一种基于稀疏规则化的判别投影方法以及图像识别装置与流程
本发明公开了一种特征提取方法—稀疏规则化判别投影,其属于生物特征提取和模式识别技术领域,涉及数据稀疏表示的学习、局部和非局部结构的构建、目标函数的优化,可用于图像识别、数据挖掘、数据聚类。
背景技术:
目前大多数非线性特征提取方法面临着人为定义近邻图的问题,同时邻域参数的选择也直接关系着数据特征提取的质量。到现在为止,一直没有一个简单而有效的标准来确定算法的邻域参数。稀疏表示的出现,很好地避免了领域参数的选择问题,它可以自适应地获取数据的近邻关系。近年来一些学者把稀疏表示引入模式识别领域,用于处理特征提取或特征选择、分类、聚类、目标检测和信息融合等问题。
稀疏表示和压缩感知是由donoho等人提出的一种新的信号表示和获取框架,它激起了信息科学领域的广泛研究热情。稀疏表示将一个信号表示为字典中基本信号的稀疏线性组合,该稀疏线性组合中的系数向量被称为稀疏系数向量。假设原始高维空间中的稀疏信号
鉴于稀疏学习对问题的高精准建模能力,其已经发展成为一种非常有力的图像处理和模式识别工具。以稀疏学习为思想,aharon等人提出了一种新的稀疏表示方法k-svd,它在(1)基于当前字典对样本进行稀疏编码和(2)更新字典中的原子以更好拟合样本数据两个步骤之间反复迭代直到收敛。elad等人将k-svd推广到图像去噪问题中,并得到了很好的去燥效果。mairal等人将非局部的思想和稀疏学习相结合提出了一种非局部稀疏模型,并将其成功应用于图像去噪等问题。feng等人提出了一种将特征提取的投影矩阵和稀疏表示中的判别字典进行联合学习的方法,并通过人脸识别实验证明了该方法的有效性。
pca作为最典型的维数约简方法,为了保证其投影向量的稀疏性,学者们提出了稀疏主成分分析(sparsepca,spca)和非负稀疏主成分分析(nonnegativespca,nspca)。为了保持稀疏重构权重,cheng等人提出了稀疏近邻保持嵌入方法(sparseneighborhoodpreservingprojection,snpe)。qiao等人将稀疏表示与流形学习相结合,提出了一种基于稀疏学习的无监督维数特征提取方法——稀疏保持投影(sparsitypreservingprojections,spp),spp通过一个基于l1正则化的目标函数获取数据的稀疏重构关系,并最终以保持此稀疏重构关系来来达到维数约简的目的。一方面,spp具有自动捕获数据点邻域关系的优点;另一方面,即使在没有样本标签信息的情况下,基于spp所获得的投影仍然包含一定程度的判别信息。spp作为非常典型的稀疏学习算法,缺点也是明显的。
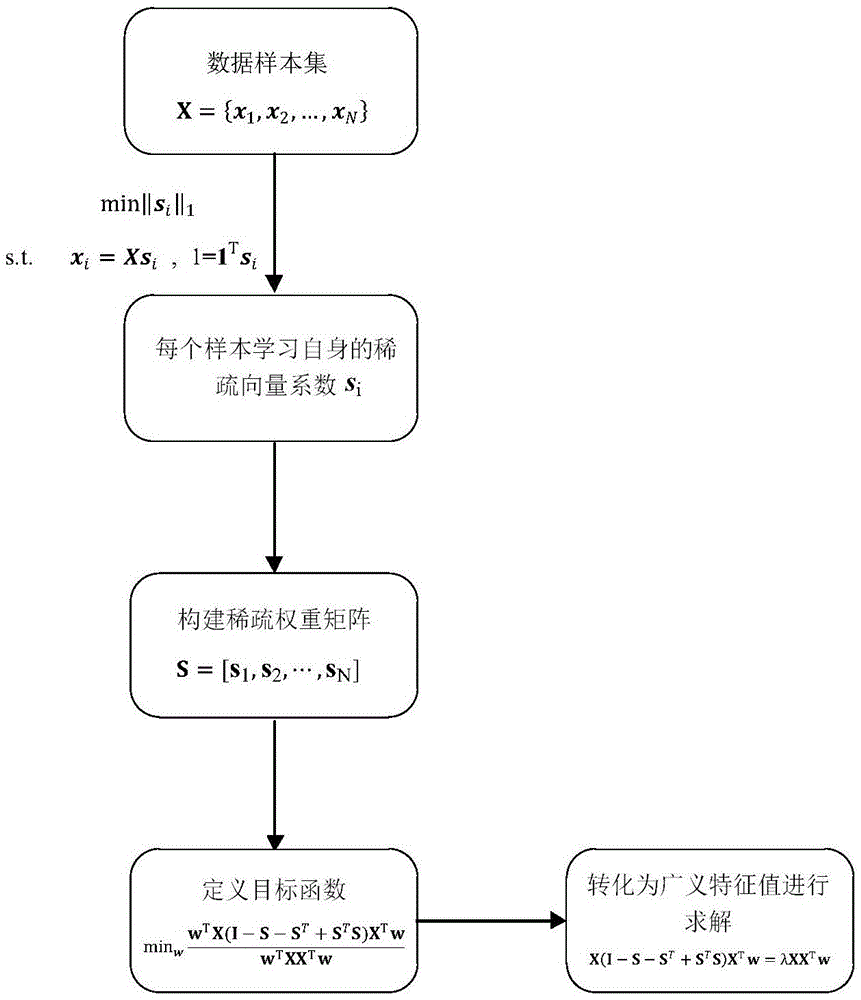
参见附图1所示。稀疏保持投影(spp)旨在通过保持数据的稀疏表示结构来实现维数约简的目的,其具体流程图如图1所示。对于一个给定的训练样本集x={x1,x2,…,xn}∈rd×n,其中d表示特征维数,n表示样本数。spp首先通过求解下面的l1范数最小化问题来学习每一个样本xi的稀疏系数向量si:
min||si||1
s.t.xi=xsi,1=1tsi(1.1)
其中||·||1表示l1范数,也就是绝对值操作;1表示一个全为1的向量。一旦利用式(1.1)学习到所有样本的稀疏系数向量si(i=1,2,…,n),其稀疏重构权重矩阵s可以定义如下:
s=[s1,s2,…,sn](1.2)
最终,基于上述权重矩阵s,spp的目标函数可以定义如下:
最优投影向量w可以通过求解最小的特征值所对应特征向量的广义特征值方程来求得,其广义特征值方程为:
x(i-s-st+sts)xtw=λxxtw(1.4)
通过spp方法的计算过程发现,其比较明显的两个缺点是:
(1)需重复进行n次求解l1范数最小化问题来获得所有样本的稀疏系数向量,以至于计算复杂度高,因此在实际应用中很难达到实时性要求。
(2)忽略了数据的局部和非局部结构信息,很难学习到最具判别的特征表示。
技术实现要素:
本发明针对目前稀疏表示算法中存在的高计算复杂度、未考虑数据本身的几何结构信息等问题,提出了一种基于稀疏规则化的判别投影方法,其技术方案如下:包括如下步骤:
1)构建级联字典和学习稀疏表征结构;
2)保留稀疏表征结构;
3)学习数据的局部和非局部结构;
4)稀疏规则化辨别投影。
本发明还公开一种图像识别装置,该装置包括基于稀疏规则化的判别投影方法。
附图说明
图1为本发明现有技术稀疏保持投影方法流程图。
图2为本发明基于稀疏规则化的判别投影方法流程图。
具体实施方式
一种基于稀疏规则化的判别投影方法,其技术方案如下:包括如下步骤:
1)构建级联字典和学习稀疏表征结构
给定一个训练样本集x=[x1,x2,…,xn],每一个xi表示一个d维向量。接着,利用标签信息(也就是样本类别)对样本集重新排列:x=[x1,x2,…,xc],其中c表示样本类别数,
其中,μi表示第i类所有的样本的平均值,ni为第i类样本数。
然后,对于每一类样本矩阵
其中,φi表示
其中,d是通过pca分解获得的级联字典,并由所有的di(i=1,2,…,c)构成。
根据上述计算过程,每一个样本对应一个稀疏系数向量。通过式(1.7),我们发现,由于di列的正交性,对于第i类中的任意一个样本,其稀疏系数向量
不难发现,步骤1)通过简单的矩阵计算就可以快速学习数据的稀疏表示,避免了l1范数最优化问题,可大大减少计算复杂度。
2)保留稀疏表征结构
可以看出,数据的稀疏表征结构很好地揭示着训练样本的局部判别信息。为了获取数据的低维表示,实现维数约简,我们希望保留数据的稀疏表征结构。因此,接下来定义以下目标函数,并通过最小化重构误差寻找最优投影来保留其稀疏结构。目标函数为:
其中,
其中,
3)学习数据的局部和非局部结构
为了集合数据的局部和非局部的优点,定义两个散度矩阵:局部散度和非局部散度。局部散度矩阵表示为:
其中,xi为样本数据,权值hij定义为:
上式中,o(k,xi)表示样本xi的k个近邻点的集合,k变化范围为1~(ni-1),可根据实验选取最合适的值。式(1.12)意味着:如果xj属于xi的k个近邻点,则认为两点之间有边相连,hij=1;否则,则认为两点间无边相连,hij=0。
如此以来,非局部散度矩阵可以表示为:
4)稀疏规则化辨别投影
基于稀疏规则化的判别投影方法目的是找到一组最优的投影向量,一方面,能够保留数据的稀疏表征结构;另一方面,最大化非局部散度和最小化局部散度。鉴于此,基于稀疏规则化的判别投影的目标函数可以定义为:
其中,α(0<α<1)是一个平衡参数,其可以通过调节不同的值来平衡分子中的两个度量。sn和sl分别是前面定义的非局部和局部散度矩阵。
将式(1.10),(1.11),(1.13)代入式(1.14)可得:
令
ψ=αsl+(1-α)(xxt-xstdt-dsxt+dsstdt)
最优化问题(1.15)最终可以转化为以下广义特征值问题:
snw=λψw(1.16)
因此,最优投影矩阵w=[w1,w2,…,wd]可由求解上式广义特征值问题得到的d个最大特征值对应的特征向量组成。
本发明算法整个计算过程两次考虑了数据的局部结构,一次是利用k近邻方式构建邻域图的过程,如式(1.12)所示;一次是学习稀疏表示的过程,参见步骤1。
对于步骤3),可以单独只考虑数据的局部或者非局部结构,也可以用其他结构替代,最终将结构带入到目标函数进行优化求解。
对于本发明目标函数(1.15),可以将其比值形式变换成差值形式达到同样目的。
总结如下:
1、本发明充分利用级联字典学习数据的稀疏表示,避免了求解l1范数问题,大大减少了计算复杂度。
2、本发明相对于稀疏保持投影算法,不仅考虑了数据的稀疏表示结构,还利用了数据的标签信息。
3、本发明通过局部结构最小化和非局部结构最大化,实现了对原始数据几何特性的考虑。
4、本发明算法整个计算过程两次考虑了数据的局部结构,一次是利用k近邻方式构建邻域图的过程,如式(1.12)所示;一次是学习稀疏表示的过程,参见步骤1。
本发明还公开一种图像识别装置,该装置包括基于稀疏规则化的判别投影方法。
在以上的描述中阐述了很多具体细节以便于充分理解本发明。但是以上描述仅是本发明的较佳实施例而已,本发明能够以很多不同于在此描述的其它方式来实施,因此本发明不受上面公开的具体实施的限制。同时任何熟悉本领域技术人员在不脱离本发明技术方案范围情况下,都可利用上述揭示的方法和技术内容对本发明技术方案做出许多可能的变动和修饰,或修改为等同变化的等效实施例。凡是未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所做的任何简单修改、等同变化及修饰,均仍属于本发明技术方案保护的范围内。
- 还没有人留言评论。精彩留言会获得点赞!