一种基于HBase的文件分片方法与流程
本发明属于计算机领域,具体是一种基于hbase的文件分片方法。
背景技术:
随着互联网技术的发展与应用,社交网络、移动通信、网络视频以及电子商务等各行业产生的数据呈现爆炸式增长,我们的生活正逐步进入大数据时代。在大数据时代里,如何对大量数据进行有效存储进而分析应用,越来越成为各行各业企业发展进阶的关键。尤其是在面对大文件存储时,如何避免单点负载过高,如何实现高效可靠存储更是亟待解决的难题。
hbase作为一种面向列的非结构化数据分布式存储系统,为解决非结构化数据的分布式高性能可靠性存储提供了解决方案。搭建在廉价pc机上的集群利用机器的硬件设备完成了数据的分布式存储;无限定增加的列结构可以为元数据的存储提供扩展性。
技术实现要素:
本发明针对大文件存储时单点负载过高、存储低效且数据安全性低等问题,提出了一种基于hbase的文件分片方法,为大文件的分片存储提供高效可靠的解决方案。
所述的一种基于hbase的文件分片方法,具体步骤如下:
步骤一、针对每个大文件,从系统中读取对大文件分片的配置文件和按分片粒度进行读取的配置文件。
配置文件包括:slicenum分片数量的配置和slicesize每片大小的配置;
分片数量指定后,根据大文件的大小确定各分片的大小及在大文件中的位置;
分片大小指定后,按照分片大小对大文件进行内容读取。
步骤二、按照分片粒度规则将用户预备写入的某个大文件进行分片。
具体分片过程为:
根据用户预备写入的大文件的大小,按照分片数量确定每个片的平均大小,最后一个分片的大小小于等于每个片平均的大小。
步骤三、判断文件内容的写入读取是否为指定片或者随机读取,如果是,进入步骤六,否则,进入步骤四按分片的顺序进行写入或读取;
步骤四、在对大文件进行分片后,通过多个并列线程将每个分片的内容以独立的键值存入hbase的数据表中。
键为该片内容存储在数据表的rowkey的二进制字节数组;值为该片内容的二进制字节数组。
步骤五、同时,将大文件的相关信息写入到hbase元数据信息表中,同时将每个分片的元数据信息以新增列的方式存储在hbase元数据信息表中。
相关信息包括文件名称、文件大小、写入时间、文件拥有者及分片信息等;
新增列的名称包含每个分片的编号,列值则为每个分片在数据表中rowkey所包含的信息,通过此信息能够索引定位每个分片在数据表中的位置,便于每个分片数据内容的读取。
步骤六、判断文件内容的写入读取是否为指定片或者随机读取,如果是指定片,按照指定的分片编号写入读取文件内容;否则,进入步骤七进行随机读取。
写入过程为:首先、在大文件中移动文件指针,定位到要写入的指定分片的起始位置,然后读取该分片内容将该分片对应写入hbase的数据表中,并添加该分片的元数据信息到hbase元数据列。
读取过程为:首先,确定要读取的大文件的指定分片编号;然后,根据大文件名称定位到hbase元数据表中该大文件存储的元数据,最后根据指定分片编号获得对应列的值即为该分片的元数据,在数据表中定位到该分片读取其内容。
步骤七、随机读取大文件的存储内容。
具体步骤如下:
步骤701、设定随机读取的字节开始位置from和读取内容大小size配置值,从而得到随机读取的范围为from至from+size;
步骤702、根据大文件名称定位到hbase的元数据表中该大文件存储的元数据,读取所有分片列的分片元数据信息;
步骤703、将得到的所有分片元数据信息按照分片编号由小到大升序排序;
步骤704、遍历排序后的所有分片元数据信息,对每个分片大小进行累加;
步骤705、当累加大小值大于字节开始位置from值时,记录该分片编号a,并继续累加分片大小值;
步骤706、当累加分片大小值大于读取结束位置from+size,记录该分片编号b作为结束位置。
步骤707、从记录的分片编号a开始读取,至记录的结束位置分片b,将此随机范围内的文件内容返回。
步骤八、针对大文件分片存储后,在分片上传写入或者读取过程中,当服务端异常导致写入或读取中断,在服务恢复后重新上传或读取断点的分片即可。
具体过程为:记录或查看被中断的分片编号,服务恢复正常后重新开始上传或下载被中断分片,上传中断之前该分片已经被写入的部分将会被覆盖,或者重新开始读取被中断分片内容。
本发明的优点在于:
1)、一种基于hbase的文件分片方法,在大文件的存储过程中将大文件进行分片,可以采用一个或多个线程读取对应分片内容,然后利用服务端的多个服务节点并发处理写入请求和分布式存储文件内容,使得大文件存储更加高效可靠。
2)、一种基于hbase的文件分片方法,以增加列的非结构化方式完成大文件分片存储时的元数据存储,以单独键值的方式将大文件每个分片独立存储于数据表中,在大文件写入读取时应对文件部分写入读取、随机读取和故障写入读取等情景变得更加灵活低耗。
3)、一种基于hbase的文件分片方法,在大数据大文件存储方面具有较强的实用性和适配性,具有很广泛的应用前景。
附图说明
图1为本发明一种基于hbase的文件分片方法原理图;
图2为本发明一种基于hbase的文件分片方法流程图;
图3为本发明大文件按粒度规则分片示意图;
图4为本发明大文件分片及元数据存储管理示意图;
图5为本发明大文件指定分片写入读取流程图;
图6为本发明大文件的文件范围内随机读取流程图;
图7为本发明大文件断点上传下载流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,下面将结合附图和实施例对本发明作进一步的详细说明。
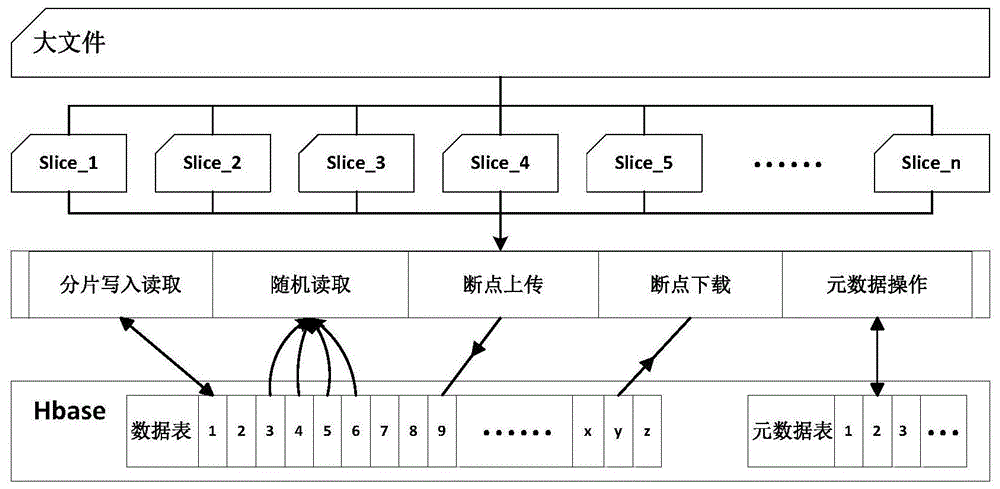
一种基于hbase的文件分片方法,采用hbase作为大文件数据分片存储时的数据内容分布式存储的存储介质和分片元数据信息存储的存储介质。如图1所示,在大文件数据写入时,将其按照一定片粒度进行切割分片,然后并发写入hbase将各个分片数据内容分布式存储在不同节点机器中,同时将各个分片的存储元数据信息以新增列的方式添加到该大文件的元数据信息表中,完成大文件分片存储的高效可靠。主要包含四部分:大文件按一定粒度分片技术、大文件分片存储管理技术、大文件分片随机读写技术和大文件分片断点上传下载技术。
大文件按一定粒度分片技术,是指大文件数据写入的过程中,将大文件按照一定粒度进行分片的过程;大文件分片存储管理技术,实现了大文件分片数据内容的分布式存储和分片元数据信息的存储管理。大文件分片随机读写技术,包括大文件指定分片写入读取和大文件在文件范围内快速随机读取。大文件分片断点上传下载技术,包含了大文件分片存储断点上传和大文件分片存储断点下载。
所述的一种基于hbase的文件分片方法,如图2所示,具体步骤如下:
步骤一、针对每个大文件,从系统中读取对大文件分片的配置文件和按分片粒度进行读取的配置文件。
如图3所示,将大文件按照配置文件读取分片粒度规则配置,包括:slicenum分片数量的配置和slicesize每片大小的配置;
分片数量指定后,根据大文件的大小确定各分片的大小及在大文件中的位置;如10则表示大文件将被切割为10个小片分布式存储到各个节点上。
分片大小指定后,按照分片大小对大文件进行内容读取,当读至文件末尾时最后一个分片的大小小于等于指定分片的大小。
将开启一个或多个线程分别并发读取大文件对应的分片内容,实现大文件分片存储。
步骤二、按照分片粒度规则将用户预备写入的某个大文件进行分片。
具体分片过程为:
针对用户预备写入的某个大文件,按照分片数量和大文件的大小确定每个片的平均大小,最后一个分片的大小小于等于每个片平均的大小。
或者当用户预备写入的数据为流式写入,将每次接收的数据流的固定大小作为每个片的大小,一定数量的片最终组成一个大文件进行存储,此时大文件为流式分片过程。
步骤三、判断文件内容的写入读取是否为指定片或者随机读取,如果是,进入步骤六,否则,进入步骤四按分片的顺序进行写入或读取;
步骤四、在对大文件进行分片后,通过多个并列线程将每个分片的内容以独立的键值存入hbase的数据表中。
在对某个写入的大文件进行分片完成以后,将开启一个或多个线程分别读取对应的片内容,以并发处理的方式将对应的片写入hbase数据表中。每一个分片的内容将会以独立的键值存入hbase的数据表中,值为该片的数据内容的二进制字节数组,键作为该片数据内容存储在数据表的rowkey的二进制字节数组,其中包含该大文件名称及该分片编号、分片大小等信息。
由于hbase存储底层采用字典序排序,需要根据实际业务要求进行rowkey的设计,既需要避免热点访问又要充分提高并发性。如图4所示,本实施例中rowkey的设计是:先以大文件的名称拼上下划线拼上分片编号拼上下划线拼上分片大小,即file_slicenum_size作为主体内容,然后将此内容hash取余该数据表的预分区region数,并用0补齐四位作为前四位散列数,再拼上之前的主体内容如0000_file_slicenum_size作为每个分片写入数据表时的rowkey。
由于大文件采用了分片写入,可以充分利用hbase服务端多个rs进行并发处理和分布式存储。
步骤五、同时,将大文件的相关信息写入到hbase元数据信息表中,同时将每个分片的元数据信息以新增列的方式存储在hbase元数据信息表中。
大文件写入时的相关信息,如名称name,类型type,标题title,大小size,拥有者own,写入时间time等;将在大文件写入时被写入到hbase元数据信息表中。
当大文件以分片方式写入时,每一个分片在将内容写入数据表之后又会在大文件的元数据表中在该大文件行中添加一个列,新增列的名称包含每个分片的编号如slice_0,列的值则为每个分片在数据表中对应rowkey的主体内容即file_slicenum_size,通过此信息能够索引定位每个分片在数据表中的位置,便于每个分片数据内容的读取。
关于大文件在元数据表中的rowkey同样采用大文件名称hash取余元数据表的预分区region数,并以0补齐四位后拼上下划线拼上大文件名称的方式如0000_file。在读取某个大文件某个分片内容时,需要先以大文件名称获得rowkey在元数据表中定位到该大文件的元数据,然后读取对应分片的列值得到该分片在数据表中存储时的主体内容,然后以此内容获得rowkey在数据表中定位到该分片的实际内容完成读取。
则大文件按照指定的粒度分片存储后,大文件元数据信息中将有与分片数目一致的包含分片编号的列与值存在,作为大文件分片的元数据信息存储。同时每当一个新的分片写入数据表后,将更新元数据信息表中大文件的大小列值与写入时间列值。
步骤六、判断文件内容的写入读取是否为指定片或者随机读取,如果是指定片,按照指定的分片编号写入读取文件内容;否则,进入步骤七进行随机读取。
当大文件按照粒度规则分片以后,可以不按照大文件既有的文件内容顺序写入文件分片,而是将文件内容按照指定的分片编号写入。同样的在大文件分片写入分布式存储以后,可以指定文件分片进行文件内容读取。因为大文件切割分片写入后每个分片在hbase数据表中是一个单独的存储单元,互相之间并不具备任何索引前后限制,故而可以进行指定分片写入和读取。
如图5所示,写入过程为:大文件分片写入时已经按照分片粒度规则,确定了大文件分片时各个分片在大文件中的位置和大小;同时确定了要写入的大文件的某个分片编号。首先、在大文件中移动文件指针,定位到要写入的指定分片的起始位置,然后读取该分片内容将该分片对应写入hbase的数据表中,并添加该分片的元数据信息到hbase元数据列。
读取过程为:大文件分片读取时大文件已经分片存储到数据表中;首先,确定要读取的大文件的指定分片编号;然后,根据大文件名称定位到hbase元数据表中该大文件存储的元数据,最后根据指定分片编号获得对应列的值即为该分片的元数据,在数据表中定位到该分片读取其内容。
步骤七、通过指定的开始位置和结束位置,随机读取大文件的存储内容。
当选择在大文件范围内随机读取时,可以指定读取的字节开始位置和读取的字节总大小,根据大文件元数据信息中各个分片的元数据信息,可以得到大文件所有存储分片的数目、编号顺序及每个分片的大小,通过定位和计算可以得到读取范围内应包含的某一个或某几个分片,在数据表中读取这些分片内容后返回指定读取范围的数据内容。
相对于大文件单独存储时随机读取情境下整个大文件数据范围内的指针移动内容读取,大文件分片存储随机读取只需要定位计算读取某一个或某几个分片返回即可,减少了磁盘io对于读取性能的影响。
如图6所示,具体步骤如下:
步骤701、设定随机读取的字节开始位置from和读取内容大小size配置值,从而得到随机读取的范围为from至from+size;
步骤702、根据大文件名称定位到hbase的元数据表中该大文件存储的元数据,读取所有分片列的分片元数据信息;
步骤703、将得到的所有分片元数据信息按照分片编号由小到大升序排序;
步骤704、遍历排序后的所有分片元数据信息,对每个分片大小进行累加;
步骤705、当累加大小值大于字节开始位置from值时,记录该分片编号a,并继续累加分片大小值;
步骤706、当继续累加分片大小值大于读取结束位置from+size,记录该分片编号b作为结束位置。
步骤707、从记录的分片编号a开始读取,至记录的结束位置分片b,将此随机范围内的文件内容返回。
步骤八、针对大文件分片存储后,在分片上传写入或者读取过程中,当服务端异常导致写入或读取中断,在服务恢复后重新上传或读取断点的分片即可。
当大文件上传过程中由于服务端异常导致写入失败,如果大文件并没有分片存储,此时的中断即表示需要重新上传此大文件,容错性较差。而如果大文件已经按照分片粒度规则分片并开始分片上传写入,当服务端异常导致写入失败,也只会导致某一个或者某几个分片的写入失败,在服务恢复后只需要重新开始上传失败了的分片即可。
同样的在大文件读取时,当读取过程中服务端异常,如果大文件并没有分片存储,再次下载时也只能重新开始下载。而如果大文件采用了分片存储,当服务端异常导致读取中断时,可以检查读取失败的分片重新开始下载即可,减少了因为故障中断而带来的数据恢复的耗费。
如图7所示,具体过程为:当大文件的某个或某几个分片在上传或下载过程中,服务端发生异常或者其他故障问题发生;导致大文件部分文件分片上传或下载被中断;记录或查看被中断的分片编号,服务恢复正常后重新开始上传或下载被中断分片,上传中断之前该分片已经被写入的部分将会被覆盖,或者重新开始读取被中断分片内容。
本发明通过对文件进行分片管理,将文件分片元数据存储到hbase中,提高了文件的并发处理的性能,减少了大文件处理时的单点负载问题。使用hbase作为文件分片元数据的存储,极大的扩展了文件元数据存储级别,为流式数据存储提供了解决方案。而且支持文件分片的片粒度配置,可以根据不同的场景进行调节。实现了分片文件范围随机读取对用户无感,也可以指定某片进行读取或写入,同时可以实现文件断点上传下载。在提高性能带来便利的同时,文件分片技术将文件切分放到不同的数据节点上,提高了数据存储的安全性。
- 还没有人留言评论。精彩留言会获得点赞!