一种基于Hadoop平台的改进并行KNN网络舆情分类算法的制作方法
本发明涉及到移动互联网技术领域,特别涉及一种基于hadoop平台的改进并行knn网络舆情分类算法。
背景技术:
随着移动互联网的快速发展,微博、博客、twitter等社交平台已经成为人们获取信息的重要媒介,因此社交平台上数据正成几何数量增长。而社交平台上也存在一些影响社会稳定的不良信息,因此对社交平台上的敏感数据进行及时分析、监控以及对不同主题进行分类、预警和引导具有十分重要的现实意义。网络舆情数据具有数量大、非结构化、分散性强等特点,因此传统的文本分类算法在处理大批量网络舆情数据时,无法高效、快速的对网络舆情数据进行分类。
传统经典分类算法有:朴素贝叶斯(naivebayes,nb)、决策树(decisiontree,dt)、支持向量机(supportvectormachine,svm)、k近邻(k-nearestneighbor,knn)等。其中knn分类算法具有算法原理简单、理论成熟、分类准确率高和易于实现等优点,被广泛应用于各个领域。而knn分类算法在计算数据集中每一个样本点的相似度或距离时,需要耗费较长的时间,导致分类算法的时间复杂度增加。另一方面,当数据集中数据分布较为分散时,会使得分类准确率下降。因此,研究如何提高算法的分类准确率和时间复杂度是当前的研究热点。
现阶段,已有许多学者对knn分类算法进行了相关研究。王艳飞[1]提出基于样本密度对整个训练数据集进行裁剪,对裁剪后的样本数据进行聚类处理。马宾等[2,3]通过将knn分类算法与hadoop平台结合使之并行化,经过并行化后可以较好处理大批量数据。马莹等[4]提出使用k-medoids聚类算法对训练集进行裁剪,去除样本中相似度较低的部分,然后进行knn并行化处理,实验结果表明,该方法可以较好的减少算法运行时间。虽然k-medoids聚类算法对孤立点和噪声数据的敏感性小,但是无法处理大批量数据。
k最近邻(k-nearestneighbor,knn)算法[5],最初由cover和hart于1968年提出,其思路非常简单直观,易于快速实现,同时也是最简单的机器学习算法之一。该算法的思想是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
knn分类器是一种消极(懒惰)型学习器,模型的对建立非常简单(仅需要存储训练数据),当接收到测试数据后开始构造分类模型,对测试数据进行预处理并计算各分量间的距离,根据测试数据与训练数据进行分类。knn算法在进行分类时需要计算训练数据与测试数据之间的距离,因此算法消耗资源较多,各个数据节点对相似度计算具有独立性,因而该算法适合在并行环境下运行。
假设训练集为l,c1,c2,…,cn表示有n个类别,l训练集的总数量为m,特征向量维度阈值为n。di={xi1,xi2,…,xij,…,xin}表示训练集l中的一个文本的特征向量形式(0<i≤m)xij表示di的第j维的权重(0<j≤n)。测试集的特征向量形式为d={x1,x2,…,xj,…xn},其中xj代表d的第j维的权重(0<j≤n)。用来判断测试集与训练集中每个对象的距离常用方法有:余弦相似度和欧氏距离。余弦相似度计算如式所示。
通过式找到测试数据集分类文本的k个最近邻文本后,最后通过式计算待分类文本d属于每个类别的权重,将待分类文本归到权重最大的类别。
公式中,y(di,cj)为类别属性函数,如式所示。
3knn算法的改进
k近邻算法具有算法简单、易于实现的特点,但是在执行过程中需要花费大量时间计算数据集中各样本点的距离,这就降低了分类算法的效率。基于此文献[4]提出使用k-medoids聚类算法对数据集中样本相似度或距离低的数据进行剪裁,从而降低相似度的冗余计算。k-medoids聚类算法在处理大批量数据时表现的并不理想。
技术实现要素:
发明的目的在于提供一种基于hadoop平台的改进并行knn网络舆情分类算法,首先使用clara聚类算法对数据集中相似度或距离较低的部分进行剪裁处理,减少数据集中样本距离的计算;然后使mapreduce将knn算法进行并行化在hadoop平台上进行数据分类,以解决现有技术中的问题。
为实现上述目的,本发明提供如下技术方案:
一种基于hadoop平台的改进并行knn网络舆情分类算法,clara算法的步骤如下:
s1:进行m次迭代,迭代执行s2-s6;
s2:从整体数据集d中按照随机采样的方法抽取相同数量r个对象得到样本数据集si,si=(s1,s2,…,sr);
s3:在样本数据集si上调用pam算法找到样本数据集的最优k个中心点集合ci,ci=(c1,c2,…,ck);
s4:根据得到的ci找到整个数据集d中的每一个对象oj∈d在ci中欧氏距离最近的中心点,将oj划分为相应的簇中;
s5:根据公式
s6:返回步骤s1,开始下一次迭代;
s7:所有迭代都完成后以平均相异度作为评价标准衡量聚类效果,平均相异度最小的即是最优聚类;
s8:统计样本数据集与k个聚类的平均相异度,如果sim(d,oi)小于给定的阈值则将其从样本数据集中裁剪掉,否则将该簇内包含的样本添加到样本集中。
进一步地,knn并行化mapreduce文本分类算法实现函数如下:
(1)map函数
input:训练数据集和测试数据集、设定k的值一般取奇数、给出训练数据集的类别;
output:键值对<key1,value1>,其中key1表示测试数据集索引值,value1由字符串相似度s和类别标签c组成;
1:methodmap(key,value,key1,value1)
2:{
3:foreachlineinvaluedo
将line中的数据分解成<id,x,y>的形式;
计算相似度s=sim(x,y);
x表示测试向量;y表示训练向量;
emit(key1,value1);
4:}
(2)reduce函数
input:map函数的输出结果<key1,value1>
output:<key2,value2>,其中key2为key1的值,value2表示分类结果
1:methodreduce(key1,value1,key2,value2)
2:{
3:collectionsem=newarraylist();
//声明一个集合sem用于存放测试数据
//集与训练数//据集的相似度
4:collectionclassify=newarraylist();//声明一个集合classify用于存放分类标签
5:foreachvinvalue1do
构建键值对<s,c>,其中s为相似度,c为类别标签;
将s的值加入到集合sem中,c添加到集合classify中;
6:将集合sem中的值进行排序,确定k个最近邻集合同时得到集合sem数据所对应的类别;
7:把key1的值赋值给key2;
8:emit(key2,value2);
9:}
通过将knn算法构造成mapreduce程序实现算法的并行化处理文本分类,其中map函数中key值为测试数据集的行号即偏移量,value代表该行对应的训练集数据,数据集中包括相应的属性字段和类别标示,map阶段的输出key1表示测试数据集的行号,value1表示计算出的相似度s和类别标签c。在reduce阶段key2表示测试数据集的行号,value2代表计算出的分类结果。
进一步地,实验数据通过网络爬虫工具收集微博文本数据,语料中分为积极情感和消极情感两个类别,每个类别中包含6000条文本,共计12000条文本。
进一步地,利用虚拟机构建10台hadoop集群,cpu:intele7400,4gb内存,centos6.5,hadoop-2.8.5。
进一步地,衡量分类算法性能,通过比较算法的加速比、正确率p和运行时间t,其中加速比公式为:
正确率计算公式为:
与现有技术相比,本发明的有益效果是:本发明提出的基于hadoop平台的改进并行knn网络舆情分类算法,首先使用clara聚类算法对数据集中相似度或距离较低的部分进行剪裁处理,减少数据集中样本距离的计算;然后使mapreduce将knn算法进行并行化在hadoop平台上进行数据分类,利用hdfs分布式存储特性可以实现大量数据高效快速存储,同时设计对数据集进行前期处理,减少knn算法运时间,同时设计并行knn的mapreduce程序利用移动计算来实现数据快速处理,本发明的分类算法具有较低的时间复杂度和较好的分类准确率。
附图说明
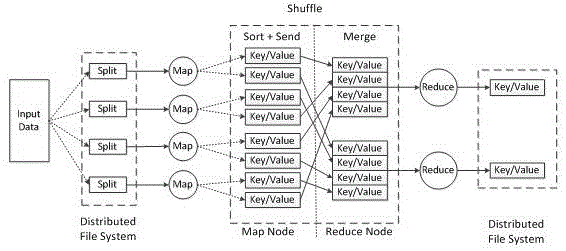
图1为本发明的mapreduce编程模型图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
一种基于hadoop平台的改进并行knn网络舆情分类算法,clara(clusteringlargeapplications)算法在pam算法的基础上采用随机抽样的方法降低大数据集上计算的时间复杂度,clara算法的步骤如下:
s1:进行m次迭代,迭代执行s2-s6;
s2:从整体数据集d中按照随机采样的方法抽取相同数量r个对象得到样本数据集si,si=(s1,s2,…,sr);
s3:在样本数据集si上调用pam算法找到样本数据集的最优k个中心点集合ci,ci=(c1,c2,…,ck);
s4:根据得到的ci找到整个数据集d中的每一个对象oj∈d在ci中欧氏距离最近的中心点,将oj划分为相应的簇中;
s5:根据公式
s6:返回步骤s1,开始下一次迭代;
s7:所有迭代都完成后以平均相异度作为评价标准衡量聚类效果,平均相异度最小的即是最优聚类;
s8:统计样本数据集与k个聚类的平均相异度,如果sim(d,oi)小于给定的阈值则将其从样本数据集中裁剪掉,否则将该簇内包含的样本添加到样本集中。
knn并行化mapreduce文本分类算法实现函数如下:
(2)map函数
input:训练数据集和测试数据集、设定k的值一般取奇数、给出训练数据集的类别;
output:键值对<key1,value1>,其中key1表示测试数据集索引值,value1由字符串相似度s和类别标签c组成;
1:methodmap(key,value,key1,value1)
2:{
3:foreachlineinvaluedo
将line中的数据分解成<id,x,y>的形式;
计算相似度s=sim(x,y);
x表示测试向量;y表示训练向量;
emit(key1,value1);
4:}
(2)reduce函数
input:map函数的输出结果<key1,value1>
output:<key2,value2>,其中key2为key1的值,value2表示分类结果
1:methodreduce(key1,value1,key2,value2)
2:{
3:collectionsem=newarraylist();
//声明一个集合sem用于存放测试数据
//集与训练数//据集的相似度
4:collectionclassify=newarraylist();//声明一个集合classify用于存放分类标签
5:foreachvinvalue1do
构建键值对<s,c>,其中s为相似度,c为类别标签;
将s的值加入到集合sem中,c添加到集合classify中;
6:将集合sem中的值进行排序,确定k个最近邻集合同时得到集合sem数据所对应的类别;
7:把key1的值赋值给key2;
8:emit(key2,value2);
9:}
通过将knn算法构造成mapreduce程序实现算法的并行化处理文本分类,其中map函数中key值为测试数据集的行号即偏移量,value代表该行对应的训练集数据,数据集中包括相应的属性字段和类别标示,map阶段的输出key1表示测试数据集的行号,value1表示计算出的相似度s和类别标签c。在reduce阶段key2表示测试数据集的行号,value2代表计算出的分类结果,mapreduce编程模型如图1所示。
接下来对该算法的算法测试和性能评估
首先实验环境和数据集设计
首先,实验数据通过网络爬虫工具收集微博文本数据,语料中分为积极情感和消极情感两个类别,每个类别中包含6000条文本,共计12000条文本。从两种文本类别中各抽取1000条,共计2000条文本作为训练集。为了进一步验证分类算法的可靠性和有效性,将抽取后的数据集划分为不同规模的测试集,如表1所示:利用虚拟机构建10台hadoop集群,cpu:intele7400,4gb内存,centos6.5,hadoop-2.8.5。
表1测试集
为了衡量分类算法性能,通过比较算法的加速比、正确率p和运行时间t,其中加速比公式为:
正确率计算公式为:
实验1:通过在单节点上比较knn算法、文献4和基于clara改进的knn算法三者之间的正确率和运行时间评价指标。参考文献4为马莹,赵辉,崔岩,基于hadoop平台的改进knn分类算法并行化处理[j].长春工业大学学报,2018,39(05):484-489,比较结果如表2所示:
表2分类算法对比表
由表2可知,由ts1测试集中数据量比较少,因此基于clara的knn分类算法在准确率上比knn分类算法相比下降了0.4%,因为通过clara聚类算法对数据集剪裁后算法为近似算法,当样本数量较少时,会对算法的准确率产生一定的影响;在运行时间上,基于clara改进的knn分类算法比knn分类算法缩短了10%~16%,而比文献4分类算法仅多出了8.33s,但在平均准确率方面比文献4分类算法高出了0.83%。当样本数量逐渐增加时,算法所需的计算时间的缩短会越来越明显,这是因为样本数据经过剪裁后,降低了相似度的冗余计算。
实验2:使用加速比来衡量一个系统的可扩充性。基于clara改进的knn分类算法,针对不同规模的数据集和不同数量的节点个数之间的加速比进行比较,对比结果如表3所示:
表3加速比对比
由表3可知,基于clara改进的knn文本分类算法随着节点个数的增加,加速比呈线性上升,节点个数的增加能够快速减少分类算法所需的分类时间,这说明基于hadoop平台的并行化算法具有较好的扩充性。
综上所述,本发明提出的基于hadoop平台的改进并行knn网络舆情分类算法,首先使用clara聚类算法对数据集中相似度或距离较低的部分进行剪裁处理,减少数据集中样本距离的计算;然后使mapreduce将knn算法进行并行化在hadoop平台上进行数据分类,利用hdfs分布式存储特性可以实现大量数据高效快速存储,同时设计对数据集进行前期处理,减少knn算法运时间,同时设计并行knn的mapreduce程序利用移动计算来实现数据快速处理,本发明的分类算法具有较低的时间复杂度和较好的分类准确率。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!