一种基于栅格的轮廓线段特征提取算法的制作方法
本发明涉及移动机器人的技术领域,更具体地,涉及一种基于栅格的轮廓线段特征提取算法。
背景技术:
同时定位和地图构建(slam:simultaneouslocalizationandmapping)问题一直是移动机器人研究的重要方向,而栅格地图是slam问题中地图构建的常用方法。与边缘、角、区域、脊等其他环境特征相比,线段是数学上简单的中层描述符,利用它不但可以描述许多环境物体,而且提取复杂度较低。所以对栅格地图进行线段特征提取,是slam问题中很好的研究方向。
目前,线段类特征提取方法主要有pdbs(point-distance-basesegmentation)、sef(successiveedgefollowing)、lt(linetracking)、iepf(iterativeendpointfit)、sm(split-and-merge)等,然而这些提取方法都是对传感器的采样速度、数据有效性、连续型具有较高的要求,容易受噪点影响,且依赖于合适的阈值,环境的复杂性和多变性导致阈值选取困难。其中:pdbs算法与sef算法依赖于激光扫描数据的连续性,若出现数据丢失或噪点,则容易误判,且由于激光数据对近处障碍物和远处障碍物具有不同的探测精度,因此算法中阈值dth的设定往往顾此失彼;lt算法容易将下一线段的数据点划入上一线段,造成线段端点处的误判;iepf算法容易受到到噪点的影响,造成线段分割过多,且由于工作环境的复杂性和多变性,阈值的选取存在一定困难;sm算法对噪声和阈值敏感,容易得到错误的结果。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供一种基于栅格的轮廓线段特征提取算法,计算过程简单,可降低对旋转激光扫描仪的性能要求,同时降低噪点对提取效果的影响。
为解决上述技术问题,本发明采用的技术方案是:
提供一种基于栅格的轮廓线段特征提取算法,包括以下步骤:
s10.构建包括有若干障碍物栅格的栅格地图,提取障碍物栅格的中心点坐标组成数据点集m={p1,p2,....,pn};
s20.基于欧式距离的聚类方法,通过数据点之间的欧氏距离度量将点集m划分为若干个第一聚类点集mi={p1,p2,...,pk};
s30.基于路径搜索和分支点判断对每个第一聚类点集mi的数据点进行排序,得到排序后的第二聚类点集mii,mii内的数据点满足拓扑结构的先后顺序;
s40.将每个第二聚类点集mii内的数据点划分为若干个数据段sj={p1,p2,...,pj},每个数据段内的数据点可拟合成一条线段;
s50.对每个数据段内的数据点采用最小二乘法进行线段拟合。
本发明的基于栅格的轮廓线段特征提取算法,通过聚集程度为障碍物栅格分区域,再计算位置关系为区域内障碍物栅格分组,最后对组内障碍物栅格进行线段拟合;本发明的算法在寻找线段支持区时,不需要较大的内存和较长的计算时间,在拟合线段时,拟合的方法简单;且本发明能够降低对旋转激光扫描仪的性能要求,降低噪点对于提取效果的影响。
优选地,步骤s10的实现方法是:逐行逐列扫描栅格地图,若扫描到的栅格为障碍物,则将所述栅格的中心点坐标作为数据点加入数据点集m。
优选地,步骤s20中,对mi内每个数据点pi在mi内寻找至少一个相邻的数据点pj满足0<|pj-pi|≤1,pi,pj∈mi。
优选地,步骤s20包括以下步骤:
s21.建立一个第一聚类点集mi;
s22.从数据点集m中取出第一个数据点p1,作为第一聚类点集mi的第一个数据点,同时将p1从数据点集m中删除;
s23.从第一聚类点集mi中取出一个数据点pj;
s24.逐点扫描数据点集m中的数据点pi,若0<|pj-pi|≤1,则将pi加入第一聚类点集mi中,并将pi从数据点集m中删除;
s25.重复步骤s23~s24,直至遍历完第一聚类点集mi中所有的数据点;
s26.重复步骤s21~s25,直至遍历完数据点集m中所有的数据点。
聚类算法的目的是将一组未知类标的数据样本进行划分,希望找到数据集中隐藏的潜在结构,并按照某种相似性度量,使得具有相似性质的数据归于同一类,不相似性质的数据尽可能分开,以便于对数据进行分析处理。
优选地,步骤s30包括以下步骤:
s31.建立一个第二聚类点集mii,选取第一聚类点集mi={p1,p2,...,pk}的最后一点pk存入第二聚类点集mii,并将pk从mi中删除,标记mii的第一点为未遍历点;
s32.从第二聚类点集mii中取出第一个未遍历点pii,并将pii标记为已遍历点;
s33.按顺序搜索pii周围相邻的栅格pi:
若pi∈mi,且pi被判断为分支点,则将pi存入分支点缓存点集bii,并将pi从mi删除;跳入下一步;
若pi∈mi,且pi不是分支点,则将pi加入mii,标记为未遍历点,同时将pi从mi删除,跳入下一步;
s34.重复s33,直至搜索完pii周围相邻的所有栅格;
s35.重复s32-s34,直至第二聚类点集mii中没有未遍历点;
s36.从bii中取出一点pj添加到mii中,标记为未遍历点,并将pj从bii删除;
s37.重复步骤s32~s36,直至分支点缓存点集bii中没有数据点。
优选地,步骤s33所述的分支点判定方法为:
若mii中存在至少一个数据点pjj满足|pi-pjj|≥1且
若mii中存在至少两个数据点pjj满足
聚类内的数据点之间不存在拓扑结构上的先后顺序,不利于后续的分析处理,本发明引入路径搜索和分支点判断,对mi={p1,p2,....,pk}的数据点进行排序,从而使得聚类内的数据点具有拓扑结构上的先后顺序,有利于后续算法分析。其中,分支点是指从该点出发,路径搜索可能会扩充到两条互不相交的路径;在路径扩充时,若遇到分支点,则将分支点缓存起来,将当前路径扩充完成后,再从分支点出发继续进行扩充;这样处理的目的是使得存入mii的数据点中,位于同一线段上的数据点在mii内总是按顺序排列。
优选地,步骤s40中包括以下步骤:
s41.取聚类mii中的首尾两点p1,pk作为端点,另a0=p1,a1=pk,数据段计数为0;
s42.以a0,a1为端点,作线段l,数据段计数n=n+1;
s43.计算mi内位于a0,a1间的所有数据点对l的垂直距离d,假设在数据点pi处取得最大值dmax:若dmax>dth,则令a1=pi,跳到2,dth为设定的阈值;若dmax≤dth,则将mi内a0,a1及它们之间的数据点存入数据段sn,并将以上数据点从mii删除,令a0=p1,a1=pk,跳到2;
s44.重复步骤s42~s43,直到遍历完mii中所有数据点。
聚类内的数据点可能包含多个线段特征,分段的目的是将mii的数据点划分为若干个数据段sj,使得sj内的数据点满足:以首尾两点p1,pj作直线l,sj内其它数据点p2,...,pj-1到该直线l的距离均小于设定的阈值。
优选地,步骤s50按以下步骤进行:
s51.对于点集{p1(x1,y1),p2(x2,y2),...,pn(xn,yn)},按下式计算a、b、c的值:
c=-aμx-bμy
式中,μx是xi的均值,μy是yi的均值,μxx与是xi的方差,μyy是yi的方差,μxy是xi和yi的协方差;
s52.将分段点集sj={p1,p2,...,pj}代入步骤s51中公式,可得到拟合的直线:
ajx+bjy+cj=0
s53.将点集sj的首尾两点p1(x1,y1),pj(xj,yj)投影到直线ajx+bjy+cj=0,得到直线端点e0(xe0,ye0),e1(xe1,ye1):
与现有技术相比,本发明的有益效果是:
(1)本发明通过聚类、排序、分段的方法搜寻栅格地图中的线段支持区,不需要较大的内存和较长的计算时间,且编程实现简单代码量较少,可以节省存储空间,比较适用于存储空间紧张且计算能力较弱的设备;且本发明算法的搜寻效果好,符合人眼的观察标准;
(2)本发明计算简单,不用设置阈值等参数,降低对旋转激光扫描仪的性能要求,同时降低噪点对提取效果的影响,提取线段的分辨率高、鲁棒性强。
附图说明
图1为本发明的基于栅格的轮廓线段特征提取算法的流程图。
图2为实施例一基于栅格的轮廓线段特征提取算法的相邻栅格搜索顺序的示意图。
图3为实施例一基于栅格的轮廓线段特征提取算法的分支点判定的示意图。
图4为实施例一基于栅格的轮廓线段特征提取算法的分段的示意图。
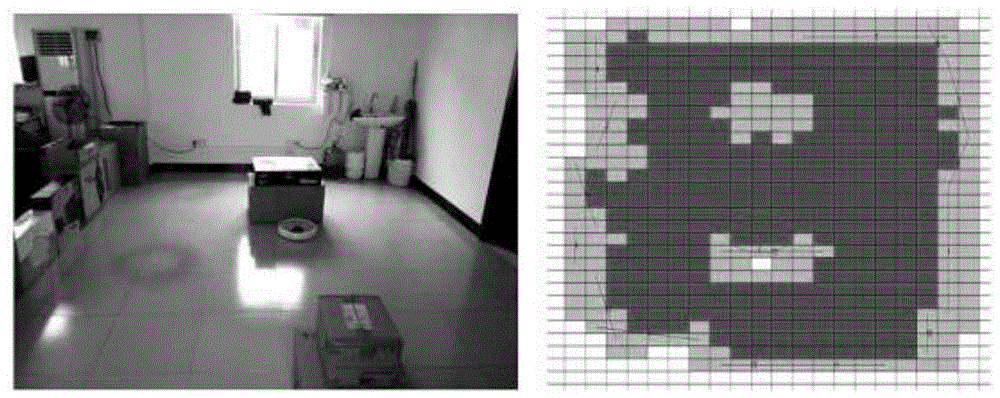
图5为实施例二中单矩形空间的实景图及栅格地图。
图6为实施例二中多矩形空间的实景图及栅格地图。
具体实施方式
下面结合具体实施方式对本发明作进一步的说明。其中,附图仅用于示例性说明,表示的仅是示意图,而非实物图,不能理解为对本专利的限制;为了更好地说明本发明的实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;对本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
实施例一
如图1至图4所示为本发明的基于栅格的轮廓线段特征提取算法的实施例,包括以下步骤:
s10.构建包括有若干障碍物栅格的栅格地图,提取障碍物栅格的中心点坐标组成数据点集m={p1,p2,....,pn};
s20.基于欧式距离的聚类方法,通过数据点之间的欧氏距离度量将点集m划分为若干个第一聚类点集mi={p1,p2,...,pk};
s30.基于路径搜索和分支点判断对每个第一聚类点集mi的数据点进行排序,得到排序后的第二聚类点集mii,mii内的数据点满足拓扑结构的先后顺序;
s40.将每个第二聚类点集mii内的数据点划分为若干个数据段sj={p1,p2,...,pj},每个数据段内的数据点可拟合成一条线段;
s50.对每个数据段内的数据点采用最小二乘法进行线段拟合。
步骤s10中,其通过以下方法实现:逐行逐列扫描栅格地图,若扫描到的栅格为障碍物,则将所述栅格的中心点坐标作为数据点加入数据点集m。
步骤s20中,对mi内每个数据点pi寻找至少一个相邻的数据点pj满足0<|pj-pi|≤1,pi,pj∈mi;步骤s20具体按以下步骤实施:
s21.建立一个第一聚类点集mi;
s22.从数据点集m中取出第一个数据点p1,作为第一聚类点集mi的第一个数据点,同时将p1从数据点集m中删除;
s23.从第一聚类点集mi中取出一个数据点pj;
s24.逐点扫描数据点集m中的数据点pi,若0<|pj-pi|≤1,则将pi加入第一聚类点集mi中,并将pi从数据点集m中删除;
s25.重复步骤s23~s24,直至遍历完第一聚类点集mi中所有的数据点;
s26.重复步骤s21~s25,直至遍历完数据点集m中所有的数据点。
聚类算法的目的是将一组未知类标的数据样本进行划分,希望找到数据集中隐藏的潜在结构,并按照某种相似性度量,使得具有相似性质的数据归于同一类,不相似性质的数据尽可能分开,以便于对数据进行分析处理。
步骤s30按以下步骤进行:
s31.建立一个第二聚类点集mii,选取聚类mi={p1,p2,...,pk}的最后一点pk存入第二聚类点集mii,并将pk从mi中删除,标记mii的第一点为未遍历点;
s32.从第二聚类点集mii中取出第一个未遍历点pii,并将pii标记为已遍历点;
s33.按顺序搜索pii周围相邻的栅格pi:
若pi∈mi,且pi被判断为分支点,则将pi存入分支点缓存点集bii,并将pi从mi删除;跳入下一步;
若pi∈mi,且pi不是分支点,则将pi加入mii,标记为未遍历点,同时将pi从mi删除,跳入下一步;
s34.重复s33,直至搜索完pii周围相邻的所有栅格;
s35.重复s32-s34,直至第二聚类点集mii中没有未遍历点;
s36.从bii中取出一点pj添加到mii中,标记为未遍历点,并将pj从bii删除;
s37.重复步骤s32~s36,直至分支点缓存点集bii中没有数据点。
步骤s33中,本实施例以pii周围有8个相邻的栅格为例进行说明,但本发明并不局限于此。按顺序搜索pii周围相邻的8个栅格,其搜索顺序如图2所示,从编号1的栅格顺次搜索至编号为8的栅格。
步骤s33中,如图3所示,从mii中取出一点pii作为出发点,则分支点的判定方法为:
若mii中存在至少一个数据点pjj满足|pi-pjj|≥1且
若mii中存在至少两个数据点pjj满足
步骤s40按以下步骤进行,表示为图4:
s41.取聚类mii中的首尾两点p1,pk作为端点,另a0=p1,a1=pk,数据段计数为0;
s42.以a0,a1为端点,作线段l,数据段计数n=n+1;
s43.计算mii内位于a0,a1间的所有数据点对l的垂直距离d,假设在数据点pi处取得最大值dmax:若dmax>dth,则令a1=pi,跳到2,dth为设定的阈值;若dmax≤dth,则将mi内a0,a1及它们之间的数据点存入数据段sn,并将以上数据点从mi删除,令a0=p1,a1=pk,跳到2;
s44.重复步骤s42~s43,直到遍历完mi中所有数据点。
步骤s50按以下步骤进行:
s51.对于点集{p1(x1,y1),p2(x2,y2),...,pn(xn,yn)},按下式计算a、b、c的值:
c=-aμx-bμy
式中,μx是xi的均值,μy是yi的均值,μxx与是xi的方差,μyy是yi的方差,μxy是xi和yi的协方差;
s52.将分段点集sj={p1,p2,...,pj}代入步骤s51中公式,可得到拟合的直线:
ajx+bjy+cj=0
s53.将点集sj的首尾两点p1(x1,y1),pj(xj,yj)投影到直线ajx+bjy+cj=0,得到直线端点e0(xe0,ye0),e1(xe1,ye1):
为了从点集{p1(x1,y1),p2(x2,y2),...,pn(xn,yn)}中拟合出一条hessian范式表示的直线ax+by+c=0,需要将下式的误差最小化:
实施例二
如图5、图6所示为本发明的基于栅格的轮廓线段特征提取算法的实施例,旨在验证本发明算法提取线段的可靠性和有效性。模拟搭建不同的实验环境,采用本发明算法进行测试。如图5、图6所示分别为单矩形空间、多矩形空间的实景图及栅格地图,左侧是测试环境实景图,右侧是移动机器人生成的栅格地图及线段特征;栅格地图中,白色表示栅格状态为未知,蓝色表示栅格状态为障碍物,绿色表示栅格状态为已清扫,黄色表示栅格状态为空白。测试结果表明,在障碍物分布复杂、密集且不规则的环境下,算法仍能稳健地搜寻到合适的线段拟合区域,完成线段提取,提取出的线段与观察结果相符。
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!