一种基于k均值聚类的隐私信息保护方法与流程
本发明属于机器学习领域,涉及一种基于k均值聚类的隐私信息保护方法。
背景技术:
随着互联网技术的快速发展,ai技术的再次兴起让机器学习在信息行业得到了广泛的应用,例如医学诊断、搜索引擎、计算机视觉、检测信用卡欺诈、证券市场分析等。机器学习的基本思想是模拟人类的学习行为,通过对大量数据的分析和学习,来获取新的知识或技能,用以改善已有组织结构的性能。更精确的机器学习结果需要更大的数据库作为学习的对象,然而大量的数据包含了用户的隐私信息,这给机器学习的发展带来了新的挑战和机遇。因此在机器学习领域实现数据的安全计算,是当前信息行业急需解决的重要问题,具有重要的理论意义和应用价值。
最近几年,基于大数据的机器学习是目前信息行业最热门的领域之一。数据的爆炸性增长转变了传统机器学习的窘境,大量的数据存储丰富了机器学习的学习资源,给机器学习带来了巨大的发展机遇。在这种数据规模下进行机器学习,可以利用数据的特性更好地帮助各行各业进行发展规划。例如,在医疗方面,根据病人的病例数据学习得到疾病诊断模型;在人脸识别方面,用含有人脸的图像或视频流,通过对图像的检测和跟踪进行身份识别;在商业方面,根据消费者的消费特征,确定商场的主消费人群等。
k均值聚类算法是机器学习中“无监督学习”的一种,通过对无标记数据进行分析学习,发现数据之间存在的某种关系,从而实现对数据的划分或分组处理。在该算法中,训练样本的标记信息是未知的,目标是通过对无标记的信息数据的学习,发现数据中的内在规律,进而对数据进行划分、归类。由于其简单、有效的特性,k均值聚类算法在聚类算法中是比较常用的一种算法,可以用于新闻聚类、用户购买模式、图像与基因技术等领域。
大数据与机器学习的结合发展是信息技术行业的一大优势,但同时也是未来发展的一大挑战。因为大数据的产生源于我们的生活,包含了大量的隐私数据,对于用户的隐私保护已经是社会发展的焦点。为了解决大数据下的计算问题,云计算服务得到许多大、小企业的青睐,由于云服务器的不可信特性,使得用户的隐私安全问题更加严峻。因此,如何在保证数据安全的前提下进行机器学习,已经是当前机器学习发展的重要问题,研究具有隐私保护的机器学习方法是信息行业的发展趋势,具有重要的理论意义和应用价值。
通常情况下,为了防止隐私信息的泄露,用户在上传数据之前会先进行加密,然后把密文上传到云服务器用于机器学习,然而加密数据的方法虽解决了隐私安全的问题,但对密文进行机器学习的运算带来了一定的难度。全同态的加密算法支持密文运算,但是由于全同态的效率很低,导致该加密方法在实际场景中并不实用。
在很多实际的应用场景中,为了保证数据的安全性,数据提供者仅提供训练数据样本的密文形式,云服务器只能在密文上进行机器学习的训练算法,要求在机器学习的过程中,云服务器不能学习到用户隐私信息,数据提供者承担尽可能少的计算工作量。另外,为了保证机器学习的效率,在解决方案中,降低通信成本也是一个要求。
技术实现要素:
针对现有技术的不足,本发明提供一种基于k均值聚类的隐私信息保护方法,采用线性同态加密算法lhe结合加法同态加密算法paillier对数据进行加密,得到密文数据,利用云服务端提供的计算服务实现对密文数据进行k均值聚类,得到密文聚类结果,客户端对密文聚类结果进行解密,得到明文聚类结果。本发明云服务端不获取用户的任何隐私信息,在实现聚类算法的同时保证用户的隐私信息安全,数据分析过程中数据信息不泄露,不仅有效地提高了用户数据的安全性,还大幅度地降低了客户端与云服务端之间的通信量,降低了通信成本,提高了机器学习效率,更适合应用到实际场景中去。
本发明采用如下技术方案:
一种基于k均值聚类的隐私信息保护方法,包括以下步骤:
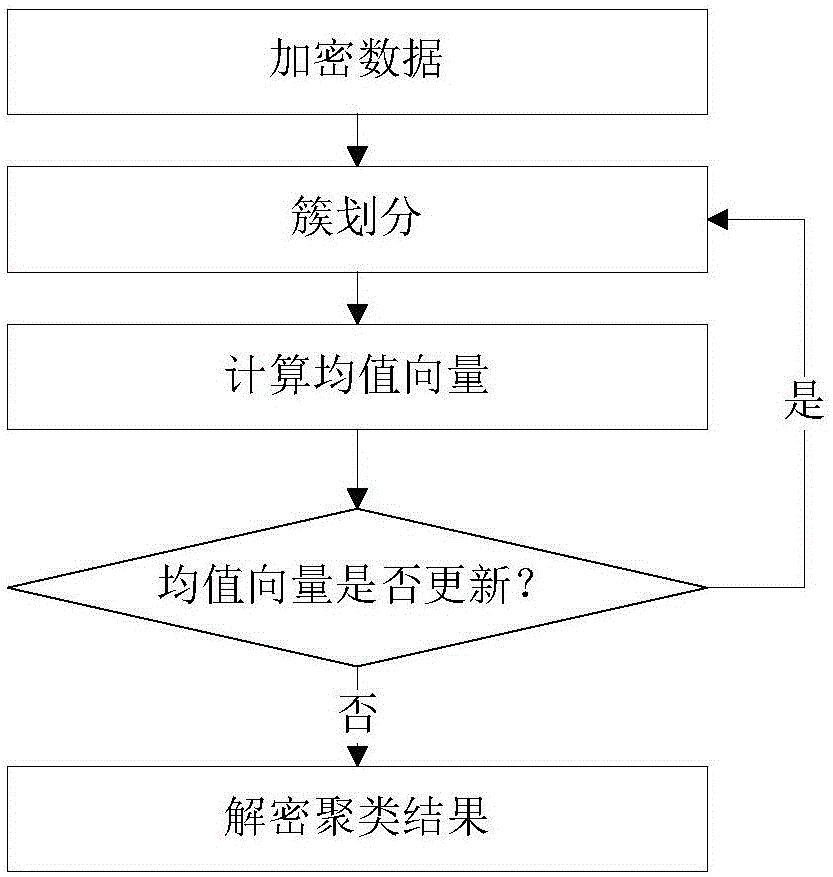
s1、客户端采用线性同态加密算法lhe结合加法同态加密算法paillier对数据进行加密,得到密文数据,并将密文数据上传至云服务端。
s2、云服务端对密文数据进行k均值聚类,得到密文聚类结果。
s3、云服务端将密文聚类结果返回客户端,客户端对密文聚类结果进行解密,得到明文聚类结果。
进一步地,假设客户端拥有一个包含n特征数据的数据集,用矩阵a表示:
其中,矩阵a中每行的向量ai(1≤i≤n)表示一个特征向量(又称“数据项”),每一个特征向量包含d个特征值。
聚类算法将数据集a划分为k个聚类簇,每个聚类簇的聚类中心用uρ表示,每一个聚类中心uρ包含d个数据元素,聚类中心集用矩阵u表示:
其中,1≤ρ≤k;
步骤s1中客户端对数据进行加密的过程包括:
s11、选择两个素数p和q,其中p、q的值不相等但是长度相等,计算n=pq,λ=lcm(p-1,q-1),其中lcm表示最小公倍数。
s12、随机选择一个整数g满足gcd(l(gλmodn2),n)=1,其中gcd表示最大公约数,l(x)=(x-1)/n。
s13、利用paillier中的函数生成公钥pk={n,g},私钥sk={λ}。把公钥发送给云服务端,保留自己的私钥。
s14、对数据集a进行加密,对每一个特征值aij,选择一个随机数bij,则特征值aij的密文形式为enc(aij)=(aij-bij,[bij]),
s15、对聚类中心集u进行加密,初始化k个聚类中心uρ,1≤ρ≤k,对聚类中心的每一个数据元素uρj,选择一个随机数hρj,则聚类中心数据元素的密文形式为
s16、把加密之后的矩阵enc(a)和enc(u)上传至云服务端,其中enc(a)和enc(u)是数据集a和聚类中心集u使用lhe加密后的密文形式。
进一步地,步骤s2包括:
s21、分配数据对象;
假设diρ表示第i个特征向量(又称“数据项”)ai到第ρ个聚类中心uρ的距离;hρ=(hρ1,...,hρd),其中hρj(1≤j≤d)是加密uρj时所选的随机数;bi=(bi1,...,bid),其中bij(1≤j≤d)是加密aij时所选的随机数;d′iρ表示加噪音的diρ;[d′iρ]表示使用paillier加密的密文形式。根据enc(aij)=(aij-bij,[bij]),和enc(uρj)=(uρj-hρj,[hρj]),1≤j≤d,[d′iρ]计算步骤包括:得:
①根据lhe加法同态的性质计算两个向量的差,得:
enc(ai)-enc(uρ)=((ai-bi)-(uρ-hρ),[bi-hρ])
其中
②根据lhe乘法同态的性质计算d乙的密文,包括:
a.计算:
用paillier加密方案加密计算结果得:
b.根据步骤a计算得:
c.根据步骤a和步骤b计算得:
式[d′iρ]中[bi-hρ]是密文中的噪音项,(bi-hρ)t(bi-hρ)为密文中的噪音,为了后续的计算,需要客户端计算出(bi-hρ)t(bi-hρ),服务器再根据客户端计算出的(bi-hρ)t(bi-hρ)去掉密文中的噪音。
云服务端比较[diρ]和[diρ′]的大小,其中diρ′表示第i个特征向量ai到第ρ′个聚类中心uρ′的距离,如果[diρ]>[diρ′],则将[diρ′]与特征向量ai到其他聚类中心的距离进行比较,直到找到距离特征向量ai最近的聚类中心,则把特征向量ai划分为该聚类。具体比较过程如下:(为简洁易懂,令x=diρ,y=diρ′):
①云服务端计算:
[x1]=[x]2·[1]=[2x+1]
[y1]=[y]2=[2y]
②云服务端利用抛硬币的方法设置s的值,然后随机选取一个正整数r。如果s=1,则云服务端计算:
[l]=([x1]·[y1]n-1)r=[r(x1-y1)]
否则,云服务端计算:
[l]=([y1]·[x1]n-1)r=[r(y1-x1)]
③云服务端把计算好的密文[l]发送给客户端;
④客户端解密[l]得到明文l;
如果|l|>|n|/2,则标记f=1,否则,标记f=0。其中,|l|表示l的位长,|n|表示n的位长。
客户端使用公钥pk={n,g}加密f,然后把密文[f]返回给云服务端。
⑤云服务端在收到[f]之后,开始做如下步骤的计算:
如果s=1,则[f′]=[f];
否则[f′]=[1]·[f]n-1=[1-f]
因此,如果f′=0,则表明x≥y,如果f′=1,则表明x<y。
s22、更新聚类中心
在所有特征向量被分配到最近的聚类中心之后,云服务端根据当前的分配情况对聚类中心点进行更新操作。假设聚类结果所产生的聚类数据集uρ中有nρ个数据项,则nρ(1≤ρ≤k)满足n1+…+nk=n。由于云服务端只知道各聚类中心的数据对象的个数,并不能获取聚类中心点和数据对象的任何信息。本发明中,云服务端根据现有的密文信息计算新的聚类中心点的密文。对于聚类数据集uρ的聚类中心uρ的更新过程如下:
其中ai=(ai1,...,aid)(1≤i≤nρ)表示一个d维特征的特征向量;bi=(bi1,...,bid)(1≤i≤nρ),bij(1≤j≤d)表示加密aij时所选的随机数。
步骤s21和s22的两个过程将不断重复直到满足聚类算法终止条件。
进一步地,客户端对密文聚类结果进行解密包括:
假设聚类结果为k个聚类数据集uρ,1≤ρ≤k,每个聚类数据集包含nρ个数据项,n1+…+nk=n,以解密第ρ个聚类中的某个特征向量的特征值enc(aij)=(aij-bij,[bij]),
(1)根据paillier加密方案中的私钥sk={λ},解密[bij]得到bij;
(2)根据aij-bij和步骤(1)解密得到的bij,计算得到aij。
本发明具有以下优点与有益效果:
(1)在计算复杂度和通信复杂度有较大优化。
(2)具有cpa安全性,有效地保护了用户数据的隐私。
(3)用户和分析者之间以及用户与用户之间交互次数降低,降低了通信复杂度,大大提升了机器学习的效率。
附图说明
图1为本发明隐私信息保护方法流程图之一;
图2为本发明隐私信息保护方法流程图之二。
具体实施方式
下面通过具体实施方式对本发明作进一步详细的描述,但本发明的实施方式并不限于此。
本实施例中,基于k均值聚类的隐私信息保护方法,如图1-2所示,包括以下步骤:
s1、客户端采用线性同态加密算法lhe结合加法同态加密算法paillier对数据进行加密,得到密文数据,并将密文数据上传至云服务端。
客户端在上传数据之前,为了保证隐私安全,需要加密,上传密文数据给云服务端。
假设客户端拥有一个包含n特征数据的数据集,用矩阵a表示:
其中,矩阵a中每行的向量ai(1≤i≤n)表示一个特征向量(又称“数据项”),每一个特征向量包含d个特征值。
聚类算法将数据集a划分为k个聚类簇,每个聚类簇的聚类中心用uρ表示,每一个聚类中心uρ包含d个数据元素,聚类中心集用矩阵u表示:
其中,1≤ρ≤k。
本发明采用catalano等提出的一种线性同态加密算法(lhe)(详见文献1:catalanod,fiored.usinglinearly-homomorphicencryptiontoevaluatedegree-2functionsonencrypteddata[c].acmsigsacconferenceoncomputerandcommunicationssecurity.acm,2015:1518-1529),该加密机制不仅拥有加法同态的性质,还可以在密文上实现一次乘法同态操作。同时,结合加法同态加密算法paillier对数据进行加密。本实施例中,客户端数据处理过程包括:
s11、选择两个大的素数p和q,其中p、q的值不相等但是长度相等,计算n=pq,λ=lcm(p-1,q-1),其中lcm表示最小公倍数。
s12、随机选择一个整数g满足gcd(l(gλmodn2),n)=1,其中gcd表示最大公约数,l(x)=(x-1)/n。
s13、利用paillier中的函数生成公钥pk={n,g},私钥sk={λ}。把公钥发送给云服务端,保留自己的私钥。
s14、对数据集a进行加密,对每一个特征值aij,选择一个随机数bij,则特征值aij的密文形式为enc(aij)=(aij-bij,[bij]),
s15、对聚类中心集u进行加密,初始化k个聚类中心uρ,1≤ρ≤k,对聚类中心的每一个数据元素uρj,选择一个随机数hρj,则聚类中心数据元素的密文形式为enc(uρj)=(uρj-hρj,[hρj]),
s16、把加密之后的矩阵enc(a)和enc(u)上传至云服务端,其中enc(a)和enc(u)是数据集a和聚类中心集u使用lhe加密后的密文形式。
s2、云服务端对密文数据进行k均值聚类,得到密文聚类结果。
本实施例中,云服务端对加密后的密文数据enc(a)和enc(u)进行k均值聚类,得到密文聚类结果。
k均值聚类算法是机器学习聚类算法中的一种原型聚类算法,它的主要思想是:先确定k个聚类中心点,然后计算数据集中每个数据项到各个中心点的距离,把数据项分配到距离它最近的聚类中心,每一个聚类中心代表一个聚类,如果所有数据项都被归类,则每个聚类的中心点会根据当前聚类中的数据项进行更新。这个过程将被重复迭代执行,直到满足一定的终止条件。该终止条件可以是聚类中心不再发生变化或者变化很小,也可以是迭代次数已经超过规定的次数。
根据k均值聚类的过程,把聚类算法分为两个阶段:第一阶段:计算最近距离,分配数据对象;第二阶段:根据当前分配结果更新聚类中心。本实施例中,k均值聚类具体过程为:
s21、分配数据对象;
假设diρ表示第i个特征向量(又称“数据项”)ai到第ρ个聚类中心uρ的距离;
hρ=(hρ1,...,hρd),其中hρj(1≤j≤d)是加密uρj时所选的随机数;,bi=(bi1,...,bid),其中bij(1≤j≤d)是加密aij时所选的随机数;d′iρ表示加噪音的diρ;[d′iρ]表示使用paillier加密的密文形式。根据enc(aij)=(aij-bij,[bij]),
①根据lhe加法同态的性质计算两个向量的差,得:
enc(ai)-enc(uρ)=((ai-bi)-(uρ-hρ),[bi-hρ])
其中
②根据lhe乘法同态的性质计算d′iρ的密文,包括:
a.计算:
用paillier加密方案加密计算结果得:
b.根据步骤a计算得:
c.根据步骤a和步骤b计算得:
上式[d′iρ]中[bi-hρ]是密文中的噪音项,(bi-hρ)t(bi-hρ)为密文中的噪音,为了后续的计算,需要客户端计算出(bi-hρ)t(bi-hρ),服务器再根据客户端计算出的(bi-hρ)t(bi-hρ)去掉密文中的噪音。具体为:
云服务端发送k×n个密文[bi-hp]给客户端,客户端使用自己的私钥sk={λ}进行解密,得到明文bi-hρ。为了除去云服务端的噪音数据,客户端计算出(bi-hρ)t(bi-hρ),并使用公钥pk={n,g}进行paillier加密,发送密文[(bi-hρ)t(bi-hρ)]给云服务端。云服务端利用paillier的加法同态的性质除去原密文中的噪音:
式中
云服务端比较[diρ]和[diρ′]的大小,其中diρ′表示第i条特征向量ai到第ρ′个聚类中心uρ′的距离,如果[diρ]>[diρ′],则将[diρ′]与特征向量ai到其他聚类中心的距离进行比较,直到找到距离特征向量ai最近的聚类中心,则把特征向量ai划分为该聚类。具体比较过程如下:(为简洁易懂,令x=diρ,y=diρ′):
①云服务端计算:
[x1]=[x]2·[1]=[2x+1]
[y1]=[y]2=[2y]
②云服务端利用抛硬币的方法设置s的值,然后随机选取一个正整数r。如果s=1,则云服务端计算:
[l]=([x1]·[y1]n-1)r=[r(x1-y1)]
否则,云服务端计算:
[l]=([y1]·[x1]n-1)r=[r(y1-x1)]
③云服务端把计算好的密文[l]发送给客户端。
④客户端解密[l]得到明文l。
如果|l|>|n|/2,则标记f=1,否则,标记f=0。其中,|l|表示l的位长,|n|表示n的位长。
客户端使用公钥pk={n,g}加密f,然后把密文[f]返回给云服务端。
⑤云服务端在收到[f]之后,开始做如下步骤的计算:
如果s=1,则[f′]=[f];
否则[f′]=[1]·[f]n-1=[1-f]
因此,如果f′=0,则表明x≥y,如果f′=1,则表明x<y。
s22、更新聚类中心
在所有特征向量被分配到最近的聚类中心之后,云服务端需要根据当前的分配情况对聚类中心点进行更新操作。假设聚类结果所产生的聚类数据集uρ中有nρ个数据项,则nρ(1≤ρ≤k)满足n1+…+nk=n。由于云服务端只知道各聚类中心的数据对象的个数,并不能获取聚类中心点和数据对象的任何信息。本发明中,云服务端根据现有的密文信息计算新的聚类中心点的密文。对于聚类数据集uρ的聚类中心uρ的更新过程如下:
其中ai=(ai1,...,aid)(1≤i≤nρ)表示一个d维特征向量;bi=(bi1,...,bid)(1≤i≤nρ),bij(1≤j≤d)表示加密aij时所选的随机数。
步骤s21和s22的两个过程将不断重复直到满足聚类算法终止条件,该终止条件可以分为两种,第一种:在更新过程中,没有聚类中心再发生变化,或者聚类中心的变化很小;第二种是更新迭代过程超过了规定的迭代次数,则算法终止。
s3、云服务端将密文聚类结果返回客户端,客户端对密文聚类结果进行解密,得到明文聚类结果。
假设聚类结果为k个数据集uρ(1≤ρ≤k),每个数据集包含nρ(n1+…+nk=n)个特征向量。以解密第ρ个聚类中的某个特征向量的特征值enc(aij)=(aij-bij,[bij]),
(1)根据paillier加密方案中的私钥sk={λ},解密[bij]得到bij:
其中:
(2)根据aij-bij和步骤(1)解密得到的bij,计算aij:
aij=aij-bij+bij
假设客户端数据有n条记录(特征向量),每个特征向量包含d个特征数据,k表示聚类结果共有k个类别。将本发明的隐私信息保护方法进行计算复杂度和通信复杂的分析,其结果如表1所示。根据文献1的安全性分析,可以证明本发明是cpa安全,有效地保护了用户数据的隐私。
表1本发明方法效率和安全性分析
本发明可以用于优质客户分析,例如电信行业运营商可以根据用户的消费情况对用户进行分类,从而针对不同的用户设计不同的套餐类型。为了保证用户数据(例如:消费金额、消费类型、套餐使用情况、缴费情况等)的安全性,某运营商公司在上传数据给云服务端之前会先进行加密操作。云服务端在客户端的协助下进行k均值聚类,然后把加密的聚类结果返回给该公司。该电商公司在拿到加密的结果之后,解密得到聚类结果,然后可以根据聚类结果,有针对性的进行套餐设计,提升客户满意度。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!