一种支持动态精度的DNN加速器及其实现方法与流程
本发明涉及一种支持动态精度的dnn加速器及其实现方法。
背景技术:
当前定点计算中存在很多冗余位,这些冗余位带来的无效计算导致了定点位宽加速器性能的下降。量化是去除这些冗余位的有效手段,目前有很多针对dnn(深度神经网络)进行量化的算法如qnn,dorefa-net,wrpn,twn,xnor-net,在尽可能减小准确性损失的同时极大的降低了突触和神经元的位宽。同时这些算法表明,在不同网络模型之间对突触和神经元可以采用不同的位宽尺度进行计算。juddetal.提出了一种既能将准确性下降保持在很小的水平又能减少神经元位宽的策略,这种策略甚至可以在没有准确性损失的情况下降低神经元的位宽。该策略提出在同一网络的不同层之间对神经元可以采用不同的位宽。
之前的大多数加速器研究存在onefitsall问题,一种加速器通常按照最坏情况来对量化后的dnn进行计算。采用了并行计算的策略需要突触和神经元的位宽在整个网络中保持固定。
一些/极少数先进的加速器设计注意到了这个问题,提出了可变位宽加速器的设计,既能支持不同量化尺度的dnn模型,又能支持同一网络模型中不同层的神经元或突触位宽可变的情况。比如,str逐位串行输入神经元,同时并行输入固定位宽的突触,这种策略解决了在同一网络不同层中采用不同位宽的神经元所带来的灵活性。loom在str的基础上更进一步,通过输入和突触两者都逐位串行输入计算的方式,同时支持网络中可变的突触和神经元位宽,这种方式通过大幅提升突触带宽来提高性能。以上方法虽然采用了不同计算方式来提升灵活性,但是加速比性能不够突出。
在之前出现的变位宽加速器中,stripes,tartan,loom更重视位宽的灵活性而采用了串行设计,这种方式降低了并行计算所带来的益处。bitfusion采用2的幂的位宽设计来支持加速器位宽的灵活性,对8bit及其以下的神经元\突触采用并行计算,引入补码计算乘法,这种设计会增加计算和控制逻辑代价。
技术实现要素:
发明的目的在于提出一种支持动态精度的dnn加速器及其构建方法。
为实现上述目的,本发明采用如下的技术方案:
一种支持动态精度的dnn加速器,包括突触存储sbin、输入神经元存储nbin、输出神经元存储nbout以及s-pip阵列,s-pip阵列包括128*8个s-pip,突触存储sbin从dram中缓存128个卷积核,每个卷积核中突触值缓存到每个s-pip中的突触寄存器sr中,作为s-pip的一个输入;输入神经元存储nbin从dram中缓存8个神经元窗,每个神经元窗包含16个神经元值,每个神经元窗中的神经元值作为s-pip的一个输入;每个s-pip的计算结果输出到输出神经元存储nbout,输出神经元存储nbout缓存到dram中。
本发明进一步的改进在于,在s-pip阵列中,沿同一行的s-pip共享一个共同的32bit突触总线,沿同一列的s-pip共享一个共同的32bit神经元总线。
本发明进一步的改进在于,每个s-pip包括16个bip,一个32bit宽的突触寄存器sr,16个neg模块,一个16输入的加法树,2个累加移位模块psum1与累加移位模块psum2,以及max模块;s-pip的输入来自于突触存储sbin中的卷积核和输入神经元存储nbin中的神经元窗,其中,每个卷积核包含16个突触,每个神经元窗包含16个神经元;s-pip的计算结果输出到输出神经元存储nbout。
本发明进一步的改进在于,bip由与门,半加器和全加器组成,用于完成2bit无符号数的乘法计算;突触寄存器sr用于缓存来自卷积核中的16个被分解为不同数量组合的2bit的突触数据;每个bip的结果通过neg模块根据每一对突触和对应的神经元的乘积结果所对应的符号位,进行带符号的2的补码计算,并将计算结果输入到加法树,加法树对补码计算结果进行加计算,并将计算结果输送到累加移位模块psum1;累加移位模块psum1将加法树输出的计算结果进行累加移位,并将累加移位的结果输出到2选1多路选择器,当进行卷积层计算时,2选1多路选择器将累加移位模块psum1结果输出到累加移位模块psum2;当进行全连接层计算时,2选1多路选择器将上一s-pip列中的部分和输出到累加移位模块psum2。
本发明进一步的改进在于,累加移位模块psum1和累加移位模块psum2中使用2bit移位;为兼容最坏情况,s-pip的突触和神经元位宽均采用16bit,因此突触和神经元buffer的深度设置为8。
本发明进一步的改进在于,累加移位模块psum2的另一个输入为nb,nb用于判断突触-神经元对的计算数目是否超过窗口大小;如果超过,则将来自输出神经元存储nbout的部分和与当前的累加移位模块psum2的计算结果进行累加,并将累加结果输出到输出神经元存储nbout。
本发明进一步的改进在于,当neg模块的输入最高有效位为1时,加法树从部分和中减去对应于msb的突触和神经元的bip结果。
一种支持动态精度的dnn加速器的实现方法,dnn加速器结构在卷积层上的计算:dnn加速器中的所有s-pip计算同步执行;首先将分解的2比特突触从缓存中送入不同s-pip阵列中的列中的sr,其次将分解为2比特的神经元送入到s-pip阵列中的行中的bip中,并和来自sr的突触进行乘积计算,然后将乘积结果移位累加,最终经过激活值函数单元输送到输出神经元存储nbout;
dnn加速器在池化层上计算:一个完整的卷积窗口的卷积计算结果通过psum2输出作为max模块的一个输入,输出神经元存储nbout反馈的i_nbout作为max模块的另外一个输入;每完成一次完整卷积窗口的计算时进行一次池化窗口计数,然后max模块对两个输入值进行比较,其中的较大值暂时作为最大值,当计数达到池化窗口大小时,将最大值输出到输出神经元存储nbout;
dnn加速器结构用在全连接层上的计算:神经元位宽设置为16位,包括以下几个步骤:
1)从dram中缓存突触和神经元数据到突触存储sbin和输出神经元存储nbout,在第一周期中,首先将第一个128组分解的突触中的(s,s-1)bit存储在第一s-pip列的sr中;之后将第一个神经元窗口的(n,n-1)bit(n为神经元的位宽,每个窗口16个神经元)送到第一s-pip列的bip中进行计算;其中s为突触的位宽,一组突触的数目为16;
2)第二个周期,首先将第二个128组分解的突触的(s,s-1)bit送入第二s-pip列的sr中,其次将第二个神经元窗的(n,n-1)bit送入到第二s-pip列中的bip中进行计算,同时,将第一个神经元窗的(n-2,n-3)bit送入到第一s-pip列的bip中,保存在第一s-pip列中的sr中的突触(s,s-1)bit在本周期保持不变;
3)之后的s-pip列中的计算按照步骤1)和步骤2)中的方式依次类推;8个周期后,在第一s-pip列中,第一个128组突触的(s,s-1)bit数据和第一个神经元窗口的神经元完成乘积计算,在剩余7个s-pip列中,不同的128突触的(s,s-1)bit数据和神经元仍然按照步骤1)和步骤2)中方式进行计算,其中,第8个128组突触的(s,s-1)bit和第8个神经元窗的(n,n-1)bit开始计算;
4)第9个周期,首先将第一个周期送入的第一个128组突触的(s-2,s-3)bit送入第一s-pip列中,其次将第一个神经元窗的(n,n-1)bit重新送入第一s-pip列中的bip中;重复步骤1)到步骤3)的过程;第8个128组突触的(s-2,s-3)bit和第8个神经元窗开始计算,直到(es/2)*8个周期后将第一个神经元窗的16个神经元和第一个128组突触计算结束,剩余的s-pip列中继续计算直到计算完所有数据;
5)在步骤4)中计算得到的结果送入第二s-pip列中进行累加,依次类推,经过(es/2)*8+8个周期后,最终的8个神经元窗和128组突触的乘加结果沿s-pip阵列的每一行输出到输出神经元存储nbout。
本发明进一步的改进在于,步骤4)中奇数位宽的突触/神经元扩展为偶数位宽的突触/神经元,突触位宽为es,神经元位宽为en,es和en均是偶数。
与现有技术相比,本发明具有的有益效果:
本发明在选择计算位宽的问题上提升加速器的效率和弹性,提出了dnn加速器,即一种可变位宽dnn加速器架构,它将神经元\突触的位宽分解为不同长度的2bit数据,2bit数据串行输入进行计算,2bit突触和2bit神经元的乘法采用原码。本发明具有以下优点:
(1)加速比:在相同的输入数据量和相同的计算吞吐量同时准确性保持为100%的情形下,平均而言,本发明相对于dadiannao,stripes和loom在主要网络模型的卷积层上分别获得了2.42×,1.24×,1.78×的性能提升,在全连接层上相对于stripes和loom分别获得了1.42×和1.7×的加速。
(2)带宽及存储:和stripes,loom相比,dnn加速器的神经元存储带宽降低了一半,但是计算带宽保持不变,突触的存储带宽保持不变,计算带宽是loom的2倍,突触的存储规模和loom相同;相对于dadiannao提高了片上的突触存储规模,减少了片外的突触读取;在匹配dadiannao的计算峰值带宽的情况下,dnn加速器的神经元存储相对于loom减少了1/2。
附图说明
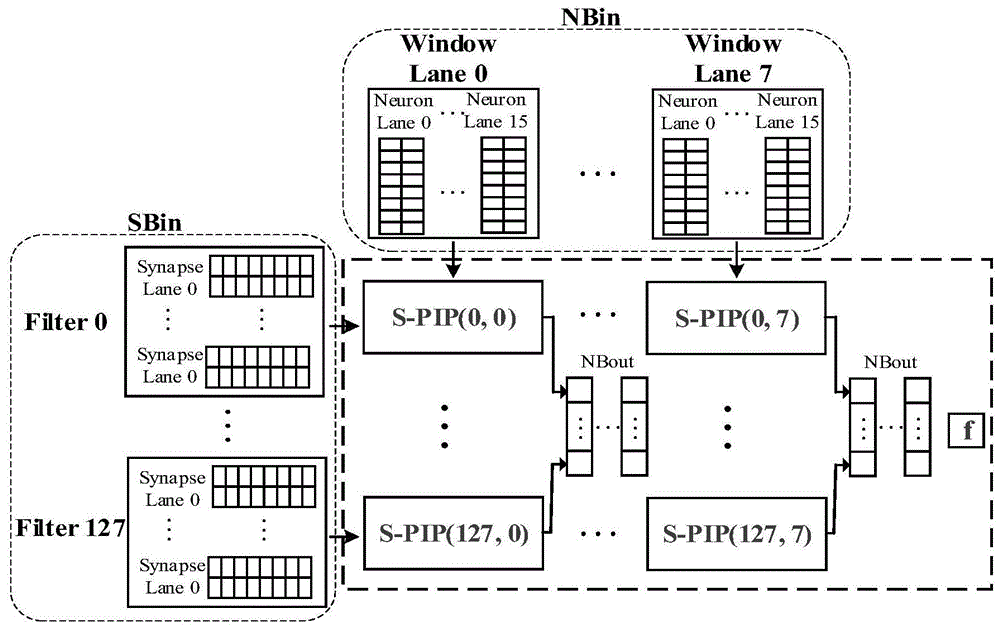
图1是本发明中加速器dnn加速器的整体结构图。
图2是本发明中加速器dnn加速器的组成单元s-pip(serial-parallelinnerproduct)结构图。
图3是本发明中s-pip的组成单元bip(basicinnerproduct)结构图。
图4是本发明中p-sip处理2个4bit操作数和另外2个4bit操作数的乘加运算的结构示意图。
图5是本发明中p-sip在4个时钟周期内处理2个4bit操作数和另外2个4bit操作数乘加运算的过程示意图。
具体实施方式
下面结合附图和实施例对本发明作更详细的说明。
本发明中的*表示相乘。
参见图1,本发明的支持动态精度的dnn加速器包括突触存储sbin、输入神经元存储nbin、输出神经元存储nbout以及s-pip阵列,s-pip阵列包括128*8个s-pip,突触存储sbin从dram中缓存128个卷积核,从filter0到filter127,其中每个卷积核包含16个突触,每个filter中突触值缓存到每个s-pip中的sr(突触寄存器,突触寄存器为32比特宽)中,作为s-pip的一个输入。输入神经元存储nbin从dram中缓存8个神经元窗,从window0到window7,每个神经元窗包含16个神经元值,每个神经元窗中的神经元值作为s-pip的一个输入。每个s-pip的计算结果输出到输出神经元存储nbout,输出神经元存储nbout缓存到dram中。输出神经元存储nbout的输出经过激活函数单元即图中的f得到激活值,将激活值反馈到s-pip中,通过累加,得到一个完整的卷积核和对应的输入神经元之间的卷积结果。
在s-pip阵列中,沿同一行的s-pip共享一个共同的32bit突触总线,即16*2bit,沿同一列的s-pip共享一个共同的32bit神经元总线。
参见图2,每个s-pip(serial-parallelinnerproduct)包括16个bip(basicinnerproduct),一个32bit宽的sr(突触寄存器),16个neg模块,一个16输入的加法树和2个累加移位模块psum1与psum2,同时还包括了max模块。s-pip的输入来自于突触存储sbin中的filter(卷积核)和突触存储nbin中的windowlane(神经元窗),每个filter包含16个突触,每个windowlane包含16个神经元;s-pip的计算结果输出到输出神经元存储nbout。
参见图3,bip由与门,半加器和全加器组成,主要用于完成2bit无符号数的乘法计算。突触寄存器sr用于缓存来自filter中的16个被分解为不同数量组合的2bit的突触数据。每个bip的结果通过neg模块处理后发送到16输入的加法树。neg模块根据每一对突触和对应的神经元的乘积结果所对应的符号位,进行带符号的2的补码计算,并将计算结果输入到加法树,加法树对补码计算结果进行加计算,并将计算结果输送到累加移位模块psum1;累加移位模块psum1将加法树输出的计算结果进行累加移位,具体过程为:对16个突触中的某2bit数据和16个神经元的乘积结果累加移位;并将累加移位的结果输出到2选1多路选择器,当进行卷积层计算时,2选1多路选择器将累加移位模块psum1结果输出到累加移位模块psum2;当进行全连接层计算时,2选1多路选择器将上一s-pip列中的部分和输出到累加移位模块psum2。
累加移位模块psum2对接收到的结果进行累加移位,当进行卷积层计算时,累加移位模块psum2对psum1的输出数据进行累加移位,当进行全连接层计算时,累加移位模块psum2对上一s-pip列中的部分和进行累加。累加移位模块psum1和psum2中使用2bit移位。为兼容最坏情况,s-pip的突触和神经元位宽均采用16bit,因此突触和神经元buffer的深度被设置为8。为了支持超过16个输入值的卷积窗口,从nbout读回数据以初始化psum2中的累加器并和psum2的输出结果累加得到一个完整的卷积窗的卷积计算结果,nb作为累加移位模块psum2的另一个输入(一个输入为累加移位模块psum1的输出结果),用于判断突触-神经元对的计算数目是否超过窗口大小。如果超过,则将来自输出神经元存储nbout的部分和与当前的累加移位模块psum2的计算结果进行累加,并将累加结果输出到输出神经元存储nbout。
当neg模块的输入msb(最高有效位)为1时,即neg模块的输入为负数时,加法树必须从部分和中减去对应于msb的突触和神经元的bip结果。
s-pip中不同突触和神经元位宽的数据被分解为不同数量的2bit的数据组合,被分解的2bit数据通过bip计算得到的结果最终被融合得到高位宽数据进行乘加计算的正确结果。这种数据分解方式扩展了计算的灵活性,避免了所有数据均采用统一位宽进行计算的情况。
s-pip阵列同步工作处理突触和神经元花费时间的具体计算过程为:突触位宽度表示为es,神经元位宽度表示为en,两者均用偶数表示。在en/2周期后,psum1的结果被级联到psum2中以进行累加和移位。在(es×en)/4个周期之后,得到由16个突触和16个神经元乘加结果。
本发明的支持动态精度的dnn加速器的实现方法如下:
dnn加速器每个周期完成总计256*16*16bit的计算。
dnn加速器结构在卷积层上的计算过程为:在进行卷积计算时,dnn加速器中的所有s-pip计算同步执行;首先将分解的2比特突触从缓存中送入不同s-pip阵列中的列中的sr,其次将分解为2比特的神经元送入到s-pip阵列中的行中的bip(基本内积)中,并和来自sr的突触进行乘积计算,然后将乘积结果移位累加,最终经过激活值函数单元输送到输出神经元存储nbout。
在dnn加速器的结构中,突触的峰值计算带宽为128×16位,神经元的峰值计算带位宽为128位。在一个卷积层的计算中,同一卷积核中的一个突触在多个神经元窗口之间共享,并且同一神经元窗口中的一个神经元在不同卷积核中的突触之间共享。dnn加速器使用8个神经元窗口,每个窗口包含16个神经元,同时使用了128组突触,每个突触包含16个突触数据,完成这些数据的计算共花费(es×en)/4×4个周期。
dnn加速器结构用在全连接层上的计算过程为:在全连接层计算中,神经元位宽设置为16位,突触位宽可变,不影响分类精度。
dnn加速器在池化层上计算过程为:s-pip中引入了max模块,max模块用于确定最大值池化值。一个完整的卷积窗口的卷积计算结果通过psum2输出作为max模块的一个输入,输出神经元存储nbout反馈回来的i_nbout作为max模块的另外一个输入。每完成一次完整卷积窗口的计算时进行一次池化窗口计数,然后max模块对两个输入值进行比较,其中的较大值暂时作为最大值,当计数达到池化窗口大小时,将最大值输出到输出神经元存储nbout。
全连接层的计算过程主要包括以下几个步骤:
1)从dram中缓存突触和神经元数据到突触存储sbin和输出神经元存储nbout,在第一周期中,首先将第一个128组分解的突触中的(s,s-1)bit(s为突触的位宽,每组包含16个突触)存储在第一s-pip列的sr中。之后将第一个神经元窗口的(n,n-1)bit(n为神经元的位宽,每个窗口16个神经元)送到第一s-pip列的bip中进行计算。
2)第二个周期,首先将第二个128组分解的突触的(s,s-1)bit送入第二s-pip列的sr中,其次将第二个神经元窗的(n,n-1)bit送入到第二s-pip列中的bip中进行计算,同时,将第一个神经元窗的(n-2,n-3)bit送入到第一s-pip列的bip中,保存在第一s-pip列中的sr中的突触(s,s-1)bit在本周期保持不变。
3)之后的s-pip列中的计算按照步骤1)和步骤2)中的方式依次类推;8个周期后,在第一s-pip列中,第一个128组突触的(s,s-1)bit数据和第一个神经元窗口的神经元(16bit)完成乘积计算,在剩余7个s-pip列中,不同的128突触的(s,s-1)bit数据和神经元仍然按照步骤1)和步骤2)中方式进行计算,其中,第8个128组突触的(s,s-1)bit和第8个神经元窗的(n,n-1)bit开始计算。
4)第9个周期,首先将第一个周期送入的第一个128组突触的(s-2,s-3)bit送入第一s-pip列中,其次将第一个神经元窗的(n,n-1)bit重新送入第一s-pip列中的bip中。重复步骤1)到步骤3)的过程即第一个128组突触的(s-2,s-3)bit和第一个神经元窗口的16bit神经元做乘积计算,其余的s-pip列仍然采用上述步骤1)到步骤2)进行计算,其中,第8个128组突触的(s-2,s-3)ibt和第8个神经元窗开始计算。直到(es/2)*8个周期后将第一个神经元窗的16个神经元和第一个128组突触计算结束,即第一s-pip列的计算结束,剩余的s-pip列中继续计算直到计算完所有数据。
5)在步骤4)中计算得到的结果送入第二s-pip列中进行累加,依次类推,经过(es/2)*8+8个周期后,最终的8个神经元窗和128组突触的乘加结果沿s-pip阵列的每一行输出。
步骤5)中的计算方式相当于将全连接层的计算结果分解在一行中不同s-pip单元中,因此,不同组突触需要以交错的方式送入sbin,即将分解的相同位(如高2bit)的数据存储在一起,在计算时加载至某一s-pip列中的sr中,同时其他s-pip仍然列进行不同神经元窗中的神经元和对应的128组突触的乘加计算。和卷积计算方式相比,这里仅需要修改控制方式。
在s-pip阵列中,每行的s-pip级联在一起,并且一个s-pip的输出通过多路复用器作为下一个s-pip的输入。该级联将上一列的结果级联到本列和本列的输出结果做累加,主要用于全连接层,同时用于反馈卷积的部分和结果以进行累加得到完整的卷积结果。以提高s-pip阵列中计算单元的利用率。
为了便于理解支持动态精度的dnn加速器在卷积层和全连接层上的计算方式,下面通过一个简单的实施例进行说明。
图3是s-pip的组成单元bip(basicinnerproduct),2个2bit无符号的操作数x1x0和y1y0作为输入。有符号数的处理过程中,符号位被取出单独进行计算,符号位被送入s-pip中的neg模块中进行判断。原来的符号位被0代替,这样得到完全的无符号数以便于在bip中进行计算。
图4是s-pip处理2个4bit操作数a3a2a1a0,b3b2b1b0和2个4bit操作数c3c2c1c0,d3d2d1d0的乘加运算的结构,这个结构作为一个简单例子对dnn加速器中的基本单元s-pip的工作方式进行了说明。4bit的操作数被分解为两个2位操作数作为bip的输入。每个操作数中的符号位被分开用xor计算,并且计算得到的msb的结果将在shift-add单元的neg模块中判断以支持2的补码。
图5是p-sip在4个时钟周期内处理2个4bit操作数a3a2a1a0,b3b2b1b0和2个操作数c3c2c1c0,d3d2d1d0的过程,4个周期的过程如下,
1)周期0,操作数0a2,0b2首先被送入寄存器ar和br中,其次bip0和bip1分别将0a2,0b2与0c2,0d2相乘;最终2个bip的被结果馈入移位添加单元进行累加。
2)在周期1,操作数0a2和0b2分别保持在寄存器中不变,同时操作数c1c0,d1d0在buffer中分别移位到操作数0c2和0d2,操作数0c2和0d2在buffer中被移位到操作数c1c0,d1d0。之后bip0和bip1分别将c1c0,d1d0与0a2,0b2相乘,最终2个bip的计算结果在移位加单元中累加。
3)在周期2,首先操作数a1a0,b1b0被送入寄存器ar,br中覆盖之前的数据,其次操作数0c2和0d2在buffer中被移位到操作数c1c0,d1d0。bip0和bip1分别将a1a0,b1b0与0c2,0d2相乘,最终2个bip的乘积结果被累加。
4)在周期3,操作数a1a0和b1b0保持不变,同时操作数c1c0,d1d0在buffer中分别移位到0c2和0d2,之后bip0和bip1分别将a1a0,b1b0与c1c0,d1d0相乘,最终2个bip的乘积结果被累加。
经过上述4个周期,得到的结果即为2个操作数a3a2a1a0,b3b2b1b0和2个操作数c3c2c1c0,d3d2d1d0分别对应做乘加的结果。
bip要得到正确的结果,需要按照数据位宽分解为不同数量的2bit值,因此,奇数位宽的突触/神经元需要被扩展为偶数位宽的突触/神经元,即在位宽为奇数的突触/神经元符号位后增加一个0值。位宽分别表示为es和en的突触和神经元(es和en分别是偶数)。
本发明具有以下优点:
(1)加速比:在相同的输入数据量和相同的计算吞吐量同时准确性保持为100%的情形下,平均而言,本发明相对于dadiannao,stripes和loom的加速比计算公式分别为256/((es*en/4)*4),(16*pn)/((es*en/4)*4),(ps*pn*2)/((es*en/4)*4),其中ps,pn表示突触和神经元的实际位宽。根据计算公式,本发明在主要网络模型的卷积层上相对于dadiannao,stripes和loom分别获得了2.42×,1.24×,1.78×的性能提升。本发明在全连接层上相对于stripes和loom的加速比计算公式分别为64/((es*16/4)+8),(2*((es*16/4)+8))/(ps*16+16),根据计算公式,本发明在主要网络模型上的全连接层上相对于stripes和loom分别获得了1.42×和1.7×的加速。
(2)带宽及存储:和stripes,loom相比,dnn加速器的神经元存储带宽降低了一半,突触的存储带宽保持不变,计算带宽是loom的2倍,突触的存储规模和loom相同”但是计算带宽保持不变;提高了片上的突触存储规模,减少了片外的突触读取;在匹配dadiannao的计算峰值带宽的情况下,本发明的dnn加速器的突触存储相对于loom减少了1/2。
通常可变精度加速器由全串行,全并行和串行并行计算单元实现。但是,太多的并行单元可能会导致计算无效位。而过多的串行单元可能会失去并行性带来的加速优势。因此,本发明提出了一种灵活的支持动态精度的dnn加速器,它利用低位串行—并行组合计算单元实现dnn加速器的高效率和弹性。将不同的粒度精度(从32位到3位神经元/突触宽度)分解为2位用于串行计算,而2位精度是并行计算的。dnn加速器在低位并行性上保持其并行化加速优势,并在高位串行保持其计算灵活性。图像分类数据集上的实验结果表明,dnn加速器相比于dadiannao,stripes在准确性没有损失的情况下在卷积层上性能提升2.43x,1.24x,相比于dadiannao,在全连接层上性能提升1.42x。
- 还没有人留言评论。精彩留言会获得点赞!