一种用户特征及特征因子抽取、查询方法和系统与流程
本发明涉及数据挖掘
技术领域:
,尤其涉及一种用户特征及特征因子抽取、查询方法和系统。
背景技术:
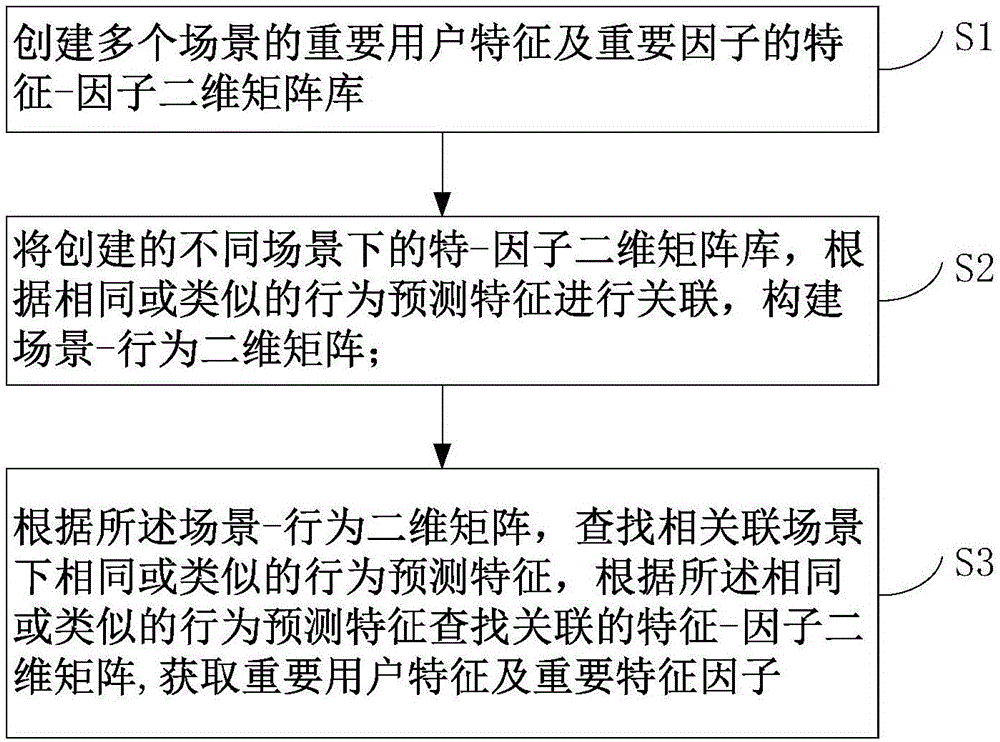
:现有的特征筛选技术,如pca主成分分析,logistic回归,随机森林的特征重要性判定重要性技术,bp反向传播神经网络对于特征的广义权重技术评价等,有两个缺陷:深度:一般的降维只顾及了特征中的维度,而并未顾及维度中不同因子对于输出的影响,比如购买决策中,年龄是影响的重要特征,但年龄分为儿童,青年,中年,老年,并未分出各个不同年龄的影响,就造成了无法实践落地,只知道年龄对购买有影响,但不知如何做,如果分析出重要特征是年龄,而重要正向影响因子是20-30岁的青年,重要的反向因子是60岁以上的老年,就非常明晰了,特征筛选流程只到一维,未到二维。性价比:并未将特征,因子的有效性进行组合并进行系统归纳,记录,形成编码库,遇到类似场景需重新寻找数据。比如如果知道年龄、年龄中的青年对是否购买商场会员卡有重要影响,那么类似场景比如是否购买餐饮券,参照类似场景的有效的特征因子库的编码记录,则去找到类似场景的类似预测结果特征形成基本框架,并在此基础上再补充,则可节约大量开发成本,而如果没有该特征+因子二维库,每次数据挖掘面对一个新的场景,只能重新耗费大量资源、时间成本去不断反复训练试错,并且如果没有有效的特征变量,很可能努力的方向错误,耗费成本却得不到较精准的结果;不断消耗设计与研发资源调优算法,却没有想到不是算法的问题,而是没有找到有效的特征,导致事倍功半,甚至事倍无功。技术实现要素:本发明实施例的目的在于提出一种用户特征及特征因子抽取、查询方法,旨在解决现有技术中数据特征筛选并未将特征、因子的有效性进行组合并进行系统归纳、记录,遇到类似场景重新寻找数据,导致的精度不高、资源和成本浪费的问题。本发明实施例是这样实现的,一种用户特征及特征因子抽取、查询方法方法,所述方法包括:s1,创建多个场景的重要用户特征及重要因子的特征-因子二维矩阵库;s2,将创建的不同场景下的特征-因子二维矩阵库,根据相同或类似的行为预测特征进行关联,构建场景-行为二维矩阵;s3,根据所述场景-行为二维矩阵,查找相关联场景下相同或类似的行为预测特征,根据所述相同或类似的行为预测特征查找关联的特征-因子二维矩阵,获取重要用户特征及重要特征因子。本发明实施例的第二目的在于提出一种用户特征及特征因子抽取方法,包括以下步骤(s101-s108):s101,从第一场景的用户行为统计数据库中抽取用户行为数据集;s102,对所述用户行为数据集进行预处理;s103,对预处理后的用户行为数据集进行归一化和离散化处理,得到第一用户行为特征集;s104,对第一用户行为特征集进行用户特征降维处理,获得降维后的第二用户行为特征集;s105,从第二用户行为特征集中抽取训练集和测试集,根据训练集和测试集建立候选数据预测模型并进行评价,获取优秀数据预测模型;s106,根据选出的优秀数据预测模型,对第二用户行为特征集中的用户特征进行筛选,选出重要用户特征;s107,对所述重要用户特征的特征因子进行过滤,获取重要特征因子;s108,根据所述重要用户特征及重要特征因子组合,构建第一场景的特征-因子二维矩阵库。本发明实施例的第三目的在于提出一种用户特征及特征因子抽取、查询系统,所述系统包括:特征-因子二维矩阵库创建装置,用于创建多个场景的重要用户特征及重要因子的特征-因子二维矩阵库;场景-行为二维矩阵创建装置,用于将创建的不同场景下的特征-因子二维矩阵库,根据相同或类似的行为预测特征进行关联,构建场景-行为二维矩阵;重要用户特征及重要特征因子查询装置,用于根据所述场景-行为二维矩阵,查找相关联场景下相同或类似的行为预测特征,根据所述相同或类似的行为预测特征查找关联的特征-因子二维矩阵,获取重要用户特征及重要特征因子。本发明实施例的第四目的在于提出一种用户特征及特征因子抽取装置,所述装置包括:第一场景的用户行为数据集抽取模块,用于从第一场景的用户行为统计数据库中抽取用户行为数据集;所述用户行为数据集m1包括至少一个用户特征、行为预测特征;所述用户特征包括至少一个特征因子;所述行为预测特征是以用户特征为输入变量根据数据预测模型生成;设用户特征为输入变量x,行为预测特征为输出变量y,y=model(x);所述数据预测模型包括神经网络、随机森林、支持向量机、决策树、逻辑回归、集成学习、k近邻模型、贝叶斯线性判别中的一个或多个;数据预处理模块,用于对所述用户行为数据集进行预处理;所述预处理包括缺失值处理、异常数据处理、数据冗余处理;归一化及离散化处理处理模块,对预处理后用户行为数据集进行归一化和离散化处理,得到第一用户行为特征集;用户特征降维处理模块,用于对第一用户行为特征集进行用户特征降维处理,获得降维后的第二用户行为特征集;降维处理方法包括:多重共线性降维法、回归降维法;优秀数据预测模型获取装置,用于从第二用户行为特征集中抽取训练集和测试集,根据训练集和测试集建立候选数据预测模型并进行评价,获取优秀数据预测模型;所述训练集和测试集获取方法采用无放回随机抽样,等距抽样,分层抽样,分类抽样方法;重要用户特征获取装置,用于根据选出的优秀数据预测模型,对第二用户行为特征集中的用户特征进行筛选,选出重要用户特征;重要特征因子获取装置,用于对所述重要用户特征的特征因子进行过滤,获取重要特征因子;特征-因子二维矩阵库创建模块,用于根据所述重要用户特征及重要特征因子组合,构建第一场景的特征-因子二维矩阵库。本发明的有益效果本发明提出一种用户特征及特征因子抽取、查询方法和系统。本发明方法通过首先对场景的用户行为数据进行预处理,离散化与用户特征降维,接着对降维后的用户特征进行优选,获取重要用户特征,接着对重要用户特征中的特征因子进行进一步的过滤,找到重要特征因子,创建场景的重要用户特征征和重要特征因子二维矩阵;然后根据创建的不同场景的重要用户特征和重要特征因子二维矩阵,通过相同或类似用户行为预测特征相关联,创建场景用户行为预测特征二维矩阵。通过本发明方法,在排查类似场景可能对决策结果产生重要影响的特征及因子时,不用花费大量成本进行重新探索,重新寻找数据,只需用通过本发明场景用户行为预测特征二维矩阵库进一步找到关联的重要用户特征和重要特征因子二维矩阵,从而可缩小查找范围,得出相对精准的训练结果,节约大量的资源与训练成本。附图说明图1是本发明优选实施例一种用户特征及特征因子抽取、查询方法流程图;图2是图1中创建其中一个场景的重要用户特征及重要因子的特征-因子二维矩阵库的方法流程图;图3是本发明实施例各候选数据预测模型的错判率四分位数-箱线图;图4是本发明实施例剔除用户特征后的错判率折线图;图5是本发明实施例年龄-负债错判率折线图;图6是本发明实施例信用卡消费场景下重要用户特征和重要特征因子存储示意图;图7是本发明实施例不同场景的场景、用户行为预测特征数据存储示意图;图8是本发明优选实施例一种用户特征及特征因子抽取、查询系统结构图;图9是图8中特征-因子二维矩阵库创建装置结构图;图10是图9中优秀数据预测模型获取装置结构图;图11是图9中重要用户特征获取装置结构图;图12是图9中重要特征因子获取装置结构图;图13是10中候选数据预测模型评价装置结构图;图14是图12中重要用户特征的特征因子降维装置结构图;图15是图12中第三错判率矩阵创建装置结构图。具体实施方式为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图和实施例,对本发明进行进一步详细说明,为了便于说明,仅示出了与本发明实施例相关的部分。应当理解,此处所描写的具体实施例,仅仅用于解释本发明,并不用以限制本发明。本发明提出一种用户特征及特征因子抽取、查询方法和系统。本发明方法通过首先对场景的用户行为数据进行用户特征降维,接着对降维后的用户特征进行优选,获取重要用户特征,接着对重要用户特征中的特征因子进行进一步的过滤,找到重要特征因子,创建场景的重要用户特征和重要特征因子二维矩阵;然后根据创建的不同场景的重要用户特征和重要特征因子二维矩阵,通过相同或类似用户行为预测特征相关联,创建场景用户行为预测特征二维矩阵。通过本发明方法,在排查类似场景可能对决策结果产生重要影响的特征及因子时,不用花费大量成本进行重新探索,重新寻找数据,只用通过本发明场景用户行为预测特征二维矩阵库进一步找到关联的重要用户特征和重要特征因子二维矩阵,从而可缩小查找范围,得出相对精准的训练结果,节约大量的资源与训练成本。实施例一图1是本发明优选实施例一种用户特征及特征因子抽取、查询方法流程图;所述方法包括(s1-s3):s1,创建多个场景的重要用户特征及重要因子的特征-因子二维矩阵库;具体地,创建其中一个场景的重要用户特征及重要因子的特征-因子二维矩阵库的方法包括以下步骤(s101-s108):图2是图1中创建其中一个场景的重要用户特征及重要因子的特征-因子二维矩阵库的方法流程图;s101,从第一场景的用户行为统计数据库中抽取用户行为数据集;所述用户行为数据集包括至少一个用户特征、行为预测特征;所述行为预测特征是以用户特征为输入变量根据数据预测模型生成;设用户特征为输入变量x,行为预测特征为输出变量y,y=model(x);所述数据预测模型包括神经网络、随机森林、支持向量机、决策树、逻辑回归、集成学习、k近邻模型、贝叶斯线性判别中的一个或多个。具体地,本发明实施例以信用卡消费这一场景的用户行为统计数据来进行详细说明;表1为信用卡消费场景下用户行为数据集片段;年龄教育工龄地址收入负债率信用卡负债其他负债违约41317121769.311.365.0112711063117.31.36404011514555.50.862.17041115141202.92.660.820242202817.31.793.061412552510.20.392.1603912096730.63.8316.6704311211383.60.131.240241341924.41.363.2813610132519.72.782.150表1表1中,用户特征包括年龄、教育、工龄、地址、收入、负债率、信用卡负债、其他负债;行为预测特征为违约;s102,对所述用户行为数据集进行预处理;所述预处理包括缺失值处理、异常数据处理、数据冗余处理;均为现有技术。s103,对预处理后的用户行为数据集进行归一化和离散化处理,得到第一用户行为特征集;所述归一化和离散化处理方法均为本
技术领域:
公知的方法;进一步地,所述用户特征包括至少一个特征因子;具体地,本发明实施例中,假设经过数据预处理、归一化和离散化处理后,用户特征值已按照区间值进行分类,分类后的类别即为特征因子;以用户特征教育为例来说明特征因子,教育特征包括本科、大专、高中及以下;年龄特征因子包括少年,青年,大龄青年,中年,中老年,老年;s104,对所述第一用户行为特征集进行用户特征降维处理,获得降维后的第二用户行为特征集;降维处理方法包括:步骤a1,利用多重共线性降维法,找到高度关联的用户特征(输入变量x),删除并保留高度关联的用户特征中的一个;步骤a2,利用回归降维法(线性,非线性,logistic)进行逐步寻优,删除对行为预测特征影响无关的用户特征(输入变量x)。所述多重共线性降维法,回归降维法均为本
技术领域:
公知的方法;s105,从第二用户行为特征集中抽取训练集和测试集,根据训练集和测试集建立候选数据预测模型并进行评价,获取优秀数据预测模型;所述训练集和测试集样本数量比例约为7/3;所述训练集和测试集获取方法可采用无放回随机抽样,等距抽样,分层抽样,分类抽样方法,均为本
技术领域:
公知的方法。所述根据训练集和测试集建立候选数据预测模型并进行评价,获取优秀数据预测模型,包括以下步骤:步骤b1,根据训练集中的用户特征变量(输入变量)、行为预测特征变量(输出变量),构建候选数据预测模型;所述候选数据预测模型包括神经网络、随机森林、支持向量机、决策树、逻辑回归、集成学习、k近邻模型、贝叶斯、线性判别中的一个或多个;步骤b2,对候选数据预测模型进行评价;具体包括(b201-b202):b201:将测试集中的用户特征变量代入所述候选数据预测模型,计算行为预测特征值(称为第一行为预测特征值);将所述第一行为预测特征值与测试集原有行为预测特征值进行对比,根据对比的预测误差建立混淆矩阵;混淆矩阵的每一列代表了预测类别,每一列的总数表示预测为该类别的数据的数目;每一行代表了数据的真实归属类别,每一行的数据总数表示该类别的数据实例的数目。每一列中的数值表示真实数据被预测为该类的数目;b202:计算候选预测模型的错判率,并存储为第一错判率矩阵;错判率=(预测错的数据量/样本总量)*100%;其中,候选预测模型的错判率≤第一阈值,第一阈值由使用者设置,一般不超过50%;候选预测模型的错判率数值越小,数据预测模型效果越好;本发明实施例中,表2表示信用卡消费预测误差混淆矩阵;表2假设本发明实施例的某一候选预测模型下,真实的未违约用户数为10000人,违约用户数为500人;预测的数据未违约的用户数9240人,违约用户数为1260人。预测错的数据量即为预测错的用户数量,样本总量即为测试集中的总用户数量,则错判率=(800+40)/(10000+500)=8%。本发明实施例中,构建的各个候选数据预测模型的错判率为表3所示,神经网络随机森林支持向量机决策树逻辑回归集成学习k近邻33.2%33.7%35.4%32.1%29.9%31.5%23.8%表3步骤b3:选出优秀数据预测模型;具体为:将各候选预测模型的错判率采用四分位数与箱线图法,筛选出优秀数据预测模型;本发明实施例中,假设各个候选数据预测模型的错判率四分位数对应如表4;位置最小值下四分位数中位数均值上四分位数最大值错判率23.8%30.7%32.10%31.37%33.45%35.40%表4各候选数据预测模型的错判率四分位数-箱线图如图3;四分位数错判率影响效果如表5:位置最小值下四分位数中位数均值上四分位数最大值错判率23.8%30.7%32.10%31.37%33.45%35.40%影响效果很显著显著不显著不显著不显著很不显著表5其中,四分位数与箱线图法均为现有技术;从四分位数-箱线图,可知k近邻模型影响效果最显著,可选为优秀数据预测模型;变量(数据预测模型)变量错判率是否入选优秀数据模型神经网络33.2%随机森林33.7%支持向量机35.4%决策树32.1%逻辑回归29.9%集成学习31.5%k近邻23.8%是s106,根据选出的优秀数据预测模型,对第二用户行为特征集中的用户特征进行筛选,选出重要用户特征;具体为:步骤c1:建立用户特征循环模型并进行循环迭代,计算剔除用户特征后的错判率,并存储为第二错判率矩阵;具体为:以所述选出的优秀数据预测模型为基础,以假设剔除用户特征中的任一个,来判断错判率是上升还是下降:如果剔除该用户特征后错判率上升,则判定该用户特征对预测行为结果正影响较为显著;如剔除该用户特征后错判率下降,则判定该用户特征对预测行为结果的负影响较为显著;如果剔除该用户特征后错判率变化不大,则判定该用户特征对预测行为结果影响不显著;循环重复上述过程。剔除用户特征后的错判率越高,其对应的用户变量影响越显著,错判率的计算方法与前文相同。图4是根据循环迭代的结果绘制的剔除用户特征后的错判率折线图;横坐标为剔除变量(用户特征),纵坐标表示剔除错判率(假设剔除用户特征后的错判率);步骤c2:选出重要用户特征;利用箱线图与四分位数来选择优秀数据预测模型下的重要用户特征,其方法与选择优秀数据预测模型相同,在此不再赘述。本发明实施例中,各个用户特征剔除后的错判率四分位数及影响效果表如表6,剔除用户特征的四分位数-箱线图未示出;位置最小值下四分位数中位数均值上四分位数最大值错判率22.86%25%25%26.51%30%30.71%影响效果负显著不显著不显著不显著正显著非常正显著表6若研究正显著的变量,则年龄、负债率入选。s107,对所述重要用户特征的特征因子进行过滤,获取重要特征因子;具体包括:步骤d1:对所述重要用户特征的特征因子进行降维;降维的方法包括以下步骤(d101-d103):d101,对重要用户特征中的特征因子进行离散化处理;离散化处理方法为现有技术;d102,将离散化处理后的特征因子转化为模拟用户特征;即将离散化处理后的特征因子设为模拟用户特征,对特征因子的值进行区间划分分类,将分类的名称(特征因子变量)设置为模拟用户特征变量;本发明实施例中,设数据集为data,预测行为是否有信用卡违约;模拟用户特征为负债率,负债率的变量值按照数值区间划分为1,2,3,4,5,6类别,表示用户消费负债的水平,分别对应命名为surper,senior,medium,mediocre,extra-low,并通过程序函数factor将其确定为模拟用户特征变量(特征因子变量):data$debt<-factor(data$debt,levels=c(1,2,3,4,5,6),labels=c(“super”,“senior”,“medium”,“mediocre”,“low”,“extra-low”)d103,利用回归降维法(线性,非线性,logistic),删除对行为预测影响无关的特征因子(模拟用户特征)。回归降维法为现有技术;步骤d2:利用特征因子循环迭代法,对降维后的特征因子进行循环迭代,计算剔除用特征因子组合后的错判率,并存储为第三错判率矩阵;具体包括(d201-d202):d201,将特征因子向量化;本发明实施例信用卡违约预测模型中,假设经过特征因子降维,有2个重要用户特征对于行为预测结果的影响较为显著,分别为负债率(极高,高,中等,中下,低,极低),年龄(少年,青年,大龄青年,中年,老年)。需要将重要用户特征中的特征因子进行循环,找出重要特征因子组合。特征因子向量化:debt=c(″super″,″senior",″medium",″mediocre",″low",“extra-low”)age=c(“children”,“young”,“singleyouth”,″midlife″,“old”)d202,建立特征因子循环模型并迭代,计算剔除特征因子组合后的错判率,并存储为第三错判率矩阵;具体为:以假设剔除重要特征中的任一特征因子组合,来判断错判率是上升还是下降:如果剔除该特征因子组合后错判率上升,则判定该特征因子组合对预测行为结果的正影响较为显著,如剔除该特征因子组合后错判率下降,则判定该特征因子组合对行为结果的负影响较为显著,如果剔除该特征因子组合后变化不大,则判定该特征因子组合对行为结果影响不显著;将重要用户特征的特征因子进行多重循环,重复上述过程。剔除特征因子组合后的错判率越高,其对应的特征因子组合影响越显著。错判率的计算方法与前文相同。本发明实施例中,当负债率=极高时,依次有负债率=极高,高,中等,中下,低,极低的6个错判率数值形成,再依次类推,按照顺序进行迭代;假设负债率=极高时,依次有年龄=少年,青年,大龄青年,中年,老年的5个错判率数值形成,再依次类推,按照顺序进行迭代,形成6×5的30个数值矩阵;本发明实施例为年龄和负债率的特征因子双层循环迭代;可将30个错判率数值矩阵进行矩阵还原,建立6×5矩阵,并将错判率数值填入,方法如下:debt=c(″super″,″senior″,″medium″,″mediocre″,″low″,“extra-low”)age=c(“children”,“young”,“singleyouth”,″midlife″,“old”)重要用户特征-剔除特征因子数值表如表7:负债率少年青年大龄青年中年中老年极高29.2824.2823.5724.2825.71高26.4225.7127.1426.4226.42中等25.7124.2825.712524.28中下26.4223.5724.2824.2822.14低23.5724.28252525极低24.2824.2824.2824.2824.28表7图5是根据上表绘制的年龄-负债错判率折线图;横坐标为剔除的特征因子组合,纵坐标表示剔除错判率(假设剔除特征因子组合后的错判率);步骤d3:,选出重要特征因子组合;利用箱线图与四分位数来选择重要用户特征中的重要特征因子组合,其方法与选择重要用户特征相同,在此不再赘述。本发明实施例中,各个特征因子组合剔除后的错判率四分位数及影响效果表如表8,剔除特征因子组合的四分位数-箱线图未示出;位置最小值下四分位数中位数均值上四分位数最大值数值22.14%24.29%24.29%24.98%25.71%29.28%影响效果负影响显著负影响不显著不显著正显著正影响显著表8根据剔除特征因子组合的四分位数-箱线图,结合第三错判率矩阵,获取影响效果显著的特征因子组合;本发明实施例中可以得出特征因子组合(负债率极高,少年)较为明显,剔除特征因子组合(负债率极高,少年)的错判率为29.28%,为正影响,少年群体信用卡违约概率高,对该群体的审批和额度银行可做对应策略。s108,根据所述重要用户特征及重要特征因子组合,构建第一场景的特征-因子二维矩阵库;本发明实施例中,重要用户特征及重要特征因子为负债率(极高)、年龄(少年)。负债率年龄违约111负债率=1,2,3,4,5,6分别表示极高,高,中等,中下,低,极低;年龄=1,2,3,4,5分别表示少年,青年,大龄青年,中年,老年;违约=1,0分别表示是、否;图6为信用卡消费场景下重要用户特征和重要特征因子存储示意图;黑点表示相应用户特征下的相应特征因子有存储数据;s2,将创建的不同场景下的特征-因子二维矩阵库,根据相同或类似的行为预测特征进行关联,构建场景-行为二维矩阵;图7为不同场景的场景、用户行为预测特征数据存储示意图;黑点表示相应场景下的行为预测特征有存储数据;场景包括商场、汽车、信用卡、房产、招聘、培训、旅行;相同或类似的行为预测特征包括购买、会员、账单逾期;s3,根据所述场景-行为二维矩阵,查找相关联场景下相同或类似的行为预测特征,根据所述相同或类似的行为预测特征查找关联的特征-因子二维矩阵,获取重要用户特征及重要特征因子。譬如,若想了解购买房产的人群及特征(即查找在房产场景下购买这一行为预测特征对应的用户特征及特征因子),已知购买房产与购买汽车(行为预测特征相同)息息相关;先通过场景-行为二维矩阵找到汽车场景下购买行为预测特征,然后找到所述汽车场景下购买行为预测特征对应的汽车场景下的特征-因子二维矩阵库,根据特征-因子二维矩阵库找到关联的用户特征和特征因子,从而可获知对购买房产行为影响显著的重要用户特征和重要特征因子;根据图7场景、用户行为预测特征数据存储示意图,可以快速直观的获知汽车场景下的购买行为预测特征有存储数据。譬如,若想了解购买培训课程的人群及特征(即查找在培训场景下购买这一行为预测特征关联的用户特征及特征因子),已知购买培训课程与招聘场景的办理会员(行为预测特征类似)息息相关;先找到招聘场景下会员行为预测特征,然后找到所述招聘场景下会员行为预测特征对应的招聘场景下的特征-因子二维矩阵库,根据特征-因子二维矩阵库找到关联的用户特征和特征因子,从而可获知对购买培训课程行为影响显著的重要用户特征和重要特征因子;根据图7场景、用户行为预测特征数据存储示意图,可以快速直观的获知招聘场景下会员行为预测特征有存储数据。实施例二一种用户特征及特征因子抽取方法,所述方法与实施例一的步骤s101-s108相同,在此不再赘述。实施例三图8是本发明优选实施例一种用户特征及特征因子抽取、查询系统结构图;本发明优选实施例一种用户特征及特征因子抽取、查询系统;所述系统包括:特征-因子二维矩阵库创建装置,用于创建多个场景的重要用户特征及重要因子的特征-因子二维矩阵库;场景-行为二维矩阵创建装置,用于将创建的不同场景下的特征-因子二维矩阵库,根据相同或类似的行为预测特征进行关联,构建场景-行为二维矩阵;重要用户特征及重要特征因子查询装置,用于根据所述场景-行为二维矩阵,查找相关联场景下相同或类似的行为预测特征,根据所述相同或类似的行为预测特征查找关联的特征-因子二维矩阵,获取重要用户特征及重要特征因子。进一步地,图9是图8中特征-因子二维矩阵库创建装置结构图;所述特征-因子二维矩阵库创建装置包括:第一场景的用户行为数据集抽取模块,用于从第一场景的用户行为统计数据库中抽取用户行为数据集1;所述用户行为数据集包括至少一个用户特征、行为预测特征;所述用户特征包括至少一个特征因子;所述行为预测特征是以用户特征为输入变量根据数据预测模型生成;设用户特征为输入变量x,行为预测特征为输出变量y,y=model(x);所述数据预测模型包括神经网络、随机森林、支持向量机、决策树、逻辑回归、集成学习、k近邻模型、贝叶斯、线性判别中的一个或多个。数据预处理模块,用于对所述用户行为数据集进行预处理;所述预处理包括缺失值处理、异常数据处理、数据冗余处理;均为现有技术。归一化及离散化处理处理模块,对预处理后的用户行为数据集进行归一化和离散化处理,得到第一用户行为特征集;所述归一化和离散化处理方法均为本
技术领域:
公知的方法;用户特征降维处理模块,用于对第一用户行为特征集进行用户特征降维处理,获得降维后的第二用户行为特征集;降维处理方法包括:多重共线性降维法,回归降维法均为本
技术领域:
公知的方法;优秀数据预测模型获取装置,用于从第二用户行为特征集中抽取训练集和测试集,根据训练集和测试集建立候选数据预测模型并进行评价,获取优秀数据预测模型;所述训练集和测试集样本数量比例约为7/3;所述训练集和测试集获取方法可采用无放回随机抽样,等距抽样,分层抽样,分类抽样方法,均为本
技术领域:
公知的方法。重要用户特征获取装置,用于根据选出的优秀数据预测模型,对第二用户行为特征集中的用户特征进行筛选,选出重要用户特征;重要特征因子获取装置,用于对所述重要用户特征的特征因子进行过滤,获取重要特征因子;特征-因子二维矩阵库创建模块,用于根据所述重要用户特征及重要特征因子组合,构建第一场景的特征-因子二维矩阵库;进一步地,图10是图9中优秀数据预测模型获取装置结构图;所述优秀数据预测模型获取装置包括候选数据预测模型构建装置、候选数据预测模型评价装置和优秀数据预测模型取出装置,候选数据预测模型构建装置,用于根据训练集中的用户特征变量(输入变量)、行为预测特征变量(输出变量),构建候选数据预测模型;所述候选数据预测模型包括神经网络、随机森林、支持向量机、决策树、逻辑回归、集成学习、k近邻模型、贝叶斯、线性判别中的一个或多个;候选数据预测模型评价装置,用于对候选数据预测模型进行评价;优秀数据预测模型取出装置,用于选出优秀数据预测模型;具体为:将各候选预测模型的错判率采用四分位数与箱线图法,筛选出优秀数据预测模型;进一步地,图11是图9中重要用户特征获取装置结构图;所述重要用户特征获取装置包括第二错判率矩阵创建模块和重要用户特征获取模块;第二错判率矩阵创建模块,用于建立用户特征循环模型并进行循环迭代,计算剔除用户特征后的错判率,并存储为第二错判率矩阵;具体为:以所述选出的优秀数据预测模型为基础,以假设剔除用户特征中的任一个,来判断错判率是上升还是下降:如果剔除该用户特征后错判率上升,则判定该用户特征对预测行为结果正影响较为显著;如剔除该用户特征后错判率下降,则判定该用户特征对预测行为结果的负影响较为显著;如果剔除该用户特征后错判率变化不大,则判定该用户特征对预测行为结果影响不显著;循环重复上述过程。剔除用户特征后的错判率越高,其对应的用户变量影响越显著,错判率的计算方法与前文相同。重要用户特征获取模块,用于选出重要用户特征;具体为:利用箱线图与四分位数来选择优秀数据预测模型下的重要用户特征,其方法与选择优秀数据预测模型相同,在此不再赘述。进一步地,图12是图9中重要特征因子获取装置结构图;所述重要特征因子获取装置包括重要用户特征的特征因子降维装置、第三错判率矩阵创建装置、重要特征因子获取装置;重要用户特征的特征因子降维装置,用于对所述重要用户特征的特征因子进行降维;第三错判率矩阵创建装置,用于利用特征因子循环迭代法,对降维后的特征因子进行循环迭代,计算剔除用特征因子组合后的错判率,并存储为第三错判率矩阵;重要特征因子获取装置,用于选出重要特征因子组合;具体为:利用箱线图与四分位数来选择重要用户特征中的重要特征因子组合,其方法与选择重要用户特征相同,在此不再赘述。进一步地,图13是图10中候选数据预测模型评价装置结构图;所述候选数据预测模型评价装置包括混淆矩阵创建模块和第一错判率矩阵创建模块;混淆矩阵创建模块,用于先将测试集中的用户特征变量代入所述候选数据预测模型,计算行为预测特征值(称为第一行为预测特征值);然后将所述第一行为预测特征值与测试集原有行为预测特征值进行对比,根据对比的预测误差建立混淆矩阵;其中,混淆矩阵的每一列代表了预测类别,每一列的总数表示预测为该类别的数据的数目;每一行代表了数据的真实归属类别,每一行的数据总数表示该类别的数据实例的数目。每一列中的数值表示真实数据被预测为该类的数目;第一错判率矩阵创建模块,用于计算候选预测模型的错判率,并存储为第一错判率矩阵;错判率=(预测错的数据量/样本总量)*100%;其中,候选预测模型的错判率≤第一阈值,第一阈值由使用者设置,一般不超过50%;候选预测模型的错判率数值越小,数据预测模型效果越好;进一步地,图14是图12中重要用户特征的特征因子降维装置结构图;所述重要用户特征的特征因子降维装置包括重要用户特征的特征因子离散化处理模块、特征因子转化模块和重要用户特征的特征因子降维处理模块;重要用户特征的特征因子离散化处理模块,用于对重要用户特征中的特征因子进行离散化处理;离散化处理方法为现有技术;特征因子转化模块,用于离散化处理后的特征因子转化为模拟用户特征;即将离散化处理后的特征因子设为模拟用户特征,对特征因子的值进行区间划分分类,将分类的名称(特征因子变量)设置为模拟用户特征变量;重要要用户特征的特征因子降维处理模块,用于利用回归降维法(线性,非线性,logistic),删除对行为预测影响无关的特征因子(模拟用户特征)。回归降维法为现有技术;进一步地,图15是图12中第三错判率矩阵创建装置结构图。所述第三错判率矩阵创建装置包括特征因子向量化模块和特征因子循环迭代模块;特征因子向量化模块,用于将特征因子向量化;特征因子循环迭代模块,用于建立特征因子循环模型并迭代,计算剔除特征因子组合后的错判率,并存储为第三错判率矩阵;具体为:以假设剔除重要特征中的任一特征因子组合,来判断错判率是上升还是下降:如果剔除该特征因子组合后错判率上升,则判定该特征因子组合对预测行为结果的正影响较为显著,如剔除该特征因子组合后错判率下降,则判定该特征因子组合对行为结果的负影响较为显著,如果剔除该特征因子组合后变化不大,则判定该特征因子组合对行为结果影响不显著;将重要用户特征的特征因子进行多重循环,重复上述过程。剔除特征因子组合后的错判率越高,其对应的特征因子组合影响越显著。错判率的计算方法与前文相同。实施例四一种用户特征及特征因子抽取装置,所述装置结构与实施例四中的特征-因子二维矩阵库创建装置相同,在此不再赘述。本领域的普通技术人员可以理解,实现上述实施例方法中的全部或部分步骤是可以通过程序指令相关硬件来完成的,所述的程序可以存储于一计算机可读取存储介质中,所述的存储介质可以为rom、ram、磁盘、光盘等。以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1