一种数据库优化方法及其系统与流程
本发明属于数据库技术领域,涉及到一种数据库优化方法及其系统。
背景技术:
数据库,可视为电子化的文件柜,即存储电子文件的处所,用户可以对文件中的数据运行新增、截取、更新、删除等操作,所谓“数据库”是以一定方式储存在一起、能予多个用户共享、具有尽可能小的冗余度、与应用程序彼此独立的数据集合。
随着网络信息技术的不断发展,数据库应用技术已经在诸多行业领域得到广泛的应用,数据库内存储有大量的数据,在对数据库内的数据进行查询、更新时,由于数据库内数据量庞大,需逐一查询数据库中的数据,时间复杂度高,增加不必要的重复查询环节,大大浪费数据库检索的时间,降低数据库查询的效率,为了解决以上问题,现设计一种数据库优化方法及系统。
技术实现要素:
本发明的目的在于提供的数据库优化方法及系统,解决了现有数据库检索的过程中,存在的时间复杂度高、检索效率低的问题,减少无效查询次数,提高数据库优化的效率,提高查询性能。
本发明的目的可以通过以下技术方案实现:
一种数据库优化方法,包括以下步骤:
s1、对数据库内的数据进行存储划分,以存储日期不同建立文件组,并将文件组内的数据划分存储至各行列表内;
s2、提取各区分表中各行列表内数据的关键字,并将提取的关键字存储至临时缓冲区内,所述临时缓冲区内划分有若干临时缓冲表,临时缓冲表内划分有若干临时缓冲列,临时缓冲列中存储与临时缓冲列编号相同的行列表中的关键字,并统计各关键字对应权重;
s3、提取关键字权重集合中关键字的权重数值大于设定的关键字权重阈值的关键字,将大于设定的关键字权重阈值的关键字构成主干关键字集合cik(cik1,cik2,...,cikx,...,cikz),cikx表示为第i个区分表中第k个行列表内第x个主干关键字,z≤5,cik1,cik2,...,cikx,...,cikz对应的关键字权重依次降低,并将小于等于设定的关键字权重阈值的关键字构成支干关键字集合dik(dik1,dik2,...,dikx,...,diky),dikx表示为第i个区分表中第k个行列表内第x个主干关键字,dik1,dik2,...,dikx,...,diky对应的关键字权重依次降低;
s4、将各区分表中各行列内的所有关键字进行聚类分析,获得各行列表的聚类中心,并对各行列表进行聚类划分;
s5、提取各聚类中心上的所有行列表,统计各聚类中心上所有行列表的主干关键字,除去重复的主干关键字,并构成聚类关键字集合ef(ef1,ef2,...,efλ,...,efh),efλ表示为第f个聚类中心上的第λ个聚类关键字,f∈1,2,..,r,h表示为第f个聚类中心上不重复的主干关键字的数量;
s6、接收客户端发送的查询语句,对查询语句进行语法分析,以提取查询语句中的若干查询关键字,所述查询关键字代表查询语句含义的词汇,所述查询关键字构成查询关键字集合q(q1,q2,...,qy),qy表示为第y个查询关键字;
s7、将查询语句的查询关键字集合分别与各聚类中心对应的聚类关键字集合进行逐一对比,筛选各聚类中心对应的聚类关键字与查询关键字重叠度系数最大的聚类中心,并执行步骤s8;
s8、将筛选的各聚类中心中的所有行列表与查询关键字进行一一对比,提取行列表中主干关键字和支干关键字组成的所有关键字与查询语句对应的查询关键字进行一一对比,若查询语句中的查询关键字均在其中一行列表时,则提取该行列表内的数据反馈至客户端,否则,依次降低重叠度系数,提取降低后的重叠度系数对应的聚类中心,且执行步骤s7,直至检索出查询语句对应的查询关键字均存在在其中一行列表中。
进一步地,所述步骤s1中数据库内的数据存储空间划分,包括以下步骤:
t1、对数据库设置若干文件组,不同文件组以时间段进行划分,并按文件组创建的时间顺序进行排序,分别为1,2,...,i,...,n,i表示为第i个文件组,n表示为文件组的数量;
t2、创建区分函数,区分以datetime类型值为依据,并以时间点类型作为分区分隔点,以创建区分函数,其中,以每天00:00:00时间点作为分区分隔点;
t3、创建区分表,将以datetime分隔的区间与文件组进行一一对应,创建分区表,将各文件组内的数据划分至与之对应的区分表内,区分表对应的编号与文件组对应的编号相一致;
t4、将各区分表进行划分,划分成若干行列表,划分的行列表依次进行编号分别为1,2,...,k,...,h,存储至区分表的数据根据区分表的划分,依次将划分的数据存储至行列表内。
进一步地,所述步骤s2中行列表中的关键字存储至与该行列表编号相同的临时缓冲列中,各临时缓冲列中存储有若干关键字,并将存储的若干关键字构成关键字集合bik(bik1,bik2,...,bikj,...,bikm),bikj表示为第i个区分表中第k个行列表内数据的第j个关键字,关键字集合中不同关键字对应的权重构成关键字权重集合gbik(gbik1,gbik2,...,gbikj,...,gbikm),gbikj表示为第i个区分表中第k个行列表内数据的第j个关键字对应的权重。
进一步地,各行列表中关键字对应权重计算公式为
进一步地,对关键字权重集合中各关键字对应的权重进行归一化处理,得到归一化关键字权重集合gik(gik1,gik2,...,gikj,...,gikm),
进一步地,所述步骤s4中关键字聚类分析过程,包括以下步骤:
l1、获取各行列表中主干关键字集合对应的关键字权重累计和,依次筛选r个主干关键字对应的权重累计和最大的行列表,并将筛选的r个行列表作为r个聚类中心;
l2、随机分配所有区分表中行列表到r个聚类中心上,对聚类中心分别进行编号1,2,...,r;
l3、选取其中一聚类中心,将该各聚类中心上的各行列表从该聚类中心中移出;
l4、统计移出的行列表与每个聚类中心的距离ds(v),
l5、获取移出的行列表与各聚类中心间的距离ds(v),筛选最大值的距离ds(v),将移出行列表划分为第v个聚类中心上;
l6、重复执行步骤l3-l5,直至初始划分的该聚类中心上均重新进行聚类划分;
l7、重复执行步骤l3-l6,直至所有初始的聚类中心上的行列表均重新进行聚类划分。
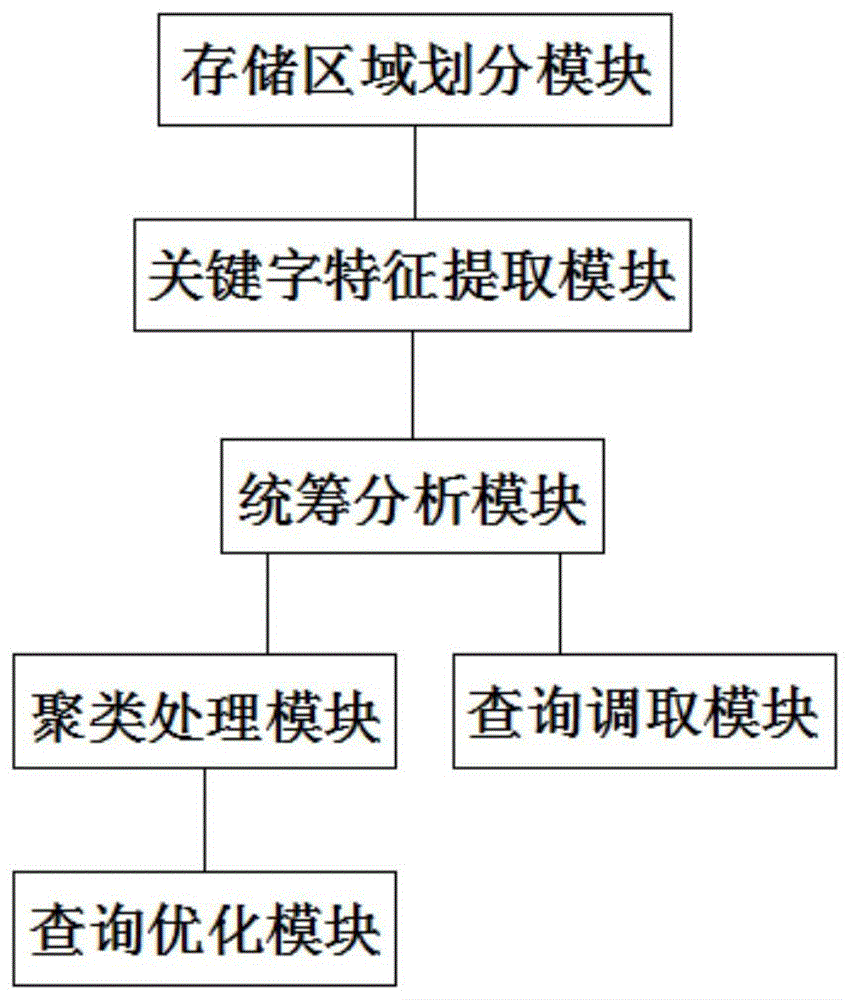
一种数据库优化系统,包括存储区域划分模块、关键字特征提取模块、查询调取模块、统筹分析模块、聚类处理模块和查询优化模块;
存储区域划分模块与关键字特征提取模块连接,统筹分析模块分别与关键字特征提取模块、查询调取模块和聚类处理模块连接,查询优化模块与聚类处理模块连接;
存储区域划分模块用于对数据库内的存储数据进行存储划分,划分成若干文件组,并对存储空间进行划分,划分成若干区分表;
关键字特征提取模块用于对存储区域划分模块内各区分表中的各行列表内存储的数据进行关键字提取,提取的关键字构成关键字集合,统计提取的各关键字在该行列表内出现的次数,并将该行列表中的关键字发送至查询调取模块,将行列表中的关键字以及关键字在该行列表中出现的次数发送至统筹统计模块;
查询调取模块用于获取历史查询语句,提取查询语句中的关键字,并接收关键字特征提取模块中关键字,将各查询语句语句中的各关键字分别与关键字特征提取模块种提取的各行列表内的关键字进行逐一对比,统计各历史查询语句中关键字出现的数量以及各查询语句中出现各行列表中关键字次数,并将各历史查询语句中关键字出现的数量以及各查询语句中出现各行列表中关键字次数发送至统筹分析模块,其中,各查询语句中出现各行列表中关键字次数构成关键字累计次数集合ul(ulik1,ulik2,...,ulikj,...,ulikm),ulikj表示为第l个查询语句中出现第i个区分表中第k个行列表内第j个关键字的次数;
统筹分析模块用于接收关键字特征提取模块发送的各行列表中各关键字出现的次数,并接收查询调取模块发送的各历史查询语句中关键字出现的数量以及各查询语句中出现各行列表中关键字次数,统计各行列表中各关键字对应的权重,并对统计的各行列表中关键字对应的权重进行归一化处理,得到经归一化处理的各行列表中的关键字权重,经归一化处理后的关键字权重发送至聚类处理模块;
聚类处理模块用于接收统筹分析模块发送的各行列表经归一化处理后的关键字权重,对接收的关键字权重与设定的关键字权重阈值进行对比,以划分主干关键字集合和支干关键字集合,统计各行列表中主干关键字集合中各关键字权重累计和,筛选r个主干关键字集合中各关键字权重累积和最大的行列表作为聚类中心,对各行列表进行聚类划分处理,并提取聚类划分后的所有行列表的主干关键字,实现不同行列表的聚类划分归类,聚类中心的所有主干关键字构成聚类关键字集合;
查询优化模块用于接收客户端发送的查询语句,对查询语句进行语法分析,提取查询语句中的查询关键字,并将提取的查询关键字与聚类处理模块处理后的各聚类中心对应的主干关键字进行逐一对比,筛选查询关键字与各聚类中心对应的聚类关键字重叠度系数最大的聚类中心,查询优化模块将该重叠关键字数量最多的聚类中心中的所有行列表分别与查询关键字进行一一对比,以获得查询关键字在其中一行列表中均出现,将该行列表数据反馈至客户端。
进一步地,所述重叠度系数的计算公式为
本发明的有益效果:
1、本发明提供的数据库优化方法及系统,通过对数据库设置文件组,并对数据库存储空间进行划分,对存储的数据进行划分存储,提高了数据库分区优化的特点,实现数据的分散存储,实现对大量数据存储的优化,为后期数据库的查询奠定基础;
2、对各区分表中各行列表内数据的关键字进行提取,统计历史查询语句中各行列表中关键字在查询语句中出现的次数以及各区分表数据中各关键字出现的次数,以获得各行列表中关键字对应的权重,并进行关键字权重的归一化处理,关键字权重的统计过程,综合统计各关键字的权重,实现关键字的综合分析和提取,减少检索相应的时间,提高了关键字权重统计的综合性和准确性,为后期聚类中心的筛选奠定基础;
3、对关键字权重集合中关键字的权重数值与设定的关键字权重阈值进行对比,以区分筛选出支干关键字和主干关键字,并根据主干关键字对应的关键字权重累计和提取聚类中心,且根据聚类中心对各行列表重新进行聚类中心的划分,便于对各行列表进行聚类划分,提高了聚类划分的准确性和聚集效果,在数据库数据搜索时,优先搜索类,提高了搜索的效率;
4、获取客户端的查询语句,提取查询语句上的关键字,并将提取的查询语句上关键字分别与各聚类中心对应的聚类关键字进行对比,依次降低各聚类中心对应的聚类关键字与查询关键字重叠度系数的聚类中心,并将该聚类中心内行列表内的关键字进一步与查询关键字对比,筛选对应的行列表内的数据,采用分层分布查询,降低查询的复杂程度,减少不必要的重复环节,节约时间成本,大大提高了数据库优化的效率。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明中一种数据库优化系统的示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
一种数据库优化方法,包括以下步骤:
s1、对数据库内的数据进行存储划分,以存储日期不同建立文件组,并将文件组内的数据划分存储至各行列表内;
数据库内的数据存储空间划分,包括以下步骤:
t1、对数据库设置若干文件组,不同文件组以时间段进行划分,并按文件组创建的时间顺序进行排序,分别为1,2,...,i,...,n,i表示为第i个文件组,n表示为文件组的数量;
t2、创建区分函数,区分以datetime类型值为依据,并以时间点类型作为分区分隔点,以创建区分函数,其中,以每天00:00:00时间点作为分区分隔点;
t3、创建区分表,将以datetime分隔的区间与文件组进行一一对应,创建分区表,将各文件组内的数据划分至与之对应的区分表内,区分表对应的编号与文件组对应的编号相一致;
t4、将各区分表进行划分,划分成若干行列表,划分的行列表依次进行编号分别为1,2,...,k,...,h,存储至区分表的数据根据区分表的划分,依次将划分的数据存储至行列表内,每个行列表内的存储空间相同;
通过对数据库的存储空间进行划分,提高数据库分区优化的特点,以实现对数据的分散存储,提高了大量数据存储的效率,为后期数据库的查询提供可靠的基础。
s2、提取各区分表中各行列表内数据的关键字,并将提取的关键字存储至临时缓冲区内,其中,临时缓冲区内划分有若干临时缓冲表,临时缓冲表内划分有若干临时缓冲列,各临时缓冲列与各行列表相一一对应,即行列表中的关键字存储至与该行列表编号相同的临时缓冲列中,各临时缓冲列中存储有若干关键字,并将存储的若干关键字构成关键字集合bik(bik1,bik2,...,bikj,...,bikm),bikj表示为第i个区分表中第k个行列表内数据的第j个关键字,关键字集合中不同关键字构成关键字权重集合gbik(gbik1,gbik2,...,gbikj,...,gbikm),gbikj表示为第i个区分表中第k个行列表内数据的第j个关键字对应的权重;
统计设定历史查询语句中的关键字,累计历史查询语句内第i个区分表中第k个行列表内第j个关键字在查询语句中出现的次数,并统计各区分表内各关键字出现的次数,统计各关键字对应的权重
对关键字权重集合中各关键字对应的权重进行归一化处理,得到归一化关键字权重集合gik(gik1,gik2,...,gikj,...,gikm),
通过对各区分表中各行列表中的关键字进行提取,并根据历史搜索语句中出现的次数以及行列表中出现的次数,以综合统计各关键字的权重,实现关键字的综合分析和提取,减少检索相应的时间;
s3、提取关键字权重集合中关键字的权重数值大于设定的关键字权重阈值的关键字,将大于设定的关键字权重阈值的关键字构成主干关键字集合cik(cik1,cik2,...,cikx,...,cikz),cikx表示为第i个区分表中第k个行列表内第x个主干关键字,z≤5,cik1,cik2,...,cikx,...,cikz对应的关键字权重依次降低,并将小于等于设定的关键字权重阈值的关键字构成支干关键字集合dik(dik1,dik2,...,dikx,...,diky),dikx表示为第i个区分表中第k个行列表内第x个主干关键字,dik1,dik2,...,dikx,...,diky对应的关键字权重依次降低;
s4、将各区分表中各行列内的所有关键字进行聚类分析,获得各行列表的聚类中心,并对各行列表进行聚类划分;
所述关键字聚类分析过程,包括以下步骤:
l1、获取各行列表中主干关键字集合对应的关键字权重累计和,依次筛选r个主干关键字对应的权重累计和最大的行列表,并将筛选的r个行列表作为r个聚类中心;
l2、随机分配所有区分表中行列表到r个聚类中心上,对聚类中心分别进行编号1,2,...,r;
l3、选取其中一聚类中心,将该各聚类中心上的各行列表从该聚类中心中移出;
l4、统计移出的行列表与每个聚类中心的距离ds(v),
l5、获取移出的行列表与各聚类中心间的距离ds(v),筛选最大值的距离ds(v),将移出行列表划分为第v个聚类中心上;
l6、重复执行步骤l3-l5,直至初始划分的该聚类中心上均重新进行聚类划分;
l7、重复执行步骤l3-l6,直至所有初始的聚类中心上的行列表均重新进行聚类划分。
通过对各行列表中主干关键字对应的权重进行统计,并筛选主干关键字对应的权重累计最大的r个行列表作为聚类中心,以进行聚类划分、分析,实现对各行列表进行聚类划分,提高了聚类划分的准确性和聚集效果,在数据库数据搜索时,优先搜索类,提高了搜索的效率。
s5、提取各聚类中心上的所有行列表,统计各聚类中心上所有行列表的主干关键字,除去重复的主干关键字,并构成聚类关键字集合ef(ef1,ef2,...,efλ,...,efh),efλ表示为第f个聚类中心上的第λ个聚类关键字,f∈1,2,..,r,h表示为第f个聚类中心上不重复的主干关键字的数量;
s6、接收客户端发送的查询语句,对查询语句进行语法分析,以提取查询语句中的若干查询关键字,所述查询关键字代表查询语句含义的词汇,所述查询关键字构成查询关键字集合q(q1,q2,...,qy),qy表示为第y个查询关键字;
s7、将查询语句的查询关键字集合分别与各聚类中心对应的聚类关键字集合进行逐一对比,筛选各聚类中心对应的聚类关键字与查询关键字重叠度系数最大的聚类中心,并执行步骤s8,重叠度系数
s8、将筛选的各聚类中心中的所有行列表与查询关键字进行一一对比,提取行列表中主干关键字和支干关键字组成的所有关键字与查询语句对应的查询关键字进行一一对比,若查询语句中的查询关键字均在其中一行列表时,则提取该行列表内的数据反馈至客户端,否则,依次降低重叠度系数,提取降低后的重叠度系数对应的聚类中心,且执行步骤s7,直至检索出查询语句对应的查询关键字均存在在其中一行列表中,通过对各聚类中心的关键字进行对比,以检索最佳聚类中心,并依次对聚类中心中行列表对应的关键字与查询语句的关键字进行逐一对比,筛选出查询语句所查询的数据内容,实现分层分步查询的特点,大大降低查询的复杂程度,实现对数据库海量数据的优化查询。
如图1所示,一种数据库优化系统,包括存储区域划分模块、关键字特征提取模块、查询调取模块、统筹分析模块、聚类处理模块和查询优化模块;
存储区域划分模块与关键字特征提取模块连接,统筹分析模块分别与关键字特征提取模块、查询调取模块和聚类处理模块连接,查询优化模块与聚类处理模块连接;
存储区域划分模块用于对数据库内的存储数据进行存储划分,划分成若干文件组,并对存储空间进行划分,划分成若干区分表,且分别对文件组和区分表进行编号,并将编号相同的文件组内的数据存储至与之编号相对应的区分表内,另外,每个区分表由若干行列表组成,各行列表进行编号分别为1,2,...,k,...,h;
关键字特征提取模块用于对存储区域划分模块内各区分表中的各行列表内存储的数据进行关键字提取,提取的关键字构成关键字集合,统计提取的各关键字在该行列表内出现的次数,并将该行列表中的关键字发送至查询调取模块,将行列表中的关键字以及关键字在该行列表中出现的次数发送至统筹统计模块;
查询调取模块用于获取历史查询语句,提取查询语句中的关键字,并接收关键字特征提取模块中关键字,将各查询语句语句中的各关键字分别与关键字特征提取模块种提取的各行列表内的关键字进行逐一对比,统计各历史查询语句中关键字出现的数量以及各查询语句中出现各行列表中关键字次数,并将各历史查询语句中关键字出现的数量以及各查询语句中出现各行列表中关键字次数发送至统筹分析模块,其中,各查询语句中出现各行列表中关键字次数构成关键字累计次数集合ul(ulik1,ulik2,...,ulikj,...,ulikm),ulikj表示为第l个查询语句中出现第i个区分表中第k个行列表内第j个关键字的次数;
统筹分析模块用于接收关键字特征提取模块发送的各行列表中各关键字出现的次数,并接收查询调取模块发送的各历史查询语句中关键字出现的数量以及各查询语句中出现各行列表中关键字次数,统计各行列表中各关键字对应的权重,并对统计的各行列表中关键字对应的权重进行归一化处理,得到经归一化处理的各行列表中的关键字权重,经归一化处理后的关键字权重发送至聚类处理模块;
聚类处理模块用于接收统筹分析模块发送的各行列表经归一化处理后的关键字权重,对接收的关键字权重与设定的关键字权重阈值进行对比,以划分主干关键字集合和支干关键字集合,统计各行列表中主干关键字集合中各关键字权重累计和,筛选r个主干关键字集合中各关键字权重累积和最大的行列表作为聚类中心,对各行列表进行聚类划分处理,并提取聚类划分后的所有行列表的主干关键字,实现不同行列表的聚类划分归类,聚类中心的所有主干关键字构成聚类关键字集合;
查询优化模块用于接收客户端发送的查询语句,对查询语句进行语法分析,提取查询语句中的查询关键字,并将提取的查询关键字与聚类处理模块处理后的各聚类中心对应的主干关键字进行逐一对比,筛选查询关键字与各聚类中心对应的聚类关键字重叠度系数最大的聚类中心,查询优化模块将该重叠关键字数量最多的聚类中心中的所有行列表分别与查询关键字进行一一对比,以获得查询关键字在其中一行列表中均出现,将该行列表数据反馈至客户端。
以上内容仅仅是对本发明的构思所作的举例和说明,所属本技术领域的技术人员对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,只要不偏离发明的构思或者超越本权利要求书所定义的范围,均应属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!