用于在卷积神经网络中进行矩阵处理的方法和设备与流程
本公开总体涉及矩阵处理,并且更具体地涉及卷积神经网络。
背景技术:
利用计算机视觉处理的传统的基于相机的物体识别系统被用于各种市场,例如:汽车;机器人;产业;可穿戴计算;和移动。在过去,这些系统使用定制设计的特征,然后是预先训练的分类器,以对图像中的感兴趣物体进行分类。现代分类系统实现“深度学习”技术,例如通过更强大和更便宜的计算资源实现的卷积神经网络(cnn)。
cnn结构通常接收输入数据,并且用一组预先训练的权重来对输入数据的样本进行卷积,该输入数据通常是rgb彩色图像。非线性激励函数(例如双曲正切、sigmoid、relu)跟随卷积层。若干此类卷积层一起使用以提供稳健的特征识别。在卷积层之间插入池化层(通常是最大池化),以提供图像数据中物体大小的一些不变性。池化还有助于受控地保持实现cnn的器件的物理特征大小。通常,池化沿着特征平面的宽度方向和高度方向将特征尺寸减小到大约二分之一。
全连接神经网络处理所学习的输出特征矢量以进行分类。可以存在若干此类全连接层,导致“软-最大”层,其横跨各种感兴趣的类别将结果标准化。存在非常深(多个层)和非常宽(每层更多卷积通道)的多个网络拓扑。这种宽且深的网络导致高达数百千兆(giga)或兆兆(tera)乘法和添加操作(“每秒千兆操作”(gops)或“每秒兆兆操作”(tops))的巨大计算和数据复杂性。与卷积层相比,全连接层使用巨大的数据带宽,并且通常在使用矩阵乘法器的物理实施方式中实现。优化的软件实施方式提高现有器件的性能,然而它们无法提供在期望时间段内完成卷积和特征识别所需的巨大计算资源。因此,cnn经常使用专用硬件。在现场可编程门阵列(fpga)以及专用集成电路(asic)和复杂逻辑可编程器件(cpld)上存在一系列优化的cnn硬件实施方式。这些解决方案使用收缩和流式架构,以实现最佳功率、性能和面积目标。这些解决方案的一个限制是较低的性能。这些实施方式的性能范围为10或100的gops。此外,这些解决方案受到数据移动的严重瓶颈。
技术实现要素:
在一个示例方面,一种集成电路包括:矢量乘法单元,其包括多个乘法/累加节点,其中矢量乘法单元可操作以使用两个输入矢量的外积来提供来自乘法/累加节点的输出;第一数据馈送器,其可操作以便以矢量格式向矢量乘法单元提供第一数据;以及第二数据馈送器,其可操作以便以矢量格式向矢量乘法单元提供第二数据。
附图说明
图1是卷积神经网络的框图。
图2是一个示例神经网络的连接图。
图3是多模式引擎的框图。
图4是外叉乘积的实施方式的图示。
图5是示出矢量乘法单元(vmu)可以如何实现外积的图。
图6是一个示例的一个乘法/累加节点的框图。
图7是示出确定卷积的一个特征值的图示。
图8-图10示出使用vmu以有效地计算卷积的操作。
图11是示出在示例中可以如何有效地交织多组权重以充分利用vmu的图表。
图12-图14示出使用两个输入矩阵和多个权重矩阵的替代示例。
图15是用于与一个示例一起使用的权重馈送器单元(wfu)的详细图。
图16是用于与一个示例一起使用的数据馈送器单元(dfu)的详细图。
图17是一个方法示例的流程图。
图18是另一示例方法的流程图。
图19是另一示例方法的流程图。
具体实施方式
除非另外指出,否则附图中的对应的数字和符号通常指代对应的部分。附图不一定按比例绘制。
术语“耦合”可以包括利用中间元件进行的连接,并且在“耦合”的任何元件之间可以存在附加元件和各种连接。
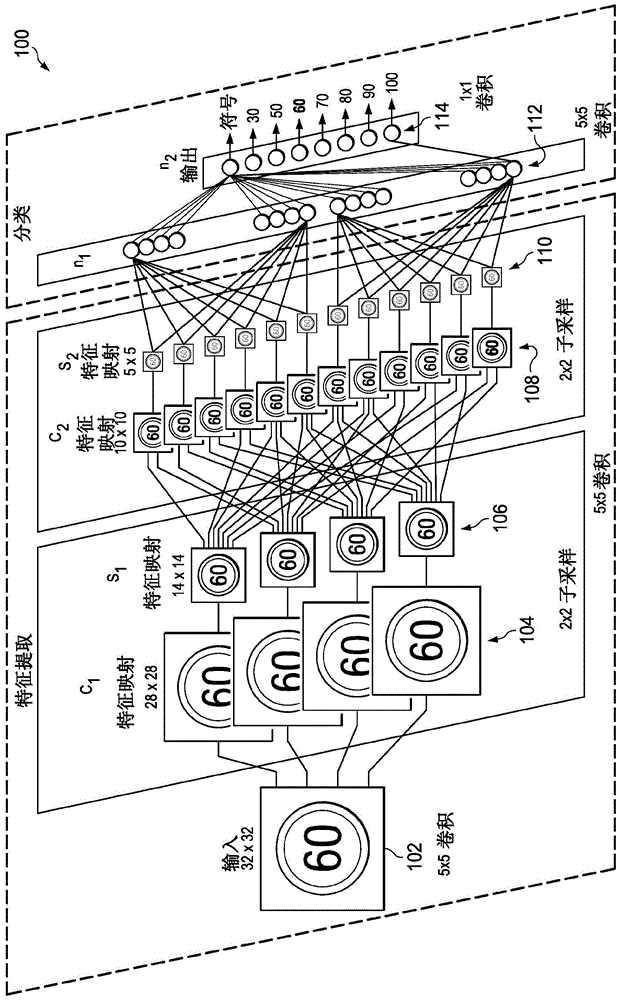
图1是卷积神经网络的框图。卷积神经网络(cnn)100包括图像输入102、特征映射层104、106、108和110、全连接层112和输出114。本说明书假定该示例cnn已被训练以识别图像中的图案并且它是处理来自视觉输入的数据。在图1的简化图中,使用卷积滤波器将32×32特征值图像输入102处理成特征映射104。在该示例中,卷积滤波器是5×5权重值,并且横跨图像输入102逐步地(卷积)移动,如下文进一步解释的。特征映射104的2×2子采样产生特征映射106。特征映射106的卷积产生特征映射108。特征映射108的子采样产生特征映射110。全连接层112对特征映射110进行分类,其后是输出114处的最终非线性处理。输出114产生学习特征存在于输入中的概率。如下文进一步解释的,这些步骤包括复杂矩阵数学。整体处理负荷非常大,因此应该非常有效地执行该处理。使用的矩阵大小是用于解释目的的示例,也可以使用其他大小。
图2是类似于图1中的全连接层112的示例全连接层200的连接图。输入层202将来自卷积步骤(对应于图1中的102-110)的特征映射提供到第一隐藏层204以用于处理。特征映射是由隐藏层204的节点处的特征标识符滤波器相乘的矩阵。隐藏层204将该滤波的结果提供到隐藏层206,在隐藏层206中发生与附加特征标识符滤波器的附加矩阵相乘。隐藏层206馈送输出层208。图2示出两个隐藏层。但是,可以使用任何数量的隐藏层,这取决于主题和可用计算资源。另外,图2示出隐藏层204的每个节点连接到隐藏层206的每个节点。隐藏层之间的每个节点可以或可以不连接到下一个隐藏层中的节点,这取决于网络学习过程和正在处理的主题。输出层208类似于输出114(图1)。
图3是示例图像处理设备或多模式引擎(mme)300的框图。二级(l2)存储器302经由主端口304从主存储器(未示出)传递数据。安全配置寄存器(scr)306将指令和滤波器权重分别路由到mme控制器308和权重馈送器单元(wfu)310。l2存储器302还将图像数据馈送到数据馈送器单元(dfu)312。数据馈送器单元312提供n个数据输入,并且权重馈送器单元向矢量乘法单元(vmu)314提供m个数据输入。vmu314包括n×m个乘法/累加节点的矩阵,如下文进一步解释的。在一个示例中,n等于m,并且因此n×m个乘法/累加节点的矩阵是方阵。vmu314执行大部分操作以提供上文关于图1和图2描述的卷积和全连接层操作的矩阵运算。下文进一步解释vmu314的操作。如关于图1所描述的,特征处理单元316执行输出层114的非线性激励函数和/或空间池化(例如,子采样)。
mme300的全部或一部分可以并入集成电路、混合模块中,或者可以实现为集成电路或模块的组合。在替代示例中,mme300可以使用诸如微处理器、视频处理器、混合信号处理器、数字信号处理器或中央处理单元(cpu)的可编程器件来实现。可以使用与诸如数字信号处理器(dsp)内核、arm内核、risc内核和图像处理内核等附加电路集成的内核。可以使用用户可定义的电路,例如专用集成电路(asic)或半定制或定制集成电路。可以使用用户可定义的可编程器件,例如现场可编程门阵列(fpga)和复杂逻辑可编程器件(cpld)。在通用计算机、处理器或微处理器上执行的软件可以用于实现mme300。
图4是外叉乘积的操作的图示。外叉乘积不是使用两个矩阵(或矩阵)的乘积,而是两个矢量的叉乘积,以产生部分输出。如下文进一步解释的,矢量是矩阵的一部分。在图4中,矢量402是由数据馈送器单元312(图3)提供的图像数据(和/或特征值),其包括来自图像数据(或特征)的4×4部分的16个值(值的精度为16位)。矢量404也是16值矢量。这些矢量的叉乘积是16×16的矩阵406。然而,如下文进一步解释的,当确定卷积或全连接数据点时,该外积本身不提供完整的解决方案。
图5是示出使用vmu500(如vmu314(图3))进行诸如图4中所示的外积操作的示例实施方式的图。权重数据504对应于矢量404(图4),并且由wfu310(图3)提供。图像数据502对应于矢量402(图4)并且由dfu312(图3)提供。vmu矩阵508中的交叉点具有乘法/累加(mac)节点506。
图6是一个乘法/累加(mac)节点600(如图5中的mac节点506)的框图。乘法器602接收一个权重字节和一个输入字节,并将结果输出到第一累加器604或第二累加器606。乘法器602的乘法与第一累加器604或第二累加器606的累加(加法)在时钟周期期间发生。如下文更全面地解释的,来自乘法器602的结果是部分结果。累加器将部分结果添加到先前的部分结果中,直到可以读出完整结果。术语“乘法/累加”描述了该操作。
图7是示出确定卷积的特征值(诸如像素数据)的图示。在图7中,对于输出矩阵708的特征值,权重矩阵704被叠加在输入特征平面702上。例如,为了确定输出矩阵708中的卷积特征值706(标记为“33”),感兴趣的特征值乘以权重矩阵的中心特征值22。权重乘以读取面积,该读取面积包括围绕感兴趣的特征值的对应的输入特征值。结果是这些乘法对的总和。等式1以数学方式表达该过程。
其中output是输出矩阵708,input是输入特征平面702,m和n分别是如矩阵708所示的输入的行和列坐标,i和j分别是如权重矩阵704所示的权重矩阵的行和列坐标,并且w是权重矩阵。然后将权重矩阵704移位以确定下一个输出或特征值,直到计算出输出矩阵。
图8-图10示出使用图5的示例vmu来有效地计算卷积。输入802和权重804不对应于输入特征平面702的输入矩阵和权重矩阵704(图7)。而是,dfu312和wfu310(图3)重新布置数据和权重,使得由vmu806针对一个输出特征值计算的部分乘积被引导到一个乘法/累加节点506(图5)内的一个乘法器和一个累加器。在一个示例中,输入802一次将一列加载到vmu806中。列中的每个像素被呈现给vmu806的一行中的所有乘法/累加节点。来自权重804的一行权重(在该行权重中,每个权重是来自十六个卷积滤波器的对应的权重)也加载到vmu806中。例如,权重矩阵704(图7)包括从00到44的二十五个权重。在第一步骤中,从权重804加载的该行权重是对于十六个卷积滤波器的00权重。大多数中间图像由多个卷积滤波器处理。例如,输入层202(图2)的每个节点具有四个卷积滤波器,其被应用于产生用于隐藏层204(图2)的四个节点的数据。图2被大大简化。大多数应用程序中的隐藏层是十六或三十二个节点。当来自一个节点的输入数据被应用于多个卷积时,一次应用十六个卷积增加了处理速度。因此,输入数据802的十六个字节与来自十六个卷积滤波器的一个权重字节作为一行权重804相乘。这产生了在vmu806的节点中累加的256个乘法。
图9示出图8中所示的步骤的下一步骤。下一行权重数据将是来自十六个卷积滤波器的下一个权重。例如,下一个权重可以是来自权重矩阵704(图7)的权重01。来自输入802的下一列。下一列输入802中的数据对应于要被应用权重01的图像像素。然后在vmu806的对应的节点中累加该结果。在图8-图10的示例中,权重804具有25个权重(例如,00到44)。图10示出二十五个周期后的结果。每行权重804已经应用于来自输入802的对应的输入像素列。因此,来自每个节点的累加数据是对应的像素的完整卷积,如结果矩阵808所示。也就是说,vmu806的第一列包含用于第一卷积滤波器的十六个完整卷积像素,vmu806的第二列包含用于第二卷积滤波器的十六个完整卷积像素,依此类推,使得vmu806的每列包含用于十六个卷积滤波器之一的十六个完整卷积像素。
图11是示出加载用于多重卷积的权重的过程的图表。在该示例中,卷积层(1102、1104)被组织成组,其中每个组包括用于十六个接收因子(rf)的权重。接收因子是来自每个卷积滤波器上的一个位置(例如,权重矩阵704中的00位置)的权重。图表1106示出第一组在第一周期中处理,第二组在第二周期中处理,依此类推,直到第九周期。在图表1106的示例中,卷积滤波器是3x3的,因此有九个周期。然后对下一个卷积层(例如,卷积层1104)重复该过程,直到对输入图像完成卷积。
图12-图14是示出使用两个输入矩阵的有效示例的框图。对于两个十六字节输入矢量1206和一个十六字节权重矢量1205,分别输入两组特征平面1202和十六个权重矩阵1204。与图8-图10的示例一样,权重矢量1205包括来自权重矩阵中的对应的位置的一个权重。权重矩阵1204和从权重矩阵1204到权重矢量1205的线表示十六个权重矩阵和十六个权重值。两组n个值(在该示例中,n=16)被路由到vmu1210的输入矢量1206中。矩阵1208表示存储在vmu1210的累加器中的数据。图12的示例在一个周期中使用一个输入矢量。权重输入矢量1205被应用两个周期。也就是说,将一个输入矢量乘以权重输入矢量1205的结果被存储在第一累加器604或第二累加器606(图6)中。将另一输入矢量与权重矢量1205相乘的结果被存储在第一累加器604或第二累加器606(图6)中的另一个中。这通过避免重新获取权重矢量1205的需要来提供附加的效率。对于权重矩阵的每个权重位置重复该过程。图12-图14的示例包括每个权重矩阵1204中的25个权重位置。因此,周期的总数i(迭代)是权重矩阵的大小l(在该示例中为25个权重值)乘以输入矩阵的数量k(在该示例中k=2)。因此,在k×l=i个周期(在图12-图14的示例中为50个周期)之后提供完全输出,以产生两个十六乘十六个输出特征值。图13示出在两个周期之后使用图12的结构进行的卷积处理,图14示出该部分卷积的最终输出。一次获取的输入矩阵和权重矩阵的数量可以根据vmu1210的大小和矩阵的大小而变化,其目标是充分vmu利用以最大化吞吐量。
更一般地,在图12-图14所示的示例处理中,处理周期可以被划分为多组k个处理周期,其中一组处理周期中的k个处理周期中的每一个相对于同一组权重值以及相对于k个特征平面中的同一组像素位置处理包括在k个特征平面中的不同特征平面中的像素值。每个权重矩阵1204可以对应于相应的cnn滤波器,并且可以替代地称为一组权重值。可以选择来自每个权重矩阵1204的第一权重值以形成用于第一组处理周期的第一组权重值。一组权重值中的每个权重值可以对应于不同的cnn滤波器,并且一组权重值可以对应于来自不同cnn滤波器中的公共权重值位置的权重值。
对于第一组处理周期,可以选择来自特征平面1202的roi的第一像素位置子集用于处理(例如,图12中所示的突出显示列中的像素位置)。在第一组处理周期的第一周期期间,第一组权重值(例如,权重00)中的每个权重值可以乘以用于第一特征平面1202(或第一输入图像)的第一像素位置子集中包括的每个像素值。在第一组周期中的第二周期期间,第一组权重值中的每个权重值可以乘以用于第二特征平面1202(或第二输入图像)的第一像素位置子集中包括的每个像素值。第一组周期中的每个周期可以对应于相应的输入图像。可以在第一组周期中的每个周期中使用相同的权重值,但是可以对每个周期使用不同的输入图像。在每个mac节点600内,可以对一组处理周期内的每个不同处理周期使用不同的累加器(例如,第一累加器604或第二累加器606(图6))。可以对对应于相同输入图像的不同组处理周期中的处理周期使用相同的累加器。在各个周期期间,可以将用于相应的输入图像的第一像素位置子集的每个像素值分配给vmu1210的相应行,并且可以将第一组权重值的每个权重值分配给vmu1210的相应列。这样,在第一组周期中的每个周期期间,vmu1210可以将第一组权重值中的每个权重值乘以用于相应的输入图像的第一像素位置子集中的每个像素值。在第一组周期之后执行第二组周期。第二组周期以与第一组周期类似的方式执行,除了:(a)通过从每个权重矩阵1204中选择第二权重值(例如,权重01)来形成第二组权重值;(b)选择roi中的第二像素位置子集,其对应于第二组权重值(例如,图13中的特征平面1202中的突出显示的列);以及(c)vmu1210关于第二组权重值和第二像素位置子集执行乘法。vmu1210通过将选择用于处理的像素位置的子集移位并从权重矩阵1204中选择对应的一组权重来继续执行成组周期,直到所有权重已经相乘并且已经累加了对应的部分乘积。
图15是权重馈送器单元(wfu)1500的详细图,其类似于wfu310(图3)。权重1504从l2存储器1502获取并存储在4×256位寄存器1506中。解复用器1510将权重路由到权重存储器1514或1516。地址生成器1508和多路复用器1512确定哪些权重指向输出缓冲器1518并且指向vmu。例如,当处理全连接层时,来自权重矩阵的权重数据的线性矢量(即行或列)在连续的时钟周期中被提供到vmu,直到已经提供了权重矩阵。在另一示例中,wfu1500可以为多个周期提供相同的权重数据,以应用于不同图像平面或不同的roi的线性矢量。wfu1500可以包括控制器(未示出),该控制器被配置为控制多路复用器1512和解复用器1510。在一些示例中,在第一状态中,控制器可以使多路复用器1512进入将权重值从权重存储器1514路由到wfu1500的输出(例如,到vmu1210的权重矢量1205输入)的状态,并且可以使解复用器1510进入将输入的权重值从存储器1502路由到权重存储器1516的状态。在第二状态期间,控制器可以使多路复用器1512进入将权重值从权重存储器1516路由到wfu1500的输出的状态,并且可以使解复用器1510进入将输入的权重值从存储器1502路由到权重存储器1514的状态。以此方式,当使用前一组权重值时,可以发生下一组权重值的加载。在一些示例中,权重值可以以交织的方式存储,例如,如图11所示。每组权重值可以对应于从不同cnn滤波器中的公共权重值位置获取的权重值。在其他示例中,在连续存储器存储槽可以存储用于不同cnn滤波器的权重值并将其存储在存储器存储槽内的意义上,可以以交织方式存储权重值,可以在对应于单个cnn滤波器的每个权重值之间交织用于其他cnn滤波器的权重值。
图16是数据馈送器单元(dfu)1600的详细图,其类似于dfu312(图3)。l2存储器1602将感兴趣区域(roi)数据1604提供到包括卷积层dfu1608的第一路径和包括全连接层dfu1606的第二路径。提供到全连接层的数据是roi的全矩阵数据(图像平面的线性矢量)。因为全连接图像和对应的滤波器的大小在全连接节点处是相同的,所以全连接层的处理是相对直接的矩阵乘法过程。roi的图像平面的线性矢量(即,行或列)由全连接层dfu1606在连续的时钟周期中提供,直到已经提供了图像平面。在另一方面,卷积层dfu1608重新布置roi数据,以便vmu对卷积节点进行有效的卷积处理。另外,卷积层dfu1608可以被配置为提供用于其他数学运算的其他数据布置。多路复用器1610和1612确定将哪些数据提供到输出缓冲器1614并因此提供到vmu。利用这种dfu配置,mme300(图3)可以提供卷积输出、全连接输出或其他数学运算。
图17是一个示例方法的流程图。方法1700开始于步骤1702,其提供图像数据(或特征平面值)。步骤1704将图像数据的一部分迭代地馈送到矢量乘法单元。步骤1706将权重数据迭代地馈送到矢量乘法单元。步骤1708将图像和权重数据相乘并累加以提供部分乘积。步骤1710在执行迭代之后读出乘积。
图18是另一示例方法的流程图。方法1800开始于步骤1802,其提供图像平面数据(或特征平面值)。步骤1804使用数据馈送器单元(如dfu1600(图16))来布置图像平面数据,以提供卷积数据,如来自卷积层dfu1608(图16)的卷积层。步骤1804将布置的图像平面数据馈送到矢量乘法单元(如vmu314(图3))。步骤1806使用权重馈送器单元(如wfu1500(图15))来布置权重数据以将卷积权重数据提供到矢量乘法单元,如vmu314(图3)。步骤1808将卷积数据和权重数据相乘并累加部分乘积。步骤1810确定完整卷积乘积的周期总数i是否已经完成。如果不是,则该方法循环回到步骤1804。如果是,则步骤1812读出完整乘积。
图19是另一示例方法的流程图。方法1900开始于步骤1902,其提供图像平面数据(或特征平面值)。步骤1904使用数据馈送器单元(如dfu1600(图16))提供图像平面数据的一部分,以提供全连接数据,如来自全连接层dfu1606(图16)的全连接层。步骤1904将全连接数据馈送到矢量乘法单元(如vmu314(图3))。步骤1906使用权重馈送器单元(如wfu1500(图15))馈送权重数据,以将全连接权重数据提供到矢量乘法单元,如vmu314(图3)。步骤1908将全连接图像数据和全连接权重数据相乘并累加部分乘积。步骤1910确定完整全连接乘积的周期总数i是否已经完成。如果不是,则该方法循环回到步骤1904。如果是,则步骤1912读出完整乘积。
在一个示例中,一种集成电路包括矢量乘法单元,该矢量乘法单元包括多个乘法/累加节点,其中矢量乘法单元可操作以提供来自乘法/累加节点的输出。该集成电路还包括第一数据馈送器和第二数据馈送器,该第一数据馈送器可操作以便以矢量格式向矢量乘法单元提供第一数据,该第二数据馈送器可操作以便以矢量格式向矢量乘法单元提供第二数据。
在另一示例中,第一数据馈送器可操作以向矢量乘法单元提供n个数据输入,其中第二数据馈送器可操作以提供m个数据输入,并且其中矢量乘法单元包括n×m个乘法/累加节点。
在另一示例中,n等于m.
在另一示例中,第一数据是具有n1*n2大小的面积的感兴趣区域的线性矢量,其中n=n1*n2。
在另一示例中,第一数据和第二数据是大于n×m的矩阵,并且矢量乘法单元将第一数据和第二数据处理为子矩阵。
在另一示例中,第一数据馈送器提供图像数据,并且第二数据馈送器提供权重数据。
在另一示例中,其中乘法/累加节点中的至少一个包括多个累加器。
在另一示例中,乘法/累加节点提供第一数据和第二数据的外积,并在时钟周期中相乘并累加外积。
在另一示例中,第一数据馈送器路由第一数据并且第二数据馈送器路由第二数据以用于二维卷积层的迭代累加。
在另一示例中,第一数据是k个特征平面,并且在第一数据馈送器的时钟周期中从k个特征平面读取n个值。
在另一示例中,第二数据是具有l个权重系数的多组权重数据,并且在k×l个乘法/累加周期之后提供来自乘法/累加节点的输出。
在另一示例中,第二数据是多组权重数据,并且来自多组权重数据的一个权重系数用于形成权重输入矢量。
在另一示例中,多组权重数据是二维矩阵。
在另一示例中,在第二数据馈送器的时钟周期期间读取多组权重数据中的一组。
在另一示例中,矢量乘法单元的输出是卷积层,并且在预定数量的乘法/累加周期之后被提供。
在另一示例中,第一数据馈送器路由第一数据,并且第二数据馈送器路由第二数据以用于全连接层的迭代累加。
在另一示例中,输入特征平面的线性矢量被连续地提供到第一数据馈送器。
在另一示例中,在连续的时钟周期期间,将权重数据的线性矢量连续地馈送到第二数据馈送器。
在另一示例中,将输出添加在累加器中达固定数量的周期。
在另一示例中,第一数据包括堆叠为附加行的多组roi(感兴趣区域)。
在另一示例中,第二数据被应用于多组第一数据。
在另一示例中,一种图像处理设备包括可操作以接收图像数据的端口。图像处理设备还包括具有多个乘法/累加节点的矢量乘法单元,其中矢量乘法单元可操作以提供来自乘法/累加节点的输出。该图像处理设备还包括第一数据馈送器和第二数据馈送器,该第一数据馈送器可操作以便以矢量格式向矢量乘法单元提供图像数据,该第二数据馈送器可操作以便以矢量格式向矢量乘法单元提供权重数据。
在另一示例中,第一数据馈送器可操作以向矢量乘法单元提供n个数据输入,其中第二数据馈送器可操作以提供m个数据输入,并且其中矢量乘法单元包括n×m个乘法/累加节点。
在另一示例中,n等于m.
在另一示例中,图像数据是具有大小为n1*n2的面积的感兴趣区域的线性矢量,其中n=n1*n2。
在另一示例中,图像数据和权重数据是大于n×m的矩阵,并且矢量乘法单元将图像数据和权重数据处理为子矩阵。
在另一示例中,输出包括指示物体在图像数据中的概率的数据。
在另一示例中,乘法/累加节点中的至少一个包括多个累加器。
在另一示例中,乘法/累加节点提供图像数据和权重数据的外积,并在时钟周期中相乘并累加外积。
在另一示例中,第一数据馈送器路由图像数据并且第二数据馈送器路由权重数据以用于二维卷积层的迭代累加。
在另一示例中,图像数据是k个特征平面,并且在第一数据馈送器的时钟周期中从k个特征平面读取n个值。
在另一示例中,权重数据是具有l个权重系数的多组权重数据,并且在k×l个乘法/累加周期之后提供来自乘法/累加节点的输出。
在另一示例中,权重数据是多组权重数据,并且来自多组权重数据的一个权重系数用于形成权重输入矢量。
在另一示例中,多组权重数据是二维矩阵。
在另一示例中,针对第二数据馈送器的时钟周期读取多组权重数据中的一组。
在另一示例中,矢量乘法单元的输出是卷积层,并且在固定数量的乘法/累加周期之后被提供。
在另一示例中,第一数据馈送器路由图像数据,并且第二数据馈送器路由权重数据以用于全连接层的迭代累加。
在另一示例中,第一数据馈送器连续地提供来自图像数据的输入特征平面的线性矢量。
在另一示例中,第二数据馈送器连续地提供权重数据的线性矢量。
在另一示例中,输出是多个乘法/累加节点中的至少一个中的累加达固定数量的周期。
在另一示例中,图像数据包括堆叠为附加行的多组roi(感兴趣区域)。
在另一示例中,权重数据被应用于多组图像数据。
在另一示例中,一种用于图像处理的方法包括接收第一数据;向矢量乘法单元提供第一数据的一部分;向矢量乘法单元提供第二数据;以及在矢量乘法单元的至少一个节点中相乘并累加部分乘积,使得在多次迭代之后在矢量乘法单元的至少一个节点中累加乘积。
在另一示例中,矢量乘法单元的至少一个节点包括多个累加器。
在另一示例中,相乘并累加在时钟周期中提供第一数据和第二数据的外积。
在另一示例中,路由第一数据和第二数据以用于二维卷积层的迭代累加。
在另一示例中,第一数据是k个特征平面,并且在矢量乘法单元的时钟周期中从k个特征平面读取n个值。
在另一示例中,第二数据是具有l个权重系数的多组权重数据,并且在矢量乘法单元的k×l个周期之后提供来自矢量乘法单元的输出。
在另一示例中,第二数据是多组权重数据,并且来自多组权重数据的一个权重系数用于形成权重输入矢量。
在另一示例中,多组权重数据是二维矩阵。
在另一示例中,针对矢量乘法单元的时钟周期读取多组权重数据中的一组。
在另一示例中,矢量乘法单元的输出是卷积层,并且在矢量乘法单元的固定数量的周期之后被提供。
在另一示例中,路由第一数据和第二数据以用于全连接层的迭代累加。
在另一示例中,第一数据是输入特征平面的线性矢量。
在另一示例中,第二数据是权重数据的线性矢量,该权重数据的线性矢量在连续的时钟周期中被连续地提供到矢量乘法单元。
在另一示例中,第一数据包括堆叠为附加行的多组roi(感兴趣区域)。
在另一示例中,第二数据被应用于多组第一数据。
在另一示例中,乘积是卷积值。
在另一示例中,在第一路径和第二路径上提供第一数据,该第一路径提供第一数据作为对应于图像平面的第一矢量,该第二路径提供第一数据作为不对应于图像平面的第二矢量。
在另一示例中,矢量乘法单元提供卷积输出和全连接输出。
在权利要求的范围内,在上文描述的示例中的修改是可能的,并且形成附加示例的其他布置是可能的。
- 还没有人留言评论。精彩留言会获得点赞!