;
step5、将当前词设置为前缀词wi后一个词wi+1,使用融合了多个老挝语机构名构词特征的隐马尔科夫模型对当前词wi+1进行判断,此时有两种情况:
第一种情况是当前词是老挝语机构名称后缀词:
当第一种情况时,说明当前词为老挝语机构名称后缀词,那么当前词位置后移一位,重复此步骤的判断;
第二种情况是当前词不是老挝语机构名称后缀词:
当第二种情况时,则提取前缀词wi到当前词wj+1的前一个词wj中的所有词,此时词wi…wj为一个完整的老挝语机构名称实体,然后执行step6;
step6、判断当前词wj+1是否为最后一个词,如果不是,则将当前词位置设置为wj+1,并返回step3,继续向后扫描,如果是,则循环结束。
本发明的有益效果是:
1、本发明的基于svm和hmm的老挝语机构名识别方法,与单独使用svm模型实现机构名识别方法相比较,精确率、召回率、f值都显著提高。
2、本发明的基于svm和hmm的老挝语机构名识别方法,将老挝语机构名形式化为简单机构名称s,或者复杂机构名称s+p。分两步识别一个完整的老挝语机构名称。
3、本发明的基于svm和hmm的老挝语机构名识别方法,将老挝语机构名称前缀词(s)的识别抽象为一个二分类问题,而svm模型善于处理二分类问题,所以使用svm模型来识别老挝语机构名称前缀词。
4、本发明的基于svm和hmm的老挝语机构名识别方法,将老挝语机构名称的后缀词(p)识别抽象成一个hmm模型的解码问题,并在模型中融合了多个老挝语机构名构词特征,比传统使用hmm模型识别机构名称的精确率提高许多。
附图说明
图1是本发明的流程图。
具体实施方式
为了更详细的描述本发明和便于本领域人员的理解,下面结合附图以及实施例对本发明做进一步的描述,本部分的实施例用于解释说明本发明,便于理解的目的,不以此来限制本发明。
实施例1:如图1所示,一种基于svm和hmm的老挝语机构名称识别方法,具体步骤如下:
step1、根据老挝语机构名称特征词在前的特点,将老挝语机构名称分为两类,单个词就是一个实体的称为简单机构名称,定义形式为s,多个词组成的一个实体名称称为复杂的机构名称,定义形式为s+p,其中s为特征词(如大学、党委等),也称前缀词,p为修饰词,也称后缀词;
step1.1、根据形式定义,将老挝语机构名称命名实体语料库中所有特征词s提取为一个特征词典;
step2、将当前词设置为第一个词;
step3、从分词处理后的句子
step4、根据词w7的特征向量使用svm模型对其进行判断,是否为老挝语机构名称前缀词。如果是,则继续下面步骤。如果不是,则返回step3,从下一个词开始继续判断。经判断w7为老挝语机构名称前缀词。
step5、从前缀词w7后一个词w8开始扫描每一个词,使用融合了多个老挝语机构名构词特征的隐马尔科夫模型对当前词w8进行判断,模型最后识别出w8和w9都为老挝语机构名称后缀词,w10不是老挝语机构名称后缀词。此时将w7、w8、w9提取出来,
step6、判断当前词w10是否为最后一个词,如果不是,则从w10开始,返回step3开始判断,继续向后扫描直至结束。如果是,则循环结束。
此时通过step3中的判断,w10、w11和w12都不存在于step1.1中的特征词典中,由于已经到结尾处,所以结束判断。
上面结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!