输入/输出(I/O)存储器管理单元的基于硬件的虚拟化的制作方法
本公开的多个方面总体上关于微处理器内的虚拟化,并且更具体地关于输入/输出(i/o)存储器管理单元的基于硬件的虚拟化。
背景技术:
虚拟化允许操作系统(os)的多个实例在单个系统平台上运行。虚拟化通过使用诸如虚拟机监视器(vmm)或管理程序之类的软件来实现,以向每个os呈现“宾客机(guest)”或虚拟机(vm)。vm是软件的部分,该部分当在适当的硬件上被执行时,创建允许对实际的物理计算机系统的抽象的环境,实际的物理计算机系统也称为“主机”或“主机机器”。在主机机器上,虚拟机监视器为vm提供各种功能,诸如,为主机机器的各种资源分配和执行虚拟机作出的请求。
附图说明
图1是根据各种实现方式的用于输入/输出(i/o)存储器管理单元(iommu)的基于硬件的虚拟化的计算系统的框图。
图2是根据各种实现方式的系统的框图,该系统包括虚拟机控制结构(vmcs)以及总线设备功能(bdf)标识符转换表的集合,这些bdf标识符转换表用于将宾客机bdf标识符转换为主机bdf标识符。
图3是图示根据一个实现方式的系统的框图,该系统包括存储器,该存储器用于使用专用工作队列对i/o设备的进程地址空间标识符的虚拟化。
图4是图示根据一个实现方式的另一系统的框图,该系统包括存储器,该存储器用于使用共享工作队列对i/o设备的进程地址空间标识符的虚拟化。
图5a是图示根据各种实现方式的管理描述符命令数据结构的框图。
图5b是图示根据一个实现方式的管理完成记录的框图,该管理完成记录包含指示管理描述符命令的完成的状态。
图6是根据一些实现方式的利用来自硬件iommu的虚拟化支持来处置来自虚拟机的无效的方法的流程图。
图7是图示根据实现方式的用于处置页请求的iommu的基于硬件的虚拟化的计算系统的框图。
图8a是图示根据一个实现方式的页请求描述符的框图。
图8b是图示根据一个实现方式的页组响应描述符的框图。
图9是根据一些实现方式的利用来自硬件iommu的虚拟化支持来处置来自i/o设备的页请求的方法的流程图。
图10a是图示根据实现方式的用于可实现iommu的基于硬件的虚拟化的处理器或集成电路的微架构的框图。
图10b是图示根据一个实现方式的可实现iommu的基于硬件的虚拟化的有序流水线以及寄存器重命名级、乱序发布/执行流水线的框图。
图11图示根据实现方式的用于可实现iommu的基于硬件的虚拟化的处理器或集成电路的微架构的框图。
图12是根据一个实现方式的可实现iommu的基于硬件的虚拟化的计算机系统的框图。
图13是根据另一实现方式的可实现iommu的基于硬件的虚拟化的计算机系统的框图。
图14是根据一个实现方式的可实现iommu的基于硬件的虚拟化的片上系统(soc)的框图。
图15图示可实现iommu的基于硬件的虚拟化的计算系统的框图的另一实现方式。
图16是根据一个实现方式的可实现iommu的基于硬件的虚拟化的用于执行指令的处理组件的框图。
图17a是根据一个实现方式的用于由处理器执行以执行指令以将工作提交到共享工作队列(swq)的示例方法的流程图。
图17b是根据一个实现方式的用于由处理器执行以执行指令以利用来自硬件iommu的支持来处置来自vm的无效的示例方法的流程图。
图18是图示用于本文中公开的指令的示例格式的框图。
图19图示可实现iommu的基于硬件的虚拟化的计算系统的框图的另一实现方式。
具体实施方式
处理器内的i/o存储器管理单元(iommu)提供隔离和保护以防止i/o设备执行对系统存储器的直接存储器访问(dma)。在不存在iommu的情况下,错误i/o设备或流氓i/o设备会破坏系统存储器,因为i/o设备可以其他方式具有对系统存储器的无限制的访问。随着诸如外围组件互连快捷(pci-
i/o的近期发展(诸如,共享虚拟存储器(svm))允许快速加速器设备(例如,图形和现场可编程门阵列(fpga))直接由用户空间进程控制。在pci-
系统平台可具有系统中的一个或多个iommu代理。当将iommu后面的设备暴露于宾客机时,诸如虚拟机监视器(vmm)之类的虚拟化软件可将用于虚拟化iommu的设施提供给宾客机,例如,创建宾客机iommu(也称为虚拟iommu)。宾客机os随后可通过宾客机iommu起作用,发现硬件iommu后面的直接指派的设备,该直接指派的设备从宾客机os内施加对存储器的dma访问。从用户进程至终端i/o设备的交互可在宾客机os正在改变用于那个进程的虚拟存储器映射时要求宾客机os执行无效。类似地,当设备尝试执行dma但页不存在时,这生成针对该设备的页错误。支持页请求服务(prs)的i/o设备可将解决页错误的页请求发送到硬件iommu(例如,物理iommu)。此类页请求服务从物理iommu(piommu)被转发到在宾客机中运行的虚拟iommu(viommu)。
硬件iommu可在架构内提供促进vmm在这些iommu交互期间软中断并允许硬件iommu驱动器代表viommu代理那些操作的电路和/或逻辑。“软中断(trap)”意味着宾客机os的vm退出到vmm,该vmm执行piommu驱动器以仿真硬件iommu。以此方式,vm退出允许vmm代表宾客机os中的viommu执行代理操作。一旦操作已完成,vmm就可引起重新进入vm。这些vm退出和进入(例如,软中断或拦截)在系统操作中引入等待时间,因此仅针对vm的宾客机os内所要求的iommu虚拟化就会引起显著开销。例如,当宾客机os可能频繁地执行i/o转换后备(tlb)或设备tlb无效,频繁地直接将诸如页请求之类的事件传递到宾客机os,并且频繁地直接将页响应传递到硬件iommu时,系统会由于vm内的iommu的虚拟化而引发大量性能开销。
相应地,所公开的实现方式通过将这些功能转移到硬件iommu降低了针对上述类型的基于viommu的功能的该性能开销,并因此避免了导致最大开销打击的vm退出和vm进入。当若干vm正在单个系统中被主管时,这些实现方式还可增强可缩放性。
更具体地,在一个实现方式中,处理器可包括硬件输入/输出(i/o)存储器管理单元(iommu)(其也可称为piommu)、以及耦合至该硬件iommu的核。核可执行虚拟机(vm)内的宾客机iommu驱动器。当vm遇到使宾客机地址范围无效的需求时,宾客机iommu驱动器可用宾客机总线设备功能(bdf)标识符、宾客机地址空间标识符(asid)、以及要无效的宾客机地址范围来填充描述符有效载荷。描述符有效载荷可与管理命令管理员模式(admcmds)指令相关联,宾客机iommu驱动器可调用该admcmds指令以供执行。admcmds指令的“管理员模式”方面可参考来自宾客机内核级别(例如,其在环-0特权级别内操作)的执行。
在各种实现方式中,核可执行admcmds指令以拦截来自vm的描述符有效载荷。在存储在存储器中的用于vm的虚拟机控制结构(vmcs)内,核可访问指向第一组转换表的第一指针。在一个实现方式中,第一指针是bdf表指针,并且第一组转换表是bdf转换表的集合。核可遍历第一组转换表,以将宾客机bdf标识符转换为主机bdf标识符。在vmcs内,核可进一步访问指向第二组转换表的第二指针。在一个实现方式中,第二指针是地址空间标识符(asid)表指针,并且第二组转换表是asid转换表。核可遍历第二组转换表以将宾客机asid转换为主机asid,并且将主机bdf标识符和主机asid存储在描述符有效载荷中。随后,核可将包含有效载荷的管理命令提交到硬件iommu,以执行宾客机地址范围的无效。随后,硬件iommu可参照宾客机地址范围完成无效操作。
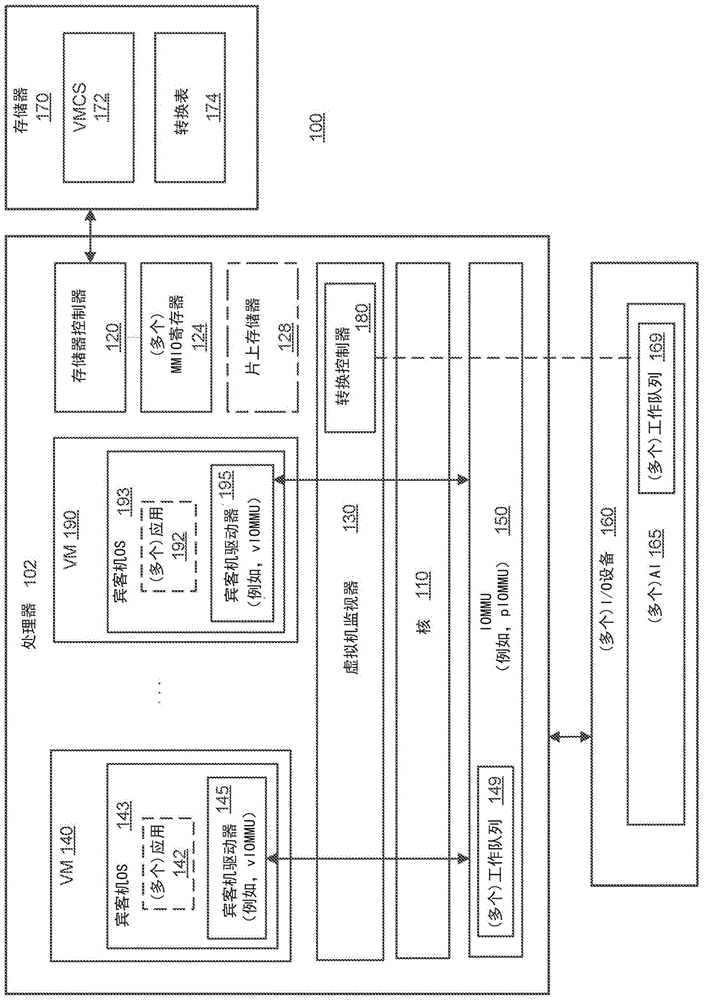
图1是根据各种实现方式的用于输入/输出(i/o)存储器管理单元(iommu)的基于硬件的虚拟化的计算系统100的框图。计算系统100可包括但不限于处理器102,该处理器102耦合至一个或多个i/o设备160并耦合至存储器170(例如,系统存储器或主存储器)。处理器102也可称为“cpu”。本文中的“处理器”或“cpu”将指能够执行指令编码的逻辑或i/o操作的设备。在一个说明性示例中,处理器可以包括算术逻辑单元(alu)、控制单元以及多个寄存器。在进一步的方面中,处理器可以包括一个或多个处理核,并且因此,处理器可以是能够处理单个指令流水线的单核处理器,或可以是可以同时处理多个指令流水线的多核处理器。在另一方面,处理器可被实现为单个集成电路、两个或更多个集成电路,或者可以是多芯片模块(例如,其中各个微处理器管芯被包括在单个集成电路封装中,并且因此,这些微处理器管芯共享单个插槽)的组件。
存储器170可被理解为是片外系统存储器,例如,主存储器,其包括易失性存储器和/或非易失性存储器。在各种实现方式中,存储器170可存储虚拟机控制结构(vmcs)172和转换表174。在一个示例中,转换表的集合174可被存储在vmcs172内,因此,描绘存储器170内的数据结构不旨在是限制性的。在替代示例中,转换表被存储在片上存储器中。
如图1中所示,处理器102可包括各种组件。在一个实现方式中,处理器102可包括如所示地彼此耦合的一个或多个处理器核110和存储器控制器单元120以及其他组件。存储器控制器120可执行使处理器102能够访问存储器170并与存储器170通信的功能。处理器102还可包括通信组件(未示出),该通信组件可用于处理器102的各组件之间的点对点通信。处理器102可用在计算系统100中,该计算系统100包括但不限于台式计算机、平板计算机、膝上型计算机、上网本、笔记本计算机、个人数字助理(pda)、服务器、工作站、蜂窝电话、移动计算设备、智能电话、互联网设备或任何其他类型的计算设备。在另一实现方式中,处理器102可用在片上系统(soc)系统中。在一个实现方式中,soc可包括处理器102和存储器170。用于一个此类系统的存储器可以是dram存储器。dram存储器可以与处理器和其他系统组件位于同一芯片上。另外,诸如存储器控制器或图形控制器之类的其他逻辑块也可以位于该芯片上。
在说明性示例中,处理核110可具有包括处理器逻辑和电路的微架构。具有不同微架构的多个处理器核可共享公共指令集的至少部分。例如,类似的寄存器架构在不同的微架构中可使用各种技术以不同方法来实现,包括专用物理寄存器、使用寄存器重命名机制(诸如,使用寄存器别名表(rat)、重排序缓冲器(rob)、以及引退寄存器堆)的一个或多个动态分配的物理寄存器。
(多个)处理器核110可执行用于处理器102的指令。这些指令可包括但不限于:用于取出指令的预取逻辑、用于对指令解码的解码逻辑、用于执行指令的执行逻辑,等等。处理器核110包括用于对指令和/或数据进行高速缓存的高速缓存(未示出)。高速缓存包括但不限于第一级、第二级和末级高速缓存(llc)、或处理器102内的高速缓存存储器的任何其他配置。处理器核110可以与计算系统100的单个集成电路(ic)芯片上的计算系统一起使用。计算系统100可表示基于可从美国加利福尼亚州圣克拉拉市的
在各种实现方式中,处理器102可进一步包括(多个)存储器映射的i/o寄存器124、片上存储器128(例如,易失性的、闪存、或其他类型的可编程存储器)、虚拟机监视器(vmm)130(或管理程序)、在图1中被标识为vm140至vm190的一个或多个虚拟机(vm)、以及硬件iommu150,该硬件iommu150也称为是物理的或piommu。vm140可执行宾客机os143,在该宾客机os143内可运行数个应用142以及一个或多个宾客机驱动器145。vm190可执行宾客机os193,在该宾客机os193上可运行数个应用192以及一个或多个宾客机驱动器195。处理器102可包括一个或多个附加的虚拟机。在一个示例中,每个宾客机驱动器145或195可以是可以与vmm130和硬件iommu150交互的虚拟iommu(viommu)驱动器。vmm130可进一步包括转换控制器180。
进一步参考图1,vmm130可抽象可包括处理器102的主机机器的硬件平台的物理层,并且将该抽象呈现给宾客机或虚拟机(vm)140或190。vmm130可为vm140至190提供虚拟操作平台,并且管理vm140至190的执行。在一些实现方式中,可提供多于一个的vmm以支持处理器102的vm140至190。每个vm140或190可以是就像其是实际的物理机器那样执行程序的机器的软件实现方式。程序可包括宾客机os143或193、以及分别在宾客机os143和宾客机os193上运行的其他类型的软件和/或应用,例如,应用142和192。
在一些实现方式中,硬件iommu150可使vm140至190能够使用i/o设备160,诸如,以太网硬件、加速图形卡和硬驱动控制器,该i/o设备160可例如借助于置于印刷电路板(pcb)上或位于pcb外的pcb或互连而耦合至处理器102。为了在虚拟机vm140至190与i/o设备160之间传递操作,硬件iommu在i/o设备160的物理存储器地址与vm140、190的虚拟存储器地址之间转换地址。例如,硬件iommu150可经由存储器控制器120通信地耦合至处理核110和存储器170,并且可将vm140至190的虚拟地址映射至存储器中的i/o设备160的物理地址。
在实现方式中,i/o设备160中的每个i/o设备可包括用于由相应的i/o设备支持的每个主管功能的一个或多个可指派接口(ai)165。ai165中的每个ai支持一个或多个工作提交接口。这些接口使vm140和190的诸如宾客机驱动器145和195之类的宾客机驱动器能够在无需由vmm130进行的主机软件干预的情况下直接将工作提交到i/o设备160的ai165。向ai的工作提交的类型是设备专用的,但是可包括基于专用工作队列(dwq)的工作提交和/或基于共享工作队列(swq)的工作提交。在一些示例中,工作队列169可以是由i/o设备160使用以对来自软件的工作排队的环、链表、数组或任何其他数据结构。工作队列169在逻辑上由(传达针对工作的命令、操作数的)工作描述符存储组成,并且能以用于向i/o设备160通知关于新工作提交情况的显式的或隐式的门铃寄存器(例如,环尾寄存器)或门户寄存器来实现。工作队列169可在主存储器中,在设备私有存储器中,或在设备上存储中(例如,在片上存储器128中)被主管。
vm可使用某些指令将工作提交到cpu(例如,处理器102)上的swq,这些指令诸如入列命令(enqcmd)指令或作为管理员的入列命令(enqcmds)指令,这些将参考图4进一步详细地讨论。可从任何特权级别执行enqcmd指令,而enqcmds指令限于管理员级别特权(环-0)软件。这些处理器指令可用于将工作排队到对于对命令所针对的设备类型不可知/透明的任何设备的(多个)swq,在该意义上而言,这些处理器指令可以是“通用的”。
在一些实现方式中,i/o设备160可配置成用于发布访问存储器中的存储器位置的存储器请求(诸如,存储器读取请求和存储器写入请求),并且在一些情况下发布转换请求。存储器请求可以是例如直接存储器访问(dma)读取或写入操作的部分。dma操作可直接或间接地由处理器102执行的软件发起以执行dma操作。取决于在其中在处理器102上执行的软件正在运行的地址空间,可将与那个地址空间对应的地址提供给i/o设备160以访问存储器。例如,在处理器102上执行的宾客机应用(例如,应用142)可将宾客机虚拟地址(gva)提供给i/o设备160。当i/o设备160请求存储器访问时,可由硬件iommu150将宾客机虚拟地址转换为对应的主机物理地址(hpa)以访问存储器,并且可将主机物理地址提供给存储器控制器120以进行访问。
为了管理与来自工作队列169的工作相关联的宾客机至主机asid转换,处理器102可实现在被本文中也被称为地址转换电路的转换控制器180。例如,转换控制器180可实现为vmm130的部分。在替代实现方式中,转换控制器180可实现在处理器102的分开的硬件组件、电路、专用逻辑、可编程逻辑、和微代码中,或实现在其任何组合中。在一个实现方式中,转换控制器180可包括包含与处理核110类似的处理器逻辑和电路的微架构。在一些实现方式中,转换控制器180可包括由处理核110使用的相同处理器逻辑和电路的专用部分。
在进一步的实现方式中,并且进一步参照图1,硬件iommu150还可支持与i/o设备160的(多个)工作队列169类似的(多个)工作队列149。例如,(多个)工作队列149可包括swq,多个虚拟机可将工作提交传输至该swq。例如,(多个vm的)多个宾客机iommu驱动器可将描述符有效载荷提交到硬件iommu150的swq。描述符有效载荷可包括宾客机总线设备功能(bdf)标识符、宾客机asid、以及要无效的宾客机地址范围。
在各种实现方式中,描述符有效载荷与管理命令管理员模式(admcmds)指令相关联,宾客机iommu驱动器(例如,宾客机驱动器145或195)可调用该admcmds指令以供由核110(例如,cpu)执行。宾客机iommu驱动器还可用宾客机bdf标识符、宾客机asid和宾客机地址范围来填充描述符有效载荷。
核110可执行admcmds指令来执行类enqcmds操作,以将描述符有效载荷提交到硬件iommu150的swq。swq可包括有效载荷缓冲器,该有效载荷缓冲器对描述符有效载荷进行缓冲,并且进而处置它们(如将参照图4进一步详细地所讨论)。admcmds指令还可使核将宾客机bdf转换为主机bdf并将宾客机asid转换为主机asid,可将主机bdf和主机asid两者插入到描述符有效载荷中。当描述符有效载荷退出swq时,核可从描述符有效载荷形成管理命令,其被传输到硬件iommu150。因此,管理命令可包含描述符有效载荷,硬件iommu150将访问该描述符有效载荷以执行iotlb和/或设备tlb无效以使硬件iommu150处和/或一个或多个i/o设备160处的宾客机地址范围无效。硬件地址范围可包括vm现在正在重新分配的一个或多个虚拟地址。
在一个实现方式中,宾客机iommu驱动器可访问处理器102的mmio寄存器124内的特定的mmio寄存器。特定的mmio寄存器可包含用于将每个描述符有效载荷提交到其以到达与硬件iommu150相关联的swq的mmio寄存器地址。swq随后能以与i/o设备160的工作队列169的swq响应于enqcmds所做的类似方式来处置来自各虚拟机的描述符命令,这将进一步详细地讨论。
在各种实现方式中,vmm130可执行宾客机bdf标识符和宾客机asid的宾客机至主机转换,并且将这些转换存储在转换表174中。vmm130还可将指针存储在与特定vm相关联的vmcs172中,该指针用于指向用于由vmm130提前设置的转换的嵌套转换表的集合中的第一级表。注意,vmcs172可包括此类指针中的针对vm的每个指针,使得核在执行admcmds指令时知晓在何处找到这些指针。在替代实现方式中,转换表174可存储在vmcs172中,存储在上下文pasid表中,存储在扩展上下文pasid表中,或存储在片上存储器128中。相应地,嵌套转换表的每个集合的位置可有所不同。
图2是根据各种实现方式的系统200的框图,该系统200包括总线设备功能(bdf)标识符转换表的集合210,这些bdf标识符转换表用于将宾客机bdf标识符转换为主机bdf标识符。在一个实现方式中,核110执行admcmds指令,该admcmds指令可使核访问vmcs172中的bdf表指针208。bdf表指针208可指向bdf转换表的集合210中的第一表(例如,总线表215)。注意,bdf转换表的集合210还可被存储在vmcs172中,核110可遍历(例如,走查)该vmcs172以转换传入的宾客机bdf标识符。在其他实现方式中,转换表210与其他转换表174一起存储。
核110还可访问硬件iommu150的swq中的下一描述符有效载荷,并且读出宾客机bdf标识符201。在图5a中图示示例描述符有效载荷(参见row_0(行_0)的字节4和字节5)。例如,宾客机bdf标识符201的第一字节可以是宾客机总线标识符(id)202,并且第二字节可以是宾客机设备功能id204。核110随后可在总线表215内索引,以定位用于与宾客机总线id202相关联的总线的条目,该条目是主机bus_n(总线_n),例如,从宾客机总线id202转换而来的主机总线标识符。
随后,核110可将总线表215的根条目n(主机总线id)用作指向第二转换表的集合中的正确的设备功能表(例如,设备功能表220至设备功能表220n)的指针。核110可从主机总线id根据设备功能id204所指向的设备功能表220n内的描述符有效载荷和索引读出宾客机设备功能标识符(id)204。设备功能表220n内的经索引的位置可存储从宾客机设备功能id204转换而来的主机设备标识符以及主机功能标识符,该主机设备标识符以及主机功能标识符当与主机总线id组合时产生经转换的主机bdf标识符。
图3图示根据一个实现方式的系统300的框图,该系统300包括存储器370,该存储器370用于管理进程地址空间标识符的转换以实现输入/输出设备的可缩放虚拟化。系统300可与图1的处理器102进行比较。如图所示,系统300包括图1的转换控制器180、vm340(其可与图1中的vm140、190进行比较)、以及i/o设备360(其可与图1中的i/o设备160进行比较)。在该示例中,i/o设备360支持一个或多个专用工作队列,诸如,dwq385。dwq385是由仅一个软件实体用于计算系统100的队列。例如,dwq385可被指派给单个vm,诸如,vm340。dwq385包括相关联的asid寄存器320(例如,asidmmio寄存器),该相关联的asid寄存器320可由vm用与应当用于处理来自dwq的工作的vm340相关联的宾客机asid343来编程。vm340中的宾客机驱动器可进一步将dwq385指派给可使用共享虚拟存储器(svm)以直接将工作提交到dwq385的单个内核模式或用户模式客户机。
在一些实现方式中,vmm的转换控制器180拦截来自vm340的将宾客机asid343配置到dwq385的请求。例如,转换控制器180可拦截vm340用宾客机asid343配置dwq385的asid寄存器320的尝试,并替代地用主机asid349来设置asid寄存器320。在这方面,当针对i/o设备360从vm304(例如,经由宾客机驱动器145、195从svm客户机)接收到工作提交347时,将来自dwq385的asid寄存器320的主机asid349用于工作提交347。例如,vmm分配主机asid349,并且在物理iommu的主机asid表330中对该主机asid349进行编程,以便用于使用指向第一级(gva→gpa)转换表的指针345和指向第二级(gpa→hpa)转换表的指针380进行嵌套转换。可通过使用vm340的主机asid349对主机asid表330进行索引。转换控制器180配置dwq385的asid寄存器320中的主机asid。这使得vm能够在没有对vmm的转换控制器180的进一步软中断的情况下直接将命令提交到i/o设备360的ai,并且使dwq能够使用主机asid来将dma请求发送到iommu以进行转换。
在一些实现方式中,地址可以是与vm340的应用相关联的gva。i/o设备360随后可发送具有要由硬件iommu150转换的gva的dma请求。当从i/o设备360接收到包括gva的dma请求或转换请求时,该请求可包括用于对主机asid表330进行索引的asid标签。asid标签可标识主机asid表330中的asid条目335,并且可执行与对hpa的请求相关联的gva的嵌套式2级转换。例如,asid条目335可包括第一地址指针,该第一地址指针指向由vm340的gva→gpa转换指针345设置的cpu页表的基址。asid条目335还可包括第二地址指针,该第二地址指针指向由vmm的iommu驱动器设置以执行地址至存储器370中的物理页的gpa→hpa转换380的转换表的基址。
图4图示根据一个实现方式的另一系统400的框图,该系统400包括存储器470,该存储器470用于管理进程地址空间标识符的转换以实现i/o设备的可缩放虚拟化。系统400可与图1的计算系统100进行比较。例如,系统400包括图1的转换控制器180、多个vm441(其可与图1的vm140和190以及图1的vm240进行比较)、以及i/o设备460(其可与图1的i/o设备160以及图2的i/o设备250进行比较)。在该示例中,使用共享工作队列(swq)485实现向i/o设备460的工作提交447。swq485可由多于一个的软件实体(诸如,由多个vm441)同时使用。i/o设备460可支持任何数量的swq485。swq可在多个vm(例如,宾客机驱动器)之间被共享。vm441中的宾客机驱动器可进一步与vm内的其他内核模式和用户模式客户机共享swq,这些内核模式和用户模式客户机可使用共享虚拟存储器(svm)来直接将工作提交到swq。
在一些实现方式中,vm441使用某些指令将工作提交到cpu(例如,处理器102)上的swq,这些指令诸如,入列命令(enqcmd)、作为管理员的入列命令(enqcmds)指令、或admcmds指令。可从任何特权级别执行enqcmd指令,而enqcmds指令可限于管理员级别特权(环-0)软件。这些处理器指令可用于将工作排队到对于对命令所针对的设备类型不可知/透明的任何设备的(多个)swq,在该意义上而言,这些处理器指令是“通用的”。这些指令产生原子性非通告写入事务(针对其完成响应被返回到处理设备的写入事务)。非通告写入事务是像向目标设备的任何正常mmio写入的所路由的地址。非通告写入事务伴随着其自身携带着正在提交该请求的线程/进程的asid。非通告写入事务伴随着其自身还携带着特权(环-3或环-0),指令在主机上以该特权执行。非通告写入事务还携带着对目标设备专用的命令有效载荷。这些swq典型地利用i/o设备上的工作队列存储来实现,但是还可使用设备外(主机存储器)存储来实现。
与dwq(其中由主机驱动器(例如,转换控制器180)对软件实体的、被指派给其的asid标识进行编程)不同,swq485(由于其共享性质)不具有可预编程的asid寄存器。相反,被分配给执行enqcmd/s指令的软件实体(应用、容器、或vm441,用于将viommu驱动器与vm441包括在一起)的asid作为由enqcmd/s指令生成的工作提交447事务的部分而由处理器102传达。enqcmd/s事务中的宾客机asid420可转换为主机asid,以使得它将被端点设备(例如,i/o设备460)用作用于为处理相应的工作项而生成的上游事务的软件实体的标识。
为了将宾客机asid420转换为主机asid,系统400可在硬件管理的逐vm状态结构(也称为vmcs472)中实现asid转换表435。vmcs472可被存储在存储器的区域中,并且包含例如宾客机的状态、vmm的状态、以及指示在宾客机执行期间vmm在哪些条件下希望重新获得控制的控制信息。vmm可在vmcs472中设置asid转换表435,以作为swq执行的部分将宾客机asid420转换为主机asid。asid转换表435可实现为由宾客机asid420索引的单级表或多级表,该宾客机asid420被包含在被提交到swq485的工作描述符中。
在一些实现方式中,宾客机asid420包括被用于宾客机asid的转换的多个位。这些位可包括例如,被用于标识第一级asid转换表440中的条目的位、以及被用于标识第二级asid转换表450中的条目的位。vmcs472还可包含控制位425,该控制位425控制asid转换。例如,如果asid控制位被设置为值0,则asid转换被禁用,并且宾客机asid被使用。如果控制位被设置为除0以外的值,则asid转换被启用,并且asid转换表被使用以将宾客机asid420转换为主机asid。在这方面,vmm的转换控制器180设置控制位425以启用或禁用转换。在一些实现方式中,vmcs472可将控制位实现为asid转换vmx执行控制位,该asid转换vmx执行控制位可由vmm启用/禁用。
当以非根模式执行enqcmd/s指令且启用控制位425时,系统400尝试使用asid转换表435将工作描述符中的宾客机asid420转换为主机asid。在一些实现方式中,系统400可将宾客机asid中的位19用作进入vmcs472的索引,以标识(两条目)asid转换表435。在一个实现方式中,asid转换表435可包括指向第一级asid表440的基址的指针。第一级asid表440可由宾客机asid(位18:10)索引,以标识指向第二级asid表450的基址的asid表指针445,该第二级asid表450通过宾客机asid(位9:0)来索引以找到经转换的主机asid455。
如果找到转换,则用(例如,工作描述符中的且入列到swq中的)经转换的主机asid455替换宾客机asid420。如果未找到转换,则它导致vmexit(vm退出)。作为vmexit处置的部分,vmm在asid转换表中创建从宾客机asid到主机asid的转换。在vmm处置了vmexit后,vm441被恢复,并且指令被重试。在由svm客户机进行的对enqcmd指令或enqcmds指令(或admcmds指令)的后续执行时,系统400可成功地在asid转换表435中找到主机asid。swq接收具有主机asid的工作描述符,并且使用该主机asid将地址转换请求发送到iommu(诸如,图1的硬件iommu150)以将宾客机虚拟地址(gva)转换为与存储器470中的物理页对应的主机物理地址(hpa)。
当vmexit发生时,vmm检查虚拟iommu的asid表中的宾客机asid。如果宾客机asid在虚拟iommu中被配置,则vmm分配新的主机asid,并且设置vmcs472中的asid转换表435以将宾客机asid映射至主机asid。vmm还在物理iommu中设置主机asid,以用于使用第一级(gva→gpa)和第二级(gpa→hpa)转换进行嵌套转换(在图4中在存储器470内示出)。
如果宾客机asid在虚拟iommu中未经配置,则vmm可将其视为差错,并且将错误注入到vm中或暂停vm。替代地,vmm可配置iommu的asid表中的主机asid而无需设置其第一级和第二级转换指针。当i/o设备将主机asid用于dma转换请求时,i/o设备导致地址转换故障,该地址转换故障进而使i/o设备将prs(页请求服务)请求发布到vmm。对未经配置的宾客机asid的这些prs请求可被注入到vm中,以便以vm专用的方式被处置。vm可作为响应来配置宾客机asid,或者可将prs视为差错并执行差错相关的处置。
注意,由如图4中图示的vmm130设置的宾客机asid至主机asid的转换也可由处理器102在执行admcmds指令时采用。例如,核110可执行admcmds指令,并且除了如图2中那样将宾客机bdf标识符转换为主机bdf标识符之外,还将宾客机asid转换为主机asid并将该主机asid插入在描述符有效载荷内,如将参照图5a所讨论。在一个实现方式中,核110用管理命令数据结构内的主机asid替换宾客机asid,该管理命令数据结构在本文中一般被称为描述符有效载荷。
图5a是图示根据各种实现方式的管理描述符命令数据结构500的框图,该管理描述符命令数据结构500并入了先前引用的描述符有效载荷。图5b是图示根据一个实现方式的管理完成记录550的框图,该管理完成记录550包含指示管理命令的完成的状态。管理描述符命令数据结构500可在每行中包括多达8个字节的数据,并且可包含多行的数据。虽然在某些行中图示出某些类型的数据,但是在其他实现方式中,数据可存储在管理描述符命令数据结构500内除所图示的之外的别处。
在各种实现方式中,可由vm的宾客机iommu驱动器(viommu)针对特定的无效请求来填充管理描述符命令数据结构500。例如,宾客机iommu驱动器可插入宾客机bdf、宾客机asid(图示为pasid)、以及要无效的宾客机地址范围(图示为addr-63:12])。第三行图示完成记录地址,其是存储器中的位置,在该位置处,虚拟iommu驱动器可访问图5b中图示的管理完成记录550,该管理完成记录550包含与无效的完成有关的状态。在一个实现方式中,状态可以是与由硬件iommu150执行的无效操作的成功完成(与否)有关的二进制“是”或“否”。
注意,管理描述符命令数据结构500因此可包括描述符有效载荷信息(宾客机bdf标识符、宾客机asid和要无效的宾客机地址范围)以及由核110在执行admcmds指令期间生成的数据。例如,核110可将主机asid和主机bdf标识符插入到管理描述符命令数据结构500的描述符有效载荷中。在一个实现方式中,用主机bdf标识符来替换宾客机bdf标识符,因为一旦管理描述符命令数据结构500作为命令被发布到硬件iommu150,宾客机bdf标识符就可能不再是有用的。
在各种实现方式中,当相关于硬件iommu的swq来处置描述符有效载荷时,核110最终将管理命令发布到硬件iommu150,该管理命令包括管理描述符命令数据结构500,并且因此也包括描述符有效载荷。硬件iommu150随后可使用管理命令的描述符有效载荷内的主机bdf标识符和主机asid,以执行相对于宾客机地址范围的无效操作。无效操作是以下至少一项:i/o转换后备缓冲器(iotlb)无效、设备tlb无效、或asid高速缓存无效。相关于后者,当宾客机os执行针对宾客机asid的高速缓存无效时,硬件iommu150可执行针对对应的主机asid的高速缓存无效。当一个或多个无效操作例如成功地或不成功地完成时,硬件iommu150可设置管理完成记录550内的状态位。vm的宾客机iommu驱动器可访问先前插入在管理描述符命令数据结构500中的地址处的管理完成记录550。
图6是根据一些实现方式的利用来自硬件iommu150的虚拟化支持来处置来自虚拟机(vm)的无效的方法600的流程图。方法600可由可包括硬件(例如,电路、专用逻辑、可编程逻辑、微代码等)、软件(诸如,在处理设备上运行的指令)、固件或其组合的处理逻辑来执行。在一个实现方式中,图1中的核110或处理器102可执行方法600。虽然以特定顺序或次序示出,但是除非以其他方式指定,否则这些过程的次序可被修改。因此,所图示的实施例应当仅被理解为示例,并且所图示的过程可按不同次序来执行,并且一些过程可被并行地执行。另外,在各实施例中可以省略一个或多个过程。因此,在每一实施例中不要求所有过程。其他过程流程是可能的。
参考图6,方法600可开始于:处理逻辑执行vm的宾客机iommu驱动器,以用宾客机bdf标识符、宾客机asid标识符以及要无效的宾客机地址范围来填充描述符有效载荷(605)。宾客机iommu驱动器可调用admcmds指令,以使处理逻辑将描述符有效载荷发送到适当的mmio寄存器,并因此发往硬件iommu150的正确的swq。方法600能以以下步骤继续:处理逻辑拦截来自vm的描述符有效载荷(610)。方法600能以以下步骤继续:处理逻辑在存储在存储器中的用于vm的vmcs内访问指向第一组转换表(例如,bdf标识符转换表)的第一指针(例如,bdf表指针)(620)。方法600能以以下步骤继续:处理逻辑遍历(例如,走查)第一组转换表,以将宾客机bdf标识符转换为主机bdf标识符(630)。
继续参考图6,方法能以以下步骤继续:处理逻辑判定主机bdf标识符是否有效,例如,是否存在(640)。如果主机bdf标识符不是有效的,则方法600可将差错返回到系统os,该差错可以是错误类型(645)。如果主机bdf标识符是有效的,则方法600能以以下步骤继续:处理逻辑在vmcs内访问指向第二组转换表(例如,asid转换表)的第二指针(例如,asid表指针)(650)。方法600能以以下步骤继续:处理逻辑遍历(例如,走查)第二组转换表,以将宾客机asid转换为主机asid(660)。
方法600能以以下步骤继续:处理器逻辑判定在框660中转换的主机asid是否有效,例如,是否存在(670)。如果主机asid不是有效的,则方法600能以以下步骤继续:再次返回差错或错误(645)。如果主机asid是有效的,则方法600能以以下步骤继续:处理逻辑将主机bdf标识符和主机asid插入在描述符有效载荷中(680)。方法600能以以下步骤继续:处理逻辑将包含描述符有效载荷的管理命令提交到硬件iommu,以执行宾客机地址范围的无效(690)。
图7是图示根据实现方式的用于处置页请求的iommu的基于硬件的虚拟化的计算系统700的框图。系统700包括多个核710、存储器770、硬件iommu750以及一个或多个i/o设备760。图7的系统700的组件和特征与参照图1的计算系统100描述的类似组件和特征是一致的且可组合的。相应地,将对图1的计算系统100进行附加的引用。
存储器770可存储可由硬件iommu750且可由vm140至190访问的数个数据结构。这些数据结构可包括但不限于:包含存储器770中的数据的页711(其也可由i/o设备760经由直接存储器访问(dma)来访问);用于页711在虚拟地址与宾客机物理地址(第一级转换)之间以及在宾客机物理地址与主机物理地址(第二级转换)之间的嵌套转换的分页结构712;用于存储扩展上下文条目(针对不具有pasid的页请求)和上下文条目(针对具有pasid的页请求)的上下文表714;状态表716;以及页请求服务(prs)队列718。
在各种实现方式中,状态表716可对附加信息排队,该附加信息可由硬件iommu750使用以转换来自i/o设备760的页请求内的参数,以便直接注入到对应的vm中,如将更详细地所讨论。对于每个vm可具有prs队列718,以将来自i/o设备的页请求排队到每个相应的vm中。支持prs的i/o设备可将页请求发送到硬件iommu350以解决页错误。此类页请求服务从硬件iommu350被转发到在宾客机中运行的虚拟iommu(viommu)。
此外,硬件iommu750可包括iotlb722、重映射硬件721、页请求队列寄存器723、以及prs能力寄存器725、以及以下讨论引用的其他寄存器。可采用重映射硬件721以重映射访问转换表的页请求,这些转换表由虚拟机的vmm出于为i/o设备760转换共享虚拟存储器(svm)的地址的目的而填充。i/o设备760中的至少一些i/o设备可包括设备tlb(devtlb)762和/或地址转换高速缓存(atc),该atc用于对(典型地)存储器770中的页711的dma地址的主机物理地址的本地副本进行高速缓存,但是在一些情况下,也可对宾客机地址进行高速缓存或可任选地对宾客机地址进行高速缓存,如参考图3所讨论。
支持设备tlb的i/o设备可(通过将转换请求发布到重映射硬件721,并且接收具有成功响应码的转换完成)支持针对由设备tlb获得的转换的可恢复地址转换错误。设备访问的什么内容能够容忍设备tlb检测到的错误且从设备tlb检测到的错误恢复以及设备访问的什么内容不能够容忍设备tlb检测到的错误是因i/o设备而异的。期望设备专用的软件(例如,驱动器)在发起不能够容忍错误的i/o设备访问之前确保具有适当的许可和特权的转换存在。能够从此类设备tlb错误恢复的i/o设备操作典型地涉及两个步骤,例如:1)将可恢复错误报告给主机软件(例如,系统os或vmm);以及2)在由主机软件服务了可恢复错误后,以设备专用方式重放最初导致可恢复错误的i/o设备操作。能通过将页请求消息发布到重映射硬件721以设备专用方式完成可恢复错误向主机软件的报告(例如,通过设备专用的驱动器),或者如果设备支持pci-
在端点i/o设备上的设备tlb762处检测可恢复错误。支持prs能力的i/o设备760可通过重映射硬件721将可恢复错误作为页请求报告给软件。软件可通过经由重映射硬件721将页响应发送到i/o设备来通知对页请求的服务。当在i/o设备处启用了prs能力时,在其i/o设备tlb处检测到的可恢复错误可使i/o设备将页请求消息发布到重映射硬件721。
重映射硬件721可支持页请求队列,作为存储器770中的圆形缓冲器以记录所接收的页请求消息,其中,prs队列718是例如与prs能力相关联的页请求队列的类型。在所公开的实现方式中,对于由(多个)核710执行的每个vm可具有prs队列718。页请求队列寄存器723可配置成管理页请求队列,该页请求队列在本文中可被称为prs队列718中的对于任何给定vm的一个prs队列。页请求队列寄存器723例如可包括以下寄存器:页请求队列地址寄存器(或者仅“地址寄存器”)、页请求队列头寄存器(“头寄存器”)、以及页请求队列尾寄存器(“尾寄存器”)。
在各种实现方式中,系统软件(例如,os或vmm)可对页请求队列地址寄存器编程,以配置主管页请求队列的系统存储器中的连续的存储器区域的基础物理地址和尺寸。页请求队列寄存器可指向页请求队列中软件接下来将处理的页请求描述符。页请求描述符的一个示例是图8a中图示的页请求描述符800。诸如vmm之类的软件可在处理了页请求队列中的一个或多个页请求描述符之后递增地址寄存器。尾寄存器可指向页请求队列中接下来要由硬件iommu150(例如,硬件iommu750)写入的页请求描述符800。可由硬件iommu150在将页请求描述符写入到页请求队列之后使头寄存器递增。
在一些实现方式中,当头寄存器和尾寄存器相等时,硬件iommu750可将页请求队列解释为空。当头寄存器是在尾寄存器之后的一个寄存器时(即,当队列中除一个条目外的所有条目都被使用时),硬件iommu750可将页请求队列解释为满。以此方式,硬件iommu750最多可将n-1个页请求写入在n条目页请求队列中。
为了启用来自i/o设备的页请求,vmm可执行以下操作。例如,vmm可将头寄存器和尾寄存器初始化为0,配置用于处理来自设备的请求的扩展上下文条目使得存在(p)和页请求启用(pre)字段两者被置位,通过地址寄存器设置页请求队列地址和尺寸,通过prs能力寄存器725在i/o设备处配置和启用页请求。
如果以下条件中的任何条件为真,则可丢弃由重映射硬件721接收的页请求消息:1)用于处理页请求的扩展上下文条目中的存在(p)字段或页请求启用(pre)字段为零(“0”);或者2)页请求对于组中的最后页(lpig)字段和请求流响应(srr)字段两者具有值0(指示针对该请求不要求响应),并且以下一项为真:a)错误状态寄存器中的页请求溢出(pro)字段为一(“1”);或者b)页请求队列已经为满(即,头寄存器的当前值是尾寄存器的值之后的一个值),从而使得硬件对错误状态寄存器中的页请求溢出(pro)字段置位。取决于错误事件寄存器的编程,对pro字段置位会导致错误事件被生成。
如果以下一项为真,则由重映射硬件721接收的具有被清除的组中最后页(lpig)字段和经置位的请求流响应(srr)字段的页请求消息导致硬件返回成功的页流响应消息:a)错误状态寄存器中的pro字段为1;或者b)页请求队列已经为满(即,头寄存器的当前值是尾寄存器的值之后的一个值),从而使得硬件对错误状态寄存器中的页请求溢出(pro)字段置位。取决于错误事件寄存器的编程,对pro字段置位会导致错误事件被生成。
如果以下一项为真,则由重映射硬件721接收的具有经置位的lpig字段的页请求消息导致硬件返回成功的页组响应消息:a)错误状态寄存器中的页请求溢出(pro)字段为一(“1”);或b)页请求队列已经为满(即,头寄存器的当前值是尾寄存器的值之后的一个值),从而使得硬件iommu750对错误状态寄存器中的pro字段置位。取决于错误事件寄存器的编程,对pro字段置位会导致错误事件被生成。如果在接收到页请求消息时上述条件无一为真,则重映射硬件721可执行隐式无效,以使被高速缓存在iotlb722以及分页结构高速缓存中的控制页请求中指定的地址的任何转换无效。重映射硬件721可进一步将页请求描述符写入到在由头寄存器指定的偏移处的页请求队列条目,并且使头寄存器中的值递增。取决于被写入到页请求队列的页请求描述符的类型以及页请求事件寄存器的编程,可生成可恢复错误事件。
在页请求可被报告给系统软件之前由重映射硬件721对iotlb和分页结构高速缓存的隐式无效,以及在发送页请求之前使来自i/o设备的设备tlb的错误转换无效的i/o设备要求强制要求在页请求被报告给软件之前不存在针对出错的页地址的经高速缓存的转换。这允许软件通过对分页条目作出必要的修改来服务可恢复错误,并且发送页响应以在设备处重新开始出错的操作,而无需执行任何显式的无效操作。
图8a是图示根据一个实现方式的可由硬件iommu750写入的页请求描述符800的框图。页请求描述符800也可被呈现至vm的iommu驱动器,以将页请求注入到vm的宾客机os中。页请求描述符800尺寸可以是128位。每个页请求描述符的类型字段(位1:0)可标识描述符类型。可使用页请求描述符800来报告由重映射硬件721接收的页请求消息。
页请求消息:页请求消息由i/o设备760发送以报告作为页组的部分(即,在页请求组索引字段中具有相同值)的一个或多个页请求,在软件已服务了作为页组的部分的请求之后,由设备预期针对这一个或多个页请求的页组响应。页组可由小如单个页请求组成。具有pasid存在字段值一(“1”)的页请求被视为具有pasid的页请求。具有pasid存在字段值零(“0”)的页请求被视为不具有pasid的页请求。对于根复合体集成设备,页组中除最后的页请求(即,具有组中的最后页(lpig)字段值0的请求)之外的任何具有pasid的页请求当那个单独的页请求被服务时可通过对请求流式响应(srr)字段置位来请求页流响应。
页请求描述符800(page_req_dsc)可包括以下字段,以下字段是非排他性列表。
总线号:该总线号字段包含发送页请求的端点设备的源id的高8位。
设备和功能号:dev#:func#字段包含发送页请求的端点设备的源id的低8位。
pasid存在:如果pasid存在字段为1,则页请求由于由具有pasid的请求引起的可恢复错误导致。如果pasid存在字段为0,则页请求由于由不具有pasid的请求引起的可恢复错误导致。
pasid:如果pasid存在字段为1,则该字段提供经历导致该页请求的可恢复错误的具有pasid的请求的pasid值。如果pasid存在字段为0,则该字段未定义。
地址(addr):如果请求读取字段和请求写入字段两者为0,则该字段是预留的。否则,该字段指示出错的页地址。如果pasid存在字段为1,则地址字段指定用于第一级转换的输入地址。如果pasid存在字段为0,则地址字段指定用于第二级转换的输入地址。
页请求组索引(prgi):9位的页请求组索引字段标识该请求是其部分的页组。预期软件在相应的页响应中返回页请求组索引。如果请求读取字段和请求写入字段两者为0,则该字段是未定义的。来自具有相同pasid值的设备的具有pasid的多个页请求(pasid存在字段值1)可包含任何页请求组索引值(0-511)。然而,对于给定的pasid值,最多可存在一个具有经置位的组中的最后页(lpig)字段以及相同的页请求组索引值的、来自设备的未决的具有pasid的页请求。来自设备的不具有pasid的多个页请求(pasid存在字段值0)可包含任何页请求组索引值(0-511)。然而,最多可存在一个具有经置位的组中的最后页字段以及相同的页请求组索引值的、来自设备的未决的不具有pasid的页请求。
组中的最后页(lpig):如果组中的最后页字段为1,则这是由页请求组索引字段中的值标识的页组中的最后请求。
请求流式响应(srr):如果组中的最后页(lpig)字段为0,则请求流式响应(srr)字段中的值1指示在该单独的页请求被服务之后针对该单独的页请求来请求页流响应。如果组中的最后页(lpig)字段为1,则该字段是预留的(0)。
出错时阻塞(bof):如果组中的最后页(lpig)字段为0且请求流式响应(srr)字段为1,则出错时阻塞(bof)字段中的值1指示导致该页请求的错误导致对于根复合体集成端点设备的阻塞条件。该字段是信息性的,并且可由软件使用以相对于普通(非阻塞)页请求来优先处理此类阻塞页请求,从而获得改善的端点设备性能或服务质量。如果组中的最后页(lpig)字段为1或请求流式响应(srr)字段为0,则该字段是预留的(0)。
请求读取:如果请求读取字段为1,则经历(导致该页请求的)可恢复错误的请求要求对页的读取访问。
请求写入:如果请求写入字段为1,则经历(导致该页请求的)可恢复错误的请求要求对页的写入访问。
请求执行:如果pasid存在字段、请求读取字段和请求执行字段全都为1,则经历导致该页请求的可恢复错误的具有pasid的请求要求对页的执行访问。
请求特权模式:如果pasid存在为1,并且请求读取字段或请求写入字段中的至少一个字段为1,则请求特权模式字段指示经历(导致该页请求的)可恢复错误的具有pasid的请求的特权。该字段的值1指示管理员特权,并且值0指示用户特权。
私有数据:可由根复合体集成端点(例如,i/o设备)使用私有数据字段以唯一地标识与单独的页请求相关联的设备专用私有信息。对于
对于指示页流响应的具有pasid的页请求(srr=1且lpig=0),在相应的页请求被服务之后,软件以页流响应来进行响应。对于指示组中的最后请求的页请求(lpig=1),在服务了作为那个页组的部分的页请求之后,软件以页组响应来进行响应。
图8b是图示根据一个实现方式的页组响应描述符850的框图。页组响应描述符850可由软件(例如,vm)响应于指示组中的最后请求的页请求而发布。在服务了具有相同的页请求组索引值的页请求之后,页组响应被发布。页组请求描述符850(page_grp_resp_dsc)包括以下字段,以下字段是非排他性列表。
请求方id:请求方id字段标识页请求组响应所针对的端点i/o设备功能。请求方id字段的高8位指定总线号,并且低8位指定设备号和功能号。软件从相应的页请求描述符800复制总线号字段、设备号字段和功能号字段,以在页组响应描述符中形成请求方id字段。
pasid存在:如果pasid存在字段为1,则页组响应携带pasid。该字段中的值应当与相应的页请求描述符800的pasid存在字段中的值匹配。
pasid:如果pasid存在字段为1,则该字段提供针对页组响应的pasid值。该字段中的值应当与相应的页请求描述符800的pasid字段中的值匹配。
页请求组索引:页请求组索引标识该页组响应的页组。该字段中的值应当与相应的页请求描述符的页请求组索引字段中的值匹配。
响应码:响应码指示页组响应状态。该字段遵循如在pci
表1
私有数据:使用私有数据字段来传达与页请求和响应相关联的设备专用私有信息。该字段中的值应当与相应的页请求描述符800的私有数据字段中的值匹配。
进一步参考图1、图7和图8a-图8b,当前实现方式用于将硬件iommu750配置成在不需要任何vmm开销的情况下直接将页请求注入到vm140至190中。避免vmm功能的软件开销将极大地增加i/o设备760与vm之间的页请求处置的效率和带宽。为了这样做,硬件iommu750可执行逆向地址转换以查找主机物理bdf和主机pasid,并且分别将这些转换为宾客机bdf和宾客机虚拟pasid。为了支持该附加功能,执行逆向转换的相关信息可被存储在扩展上下文条目中(针对不具有pasid的页请求),并且针对具有pasid的页请求被存储在上下文条目中。回忆一下,扩展上下文条目和上下文条目被存储在存储器770中的上下文表714中。
进一步注意,当常规硬件iommu生成页错误时,该常规硬件iommu不区分在第一级页表还是第二级页表中生成页错误。相应地,硬件iommu750可被增强以标识哪级页表导致或引起页错误。硬件iommu750还可被增强以支持多个prs队列718,对于每个vm有一个prs队列。这些prs队列718可被映射,并且可直接从相应的vm访问。
在各实现方式中,硬件iommu750的扩展上下文条目和上下文条目可被修改以包括至少以下信息:1)用于被包括在宾客机页请求中的宾客机bdf;2)用于被包括在宾客机页请求中的宾客机pasid;3)用于向拥有i/o设备的宾客机vm生成通告中断的中断句柄;以及4)将在其中对接收到的页请求(prs)排队以进行处置的prs队列指针。在扩展上下文条目和/或上下文条目不具有足够的空闲空间来存储该附加信息的情况下,pasid状态表指针可替代地指向存储以上四条信息的新条目(例如,在状态表716中)。硬件iommu750随后可使用上下文条目内的该附加信息,或者可跟随指向状态表716中的新条目的pasid状态表指针以检取该附加信息。
在实现方式中,当硬件iommu750从i/o设备接收到页请求时,硬件iommu750可判定页错误发生在(存储在分页结构712中的)嵌套页表的第一级还是第二级中。如果页错误发生在第一级页表中,则将由将要接收页请求的vm处理该页错误。并且如果页错误发生在第二级页表中,则将由将要接收页请求的vmm或主机os处理该页错误。硬件iommu750随后可标识来自扩展上下文条目(针对不具有pasid的页请求)或来自上下文条目(针对具有pasid的页请求)的宾客机bdf、宾客机pasid、prs队列和prs中断。硬件iommu750可在将中断通告给宾客机vm之前将具有适当的宾客机bdf和宾客机pasid的经转换的prs页请求置于对应的prs队列中。
图9是根据一些实现方式的利用来自硬件iommu的虚拟化支持来处置来自i/o设备的页请求的方法900的流程图。方法900可由可包括硬件(例如,电路、专用逻辑、可编程逻辑、微代码等)、软件(诸如,在处理设备上运行的指令)、固件或其组合的处理逻辑来执行。在一个实现方式中,计算设备100(图1)或700(图7)可执行方法900。更具体地,硬件iommu150(图1)或750(图7)可执行方法900。虽然以特定顺序或次序示出,但是除非以其他方式指定,否则这些过程的次序可被修改。因此,所图示的实施例应当仅被理解为示例,并且所图示的过程可按不同次序来执行,并且一些过程可被并行地执行。另外,在各实施例中可以省略一个或多个过程。因此,在每一实施例中不要求所有过程。其他过程流程是可能的。
参考图9,方法900可开始于以下步骤:处理逻辑(例如,处理器102)针对存储器中具有与i/o设备相关联的dma地址的页执行主机bdf至宾客机bdf的转换以及主机pasid至宾客机pasid的转换(910)。一旦这些转换完成,则方法900能以以下步骤继续:(例如,硬件iommu的)处理逻辑将宾客机bdf和宾客机pasid存储在存储器中的状态表条目中(915)。方法900能以以下步骤继续进行:处理逻辑将与页相关联的中断句柄和prs队列指针存储在状态表条目中(920)。方法900能以以下步骤继续进行:处理逻辑将地址存储到状态表中的位置,作为与存储器中的页相关联的上下文条目和扩展上下文条目中的pasid状态表指针(925)。
在时间过去之后,继续参考图9,方法900能以以下步骤继续进行:处理逻辑拦截来自i/o设备的页请求(由于页错误)(930)。在一个实现方式中,页请求以参考图8a所讨论的页请求描述符800的形式到来。方法900能以以下步骤继续进行:处理逻辑跟随指向状态表中的位置的(先前被存储在上下文条目和扩展上下文条目中的)pasid状态表指针(935)。方法900能以以下方式继续进行:处理逻辑从状态表条目检取宾客机bdf、宾客机pasid、中断句柄以及prs队列指针(940)。方法900能以以下步骤继续进行:处理逻辑判定页错误是第一级页错误还是第二级页错误(950)。如果页错误是第一级页错误(例如,发生在第一级页表中),则方法900能以以下步骤继续进行:处理逻辑使用(例如,被插入到页请求描述符800中的)宾客机bdf和宾客机pasid来生成宾客机页请求(955)。方法900能以以下步骤继续进行:处理逻辑将prs队列中的宾客机页请求置于prs队列指针的位置处(960)。方法900能以以下步骤继续进行:处理逻辑使用中断句柄将中断通告给宾客机vm以处置宾客机页请求(965)。然而,如果页错误是第二级页错误(例如,发生在第二级页表中),则方法900能以以下步骤继续进行:处理逻辑允许vmm或主机os处置页请求(980)。方法900的过程可被逆转以往回将页响应发送到i/o设备。
进一步参考图6-图7、图8a-图8b和图9,页响应被往回发送到具有与页请求一起到来的原始的(主机)pasid的i/o设备。对于使用enqcmd指令被提交的页请求,页请求可与主机pasid一起到达。但是,将页请求发送到宾客机vm将与宾客机pasid一起发送。对于直接指派的专用队列(图3),宾客机软件(例如,vm中的os)可直接将宾客机pasid编程在i/o设备中。相应地,那些页请求可已经与宾客机pasid一起到达。结果,页请求可与宾客机pasid或主机pasid一起到达硬件iommu750,并且硬件iommu在将页请求注入到vm之前将适当地将主机pasid转换为宾客机pasid。
在各种实现方式中,页请求中的pasid可由于经由enqcmd指令被提交到i/o设备的命令而包括主机pasid,或者可在这是
在实现方式中,为了帮助保持页请求的原始(主机)pasid,硬件iommu可将pasid保存在i/o设备上或由vm的iommu驱动器指派的系统存储器中的内部数据结构中(例如,保存在上下文条目中,保存在扩展上下文条目中,或保存在状态表中)。iommu随后可将此类指派的散列查找置于页请求描述符800的私有数据字段中。以此方式,硬件iommu750可具有对用于在生成页响应时使用的宾客机pasid和主机pasid两者的访问权。也就是说,当处理页响应时,预期私有数据将被复制。宾客机iommu驱动器在使用先前讨论的admcmds指令通告页响应描述符时可简单地将私有数据复制到页响应描述符850中。硬件iommu750随后可查找数据,并且用主机pasid来替换宾客机pasid,该主机pasid可进入页响应。随后可由最初发布页请求的i/o来传输页响应。
图10a是图示根据实现方式的用于可实现iommu的基于硬件的虚拟化的处理器1000的微架构的框图。具体而言,处理器1000描绘根据本公开的至少一个实现方式的要被包括在处理器中的有序架构核以及寄存器重命名逻辑、乱序发布/执行逻辑。
处理器1000包括前端单元1030,该前端单元1030耦合至执行引擎单元1050,并且前端单元1030和执行引擎单元1050两者都耦合至存储器单元1070。处理器1000可包括精简指令集计算(risc)核、复杂指令集计算(cisc)核、超长指令字(vliw)核、或混合或替代的核类型。作为又一选项,处理器1000可包括专用核,诸如例如,网络或通信核、压缩引擎、图形核,等等。在一个实现方式中,处理器1000可以是多核处理器或者可以是多处理器系统的部分。
前端单元1030包括耦合至指令高速缓存单元1034的分支预测单元1032,该指令高速缓存单元1034耦合至指令转换后备缓冲器(tlb)1036,该指令转换后备缓冲器1036耦合至指令取出单元1038,该指令取出单元1038耦合至解码单元1040。解码单元1040(也称为解码器)可对指令解码,并且生成从原始指令解码出的、或以其他方式反映原始指令的、或从原始指令导出的一个或多个微操作、微代码进入点、微指令、其他指令、或其他控制信号作为输出。解码器1040可使用各种不同的机制来实现。合适机制的示例包括但不限于,查找表、硬件实现、可编程逻辑阵列(pla)、微代码只读存储器(rom)等。指令高速缓存单元1034进一步耦合至存储器单元1070。解码单元1040耦合至执行引擎单元1050中的重命名/分配器单元1052。
执行引擎单元1050包括重命名/分配器单元1052,该重命名/分配器单元1052耦合至引退单元1054和一个或多个调度器单元的集合1056。(多个)调度器单元1056表示任何数量的不同调度器电路,包括预留站(rs)、中央指令窗等。(多个)调度器单元1056耦合至(多个)物理寄存器集合单元1058。(多个)物理寄存器集合单元1058中的每一个物理寄存器集合单元表示一个或多个物理寄存器集合,这些物理寄存器集合中不同的物理寄存器集合存储一种或多种不同的数据类型,诸如,标量整数、标量浮点、紧缩整数、紧缩浮点、向量整数、向量浮点等、状态(例如,作为要执行的下一条指令的地址的指令指针)等。(多个)物理寄存器集合单元1058由引退单元1054重叠,以图示可实现寄存器重命名和乱序执行的各种方式(例如,使用(多个)重排序缓冲器和(多个)引退寄存器集合;使用(多个)未来文件、(多个)历史缓冲器、以及(多个)引退寄存器集合;使用寄存器映射和寄存器池;等等)。
通常,架构寄存器从处理器外部或从编程者的视角来看是可见的。这些寄存器不限于任何已知的特定类型的电路。各种不同类型的寄存器只要能够存储并提供如本文中所描述的数据,那么它们就是合适的。合适寄存器的示例包括但不限于:专用物理寄存器、使用寄存器重命名的动态分配的物理寄存器、以及专用物理寄存器和动态分配的物理寄存器的组合等。引退单元1054和(多个)物理寄存器集合单元1058耦合至(多个)执行集群1060。(多个)执行集群1060包括一个或多个执行单元的集合1062和一个或多个存储器访问单元的集合1064。执行单元1062可执行各种操作(例如,移位、加法、减法、乘法)并可对各种类型的数据(例如,标量浮点、紧缩整数、紧缩浮点、向量整数、向量浮点)进行操作。
尽管一些实现方式可以包括专用于特定功能或功能集的多个执行单元,但是其他实现方式可包括仅一个执行单元或全都执行所有功能的多个执行单元。(多个)调度器单元1056、(多个)物理寄存器集合单元1058、以及(多个)执行集群1060被示出为可能是复数个,因为某些实现方式为某些数据/操作类型创建了分开的流水线(例如,各自都具有它们自己的调度器单元、物理寄存器集合单元和/或执行集群的标量整数流水线、标量浮点/紧缩整数/紧缩浮点/向量整数/向量浮点流水线、和/或存储器访问流水线——并且在分开的存储器访问流水线的情况下,某些实现方式被实现为其中仅该流水线的执行集群具有(多个)存储器访问单元1064)。还应当理解,在使用分开的流水线的情况下,这些流水线中的一个或多个可以是乱序发布/执行,并且其余流水线可以是有序的。
存储器访问单元的集合1064耦合至存储器单元1070,该存储器单元1070可包括数据预取器1080、数据tlb单元1072、数据高速缓存单元(dcu)1074、以及第二级(l2)高速缓存单元1076,仅举数例。在一些实现方式中,dcu1074也被称为第一级数据高速缓存(l1高速缓存)。dcu1074可处置多个未决的高速缓存未命中,并继续服务传入的存储和加载。它还支持维护高速缓存一致性。数据tlb单元1072是用于通过映射虚拟和物理地址空间来改善虚拟地址转换速度的高速缓存。在一个示例性实现方式中,存储器访问单元1064可包括加载单元、存储地址单元和存储数据单元,其中的每一个均耦合至存储器单元1070中的数据tlb单元1072。l2高速缓存单元1076可耦合至一个或多个其他级别的高速缓存,并最终耦合至主存储器。
在一个实现方式中,数据预取器1080通过自动地预测程序将消耗哪些数据来推测性地将数据加载/预取到dcu1074。预取可以指在存储在存储器层级结构(例如,较低级别的高速缓存或存储器)的一个存储器位置(例如,地点)中的数据被处理器实际要求之前,将该数据传送至更靠近(例如,产生更低的访问等待时间)处理器的较高级别的存储器位置。更具体地,预取可以指在处理器发布对正在被返回的特定数据的需求之前,对从较低级别高速缓存/存储器中的一个较低级别高速缓存/存储器到数据高速缓存和/或预取缓冲器的数据的早期检取。
处理器1000可支持一个或多个指令集(诸如,x86指令集(具有增加有更新版本的一些扩展)、英国赫特福德郡金斯兰利的想象技术公司(imaginationtechnologies)的mips指令集、加利福尼亚州桑尼威尔的arm控股公司的arm指令集(具有任选的附加扩展,诸如neon))。
应当理解,核可支持多线程化(执行两个或更多个并行的操作或线程的集合),并且可以按各种方式来完成该多线程化,各种方式包括时分多线程化、同时多线程化(其中单个物理核为物理核正在同时多线程化的各线程中的每一个线程提供逻辑核)、或其组合(例如,时分取出和解码以及此后诸如
尽管在乱序执行的上下文中描述了寄存器重命名,但应当理解,可以在有序架构中使用寄存器重命名。虽然处理器的所图示的实现方式也包括单独的指令和数据高速缓存单元以及共享的l2高速缓存单元,但替代实现方式可具有用于指令和数据两者的单个内部高速缓存,诸如例如,第一级(l1)内部高速缓存、或多个级别的内部高速缓存。在一些实现方式中,系统可包括内部高速缓存和在核和/或处理器外部的外部高速缓存的组合。或者,所有高速缓存都可以在核和/或处理器的外部。
图10b是图示根据本公开的一些实现方式的可实现iommu的基于硬件的虚拟化的、根据图10a的处理器1000的有序流水线以及寄存器重命名级、乱序发布/执行流水线的框图。图10b中的实线框图示出有序流水线1001,而虚线框图示出寄存器重命名、乱序发布/执行流水线1003。在图10b中,流水线1001和流水线1003包括取出级1002、长度解码级1004、解码级1006、分配级1008、重命名级1010、调度(也被称为分派或发布)级1012、寄存器读取/存储器读取级1014、执行级1016、写回/存储器写入级1018、异常处置级1022和提交级1024。在一些实现方式中,级1002-1024的排序可以与所图示的不同,并且不限于图10b中所示的特定排序。
图11图示根据本公开的实现方式的用于处理器1100的微架构的框图,该处理器1100包括可实现iommu的基于硬件的虚拟化的处理器或集成电路的逻辑电路。在一些实现方式中,根据一个实现方式的指令可被实现为对具有字节尺寸、字尺寸、双字尺寸、四字尺寸等并具有诸如单精度整数、双精度整数、单精度浮点和双精度浮点类型之类的数据类型的数据元素进行操作。在一个实现方式中,有序前端1101是处理器1100的部分,该部分取出将要被执行的指令,并准备这些指令以便稍后在处理器流水线中使用。可以在处理器1100中实现页添加和内容复制的实现方式。
前端1101可包括若干单元。在一个实现方式中,指令预取器1116从存储器取出指令,并将指令馈送至指令解码器1118,指令解码器1118进而对指令进行解码或解释。例如,在一个实现方式中,解码器将接收到的指令解码为机器可以执行的被称为“微指令”或“微操作”(也称为微op或uop)的一个或多个操作。在其他实现方式中,解码器将指令解析为操作码和对应的数据及控制字段,它们被微架构用于执行根据一个实现方式的操作。在一个实现方式中,跟踪高速缓存1130取得经解码的微操作,并将它们组装为微操作队列1134中的按程序排序的序列或踪迹以供执行。当跟踪高速缓存1130遇到复杂指令时,微代码rom(或ram)1132提供完成操作所需的微操作。
一些指令被转换为单个微操作,而其他指令需要若干个微操作以完成整个操作。在一个实现方式中,如果需要多于四个微操作来完成指令,则解码器1118访问微代码rom1132以进行该指令。对于一个实现方式,指令可被解码为少量的微操作以用于在指令解码器1118处进行处理。在另一实现方式中,如果需要数个微操作来完成操作,则可将指令存储在微代码rom1132中。跟踪高速缓存1130参考进入点可编程逻辑阵列(pla)来确定正确的微指令指针,以从微代码rom1132读取微代码序列以完成根据一个实现方式的一条或多条指令。在微代码rom1132完成对于指令的微操作定序之后,机器的前端1101恢复从跟踪高速缓存1130取出微操作。
乱序执行引擎1103是将指令准备好用于执行的地方。乱序执行逻辑具有数个缓冲器,用于将指令流平滑并且重排序,以在指令流沿流水线向下行进并被调度以供执行时优化性能。分配器逻辑分配每一个微操作需要的机器缓冲器和资源,以用于执行。寄存器重命名逻辑将逻辑寄存器重命名为寄存器集合中的条目。在指令调度器(存储器调度器、快速调度器1102、慢速/通用浮点调度器1104、以及简单浮点调度器1106)之前,分配器也将每一个微操作的条目分配在两个微操作队列中的一个微操作队列中,一个微操作队列用于存储器操作,另一个微操作队列用于非存储器操作。微操作调度器1102、1104、1106基于对它们的依赖性输入寄存器操作数源的准备就绪以及微操作完成它们的操作所需的执行资源的可用性来确定微操作何时准备好用于执行。一个实现方式的快速调度器1102可在主时钟周期的每半个周期上进行调度,而其他调度器可仅仅在每一个主处理器时钟周期上调度一次。调度器对分派端口进行仲裁以调度用于执行的微操作。
寄存器集合1108、1110位于调度器1102、1104、1106与执行块1111中的执行单元1112、1114、1116、1118、1120、1122、1124之间。存在分别用于整数操作和浮点操作的单独的寄存器集合1108、1110。一个实现方式的每一个寄存器集合1108、1110也包括旁路网络,该旁路网络可以将尚未被写入到寄存器集合中的刚完成的结果旁路或转发至新的依赖性微操作。整数寄存器集合1108和浮点寄存器集合1110也能够彼此传递数据。对于一个实现方式,整数寄存器集合1108被划分为两个单独的寄存器集合:用于数据的低阶的32位的一个寄存器集合、以及用于数据的高阶的32位的第二寄存器集合。一个实现方式的浮点寄存器集合1110具有128位宽度的条目,因为浮点指令典型地具有从64位宽度至128位宽度的操作数。
执行块1111包括执行单元1112、1114、1116、1118、1120、1122、1124,在执行单元1112、1114、1116、1118、1120、1122、1124中实际执行指令。该部分包括存储微指令需要执行的整数和浮点数据操作数值的寄存器集合1108、1110。一个实现方式的处理器1100由以下数个执行单元所组成:地址生成单元(agu)1112、agu1114、快速alu1116、快速alu1118、慢速alu1120、浮点alu1112、浮点移动单元1114。对于一个实现方式,浮点执行块1112、1114执行浮点、mmx、simd、sse或其他操作。一个实现方式的浮点alu1112包括64位除以64位浮点除法器,用于执行除法、平方根、以及余数微操作。对于本公开的实现方式,涉及浮点值的指令可利用浮点硬件来处置。
在一个实现方式中,alu操作去往高速alu执行单元1116、1118。一个实现方式的快速alu1116、1118能以半个时钟周期的有效等待时间来执行快速操作。对于一个实现方式,大多数复杂整数操作去往慢速alu1120,因为慢速alu1120包括用于长等待时间类型的操作的整数执行硬件,诸如,乘法器、移位器、标志逻辑和分支处理。存储器加载/存储操作由agu1122、1124执行。对于一个实现方式,整数alu1116、1118、1120在对64位数据操作数执行整数操作的上下文中进行描述。在替代实现方式中,alu1116、1118、1120可以被实现为支持各种数据位,包括16位、32位、128位、256位等。类似地,浮点单元1122、1124可以被实现为支持具有各种宽度的位的一系列操作数。对于一个实现方式,浮点单元1122、1124可以结合simd和多媒体指令对128位宽的紧缩数据操作数进行操作。
在一个实现方式中,在父加载已完成执行之前,微操作调度器1102、1104、1106分派依赖性操作。因为微操作在处理器1100中被推测地调度和执行,所以处理器1100也包括用于处置存储器未命中的逻辑。如果数据加载在数据高速缓存中未命中,则在流水线中会存在已带着临时错误的数据离开调度器的运行中的依赖性操作。重放机制跟踪使用错误数据的指令并重新执行这些指令。仅依赖性操作需要被重放,并且允许独立的操作完成。处理器的一个实现方式的调度器和重放机制也被设计成用于捕捉用于文本串比较操作的指令序列。
术语“寄存器”可以指被用作指令的部分以标识操作数的板上处理器存储位置。换言之,寄存器可以是从处理器外部(从编程者的角度来看)可用的那些处理器存储位置。然而,实现方式的寄存器在含义上不应当限于特定类型的电路。相反,实现方式的寄存器能够存储并提供数据,并且能够执行本文中所描述的功能。本文中所描述的寄存器可以由处理器中的电路使用任何数量的不同技术来实现,这些不同技术诸如专用物理寄存器、使用寄存器重命名的动态分配的物理寄存器、专用物理寄存器和动态分配的物理寄存器的组合等。在一个实现方式中,整数寄存器存储32位的整数数据。一个实现方式的寄存器集合还包含用于紧缩数据的八个多媒体simd寄存器。
对于本文中的讨论,寄存器应被理解为设计成保存紧缩数据的数据寄存器,诸如,来自美国加利福尼亚州圣克拉拉市的英特尔公司的启用了mmx技术的微处理器中的64位宽的mmxtm寄存器(在一些实例中也称为“mm”寄存器)。这些mmx寄存器(以整数形式和浮点形式两者是可用的)可以与伴随simd和sse指令的紧缩数据元素一起操作。类似地,也可以使用涉及sse2、sse3、sse4或以外的(统称为“ssex”)技术的128位宽的xmm寄存器来保存此类紧缩数据操作数。在一个实现方式中,在存储紧缩数据和整数数据时,寄存器不需要在这两种数据类型之间进行区分。在一个实现方式中,整数和浮点可被包含在同一寄存器集合中,或被包含在不同的寄存器集合中。此外,在一个实现方式中,浮点和整数数据可被存储在不同的寄存器中,或被存储在相同的寄存器中。
实现方式能以许多不同的系统类型实现。现在参考图12,所示出的是根据实现方式的多处理器系统1200的框图,该多处理器系统1200可实现iommu的基于硬件的虚拟化。如图12中所示,多处理器系统1200是点对点互连系统,并且包括经由点对点互连1250耦合的第一处理器1270和第二处理器1280。如图12中所示,处理器1270和1280中的每一个处理器可以是多核处理器,包括第一处理核和第二处理器核(即,处理器核1274a和1274b以及处理器核1284a和1284b),但是潜在地,多得多的核可存在于处理器中。虽然以两个处理器1270、1280示出,但是应当理解,本公开的范围不限于此。在其他实现方式中,在给定处理器中可存在一个或多个附加处理器。
处理器1270和1280被示出为分别包括集成存储器控制器单元1272和1282。处理器1270还包括作为其总线控制器单元的部分的点对点(p-p)接口1276和1288;类似地,第二处理器1280包括p-p接口1286和1288。处理器1270、1280可经由使用点对点(p-p)接口电路1278、1288的p-p接口1250来交换信息。如图12中所示,imc1272和1282将处理器耦合至相应的存储器,即存储器1232和存储器1234,这些存储器可以是本地附连到相应处理器的主存储器的部分。
处理器1270、1280可经由使用点对点接口电路1276、1294、1286、1298的各个p-p接口1252、1254与芯片组1290交换信息。芯片组1290还可经由高性能图形接口1239来与高性能图形电路1238交换信息。
芯片组1290可以经由接口1296耦合至第一总线1216。在一个实现方式中,第一总线1216可以是外围组件互连(pci)总线或诸如pciexpress总线或互连总线之类的总线,但是本公开的范围不限于此。
现在参考图13,所示出的是根据本公开的实现方式的第三系统1300的框图,该第三系统1300可实现iommu的基于硬件的虚拟化。图12和图13中的同样的元件带有同样的附图标记,并且已从图12中省去了图13中的某些方面,以避免使图13的其他方面模糊。
图13图示处理器1370、1380可分别包括集成存储器和i/o控制逻辑(“cl”)1372和1392。对于至少一个实现方式,cl1372、1382可包括诸如本文中所描述的集成存储器控制器单元。另外,cl1372、1392还可包括i/o控制逻辑。图13图示存储器1332、1334耦合至cl1372、1392,并且i/o设备1314也耦合至控制逻辑1372、1392。传统i/o设备1315耦合至芯片组1390。
图14是可实现iommu的基于硬件的虚拟化的示例性片上系统(soc)1400,该示例性soc1400可包括核1402a、…、1402n中的一个或多个核。本领域中已知的对膝上型设备、台式机、手持式pc、个人数字助理、工程工作站、服务器、网络设备、网络集线器、交换机、嵌入式处理器、数字信号处理器(dsp)、图形设备、视频游戏设备、机顶盒、微控制器、蜂窝电话、便携式媒体播放器、手持设备以及各种其他电子设备的其他系统设计和配置也是合适的。一般地,能够包含如本文中所公开的处理器和/或其他执行逻辑的各种各样的系统或电子设备一般都是合适的。
在图14中的示例性soc1400内,虚线框是更高级的soc上的特征。(多个)互连单元1402可耦合至:应用处理器1417,包括一个或多个核的集合1402a-n以及(多个)共享高速缓存单元1406;系统代理单元1410;(多个)总线控制器单元1416;(多个)集成存储器控制器单元1414;一个或多个媒体处理器的集合1420,可包括集成图形逻辑1408、用于提供静止和/或视频照相功能的图像处理器1424、用于提供硬件音频加速的音频处理器1426、以及用于提供视频编码/解码加速的视频处理器1428;静态随机存取存储器(sram)单元1430;直接存储器访问(dma)单元1432;以及显示单元1440,用于耦合至一个或多个外部显示器。
接下来转向图15,描绘了根据本公开的实现方式的片上系统(soc)设计的实现方式,该片上系统设计可实现iommu的基于硬件的虚拟化。作为说明性示例,soc1500被包括在用户装备(ue)中。在一个实现方式中,ue是指可由终端用户用于通信的任何设备,诸如,手持电话、智能电话、平板、超薄笔记本、具有宽带适配器的笔记本、或任何其他类似的通信设备。ue可连接至基站或节点,该基站或节点本质上可对应于gsm网络中的移动站(ms)。可以在soc1500中实现页添加和内容复制的实现方式。
在此,soc1500包括2个核——1506和1507。与上文的讨论类似,核1506和1507可符合指令集架构,诸如,具有
在一个实现方式中,sdram控制器1540可经由高速缓存1510而连接至互连1511。互连1511提供到其他组件的通信信道,其他组件诸如,用于与订户身份模块(sim)卡对接的sim1530、用于保存供核1506和1507执行以初始化和引导soc1500的引导代码的引导rom1535、用于与外部存储器(例如,dram1560)对接的sdram控制器1540、用于与非易失性存储器(例如,闪存1565)对接的闪存控制器1545、用于与外围设备对接的外围控件1550(例如,串行外围接口)、用于显示和接收输入(例如,触摸实现的输入)的视频编解码器1520和视频接口1525、用于执行图形相关的计算的gpu1515等等。这些接口中的任何接口可包含本文中所描述的实现方式的各方面。
另外,系统图示用于通信的外围设备,诸如,
图16是可实现iommu的基于硬件的虚拟化的用于执行指令的处理组件的框图。如图所示,计算系统1600包括代码存储1602、取出电路1604、解码电路1606、执行电路1608、寄存器1610、存储器1612以及引退或提交电路1614。在操作中,指令(例如,enqcmds、admcmds)将由取出电路1604从代码存储1602取出,不作为限制,代码存储1602可以包括高速缓存存储器、片上存储器、与处理器在同一管芯上的存储器、指令寄存器、通用寄存器或系统存储器。在一个实现方式中,指令可具有与图14中的指令1400的格式类似的格式。在从代码存储1602取出指令之后,解码电路1606可对取出的指令进行解码,包括通过解析指令的各个字段。在对取出的指令进行解码之后,执行电路1608用于执行经解码的指令。在执行执行指令的步骤时,执行电路1608可从寄存器1610和存储器1612读取数据,并且可将数据写入寄存器1610和存储器1612。不作为限制,寄存器1610可以包括数据寄存器、指令寄存器、向量寄存器、掩码寄存器、通用寄存器、片上存储器、与处理器在同一管芯上的存储器、或与处理器在同一封装中的存储器。不作为限制,存储器1612可以包括片上存储器、与处理器位于同一管芯上的存储器、与处理器位于同一封装中的存储器、高速缓存存储器或系统存储器。在执行电路执行了指令之后,引退或提交电路1614可引退指令,从而确保执行结果被写入或已被写入这些执行结果的目的地,并清空或释放资源供稍后使用。
图17a是根据一个实现方式的用于由处理器执行以执行enqcmds指令以将工作提交到共享工作队列(swq)的示例方法1700的流程图。在开始该过程后,在框1712处,取出电路用于从代码存储取出enqcmds指令。在任选的框1714处,解码电路可对取出的enqcmds指令解码。在框1716处,执行电路用于执行enqcmds指令以协调向swq的工作提交。
enqcmds指令可用于将工作排队到对于对命令所针对的设备类型不可知/透明的任何设备的(多个)swq,在该意义上而言,该enqcmds指令是“通用的”。enqcmds指令可产生原子性非通告写入事务(针对其完成响应被返回到处理设备的写入事务)。非通告写入事务可以是像向目标设备的任何正常mmio写入的所路由的地址。非通告写入事务可伴随其自身携带正在提交该请求的线程/进程的asid,并且还伴随其自身携带特权(例如,环-0),指令在主机上以该特权执行。非通告写入事务还携带专用于目标设备的命令有效载荷。此类swq可利用i/o设备上的工作队列存储来实现,但是还可使用设备外(主机存储器)存储来实现。
图17b是用于由处理器执行以执行admcmds指令以利用来自硬件iommu的支持来处置来自vm的无效的示例方法1720的流程图。在开始该过程后,在框1722处,取出电路用于从代码存储取出admcmds指令。在任选的框1724处,解码电路可对取出的admcmds指令解码。在框1726处,执行电路用于执行admcmds指令以协调包括描述符有效载荷的管理命令从vm向硬件iommu150的提交。描述符有效载荷可包括主机总线设备功能(bdf)标识符,可任选地包括宾客机asid,可包括主机asid,并且可包括要无效的宾客机地址范围。硬件iommu150随后可使用该信息来执行一个或多个无效操作。
图18是图示用于本文中公开的实现对多密钥密码引擎的硬件支持的指令1800的示例格式的框图。指令1800可以是enqcmds或admcmds。指令1800的格式中的参数对于enqcmds或admcmds可以是不同的。由此,参数中的一些参数以虚线被描绘为是任选的。如图所示,指令1400包括页地址1802、任选的操作码1804、任选的属性1806、任选的安全状态位1808以及任选的有效状态位1810。
图19图示根据本文中所讨论的方法中的任何一种或多种方法的计算系统1900的示例形式的机器的图解表示,该计算系统1900内的一组指令用于使机器实现iommu的基于硬件的虚拟化。在替代实现方式中,可以在lan、内联网、外联网或因特网中将机器连接(例如,联网)到其他机器。机器可以在客户机-服务器网络环境中作为服务器或客户机设备操作,或者在对等(或分布式)网络环境中作为对等机器操作。机器可以是个人计算机(pc)、平板pc、机顶盒(stb)、个人数字助理(pda)、蜂窝电话、web设备、服务器、网络路由器、交换机或桥接器、或者能够执行指定由该机器执行的动作的一组指令(顺序的或以其他方式)的任何机器。进一步地,虽然仅图示出单个机器,但是,术语“机器”也应当被认为包括单独地或联合地执行一组(或多组)指令以执行本文中所讨论的方法中的任何一种或多种方法的机器的任何集合。可以在计算系统1900中实现页添加和内容复制的实现方式。
计算机系统1900包括处理设备1902、主存储器1904(例如,闪存、动态随机存取存储器(dram)(诸如,同步dram(sdram)或dram(rdram)等)、静态存储器1906(例如,闪存存储器、静态随机存取存储器(sram)等)以及数据存储设备1916,它们经由总线1908彼此进行通信。
处理设备1902表示一个或多个通用处理设备,诸如,微处理器、中央处理单元等等。更具体地,处理设备可以是复杂指令集计算(cisc)微处理器、精简指令集计算机(risc)微处理器、超长指令字(vliw)微处理器、或实现其他指令集的处理器、或实现指令集的组合的处理器。处理设备1902也可以是一个或多个专用处理设备,诸如,专用集成电路(asic)、现场可编程门阵列(fpga)、数字信号处理器(dsp)、网络处理器等等。在一个实现方式中,处理设备1902可包括一个或多个处理器核。处理设备1902被配置成执行用于执行本文中所讨论的操作的处理逻辑1926。
在一个实现方式中,处理设备1902可以是包括所公开的llc高速缓存架构的处理器或集成电路的部分。替代地,计算系统1900可以包括如本文中所描述的其他组件。应当理解,核可支持多线程化(执行两个或更多个并行的操作或线程的集合),并且可以按各种方式来完成该多线程化,各种方式包括时分多线程化、同时多线程化(其中单个物理核为物理核正在同时多线程化的线程中的每一个线程提供逻辑核)、或其组合(例如,时分取出和解码以及此后的诸如
计算系统1900可进一步包括可通信地耦合至网络1919的网络接口设备1918。计算系统1900还可包括视频显示设备1910(例如,液晶显示器(lcd)或阴极射线管(crt))、字母数字输入设备1912(例如,键盘)、光标控制设备1914(例如,鼠标)、信号生成设备1920(例如,扬声器),或其他外围设备。此外,计算系统1900可包括图形处理单元1922、视频处理单元1928以及音频处理单元1932。在另一实现方式中,计算系统1900可包括芯片组(未图示出),该芯片组是指被设计成与处理设备1902一起工作并控制处理设备1902与外部设备之间的通信的一组集成电路或芯片。例如,芯片组可以是将处理设备1902链接到非常高速度的设备(诸如,主存储器1904和图形控制器)以及将处理设备1902链接到较低速度的外围设备的外围总线(诸如,usb、pci或isa总线)的主板上的一组芯片。
数据存储设备1916可包括计算机可读存储介质1924,在其上存储了具体化本文中描述的功能的方法中的任何一种或多种方法的软件1926。软件1926也可完全或至少部分地作为指令1926驻留在主存储器1904内和/或在由计算系统1900对软件1926的执行期间作为处理逻辑驻留在处理设备1902内;该主存储器1904和处理设备1902也构成计算机可读存储介质。
计算机可读存储介质1924还可用于存储利用处理设备1902的指令1926和/或包含调用以上应用的方法的软件库。尽管计算机可读存储介质1924在示例实现方式中被示出为单个介质,但术语“计算机可读存储介质”应当被视为包括存储一组或多组指令的单个介质或多个介质(例如,集中式或分布式数据库和/或相关联的高速缓存和服务器)。术语“计算机可读存储介质”还应当被视为包括能够存储、编码或承载用于由机器执行并且使该机器执行所公开的实现方式的方法中的任何一种或多种方法的一组指令的任何介质。术语“计算机可读存储介质”应当相应地被视为包括但不限于固态存储器以及光和磁介质。
以下示例涉及进一步的实现方式。
示例1是一种处理器,该处理器包括:1)硬件输入/输出(i/o)存储器管理单元(iommu);以及2)核,耦合至硬件iommu,其中,核用于执行第一指令,以:a)拦截来自虚拟机(vm)的描述符有效载荷,该描述符有效载荷包含宾客机总线设备功能(bdf)标识符、宾客机地址空间标识符(asid)、以及要无效的宾客机地址范围;b)在存储在存储器中的虚拟机控制结构(vmcs)内访问指向第一组转换表的第一指针和指向第二组转换表的第二指针;c)遍历第一组转换表,以将宾客机bdf标识符转换为主机bdf标识符;d)遍历第二组转换表,以将宾客机asid转换为主机asid;e)将主机bdf标识符和主机asid插入在描述符有效载荷中;以及f)将包含描述符有效载荷的管理命令提交到硬件iommu,以执行宾客机地址范围的无效。
在示例2中,如示例1的处理器,其中,硬件iommu用于使用管理命令的描述符有效载荷内的主机bdf标识符和主机asid,以执行相对于宾客机地址范围的无效操作,其中,无效操作是以下至少一项:i/o转换后备缓冲器(iotlb)无效、设备tlb无效、或asid高速缓存无效。
在示例3中,如示例2的处理器,其中,核用于执行第一指令,以进一步响应于由硬件iommu进行的无效操作的完成而将成功的无效传递到vm。
在示例4中,如示例1的处理器,其中,第一组表包括总线表和设备功能表,其中,总线表通过宾客机总线标识符索引,并且其中,设备功能表通过宾客机设备功能标识符索引。
在示例5中,如示例1的处理器,其中,核进一步用于执行vm内的宾客机iommu驱动器,以:a)调用第一指令;b)用宾客机bdf标识符、宾客机asid和宾客机地址范围填充描述符有效载荷;以及c)将描述符有效载荷作为工作提交传输到硬件iommu的共享工作队列(swq)。
在示例6中,如示例5的处理器,进一步包括存储器映射的i/o(mmio)寄存器,其中,宾客机iommu驱动器进一步用于:在mmio寄存器内访问用于将描述符有效载荷提交到swq所提交到的mmio寄存器地址。
在示例7中,如示例1的处理器,其中,第一组转换表被存储在vmcs或片上存储器中的一者中。
各种实现方式可具有以上所述的结构特征的不同组合。例如,也可参照本文中所描述的系统来实现以上所描述的处理器和方法的所有任选特征,并且可在一个或多个实现方式中的任何地方使用示例中的细节。
示例8是一种方法,该方法包括:1)由处理器从在处理器上运行的虚拟机(vm)拦截描述符有效载荷,该描述符有效载荷具有宾客机总线设备功能(bdf)标识符、宾客机地址空间标识符(asid)、以及要无效的宾客机地址范围;2)在存储在存储器中的用于vm的虚拟机控制结构(vmcs)内访问指向第一组转换表的第一指针和指向第二组转换表的第二指针;3)由处理器遍历第一组转换表,以将宾客机bdf标识符转换为主机bdf标识符;4)由处理器遍历第二组转换表,以将宾客机asid转换为主机asid;5)将主机bdf标识符和主机asid插入在描述符有效载荷内;以及6)由处理器将包含描述符有效载荷的管理命令提交到处理器的硬件iommu,以执行宾客机地址范围的无效。
在示例9中,如示例8的方法,进一步包括:由硬件iommu使用管理命令的描述符有效载荷内的主机bdf标识符和主机asid执行相对于宾客机地址范围的无效操作,其中,无效操作是以下至少一项:i/o转换后备缓冲器(iotlb)无效、设备tlb无效、或asid高速缓存无效。
在示例10中,如示例9的方法,进一步包括:由处理器响应于由硬件iommu进行的无效操作的完成而将成功的无效传递到vm,其中,传递包括:设置能由vm访问的完成记录内的状态位。
在示例11中,如示例8的方法,其中,第一组表包括总线表和设备功能表,该方法进一步包括:通过宾客机总线标识符索引总线表;以及通过宾客机设备功能标识符索引设备功能表。
在示例12中,如示例8的方法,进一步包括:1)由vm的宾客机iommu驱动器调用供由处理器执行的指令;2)由宾客机iommu驱动器用宾客机bdf标识符、宾客机asid和宾客机地址范围来填充描述符有效载荷;以及3)由宾客机iommu驱动器将描述符有效载荷传输到硬件iommu的共享工作队列(swq)。
在示例13中,如示例12的方法,进一步包括:1)从存储器映射的i/o(mmio)寄存器检取用于将描述符有效载荷提交到swq所提交到的mmio寄存器地址;以及2)将描述符有效载荷提交到mmio寄存器地址。
各种实现方式可具有以上所述的结构特征的不同组合。例如,也可参照本文中所描述的系统来实现以上所描述的处理器和方法的所有任选特征,并且可在一个或多个实现方式中的任何地方使用示例中的细节。
示例14是一种系统,该系统包括:1)硬件输入/输出(i/o)存储器管理单元(iommu);2)多个核,耦合至硬件iommu,多个核用于执行多个虚拟机;并且3)其中,多个核中的核用于执行第一指令,以:a)拦截来自多个虚拟机中的虚拟机(vm)的描述符有效载荷,该描述符有效载荷包含宾客机总线设备功能(bdf)标识符、宾客机地址空间标识符(asid)、以及要无效的宾客机地址范围;b)在存储在存储器中的虚拟机控制结构(vmcs)内访问指向第一组转换表的第一指针和指向第二组转换表的第二指针;c)遍历第一组转换表,以将宾客机bdf标识符转换为主机bdf标识符;d)遍历第二组转换表,以将宾客机asid转换为主机asid;e)将主机bdf标识符和主机asid插入在描述符有效载荷中;以及f)将包含描述符有效载荷的管理命令提交到硬件iommu,以执行宾客机地址范围的无效。如示例14的系统在进一步的实现方式中还可包括存储器。
在示例15中,如示例14的系统,其中,硬件iommu用于使用管理命令的描述符有效载荷内的主机bdf标识符和主机asid,以执行相对于宾客机地址范围的无效操作,其中,无效操作是以下至少一项:i/o转换后备缓冲器(iotlb)无效、设备tlb无效、或asid高速缓存无效。
在示例16中,如示例15的系统,其中,核用于执行第一指令,以进一步响应于由硬件iommu进行的无效操作的完成而将成功的无效传递到vm,其中,传递包括:设置能由宾客机iommu驱动器访问的完成记录内的状态位。
在示例17中,如示例14的系统,其中,第一组表包括总线表和设备功能表,其中,总线表通过宾客机总线标识符索引,并且其中,设备功能表通过宾客机设备功能标识符索引。
在示例18中,如示例14的系统,其中,核进一步用于执行vm内的宾客机iommu驱动器,以:a)调用第一指令;b)用宾客机bdf标识符、宾客机asid和宾客机地址范围填充描述符有效载荷;以及c)将描述符有效载荷传输到硬件iommu的共享工作队列(swq)。
在示例19中,如示例18的系统,进一步包括存储器映射的i/o(mmio)寄存器,其中,宾客机iommu驱动器进一步用于:在mmio寄存器内访问用于将描述符有效载荷提交到swq所提交到的mmio寄存器地址。
在示例20中,如示例14的系统,其中,第一组转换表被存储在vmcs、存储器或片上存储器中的一者中。
各种实现方式可具有以上所述的结构特征的不同组合。例如,也可参照本文中所描述的系统来实现以上所描述的处理器和方法的所有任选特征,并且可在一个或多个实现方式中的任何地方使用示例中的细节。
示例21是一种非瞬态计算机可读介质,存储有指令,这些指令当由具有硬件输入/输出(i/o)存储器管理单元(iommu)的处理器执行时使处理器执行多个逻辑操作,这些逻辑操作包括:1)从在处理器上运行的虚拟机(vm)拦截描述符有效载荷,该描述符有效载荷具有宾客机总线设备功能(bdf)标识符、宾客机地址空间标识符(asid)、以及要无效的宾客机地址范围;2)在存储在存储器中的用于vm的虚拟机控制结构(vmcs)内访问指向第一组转换表的第一指针和指向第二组转换表的第二指针;3)遍历第一组转换表,以将宾客机bdf标识符转换为主机bdf标识符;4)遍历第二组转换表,以将宾客机asid转换为主机asid;5)将主机bdf标识符和主机asid插入在描述符有效载荷内;以及6)将包含描述符有效载荷的管理命令提交到处理器的硬件iommu,以执行宾客机地址范围的无效。
在示例22中,如示例21的非瞬态计算机可读介质,其中,多个逻辑操作进一步包括:使用管理命令的描述符有效载荷内的主机bdf标识符和主机asid执行相对于宾客机地址范围的无效操作,其中,无效操作是以下至少一项:i/o转换后备缓冲器(iotlb)无效、设备tlb无效、或asid高速缓存无效。
在示例23中,如示例22的非瞬态计算机可读介质,其中,多个逻辑操作进一步包括:响应于由硬件iommu进行的无效操作的完成而将成功的无效传递到vm,其中,传递包括:设置能由vm访问的完成记录内的状态位。
在示例24中,如示例21的非瞬态计算机可读介质,其中,第一组表包括总线表和设备功能表,其中,多个逻辑操作进一步包括:通过宾客机总线标识符索引总线表;以及通过宾客机设备功能标识符索引设备功能表。
在示例25中,如示例21的非瞬态计算机可读介质,其中,多个逻辑操作进一步包括:1)由vm的宾客机iommu驱动器调用供由处理器执行的指令;2)由宾客机iommu驱动器用宾客机bdf标识符、宾客机asid和宾客机地址范围来填充描述符有效载荷;以及3)由宾客机iommu驱动器将描述符有效载荷传输到硬件iommu的共享工作队列(swq)。
在示例26中,如示例25的非瞬态计算机可读介质,其中,多个逻辑操作进一步包括:1)从存储器映射的i/o(mmio)寄存器检取用于将描述符有效载荷提交到swq所提交到的mmio寄存器地址;以及2)将描述符有效载荷提交到mmio寄存器地址。
各种实现方式可具有以上所述的结构特征的不同组合。例如,也可参照本文中所描述的系统来实现以上所描述的处理器和方法的所有任选特征,并且可在一个或多个实现方式中的任何地方使用示例中的细节。
示例27是一种设备,该设备包括:1)用于从虚拟机(vm)拦截描述符有效载荷的装置,该描述符有效载荷具有宾客机总线设备功能(bdf)标识符、宾客机地址空间标识符(asid)、以及要无效的宾客机地址范围;2)用于在存储在存储器中的用于vm的虚拟机控制结构(vmcs)内访问指向第一组转换表的第一指针和指向第二组转换表的第二指针的装置;3)用于遍历第一组转换表以将宾客机bdf标识符转换为主机bdf标识符的装置;4)用于遍历第二组转换表以将宾客机asid转换为主机asid的装置;5)用于将主机bdf标识符和主机asid插入在描述符有效载荷内的装置;以及6)用于将包含描述符有效载荷的管理命令提交到硬件iommu以执行宾客机地址范围的无效的装置。
在示例28中,如示例27的设备,进一步包括:用于使用管理命令的描述符有效载荷内的主机bdf标识符和主机asid执行相对于宾客机地址范围的无效操作的装置,其中,无效操作是以下至少一项:i/o转换后备缓冲器(iotlb)无效、设备tlb无效、或asid高速缓存无效。
在示例29中,如示例28的设备,进一步包括:用于响应于由硬件iommu进行的无效操作的完成而将成功的无效传递到vm的装置,其中,用于传递的装置包括:用于设置能由vm访问的完成记录内的状态位的装置。
在示例30中,如示例27的设备,其中,第一组表包括总线表和设备功能表,该设备进一步包括:用于通过宾客机总线标识符索引总线表的装置;以及用于通过宾客机设备功能标识符索引设备功能表的装置。
在示例31中,如示例27的设备,进一步包括:1)用于调用供由处理器执行的指令的装置;2)用于用宾客机bdf标识符、宾客机asid和宾客机地址范围填充描述符有效载荷的装置;以及3)用于将描述符有效载荷传输到硬件iommu的共享工作队列(swq)的装置。
在示例32中,如示例31的设备,进一步包括:1)用于从存储器映射的i/o(mmio)寄存器检取用于将描述符有效载荷提交到swq所提交到的mmio寄存器地址的装置;以及2)用于将描述符有效载荷提交到mmio寄存器地址的装置。
尽管已参考有限数量的实现方式描述了本公开,但是,本领域技术人员将从其中理解众多修改和变型。所附权利要求书旨在将所有此类修改和变型涵盖为落入本公开的真实精神和范围内。
在本文中的描述中,阐明了众多特定细节(诸如,特定类型的处理器和系统配置的示例、特定的硬件结构、特定的架构和微架构细节、特定的寄存器配置、特定的指令类型、特定的系统组件、特定的测量/高度、特定的处理器流水线级和操作等)以提供对本公开的透彻理解。然而,对本领域技术人员将显而易见的是,不必采用这些特定细节来实施本公开。在其他实例中,未详细描述公知的组件或方法,以避免不必要地使本公开模糊,公知的组件或方法诸如,特定和替代的处理器架构、用于所描述算法的特定的逻辑电路/代码、特定的固件代码、特定的互连操作、特定的逻辑配置、特定的制造技术和材料、特定的编译器实现方式、代码中算法的特定表达、特定的掉电和功率门控技术/逻辑以及计算机系统的其他特定的操作细节。
实现方式参照确定特定的集成电路中(诸如,计算平台或微处理器中)的基于扇区的高速缓存的高速缓存行中的数据有效性来描述。实现方式也可适用于其他类型的集成电路和可编程逻辑器件。例如,所公开的实现方式不限于台式计算机系统或便携式计算机,诸如,
虽然参照处理器描述了本文中的实现方式,但其他实现方式适用于其他类型的集成电路和逻辑器件。本公开的实现方式的类似技术和教导可应用于可受益于更高的流水线吞吐量和改善的性能的其他类型的电路或半导体器件。本公开的实现方式的教导适用于执行数据操纵的任何处理器或机器。然而,本公开不限于执行512位、256位、128位、64位、32位、或16位数据操作的处理器或机器,并可应用于在其中执行数据的操纵或管理的任何处理器和机器。此外,本文中的描述提供了示例,并且附图出于说明性目的示出了各种示例。然而,这些示例不应当以限制性意义来解释,因为它们仅仅旨在提供本公开的实现方式的示例,而并非提供本公开的实现方式的所有可能实现方式的排他性列表。
虽然上述示例在执行单元和逻辑电路的上下文中描述了指令处置和分发,但本公开的其他实现方式也可通过存储在机器可读有形介质上的数据或指令来完成,这些数据和/或指令当由机器执行时使得机器执行与本公开的至少一个实现方式一致的功能。在一个实现方式中,与本公开的实现方式相关联的功能以机器可执行指令来具体化。这些指令可用来使以这些指令编程的通用处理器或专用处理器执行本公开的步骤。本公开的实现方式也可作为计算机程序产品或软件来提供,该计算机程序产品或软件可包括其上存储有指令的机器或计算机可读介质,这些指令可被用来对计算机(或其他电子设备)进行编程以执行根据本公开的实现方式的一个或多个操作。替代地,本公开的实现方式的操作可由包含用于执行这些操作的固定功能逻辑的专用硬件组件来执行,或由经编程的计算机组件以及固定功能硬件组件的任何组合来执行。
用于对逻辑进行编程以执行本公开的实现方式的指令可被存储在系统中的存储器(诸如,dram、高速缓存、闪存存储器、或其他存储)内。此外,指令可以经由网络或借助于其他计算机可读介质被分发。因此,机器可读介质可包括用于以机器(诸如,计算机)可读形式存储或传输信息的任何机制,但不限于:软盘、光盘、紧凑盘只读存储器(cd-rom)、磁光盘、只读存储器(rom)、随机存取存储器(ram)、可擦除可编程只读存储器(eprom)、电可擦除可编程只读存储器(eeprom)、磁卡或光卡、闪存存储器、或在经由互联网通过电、光、声、或其他形式的传播信号(诸如,载波、红外信号、数字信号等)传输信息时使用的有形机器可读存储。因此,计算机可读介质包括适用于存储或传输机器(例如,计算机)可读形式的电子指令或信息的任何类型的有形机器可读介质。
设计可经历多个阶段,从创建到仿真到制造。表示设计的数据能以数种方式来表示该设计。首先,如在仿真中有用的,可使用硬件描述语言或另一功能性描述语言来表示硬件。另外,可在设计过程的一些阶段产生具有逻辑和/或晶体管门的电路级模型。此外,大多数设计在某个阶段都达到表示硬件模型中各种器件的物理布置的数据的水平。在使用常规半导体制造技术的情况下,表示硬件模型的数据可以是指定在用于制造集成电路的掩模的不同掩模层上存在或不存在各种特征的数据。在设计的任何表示中,数据可被存储在任何形式的机器可读介质中。存储器或者磁或光存储(诸如,盘)可以是用于存储经由光学或电学波来传输的信息的机器可读介质,这些光学或电学波被调制或以其他方式生成以传输此类信息。当指示或承载代码或设计的电学载波被传输时,在电信号的复制、缓冲或重新传输被执行的程度上,产生了新副本。因此,通信提供商或网络提供商可在有形机器可读介质上至少临时地存储具体化本公开的实现方式的技术的制品(诸如,编码到载波中的信息)。
如本文中所使用的模块是指硬件、软件、和/或固件的任何组合。作为示例,模块包括与非瞬态介质相关联的诸如微控制器之类的硬件,该非瞬态介质用于存储适于由该微控制器执行的代码。因此,在一个实现方式中,对模块的引用是指硬件,该硬件被专门配置成用于识别和/或执行要被保存在非瞬态介质上的代码。另外,在另一实现方式中,模块的使用是指包括代码的非瞬态介质,该代码专门适于由微控制器执行以执行预定操作。并且如可以推断的,在又一实现方式中,术语模块(在该示例中)可以指微控制器和非瞬态介质的组合。通常,被图示为分开的模块的边界常常变化并且潜在地重叠。例如,第一模块和第二模块可共享硬件、软件、固件、或它们的组合,同时潜在地保留一些独立的硬件、软件或固件。在一个实现方式中,术语逻辑的使用包括诸如晶体管、寄存器之类的硬件或诸如可编程逻辑器件之类的其他硬件。
在一个实现方式中,使用短语“被配置成”指的是布置、组装、制造、许诺销售、进口和/或设计装置、硬件、逻辑或元件以执行所指定或所确定的任务。在该示例中,如果不是正在操作的装置或其元件被设计、耦合、和/或互连以执行所指定的任务,则该不是正在操作的装置或其元件仍然‘被配置成’执行所述所指定的任务。作为纯说明性示例,在操作期间,逻辑门可提供0或1。但‘被配置成’向时钟提供使能信号的逻辑门不包括可提供1或0的每一潜在的逻辑门。相反,该逻辑门是以在操作期间1或0的输出用于启用时钟的某种方式被耦合的逻辑门。再次注意,使用术语‘被配置成’不要求操作,而是关注于装置、硬件、和/或元件的潜在状态,其中在该潜在状态中,该装置、硬件和/或元件被设计成在该装置、硬件和/或元件正在操作时执行特定任务。
此外,在一个实现方式中,使用术语“用于”、“能够/能够用于”和/或“可操作用于”指的是按如下方式设计的某个装置、逻辑、硬件、和/或元件:以指定方式启用对该装置、逻辑、硬件、和/或元件的使用。注意,如上文所述,在一个实现方式中,‘用于’、‘能够用于’、或‘能操作用于’的使用指的是装置、逻辑、硬件、和/或元件的潜在状态,其中该装置、逻辑、硬件、和/或元件不是正在操作,而是以此类方式被设计以便以指定方式启用对装置的使用。
如本文中所使用,值包括数字、状态、逻辑状态、或二进制逻辑状态的任何已知表示。通常,逻辑电平、逻辑值、或多个逻辑值的使用也被称为1和0,这简单地表示了二进制逻辑状态。例如,1指的是高逻辑电平,并且0指的是低逻辑电平。在一个实现方式中,诸如晶体管或闪存单元之类的存储单元能够保存单个逻辑值或多个逻辑值。然而,已经使用了计算机系统中的值的其他表示。例如,十进制数10还可以被表示为二进制值1010和十六进制字母a。因此,值包括能够被保存在计算机系统中的信息的任何表示。
而且,状态可由值或值的部分来表示。作为示例,诸如逻辑1之类的第一值可表示默认或初始状态,而诸如逻辑0之类的第二值可表示非默认状态。另外,在一个实现方式中,术语重置和置位分别是指默认和经更新的值或状态。例如,默认值潜在地包括高逻辑值(即,被重置),而经更新的值潜在地包括低逻辑值(即,被置位)。注意,可利用值的任何组合来表示任何数量的状态。
上述方法、硬件、软件、固件或代码的实现方式可以经由存储在机器可访问、机器可读、计算机可访问、或计算机可读介质上的可由处理元件执行的指令或代码来实现。非瞬态机器可访问/可读介质包括提供(即,存储和/或传输)诸如由计算机或电子系统之类的机器可读的形式的信息的任何机制。例如,非瞬态机器可访问介质包括:随机存取存储器(ram),诸如,静态ram(sram)或动态ram(dram);rom;磁或光存储介质;闪存存储器设备;电存储设备;光存储设备;声存储设备;用于保存从瞬态(传播)信号(例如,载波、红外信号、数字信号)接收的信息的其他形式的存储设备;等等,这些瞬态(传播)信号用于与可从其接收信息的非瞬态介质相区别。
用于对逻辑进行编程以执行本公开的实现方式的指令可被存储在系统中的存储器(诸如,dram、高速缓存、闪存存储器、或其他存储)内。此外,指令可以经由网络或借助于其他计算机可读介质被分发。因此,机器可读介质可包括用于以机器(诸如,计算机)可读形式存储或传输信息的任何机制,但不限于:软盘、光盘、紧凑盘只读存储器(cd-rom)、磁光盘、只读存储器(rom)、随机存取存储器(ram)、可擦除可编程只读存储器(eprom)、电可擦除可编程只读存储器(eeprom)、磁卡或光卡、闪存存储器、或在经由互联网通过电、光、声、或其他形式的传播信号(诸如,载波、红外信号、数字信号等)传输信息时使用的有形机器可读存储。因此,计算机可读介质包括适用于存储或传输机器(例如,计算机)可读形式的电子指令或信息的任何类型的有形机器可读介质。
贯穿本说明书,对“一个实现方式”或“实现方式”的引用意味着结合该实现方式描述的特定特征、结构或特性被包括在本公开的至少一个实现方式中。因此,在贯穿说明书的多个位置出现短语“在一个实现方式中”或“在实现方式中”不一定全部是指同一实现方式。此外,在一个或多个实现方式中,能以任何合适的方式来组合特定的特征、结构或特性。
在上述说明书中,已经参考特定示例性实现方式给出了具体实施方式。然而,将显而易见的是,可对这些实现方式作出各种修改和改变,而不背离如所附权利要求所述的本公开的更宽泛精神和范围。因此,应当认为说明书和附图是说明性的而不是限制性的。此外,实现方式和其他示例性语言的上述使用不一定指的是同一实现方式或同一示例,而是可以指不同和独特的实现方式,也有可能指同一实现方式。
具体实施方式的一些部分在对计算机存储器内的数据位的操作的算法和符号表示方面来呈现。这些算法描述和表示是数据处理领域的技术人员用于向本领域的其他技术人员最有效地传达其工作实质的手段。算法在此一般被理解为导致所需结果的自洽的操作序列。操作是要求对物理量进行物理操纵的那些操作。通常但非必须,这些量采用能被存储、传输、组合、比较、以及以其他方式操纵的电信号或磁信号的形式。主要出于常见用途的考虑,时不时地将这些信号称为位、值、元素、符号、字符、项、数字等已被证明是方便的。本文中描述的块可以是硬件、软件、固件或其组合。
然而,应当记住,所有这些和类似的术语将与适当的物理量关联,并且仅仅是应用于这些量的方便的标记。除非明确指明,否则如从上文的讨论中显而易见的那样,可以理解,贯穿说明书,利用诸如“定义”、“接收”、“确定”、“发布”、“链接”、“关联”、“获取”、“认证”、“禁止”、“执行”、“请求”、“通信”等术语的讨论,指的是计算系统或类似的电子计算设备的动作和进程,该计算系统或类似的电子计算设备操纵在该计算系统的寄存器和存储器内表示为物理(例如,电子)量的数据并将其转换成在该计算系统存储器或寄存器或其他此类信息存储、传输或显示设备内类似地表示为物理量的其他数据。
在本文中使用词语“示例”或“示例性”以意指用作示例、实例或说明。本文中被描述为“示例”或“示例性”的任何方面或设计不一定要被解释为相比其他方面或设计是优选或有利的。相反,词语“示例”或“示例性”的使用旨在以具体的方式来呈现概念。如在本申请中所使用,术语“或”旨在表示包含性的“或”,而不是排它性的“或”。也就是说,除非另外指定或从上下文澄清,否则“x包括a或b”旨在意指自然的包含性排列中的任一者。也就是说,如果x包括a;x包括b;或x包括a和b两者,则在前述实例中的任何实例下“x包括a或b”均被满足。另外,如本申请以及所附权利要求中所使用的冠词“一(a/an)”一般应解释为意指“一个或多个”,除非另外指定或从上下文清楚是指单数形式。此外,通篇对术语“实现方式”或“一个实现方式”或“一实现方式”或“一种实现方式”的使用不旨在意指同一个实现方式,除非被描述为如此。此外,如本文中所使用的术语“第一”、“第二”、“第三”、“第四”等旨在用作用于在不同要素之间进行区分的标记,并且可以不一定具有根据它们的数值指定的顺序含义。
- 还没有人留言评论。精彩留言会获得点赞!