文档的基于命名实体的类别标签添加的制作方法
背景技术:
电子文档可以包含诸如文本、电子表格、幻灯片、图解、示图、和图像之类的内容。
浏览器是显示诸如网页之类的文档的应用。一些常规浏览器允许用户收集文档集合,例如通过对它们手动添加书签;将它们手动添加至文档阅读列表;或者在用户访问它们时将它们自动添加至历史列表。通常而言,用户能够查看这样所收集的文档集合以向他或她提醒与它们交互的历史,并且从该集合中选择个体文档来阅读。
技术实现要素:
提供了该发明内容以用简化的形式引入对以下的具体实施方式中进一步描述的概念的选择。应当理解的是,该发明内容不旨在标识所要求保护主题的关键特征或必要特征,也不旨在用于限制所要求保护的主题的范围。
描述了一种用于代表用户将主题类别归于所收集的文档集合中的文档的工具。针对该文档集合中的每个文档,基于对该文档的语义分析,该工具识别该文档的一个或多个直接主题。该工具将针对该文档所识别的直接主题归于该文档。基于跨该集合的文档的语义分析,该工具识别一个或多个共同主题,所述共同主题中的每个针对该文档集合的合适子集。该工具将所识别的每个共同主题归于所述文档集合中其被识别的子集中的每个文档。
附图说明
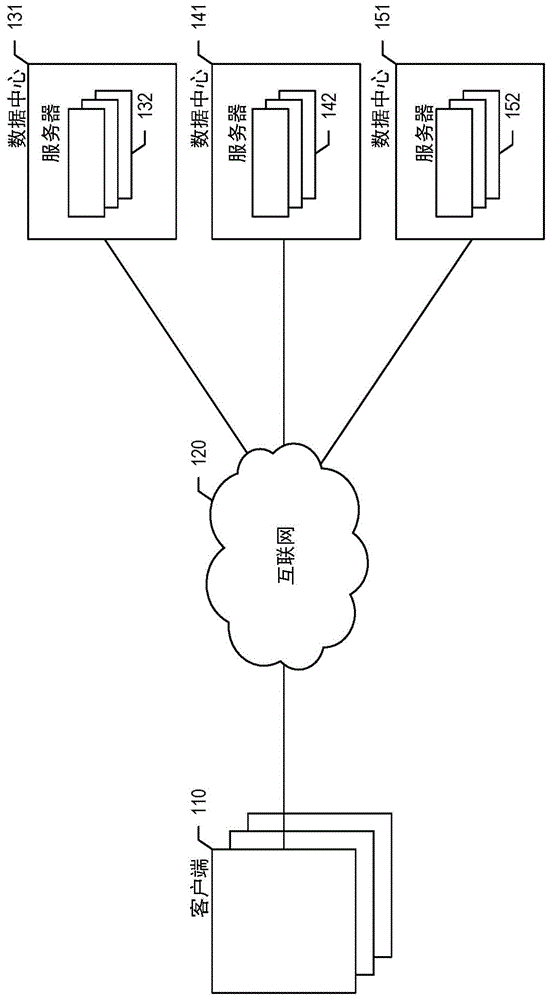
图1是示出了一些实施例中该工具在其中操作的环境的网络示图。
图2是这样的框图,其示出了通常被包含在该工具在其上操作的至少一些计算机系统和其他设备之中的组件中的一些。
图3是示出了一些示例中由该工具所执行以确定直接类别的过程的流程图。
图4是示出了一些示例中由该工具所获取或构建的命名实体“georgelucas”的样本实体关系图的图示图。
图5是示出了一些示例中由该工具所获取或构建的命名实体“harrisonford”的样本实体关系图的图示图。
图6-8是示出了示例中由该工具所获得并处理以便为六个另外的文档选择直接类别的另外的图的图示图。
图9是示出了一些示例中由该工具用来存储被归于文档的类别以供特定用户使用的文档类别表格的样本内容的数据结构图。
图10是数据结构图,其示出了一些示例中由该工具用来存储针对文档集合中的每个文档所获得的实体关系图间的所有根到叶路径的路径表格的样本内容。
图11是示出了一些示例中由该工具所执行以识别文档集合的共同类别的第一过程的流程图。
图12是示出了由该工具基于上文结合图4-8所讨论的示例所构建的样本主图的图示图。
图13是示出了被更新以反映对共同类别的选择的主图的样本内容的图示图。
图14是示出了被更新以反映对共同类别的选择的路径表格的样本内容的数据结构图。
图15是示出了被更新以反映对共同类别的添加的文档类别表格的样本内容的数据结构图。
图16是示出了一些示例中由该工具所执行以针对文档集合选择共同类别的第二过程的流程图。
图17是示出了一些示例中由该工具所执行以针对文档集合选择新的共同类别的第三过程的流程图。
图18是数据结构图,其示出一些示例中由该工具用来存储针对文档集合中的文档中出现的命名实体所获得的实体关系图间的实体之间的连接模式的父权重表格的样本内容。
图19是一些示例中由该工具所执行以使得归于文档的类别对用户可用的过程的流程图。
图20是示出了一些示例中由该工具所呈现的完整阅读列表用户界面的显示图。
图21是示出了已经被更新以包括共同类别之后的完整阅读列表用户界面的显示图。
图22是示出了被更新以显示单个类别中的文档的阅读列表用户界面的显示图。
图23是示出了一些示例中由该工具所呈现的类别层级用户界面的显示图。
具体实施方式
发明人已经确定了浏览器管理所收集的文档集合的方式中的重要缺点。特别地,针对所收集的文档集合的仅有的共同组织形式是将它们按照日期进行排序,例如按照每个被用户添加书签的日期,被添加至用户的阅读列表的日期,或者被用户访问的日期。
发明人已经认识到的是,随着所收集的文档集合增长为每个包括数十、数百、或者甚至数千个文档,用户就变得越来越难以在集合中找到他或她所搜寻的特定文档。例如,如果用户具有包含80个文档的阅读列表,其中的四个涉及奇幻电影,找到这些可能涉及整个列表过度的、重复的滚动,定期点击所列出的文档以评估它们是否涉及奇幻电影。甚至在阅读列表为可搜索的情况下,针对“奇幻电影”的查询也可能产生许多假阴性(指向该主题但是字面上不包含该短语并因此并不被包括在查询结果中的文档),或者甚至是假阳性(不指向该主题但是却包含该短语并因此被包括在查询结果中的文档)。
响应于该确定,发明人已经构思并归纳了实践一种用于使用命名实体分析利用相关类别来对文档添加标签的软件和/或硬件工具(“该工具”)。特别地,针对文档集合中的每个集合,该工具识别表征该文档主题的一个或多个类别标签。在各种示例中,该工具以各种方式显现文档的这些类别标签,这允许读者例如基于它们的类别标签选择文档来阅读。例如,在各个示例中,该工具:显示文档的列表,并且随每个所列出的文档显示其类别标签;当用户键入与该类别标签相匹配的查询时,显示具有该类别标签的文档的列表;当用户在与特定文档相关联的类别标签上点击时,显示具有该类别标签的文档的列表;显示已经向文档添加了标签的类别的层级,并且允许用户在其中一个上点击,随后显示具有该类别标签的文档的列表;等等。
在一些示例中,针对要添加标签的每个文档,该工具确定与该文档最可能的主题相对应的要利用其向该文档添加标签的“直接类别”。另外,该工具识别利用其向涉及集合内的文档群组的文档添加标签的“共同类别(collectivecategory)”。例如,该工具可以利用“theprincessbride(公主新娘)”直接类别来对涉及电影theprincessbride的第一文档群组添加标签,并且利用“starwars(星球大战)”直接类别对涉及电影starwars的第二文档群组添加标签。该工具还可以利用“电影(fantasy)(奇幻)”共同类别来向第一群组和第二群组中的所有文档添加标签,这些文档全都可能与所述共同类别相关。
在一些示例中,该工具使用命名实体将直接类别和共同类别归于文档。特别地,在一些示例中,为了使用命名实体将直接类别归于文档,该工具识别在文档中引用的命名实体,并且分析实体关系图,所述实体关系图中的每个指定那些引用的命名实体之一与涉及该被引用的命名实体的其他命名实体之间的关系。该工具在文档中识别出其引用的命名实体是引用真实世界对象的方式,例如,人、组织、或位置的名称;物质或生物种属的名称;其他“刚性标志符”;时间、数量、货币价值、或百分比的表达;等等。针对文档中的每个命名实体引用,该工具获取或构建实体关系图:指定被引用命名实体与涉及该引用的命名实体的其他更一般的命名实体之间的直接关系和间接关系的数据结构。在每个实体关系图中,引用命名实体被描述为该图的“根”。该工具比较文档所引用的命名实体的实体关系图,并且选择以距它们的根相对短的平均距离在这些实体关系图的全部或大多数中出现的实体作为该文档的直接类别。(随着实体距根的距离的增加,所述实体变得越来越一般且不具体,并且通常与该图的根的引用实体较不相关)。
在一些示例中,为了使用命名实体将共同类别归于集合中的文档,该工具收集应用于该集合中的文档的实体关系图,并且分析它们以识别在所收集图中频繁出现的另外的实体。在各个示例中,这涉及:(a)直接分析针对集合中的每个文档从实体关系图编译的“主图”;(b)分析这些实体关系图被分解得到的根到叶路径;或者(c)分析从实体关系图和/或主图编译的连通性统计数据。
通过以这些方式中的一些或全部来执行,该工具使得用户容易识别并阅读有关特定主题的文档。以这种方式,该工具使得用户免于一直以来为了识别和阅读有关特定主题的文档而施加于用户的负担,以允许他们阅读在许多情况下与他们的兴趣更加相关的文档,而且花费与他们使用常规技术相比更少的时间。
而且,通过以上述所描述的方式中的一些或全部来执行并且以高效方式存储、组织、和访问有关文档类别的信息,该工具有意义地降低了存储和利用该信息所需的硬件资源,例如包括:减少了存储有关文档类别的信息所需的存储空间的数量;并且减少了存储、获取、或处理有关文档类别的信息所需的处理周期的数量。这允许利用该工具的程序在具有较少存储和处理能力的计算机系统上执行,占用较少的物理空间,消耗较少的能量,产生较少的热量,并且获取和操作的成本更低。而且,这样的计算机系统能够以更少的延时对涉及有关文档类别的信息的用户请求进行响应,以产生更好的用户体验并且允许用户在较少时间内完成特定数量的工作。
图1是示出了一些实施例中该工具在其中操作的环境的网络示图。该网络示图示出了其中每个通常由不同用户使用的客户端110。客户端中的每个执行使得其用户能够与文档进行交互的软件,例如使得其用户能够与网页文档进行交互的浏览器。客户端由互联网120和/或一个或多个其他网络连接至诸如数据中心131、141、和151之类的数据中心,所述数据中心在一些示例中在地理上分布以在数据完整性和连续可用性两方面提供灾害和停机生存能力。在地理上分布数据中心还有助于使得与各种地理位置的客户端的通信延时最小化。每个数据中心包含服务器,例如服务器132、142、和152。每个服务器可以执行以下中的一个或多个:针对文档供应内容和/或著录信息;以及存储与命名实体之间的关系相关的信息。
尽管上文在概括的环境方面描述了该工具的各个示例,但是本领域技术人员将会意识到的是,该工具可以在各种其他环境中被实现,包括单个的整体计算机系统,以及以各种方式连接的计算机系统或类似设备的各种其他组合。在各种示例中,多种计算系统或其他不同设备被用作客户端,包括台式计算机系统、膝上计算机系统、汽车计算机系统、平板计算机系统、智能电话、个人数字助理、电视、相机等。
图2是这样的框图,其示出了通常被包含在该工具在其上操作的至少一些计算机系统和其他设备之中的组件中的一些。在各种示例中,这些计算机系统和其他设备200可以包括服务器计算机系统、台式计算机系统、膝上计算机系统、上网本、移动电话、个人数字助理、电视机、相机、汽车计算机、电子媒体播放机等。在各种示例中,该计算机系统和设备包括以下每一个中的零个或更多个:用于执行计算机程序的中央处理器(cpu)201;用于在程序和数据被使用的同时存储它们的计算机存储器202,所述程序和数据包括该工具和相关联数据、包括内核的操作系统、以及设备驱动器;持久性存储设备203,诸如用于持久存储程序和数据的硬盘或闪存;计算机可读介质驱动器204,诸如软盘、cd-rom和dvd驱动器,用于读取存储在计算机可读介质上的程序和数据;以及用于将计算机系统连接至其他计算机系统以诸如经由互联网或另一种网络及其联网硬件发送和/或接收数据的网络连接205,所述联网硬件例如交换机、路由器、中继器、电力线缆和光纤、光发射器和接收器、无线电发射机和接收机,等等。尽管如上述配置的计算机系统通常被用来支持该工具的操作,但是本领域技术人员将会意识到,该工具可以使用各种类型和配置并且具有各种组件的设备来实现。
图3是示出了一些示例中由该工具所执行以确定直接类别的过程的流程图。在301-307处,该工具循环经过待分类的每个文档。在各个示例中,这些文档包括文档集合,所述文档集合例如与添加至书签列表、阅读列表、或历史列表的文档相对应。在302处,该工具识别在当前文档中引用的命名实体,例如通过将当前文档的内容与命名实体的列表以及每个命名实体的各种可替代的表达形式进行比较。在303处,该工具针对在302处所识别的每个命名实体获得实体关系图。
在一些示例中,这涉及针对所识别的实体获取现有的实体关系图。在一些示例中,这涉及针对所识别的实体构建实体关系图。例如,在一些示例中,该工具使用诸如来自微软公司的microsoftsatori之类的服务来返回所查询实体的子实体,如下所述:(1)该工具将所识别实体建立为实体关系图的根;(2)该工具针对所识别的实体的子实体进行查询,并且将它们作为根的孩子添加至实体关系图;以及(3)针对被添加至实体关系图的孩子中的每个,该工具以递归方式针对它们的孩子进行查询并且将其添加至实体关系图,直到根没有另外的后代要被添加至该实体关系图为止。
图4-5示出了该工具针对命名实体“georgelucas”和“harrisonford”所获得的样本实体关系图,上述两个命名实体都被示例文档集合中具有文档标识符11111111的第一文档所引用。
图4是示出了一些示例中由该工具所获取或构建的命名实体“georgelucas”的样本实体关系图的图示图。在实体关系图400中,根节点401指示“georgelucas”是导演实体。来自根节点401的子节点411指示“starwars”是电影实体。节点411的子节点421指示“电影(奇幻)”是媒体实体,而来自节点421的子节点431指示“奇幻”是流派(genre)实体。由于节点431没有孩子,所以它是叶节点。
图5示出了一些示例中由该工具所获取或构建的命名实体“harrisonford”的样本实体关系图的图示图。在实体关系图500中,根节点501指示“harrisonford”是演员实体。根节点501具有两个子节点:指示“starwars”是电影的实体511,以及指示“thefugitive(亡命天涯)”是电影的实体512。以镜像在图4中所示的“starwars”节点411的方式,在图5中所示的starwars节点511具有“电影(奇幻)”子节点521,其进而具有“奇幻”子节点531。“thefugitive”节点512具有“电影(drama)(剧情)”子节点522,其进而具有作为叶节点的“剧情”子节点532。
返回图3,在304处,该工具选择处于在303处所获得的最大数量的图中距每个图的根最短平均距离的实体作为当前文档的直接类别。考虑具有文档标识符11111111的文档,该工具针对其获得了在图4和图5中所示的两个实体关系图,以下实体对于两个图是共有的:“starwars”、“电影(奇幻)”和“奇幻”。在这三个实体之中。距每个图的根具有最短平均距离的实体是“starwars”,与具有平均距离2的“电影(奇幻)”和具有平均距离3的“奇幻”相比,其具有距根的平均距离1。由此,该工具选择“starwars”作为具有文档标识符11111111的文档的直接类别。
在305处,如果在304处选择的实体尚未在活跃类别的层级之中,则该工具将该实体添加至该层级。在该示例中,具有文档标识符11111111的文档的直接类别在活跃类别的层级为空时被添加。由此,在将“starwars”添加至该层级之后,该层级处于以下在表1中所示的状态。
starwars
表1
在306处,该工具存储在303处获得的每个图的每个根到叶路径,其中针对在路径上处于活跃类别(包括在304所选择的文档的直接类别)的层级中的实体设置有标志。以下在表2中示出了在306处针对具有文档标识符11111111的文档所存储的三个路径。
“georgelucas”→“starwars”→“电影(奇幻)”→“奇幻”
“harrisonford”→“starwars”→“电影(奇幻)”→“奇幻”
“harrisonford”→“thefugitive”→“电影(剧情)”→“剧情”
表2
在第一和第二路径中,该工具将“starwars”实体标记为直接类别。在一些示例中,该工具将所述路径存储在路径表中,例如在图10中所述并且在下文中讨论的路径表。在307处,如果还有另外的文档待分类,则该工具在301处继续以对集合中的下一个文档进行分类,如果没有,则该过程结束。
本领域技术人员将会意识到,图3以及下文讨论的每个流程图中所示的动作可以以各种方法有所改变。例如,动作的顺序可以重新排列;一些动作可以并行执行;所示出的动作可以被省略,或者可以包括其他动作;所示出的动作可以被划分为子动作,或者多个所示出的动作可以被组合为单个动作,等等。
图6-8是示出了示例中由该工具所获得并处理以便为六个另外的文档选择直接类别的另外的图的图示图。图6包含针对命名实体“chewbacca”的图600,图7包含针对命名实体“princessbride”的图700,并且包含针对命名实体“tommyleejones”的图800。在该示例中,具有文档标识符22222222的文档引用了命名实体“harrisonford”和“chewbacca”,并且因此图500和600针对该文档被获得,并且被用来选择“starwars”作为其直接类别。具有文档标识符33333333和44444444的两个文档每个仅引用了命名实体“princessbride”,由此该工具针对这两个文档中的每个获得图700,并且因此将其用作基础以选择实体“princessbride”作为这两个文档的直接类别。最终,具有文档标识符55555555、66666666、和77777777的每个文档每个仅引用命名实体“tommyleejones”,由此该工具针对这三个文档中的每一个获得图800,并且将其用作基础以选择实体“tommyleejones”作为这三个文档中的每一个的直接类别。在一些示例中,该工具将这些所选择的直接类别记录在文档的文档类别表格中。
图9是示出了一些示例中由该工具用来存储被归于文档的类别以供特定用户使用的文档类别表格的样本内容的数据结构图。文档类别表格900由多行组成,例如每个对应于不同文档的行911-917。每一行被划分为以下的列:文档标识符列901,其包含标识该行所对应于的文档的标识符;类别:“starwars”列902,其指示“starwars”类别是否已经被归于该文档;类别:princessbride列903,其指示“princessbride”类别是否已经被归于该文档;类别“tommyleejones”列904,其指示“tommyleejones”类别是否已经被归于该文档;以及目前未使用的类别列905和906。例如,行912指示仅“starwars”类别已经被归于具有文档标识符22222222的文档。
尽管图9和下文所讨论的每个表格示图示了其内容和组织被设计为使得它们能够更加被人类阅读者所理解的表格,但是本领域技术人员将会意识到,该工具用来存储此信息的实际数据结构可能与所示出的表格有所不同,例如,其中它们可能以不同方式被组织;可能包含比所示出更多或更少的信息;可能被压缩和/或加密;可能包含比所示出明显更大数量的行,等等。
基于该示例中针对文档的直接类别的选择,以下的表3中示出了当前活跃类别的层级。
princessbride
starwars
表3
图10是数据结构图,其示出了一些示例中由该工具用来存储针对文档集合中的每个文档所获得的实体关系图间的所有根到叶路径的路径表格的样本内容。路径表格1000由多个行组成,例如每个对应于针对特定文档所记录的不同路径的行1011-1024。每一行被划分为以下的列:文档标识符列1001,其包含标识该行所对应于的文档的标识符;路径编号列1002,其包含标识该行所对应的特定路径的路径编号;节点1列1003,其标识在该路径开始处的实体,这是对应的实体关系图的根节点;节点1标志列1004,其包含关于节点1列中所标识的实体是否已经被选择作为该行所对应的文档的类别的指示;节点2列1005、节点3列1007、和节点4列1009,它们中的每个包含对该行所对应的路径中的下一个位置中的实体的指示;以及节点2标志列1006、节点3标志列1008、和节点4标志列1010,它们中的每个指示相对应的节点列中的实体是否已经被选择作为该行所对应的文档的类别。例如,该路径表格的行1013指示具有文档id11111111的文档具有以上在表2的第二行中所示的路径,并且还指示该路径中的“电影(奇幻)”实体已经被选择作为该文档的类别。在一些示例中,该路径表格包含为了表示在该工具所处理的实体关系图间遇到的最长路径所必需的许多节点和节点标志列。
图11是示出一些示例中该工具所执行以识别文档集合的共同类别的第一过程的流程图。在1101处,跨用户待分类的文档集合,该工具将在每个文档中出现的命名实体的实体关系图组合为针对该用户的主图。
图12是示出了由该工具基于上文结合图4-8所讨论的示例所构建的样本主图的图示图。主图1200是该工具针对具有文档标识符11111111、22222222、33333333、44444444、55555555、66666666和77777777的文档所获得的实体关系图的组合。该主图中的每个实体具有权重,该权重指示该实体在被组合的实体关系图中的相同位置出现的次数。例如,实体1223的权重指示该实体在这七个样本文档的实体关系图中被包括了四次。在该主图中,已经被选择为一个或多个文档的直接类别的实体由双重椭圆所标识:实体1201、1213、和1214。在该主图中,实体1201、1202、1203、1204和1214是根,而实体1231、1232、1233是叶。
返回图11,在1102处,该工具选择不处于活跃类别层级中并且在主图中出现次数最多的、距叶节点最远的实体作为共同类别。在图12所示的样本主图中,具有最高权重的实体是每个具有权重5且在第一路径上的实体1211、1221和1231,每个具有权重4且在第二路径上的实体1223和1233。在实体1211、1221和1231中,实体1211距叶节点1231最远,并且因此被选择作为共同类别。类似地,在实体1223和1233中,实体1223距叶节点1233最远并且因此也被选择作为共同类别。
图13是示出了被更新以反映对共同类别的选择的主图的样本内容的图示图。可以看出,在经更新的主图1300中,已经向实体1311和1323添加了三重椭圆,这表明这两个实体已经被选择作为共同类别。
返回图11,在1103处,该工具将在1102处被选择为共同类别的实体添加至活跃类别的层级。以下的表4示出了将“电影(奇幻)”和“thefugitive”共同类别添加至活跃类别的层级。
表4
在1104处,在针对用户所存储的包含这些实体的每个路径中,该工具针对在1102处被选择为共同类别的实体设置标志。
图14是示出了被更新以反映对共同类别的选择的路径表格的样本内容的数据结构图。通过将在图14中所示的路径表格1400与在图10中所示的路径表格1000进行比较,可以看出该工具已经添加了对共同类别的以下指示:在行1411和1413中,关于“电影(奇幻)”实体是具有文档标识符11111111的文档的共同类别的指示;在行1414和1416中,关于“电影(奇幻)”实体是具有文档标识符22222222的文档的共同类别的指示;在行1417和1418中,关于“电影(奇幻)”实体是具有文档标识符33333333和44444444的文档的共同类别的指示;以及在行1419、1421和1423中,关于“thefugitive”实体是具有文档标识符55555555、66666666、和77777777的文档的共同类别的指示。
返回图11,在1105处,该工具将对应的新的共同类别添加至具有包含在1102处所选择的实体的至少1个路径的每个文档。在1105之后,该过程结束。
图15是示出了被更新以反映对共同类别的添加的文档类别表格的样本内容的数据结构图。通过将在图15中所示的文档类别表格1500与在图9中所示的文档类别表格900进行比较,可以看出新的共同类别“电影(奇幻)”已经作为类别被添加至具有文档id11111111、22222222、33333333和44444444的文档;并且类别“thefugitive”已经作为类别被添加至具有文档id11111111、22222222、55555555、66666666和77777777的文档。
图16是示出了一些示例中由该工具所执行以针对文档集合选择共同类别的第二过程的流程图。在1601处,该工具从诸如路径表格之类的路径库集中随机地选择一对路径。在1602处,如果同一实体在1601处随机选择的两个路径中都是叶,则该工具在1603处继续,否则该工具在1601处继续以随机选择新的路径对。在1603处,该工具选择不处于活跃类别层级中的、该配对中的两个路径所共有的距这些路径的叶端最远的实体。在1604处,如果在整个路径库集中,在1603处所选择的实体出现超过阈值次数,则该工具在1605处继续,否则该工具在1601处继续以随机地选择新的路径对。在1605处,该工具将在1063处选择的实体添加至活跃类别的层级。在1606处,例如在路径表格中,该工具在针对用户所存储的包含所选择的实体的每个路径中针对该所选择的实体设置标志。在1607处,例如在文档类别表格中,该工具将新的共同类别添加至具有包含所选择的实体的至少一个路径的每个文档。在1607之后,该过程结束。
关于该示例,该工具首先随机选择在图10中所示的路径表格的行1015和1016中所示的路径对。然而,在1602处,该工具确定这对路径在其叶端具有不同的实体(“剧情”和“奇幻”),因此其返回1601。
该工具接着随机选择在图10中所示的路径表格的行1012和1021中所示的路径对。这对路径在两个路径的叶端具有相同实体(“剧情”)。这对路径公共的是实体“thefugitive”、“电影(奇幻)”、和“剧情”。在这些中,距叶端最远的是“thefugitive”。该工具评估整个路径表格,并且发现“thefugitive”实体在行1012、1015、1019、1021和1023中出现5次。由于这5次出现超过了3次出现的样本阈值,所以该工具将“thefugitive”实体添加为共同类别。当在图16中所示的过程随后被重复时,该工具进行类似评估从而基于随机选择的路径对(在图10中所示的路径表格的行1016和1017中所示的)将“电影(奇幻)”实体添加为共同类别。
图17是示出了一些示例中由该工具所执行以针对文档集合选择新的共同类别的第三过程的流程图。在1701-1706处,该工具循环通过实体关系图中的每个实体,该实体关系图是针对尚未处于活跃类别层级中并且不是根节点的文档集合中的文档所引用的命名实体所获得的。在一些示例中,该工具保存父权重表格,其中,列出所获得的实体关系图中出现的所有实体以及每个实体具有其独特的父实体中的每一个的次数。
图18是数据结构图,其示出一些示例中由该工具用来存储针对文档集合中的文档中出现的命名实体所获得的实体关系图间的实体之间的连接模式的父权重表格的样本内容。表格1800由多行组成,例如每个对应于不同实体与其独特父实体之一的组合的行1811-1823。所述行中的每一行被划分为以下的列:实体列1801,其标识该行所对应的实体;父列1802,其标识该行所对应的该实体的独特父;以及父列1803,其指示该行所对应的父作为该行所对应的实体的父出现的次数。例如,行1818-1820指示在所述文档的图中,“starwars”实体具有“georgelucas”父一次,“chewbacca”父一次,以及“harrisonford”父两次。这对应于针对在图12中所示的主图中的实体1204、1203和1202所示的权重1、1和2。
返回图17,在1702处,如果实体的“父”的权重之和与实体的父的权重中的最大值的比率超过阈值,则该工具在1703处继续,否则该工具在1706处继续。在1703处,该工具将当前实体添加至活跃类别的层级。在1704处,该工具在针对用户所存储的包含该实体的每个路径中针对当前实体设置标志。在1705处,该工具将新的共同类别添加至具有包含当前实体的至少一个路径的每个文档中。在1706处,如果活跃类别的层级中没有另外的实体待处理,则该工具在1701处继续以处理下一个这样的实体,否则该过程结束。
关于该示例:图12所示的实体1201、1213和1214已经处于活跃类别的层级中,并且因此不予考虑;实体1202、1203和1204没有父(即,是根),并且也不予考虑,(并且在该父权重表格中不存在)。在剩余实体中,该工具在1702处所计算的比率如下:对于“奇幻”为1;对于“剧情”为1;对于“惊悚”为1;对于“电影(奇幻)”为2;对于“电影(剧情)”为1;对于“电影(惊悚)”为1;对于“thefugitive”为1.7;并对于“nocountryforoldmen(老无所依)”为1。使用样本阈值1.5,该工具选择“电影(奇幻)”(2)和“thefugitive”(1.7)。
图19是一些示例中由该工具所执行以使得归于文档的类别对用户可用的过程的流程图。在1901处,该工具显示具有其分类标签的分类文档中的至少一些。在1902处,该工具接收选择类别的用户输入;在1903处,该工具显示具有在1902处所选择的类别的文档。在1903之后,该工具在1902处继续以接收选择另一个类别的用户输入。
图20-23示出了一些示例中该工具所呈现的视觉用户界面。图20是示出了一些示例中由该工具所呈现的完整阅读列表用户界面的显示图。该用户界面包括浏览器窗口2000,其包含用户能够在其中输入网页的url的url字段2001;可以在其中显示网页的客户端区域2002;以及添加至阅读列表控件2003,用户能够在网页或其他文档被显示的同时将其激活以便将该网页或文档添加至阅读列表。该浏览器还显示了阅读列表2003,其包含条目2010、2020、2030、2040、2050、2060和2070,这些条目中的每个对应于已经被添加至阅读列表的不同文档。每个条目包含标识文档的信息以及一个或多个类别标签。例如,条目2040是针对具有文档标识符44444444的文档2041的,并且针对“princessbride”类别包括类别标签2042。如在
图20中所示,条目仅反映了每个文档的直接类别,而没有被填入任何文档的共同类别。
图21是示出了已经被更新以包括共同类别之后的完整阅读列表用户界面的显示图。例如,可以看出“电影(奇幻)”类别已经被添加至具有文档标识符44444444的文档的条目2140。此时,用户可以继续不同的交互以仅显示具有特定类别标签的文档。例如,用户可以在“电影(奇幻)”类别标签2143上点击以便只显示具有该类别的文档。可替换地,用户可以向搜索字段2104中键入字符串“电影(奇幻)”——或者仅“奇幻”——以便显示相同文档。
图22是示出了被更新以显示单个类别中的文档的阅读列表用户界面的显示图。可以看出阅读列表2203仅包含实体2210、2220、2230和2240,省去了在图21中所示的实体2150、2160和2170。为了返回至整体安装阅读列表,用户可以激活控件2205以取消“电影(奇幻)”类别。
图23是示出了一些示例中由该工具所呈现的类别层级用户界面的显示图。在类别层级窗口2303中,该工具显示了活跃类别的层级2308。在该层级中,“电影(奇幻)”类别包括“starwars”类别2382和“princessbride”类别2383。而且,“thefugitive”类别2384包含“tommyleejones”类别2385。在每个类别中,该类别内的文档的计数被显示在括号中。用户可以在五个类别标签中的任一个上点击以便生成如在图22中所示的经过滤的阅读列表。
尽管在图20-23中所示的样本用户界面涉及阅读列表,但是本领域技术人员将会意识到,这些可以以类似方式关于以任何多种方式所收集的网页或其他文档的集合来实现。
在一些示例中,该工具提供了一种用于代表用户将主题类别归于所收集的文档集合中的文档的计算系统中的方法,所述方法包括:针对所述文档集合中的每个文档,识别所述文档所引用的一个或多个命名实体;针对所识别的命名实体中的每个命名实体,获得实体关系图,所述实体关系图表示所识别的命名实体与直接或间接地关于所识别的命名实体的命名实体之间的关系;对在针对所述文档所引用的命名实体获得的所述实体关系图中的至少一些实体关系图中出现的实体进行选择;将所选择的实体作为直接类别归于所述文档;将所获得的实体关系图添加至实体关系图的集合;选择在所述实体关系图的所述集合中的所述实体关系图中的至少一些实体关系图中出现的实体;以及将所选择的实体归于其实体关系图包含所选择的实体的文档作为共同类别。
在一些示例中,该工具提供了一种用于代表用户将主题类别归于所收集的文档集合中的文档的计算系统,包括:处理器;以及具有内容的存储器,所述内容的执行由所述处理器通过以下操作进行:针对所述文档集合中的每个文档,识别所述文档所引用的一个或多个命名实体;针对所识别的命名实体中的每个命名实体,获得实体关系图,所述实体关系图表示所识别的命名实体与直接或间接地关于所识别的命名实体的命名实体之间的关系;对在针对所述文档所引用的命名实体获得的所述实体关系图中的至少一些实体关系图中出现的实体进行选择;将所选择的实体作为直接类别归于所述文档;将所获得的实体关系图添加至实体关系图的集合;选择在所述实体关系图的所述集合中的所述实体关系图中的至少一些实体关系图中出现的实体;以及将所选择的实体归于其实体关系图包含所选择的实体的文档作为共同类别。
在一些示例中,该工具提供了一种被配置为使得计算系统执行一种用于代表用户将主题类别归于所收集的文档集合中的文档的方法的具有内容的存储器,所述方法包括:针对所述文档集合中的每个文档,识别所述文档所引用的一个或多个命名实体;针对所识别的命名实体中的每个命名实体,获得实体关系图,所述实体关系图表示所识别的命名实体与直接或间接地关于所识别的命名实体的命名实体之间的关系;对在针对所述文档所引用的命名实体获得的所述实体关系图中的至少一些实体关系图中出现的实体进行选择;将所选择的实体作为直接类别归于所述文档;将所获得的实体关系图添加至实体关系图的集合;选择在所述实体关系图的所述集合中的所述实体关系图中的至少一些实体关系图中出现的实体;以及将所选择的实体归于其实体关系图包含所选择的实体的文档作为共同类别。
在一些示例中,所述工具提供了一种用于代表用户将主题类别归于所收集的文档集合中的文档的计算系统中的方法,所述方法包括:针对所述文档集合中的每个文档,基于对所述文档的语义分析,识别所述文档的一个或多个直接主题;将针对所述文档所识别的所述直接主题归于所述文档;基于跨所述集合中的多个文档的语义分析,识别每个针对所述文档集合的合适子集的一个或多个共同主题;以及将每个所识别的共同主题归于所述文档集合中所述共同主题针对其被识别的所述子集中的每个文档。
在一些示例中,所述工具提供了一种用于代表用户将主题类别归于所收集的文档集合中的文档的计算系统,包括:处理器;以及具有内容的存储器,所述内容的执行由所述处理器通过以下操作进行:针对所述文档集合中的每个文档,基于对所述文档的语义分析,识别所述文档的一个或多个直接主题;将针对所述文档所识别的所述直接主题归于所述文档;基于跨所述集合中的多个文档的语义分析,识别每个针对所述文档集合的合适子集的一个或多个共同主题;以及将每个所识别的共同主题归于所述文档集合中所述共同主题针对其被识别的所述子集中的每个文档。
在一些示例中,该工具提供了一种被配置为使得计算系统执行一种用于代表用户将主题类别归于所收集的文档集合中的文档的方法的具有内容的存储器,所述方法包括:针对所述文档集合中的每个文档,基于对所述文档的语义分析,识别所述文档的一个或多个直接主题;将针对所述文档所识别的所述直接主题归于所述文档;基于跨所述集合中的多个文档的语义分析,识别每个针对所述文档集合的合适子集的一个或多个共同主题;以及将每个所识别的共同主题归于所述文档集合中所述共同主题针对其被识别的所述子集中的每个文档。
本领域技术人员将会意识到,以上所描述的工具可以以各种方式进行直接调整或扩展。尽管以上描述对特定示例进行了参考,但是本发明的范围仅由随后的权利要求以及其中所引用的元素来限定。
- 还没有人留言评论。精彩留言会获得点赞!